Zelfstudie: Een TensorFlow-model trainen met behulp van de Azure Machine Learning Visual Studio Code-extensie (preview)
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Azure CLI ml-extensie v2 (huidige)
Leer hoe u een afbeeldingsclassificatiemodel traint om handgeschreven nummers te herkennen met behulp van TensorFlow en de Azure Machine Learning Visual Studio Code-extensie.
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In deze zelfstudie leert u het volgende:
- De code begrijpen
- Een werkruimte maken
- Een model trainen
Vereisten
- Azure-abonnement. Als u nog geen abonnement heeft, registreert u zich of probeer de gratis of betaalde versie van Azure Machine Learning. Als u het gratis abonnement gebruikt, worden alleen CPU-clusters ondersteund.
- Visual Studio Code installeren, een lichte, platformoverschrijdende code-editor.
- Azure Machine Learning-studio Visual Studio Code-extensie. Zie de handleiding azure Machine Learning Visual Studio Code-extensie instellen voor installatie-instructies
- CLI (v2). Zie De CLI (v2) installeren, instellen en gebruiken voor installatie-instructies
- De communitygestuurde opslagplaats klonen
git clone https://github.com/Azure/azureml-examples.git
De code begrijpen
De code voor deze zelfstudie maakt gebruik van TensorFlow voor het trainen van een Machine Learning-model voor de classificatie van afbeeldingen dat handgeschreven cijfers van 0-9 categoriseert. Dit wordt gedaan door een neuraal netwerk te maken dat de pixelwaarden van een afbeelding van 28 px x 28 px als invoer gebruikt en een lijst van tien waarschijnlijkheden uitvoert, één voor elk van de cijfers die worden geclassificeerd. Dit is een voorbeeld van hoe de gegevens eruit zien.

Een werkruimte maken
Het eerste wat u moet doen om een toepassing in Azure Machine Learning te bouwen, is een werkruimte maken. Een werkruimte bevat de resources voor het trainen van modellen en de getrainde modellen zelf. Zie Wat is een werkruimte? voor meer informatie.
Open de map azureml-examples/cli/jobs/single-step/tensorflow/mnist vanuit de communitygestuurde opslagplaats in Visual Studio Code.
Selecteer op de activiteitenbalk van Visual Studio het pictogram Azure om de weergave Azure Machine Learning te openen.
Klik in de Azure Machine Learning-weergave met de rechtermuisknop op uw abonnementsknooppunt en selecteer Werkruimte maken.
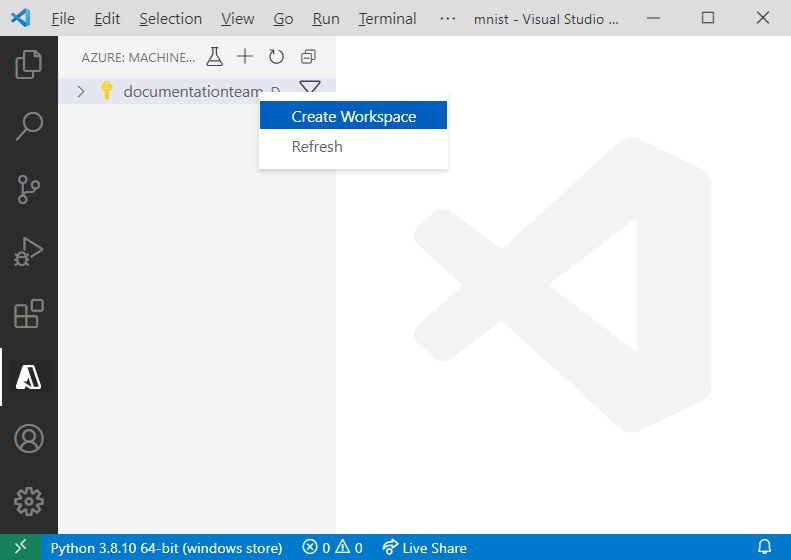
Er wordt een specificatiebestand weergegeven. Configureer het specificatiebestand met de volgende opties.
$schema: https://azuremlschemas.azureedge.net/latest/workspace.schema.json name: TeamWorkspace location: WestUS2 display_name: team-ml-workspace description: A workspace for training machine learning models tags: purpose: training team: ml-teamHet specificatiebestand maakt een werkruimte die in de
WestUS2regio wordt aangeroepenTeamWorkspace. De rest van de opties die in het specificatiebestand zijn gedefinieerd, bieden beschrijvende naamgeving, beschrijvingen en tags voor de werkruimte.Klik met de rechtermuisknop op het specificatiebestand en selecteer AzureML: YAML uitvoeren. Het maken van een resource maakt gebruik van de configuratieopties die zijn gedefinieerd in het YAML-specificatiebestand en verzendt een taak met behulp van de CLI (v2). Op dit moment wordt een aanvraag naar Azure gedaan om een nieuwe werkruimte en afhankelijke resources in uw account te maken. Na een paar minuten wordt de nieuwe werkruimte weergegeven in uw abonnementknooppunt.
Instellen
TeamWorkspaceals uw standaardwerkruimte. Als u dit doet, worden resources en taken die u in de werkruimte maakt standaard opgeslagen. Selecteer de knop Azure Machine Learning-werkruimte instellen op de statusbalk van Visual Studio Code en volg de aanwijzingen om in te stellenTeamWorkspaceals uw standaardwerkruimte.
Zie voor meer informatie over werkruimten hoe u resources beheert in VS Code.
Het model trainen
Tijdens het trainingsproces wordt een TensorFlow-model getraind door de trainingsgegevens en leerpatronen die erin zijn ingesloten, te verwerken voor elk van de respectieve cijfers die worden geclassificeerd.
Net als werkruimten en rekendoelen worden trainingstaken gedefinieerd met resourcesjablonen. Voor dit voorbeeld wordt de specificatie gedefinieerd in het bestand job.yml , dat er als volgt uitziet:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >
python train.py
environment: azureml:AzureML-tensorflow-2.4-ubuntu18.04-py37-cuda11-gpu:48
resources:
instance_type: Standard_NC12
instance_count: 3
experiment_name: tensorflow-mnist-example
description: Train a basic neural network with TensorFlow on the MNIST dataset.
Met dit specificatiebestand wordt een trainingstaak verzonden die wordt aangeroepen tensorflow-mnist-example naar het onlangs gemaakte gpu-cluster computerdoel waarmee de code in het train.py Python-script wordt uitgevoerd. De gebruikte omgeving is een van de gecureerde omgevingen van Azure Machine Learning die TensorFlow en andere softwareafhankelijkheden bevat die nodig zijn om het trainingsscript uit te voeren. Zie Gecureerde omgevingen van Azure Machine Learning voor meer informatie over gecureerde omgevingen.
De trainingstaak verzenden:
- Open het bestand job.yml .
- Klik met de rechtermuisknop op het bestand in de teksteditor en selecteer AzureML: YAML uitvoeren.
Op dit punt wordt een aanvraag verzonden naar Azure om uw experiment in het geselecteerde rekendoel in uw werkruimte uit te voeren. Dit proces duurt enkele minuten. De hoeveelheid tijd die nodig is om de trainingstaak uit te voeren, wordt beïnvloed door diverse factoren, zoals het rekentype en de grootte van de trainingsgegevens. Als u de voortgang van uw experiment wilt bijhouden, klikt u met de rechtermuisknop op het huidige uitvoeringsknooppunt en selecteert u Taak weergeven in Azure Portal.
Wanneer het dialoogvenster voor het openen van een externe website wordt weergegeven, selecteert u Openen.
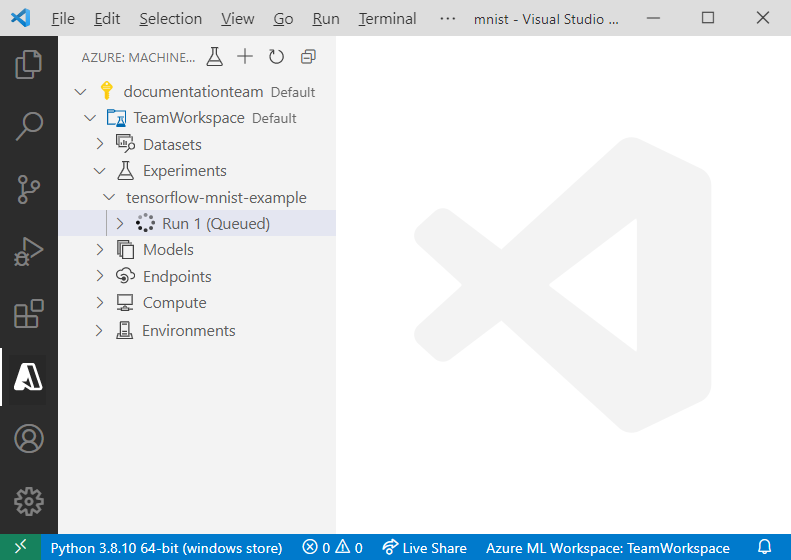
Wanneer de training van het model is voltooid, wordt het statuslabel naast het uitvoeringsknooppunt bijgewerkt in 'Voltooid'.
Volgende stappen
- Visual Studio Code starten die is geïntegreerd met Azure Machine Learning (preview)
- Voor een overzicht van het lokaal bewerken, uitvoeren en foutopsporing van code raadpleegt u de zelfstudie over Python hello-world.
- Voer Jupyter Notebooks uit in Visual Studio Code met behulp van een externe Jupyter-server.
- Zie zelfstudie: Een model trainen en implementeren met Azure Machine Learning buiten Visual Studio Code voor een overzicht van hoe u traint met Azure Machine Learning.