Probleem oplossen met serverloze SQL-pool in Azure Synapse Analytics
Dit artikel bevat informatie over het oplossen van de meest voorkomende problemen met een serverloze SQL-pool in Azure Synapse Analytics.
Raadpleeg de onderwerpen in het overzicht voor meer informatie over Azure Synapse Analytics.
Synapse Studio
Synapse Studio is een eenvoudig te gebruiken hulpprogramma dat u kunt gebruiken om toegang te krijgen tot uw gegevens met behulp van een browser zonder dat u hulpprogramma's voor databasetoegang hoeft te installeren. Synapse Studio is niet ontworpen om een grote set gegevens of volledig beheer van SQL-objecten te lezen.
Serverloze SQL-pool is niet beschikbaar in Synapse Studio
Als Synapse Studio geen verbinding kan maken met een serverloze SQL-pool, ziet u dat de serverloze SQL-pool grijs wordt weergegeven of de status Offline wordt weergegeven.
Dit probleem treedt meestal op om een van de volgende twee redenen:
- Uw netwerk voorkomt communicatie met de Back-end van Azure Synapse Analytics. Het meest voorkomende geval is dat TCP-poort 1443 wordt geblokkeerd. Als u wilt dat een serverloze SQL-pool werkt, moet u deze poort deblokkeren. Andere problemen kunnen voorkomen dat een serverloze SQL-pool ook werkt. Zie de gids voor probleemoplossing voor meer informatie.
- U bent niet gemachtigd om u aan te melden bij een serverloze SQL-pool. Als u toegang wilt krijgen, moet een Azure Synapse-werkruimtebeheerder u toevoegen aan de rol werkruimtebeheerder of de SQL-beheerdersrol. Zie Azure Synapse-toegangsbeheer voor meer informatie.
De Websocket-verbinding is onverwacht gesloten
Uw query kan mislukken met het foutbericht Websocket connection was closed unexpectedly. Dit bericht betekent dat uw browserverbinding met Synapse Studio is onderbroken, bijvoorbeeld vanwege een netwerkprobleem.
- Voer uw query opnieuw uit om dit probleem op te lossen.
- Probeer Azure Data Studio of SQL Server Management Studio voor dezelfde query's in plaats van Synapse Studio voor verder onderzoek.
- Als dit bericht vaak voorkomt in uw omgeving, kunt u hulp krijgen van uw netwerkbeheerder. U kunt ook de firewallinstellingen controleren en de handleiding voor probleemoplossing controleren.
- Als het probleem zich blijft voordoen, maakt u een ondersteuningsticket via Azure Portal.
Serverloze databases worden niet weergegeven in Synapse Studio
Als u de databases die zijn gemaakt in een serverloze SQL-pool niet ziet, controleert u of uw serverloze SQL-pool is gestart. Als een serverloze SQL-pool is gedeactiveerd, worden de databases niet weergegeven. Voer bijvoorbeeld SELECT 1een query uit op een serverloze SQL-pool om deze te activeren en de databases weer te geven.
Serverloze SQL-pool van Synapse wordt weergegeven als niet beschikbaar
Onjuiste netwerkconfiguratie is vaak de oorzaak van dit gedrag. Zorg ervoor dat de poorten juist zijn geconfigureerd. Als u een firewall of privé-eindpunten gebruikt, controleert u deze instellingen ook.
Controleer ten slotte of de juiste rollen zijn verleend en niet zijn ingetrokken.
Kan geen nieuwe database maken omdat de aanvraag gebruikmaakt van de oude/verlopen sleutel
Deze fout wordt veroorzaakt door het wijzigen van de door de klant beheerde sleutel van de werkruimte die wordt gebruikt voor versleuteling. U kunt ervoor kiezen om alle gegevens in de werkruimte opnieuw te versleutelen met de nieuwste versie van de actieve sleutel. Als u de sleutel opnieuw wilt versleutelen, wijzigt u de sleutel in Azure Portal in een tijdelijke sleutel en gaat u vervolgens terug naar de sleutel die u wilt gebruiken voor versleuteling. Lees hier hoe u de werkruimtesleutels beheert.
Serverloze SQL-pool van Synapse is niet beschikbaar nadat een abonnement is overgedragen naar een andere Microsoft Entra-tenant
Als u een abonnement naar een andere Microsoft Entra-tenant hebt verplaatst, ondervindt u mogelijk problemen met een serverloze SQL-pool. Maak een ondersteuningsticket en ondersteuning voor Azure neemt contact met u op om het probleem op te lossen.
Toegang tot opslag
Als er fouten optreden tijdens het openen van bestanden in Azure Storage, moet u ervoor zorgen dat u gemachtigd bent om toegang te krijgen tot gegevens. U moet toegang hebben tot openbaar beschikbare bestanden. Als u toegang probeert te krijgen tot gegevens zonder referenties, moet u ervoor zorgen dat uw Microsoft Entra-identiteit rechtstreeks toegang heeft tot de bestanden.
Als u een handtekeningsleutel voor gedeelde toegang hebt die u moet gebruiken voor toegang tot bestanden, moet u ervoor zorgen dat u een referentie op serverniveau of databasebereik hebt gemaakt die die referentie bevat. De referenties zijn vereist als u toegang nodig hebt tot gegevens met behulp van de beheerde identiteit van de werkruimte en de aangepaste SPN (Service Principal Name).
Kan geen bestanden lezen, weergeven of openen in Azure Data Lake Storage
Als u een Microsoft Entra-aanmelding zonder expliciete referenties gebruikt, moet u ervoor zorgen dat uw Microsoft Entra-identiteit toegang heeft tot de bestanden in de opslag. Voor toegang tot de bestanden moet uw Microsoft Entra-identiteit beschikken over de machtiging Blob Data Reader of machtigingen voor lijsten en leestoegangsbeheerlijsten (ACL) in ADLS. Zie Query mislukt voor meer informatie omdat het bestand niet kan worden geopend.
Als u toegang hebt tot opslag met behulp van referenties, moet u ervoor zorgen dat uw beheerde identiteit of SPN de rol Gegevenslezer of Inzender of specifieke ACL-machtigingen heeft. Als u een handtekeningtoken voor gedeelde toegang hebt gebruikt, controleert u of het een machtiging heeft rl en of het niet is verlopen.
Als u een SQL-aanmelding en de OPENROWSET functie zonder gegevensbron gebruikt, moet u ervoor zorgen dat u een referentie op serverniveau hebt die overeenkomt met de opslag-URI en gemachtigd is voor toegang tot de opslag.
Query mislukt omdat het bestand niet kan worden geopend
Als uw query mislukt met de fout File cannot be opened because it does not exist or it is used by another process en u zeker weet dat beide bestanden bestaan en niet worden gebruikt door een ander proces, heeft de serverloze SQL-pool geen toegang tot het bestand. Dit probleem treedt meestal op omdat uw Microsoft Entra-identiteit geen rechten heeft voor toegang tot het bestand of omdat een firewall de toegang tot het bestand blokkeert.
Standaard probeert een serverloze SQL-pool toegang te krijgen tot het bestand met behulp van uw Microsoft Entra-identiteit. U kunt dit probleem oplossen door over de juiste rechten te beschikken om toegang te krijgen tot het bestand. De eenvoudigste manier is om uzelf de rol Inzender voor opslagblobgegevens te verlenen voor het opslagaccount waarop u een query wilt uitvoeren.
Zie voor meer informatie:
- Microsoft Entra ID-toegangsbeheer voor opslag
- Toegang tot opslagaccounts beheren voor een serverloze SQL-pool in Synapse Analytics
Alternatief voor de rol Inzender voor Opslagblobgegevens
In plaats van uzelf de rol Inzender voor opslagblobgegevens toe te kennen, kunt u ook gedetailleerdere machtigingen verlenen voor een subset van bestanden.
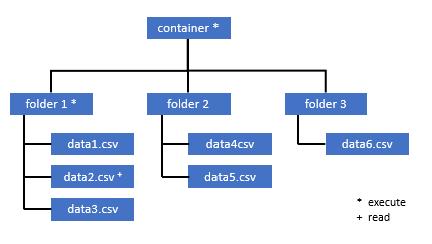
Alle gebruikers die toegang nodig hebben tot bepaalde gegevens in deze container, moeten ook de machtiging EXECUTE hebben voor alle bovenliggende mappen tot aan de hoofdmap (de container).
Meer informatie over het instellen van ACL's in Azure Data Lake Storage Gen2.
Notitie
De machtiging Uitvoeren op het containerniveau moet worden ingesteld in Azure Data Lake Storage Gen2. Machtigingen voor de map kunnen worden ingesteld in Azure Synapse.
Als u in dit voorbeeld een query wilt uitvoeren op data2.csv, zijn de volgende machtigingen nodig:
- Machtiging uitvoeren voor container
- Machtiging uitvoeren voor map1
- Leesmachtiging voor data2.csv
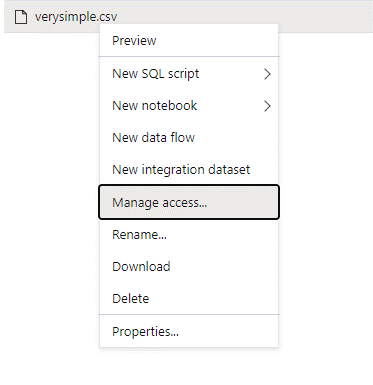
Meld u aan bij Azure Synapse met een gebruiker met beheerdersrechten voor de gegevens die u wilt openen.
Klik in het gegevensvenster met de rechtermuisknop op het bestand en selecteer Toegang beheren.
Selecteer ten minste leesmachtigingen . Voer bijvoorbeeld
user@contoso.comde UPN of object-id van de gebruiker in. Selecteer Toevoegen.Geef leesmachtigingen voor deze gebruiker.

Notitie
Voor gastgebruikers moet deze stap rechtstreeks met Azure Data Lake worden uitgevoerd, omdat deze niet rechtstreeks kan worden uitgevoerd via Azure Synapse.
Inhoud van de map op het pad kan niet worden vermeld
Deze fout geeft aan dat de gebruiker die een query uitvoert op Azure Data Lake de bestanden in de opslag niet kan vermelden. Er zijn verschillende scenario's waarin deze fout kan optreden:
- De Microsoft Entra-gebruiker die gebruikmaakt van Pass Through-verificatie van Microsoft Entra, is niet gemachtigd om de bestanden in Data Lake Storage weer te geven.
- De Microsoft Entra-id of SQL-gebruiker die gegevens leest met behulp van een beheerde identiteit voor gedeelde toegangshandtekening of werkruimte en die sleutel of identiteit is niet gemachtigd om de bestanden in de opslag weer te geven.
- De gebruiker die toegang heeft tot Dataverse-gegevens die niet gemachtigd zijn om query's uit te voeren op gegevens in Dataverse. Dit scenario kan zich voordoen als u SQL-gebruikers gebruikt.
- De gebruiker die toegang heeft tot Delta Lake, is mogelijk niet gemachtigd om het Delta Lake-transactielogboek te lezen.
De eenvoudigste manier om dit probleem op te lossen, is door uzelf de rol Inzender voor opslagblobgegevens toe te kennen in het opslagaccount waarop u een query wilt uitvoeren.
Zie voor meer informatie:
- Microsoft Entra ID-toegangsbeheer voor opslag
- Toegang tot opslagaccounts beheren voor een serverloze SQL-pool in Synapse Analytics
Inhoud van de Dataverse-tabel kan niet worden weergegeven
Als u de Azure Synapse Link voor Dataverse gebruikt om de gekoppelde DataVerse-tabellen te lezen, moet u het Microsoft Entra-account gebruiken om toegang te krijgen tot de gekoppelde gegevens met behulp van de serverloze SQL-pool. Zie Azure Synapse Link voor Dataverse met Azure Data Lake voor meer informatie.
Als u een SQL-aanmelding probeert te gebruiken om een externe tabel te lezen die verwijst naar de DataVerse-tabel, krijgt u de volgende fout: External table '???' is not accessible because content of directory cannot be listed.
Externe dataverse-tabellen maken altijd gebruik van Passthrough-verificatie van Microsoft Entra. U kunt ze niet configureren voor het gebruik van een handtekeningsleutel voor gedeelde toegang of beheerde identiteit voor werkruimten.
De inhoud van het Delta Lake-transactielogboek kan niet worden weergegeven
De volgende fout wordt geretourneerd wanneer de map van het Delta Lake-transactielogboek niet kan worden gelezen door een serverloze SQL-pool:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Zorg ervoor dat de _delta_log map bestaat. Misschien voert u query's uit op Parquet-bestanden die niet worden geconverteerd naar de Delta Lake-indeling. Als de _delta_log map bestaat, moet u de machtiging Lezen en Lijst hebben voor de onderliggende Delta Lake-mappen. Probeer json-bestanden rechtstreeks te lezen met behulp van FORMAT='csv'. Plaats uw URI in de PARAMETER BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Als deze query mislukt, is de aanroeper niet gemachtigd om de onderliggende opslagbestanden te lezen.
Queryuitvoering
In de volgende gevallen krijgt u mogelijk fouten tijdens de uitvoering van de query:
- De aanroeper heeft geen toegang tot sommige objecten.
- De query heeft geen toegang tot externe gegevens.
- De query bevat enkele functies die niet worden ondersteund in serverloze SQL-pools.
Query mislukt omdat deze niet kan worden uitgevoerd vanwege huidige resourcebeperkingen
Uw query kan mislukken met het foutbericht This query cannot be executed due to current resource constraints. Dit bericht betekent dat de serverloze SQL-pool momenteel niet kan worden uitgevoerd. Hier volgen enkele probleemoplossingsopties:
- Zorg dat u gegevenstypen van redelijke grootte gebruikt.
- Als uw query is gericht op Parquet-bestanden, kunt u overwegen expliciete typen voor tekenreekskolommen te definiëren, omdat deze standaard VARCHAR(8000) zijn. Controleer de uitgestelde gegevenstypen.
- Als uw query CSV-bestanden aanroept, kunt u overwegen om statistieken te maken.
- Zie Best practices voor prestaties voor een serverloze SQL-pool om uw query te optimaliseren.
De time-out voor de query is verlopen
De fout Query timeout expired wordt geretourneerd als de query meer dan 30 minuten wordt uitgevoerd op een serverloze SQL-pool. Deze limiet voor een serverloze SQL-pool kan niet worden gewijzigd.
- Probeer uw query te optimaliseren door best practices toe te passen.
- Probeer delen van uw query's te materialiseren met behulp van een externe tabel als select (CETAS).a0>
- Controleer of er een gelijktijdige workload wordt uitgevoerd in een serverloze SQL-pool, omdat de andere query's de resources kunnen overnemen. In dat geval kunt u de werkbelasting op meerdere werkruimten splitsen.
Ongeldige objectnaam
De fout Invalid object name 'table name' geeft aan dat u een object, zoals een tabel of weergave, gebruikt dat niet bestaat in de serverloze SQL-pooldatabase. Probeer deze opties:
Geef de tabellen of weergaven weer en controleer of het object bestaat. Gebruik SQL Server Management Studio of Azure Data Studio omdat Synapse Studio mogelijk enkele tabellen weergeeft die niet beschikbaar zijn in een serverloze SQL-pool.
Als u het object ziet, controleert u of u een hoofdlettergevoelige/binaire databasesortering gebruikt. Misschien komt de objectnaam niet overeen met de naam die u in de query hebt gebruikt. Met een binaire databasesortering
Employeeenemployeetwee verschillende objecten zijn.Als u het object niet ziet, probeert u misschien een query uit te voeren op een tabel uit een lake- of Spark-database. De tabel is mogelijk niet beschikbaar in de serverloze SQL-pool, omdat:
- De tabel bevat een aantal kolomtypen die niet kunnen worden weergegeven in een serverloze SQL-pool.
- De tabel heeft een indeling die niet wordt ondersteund in een serverloze SQL-pool. Voorbeelden zijn Avro of ORC.
Tekenreeks- of binaire gegevens worden afgekapt
Deze fout treedt op als de lengte van uw tekenreeks of binair kolomtype (bijvoorbeeld VARCHARVARBINARY, of NVARCHAR) korter is dan de werkelijke grootte van de gegevens die u leest. U kunt deze fout oplossen door de lengte van het kolomtype te verhogen:
- Als uw tekenreekskolom is gedefinieerd als het
VARCHAR(32)type en de tekst 60 tekens is, gebruikt u het type (of langer) in hetVARCHAR(60)kolomschema. - Als u de schemadeductie (zonder het
WITHschema) gebruikt, worden alle tekenreekskolommen automatisch gedefinieerd als hetVARCHAR(8000)type. Als u deze fout krijgt, definieert u expliciet het schema in eenWITHcomponent met het grotereVARCHAR(MAX)kolomtype om deze fout op te lossen. - Als uw tabel zich in de Lake-database bevindt, probeert u de kolomgrootte van de tekenreeks in de Spark-pool te vergroten.
- Probeer een serverloze SQL-pool in te
SET ANSI_WARNINGS OFFschakelen om de VARCHAR-waarden automatisch af tekappen, als dit geen invloed heeft op uw functionaliteiten.
Niet-ingesloten aanhalingsteken na de tekenreeks
In zeldzame gevallen, waarbij u de OPERATOR LIKE gebruikt in een tekenreekskolom of een vergelijking met de letterlijke tekenreeksen, krijgt u mogelijk de volgende fout:
Unclosed quotation mark after the character string
Deze fout kan optreden als u de Latin1_General_100_BIN2_UTF8 sortering op de kolom gebruikt. Probeer sortering in te stellen Latin1_General_100_CI_AS_SC_UTF8 op de kolom in plaats van de Latin1_General_100_BIN2_UTF8 sortering om het probleem op te lossen. Als de fout nog steeds wordt geretourneerd, dient u een ondersteuningsaanvraag in via Azure Portal.
Kan tempdb-ruimte niet toewijzen tijdens het overdragen van gegevens van de ene distributie naar de andere
De fout Could not allocate tempdb space while transferring data from one distribution to another wordt geretourneerd wanneer de engine voor het uitvoeren van query's geen gegevens kan verwerken en deze kan overdragen tussen de knooppunten die de query uitvoeren. Het is een speciaal geval dat de algemene query mislukt omdat deze niet kan worden uitgevoerd vanwege de fout met huidige resourcebeperkingen . Deze fout wordt geretourneerd wanneer de resources die aan de tempdb database zijn toegewezen, onvoldoende zijn om de query uit te voeren.
Pas best practices toe voordat u een ondersteuningsticket indient.
Query mislukt met foutafhandeling van een extern bestand (maximum aantal fouten bereikt)
Als uw query mislukt met het foutbericht error handling external file: Max errors count reached, betekent dit dat er geen overeenkomst is tussen een opgegeven kolomtype en de gegevens die moeten worden geladen.
Als u meer informatie wilt over de fout en welke rijen en kolommen u wilt bekijken, wijzigt u de parserversie van 2.0 in 1.0.
Opmerking
Als u een query wilt uitvoeren op het bestand names.csv met deze query 1, retourneert de serverloze SQL-pool van Azure Synapse de volgende fout: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. bijvoorbeeld:
Het bestand names.csv bevat:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Query 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Oorzaak
Zodra de parserversie is gewijzigd van versie 2.0 in 1.0, helpen de foutberichten om het probleem te identificeren. Het nieuwe foutbericht is nu Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Door afkapping wordt aangegeven dat het kolomtype te klein is om aan uw gegevens te voldoen. De langste voornaam in dit names.csv bestand heeft zeven tekens. Het gegevenstype dat moet worden gebruikt, moet ten minste VARCHAR(7) zijn. De fout wordt veroorzaakt door deze coderegel:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Als u de query wijzigt, wordt de fout opgelost. Na foutopsporing wijzigt u de parserversie opnieuw in 2.0 om maximale prestaties te bereiken.
Zie OPENROWSET gebruiken met behulp van een serverloze SQL-pool in Synapse Analytics voor meer informatie over het gebruik van welke parserversie.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Kan niet bulksgewijs laden omdat het bestand niet kan worden geopend
De fout Cannot bulk load because the file could not be opened wordt geretourneerd als een bestand wordt gewijzigd tijdens de uitvoering van de query. Normaal gesproken krijgt u mogelijk een foutmelding zoals Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
De serverloze SQL-pools kunnen geen bestanden lezen die worden gewijzigd terwijl de query wordt uitgevoerd. De query kan de bestanden niet vergrendelen. Als u weet dat de wijzigingsbewerking wordt toegevoegd, kunt u proberen de volgende optie in te stellen: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}
Zie voor meer informatie hoe u query's kunt uitvoeren op alleen toevoegbestanden of tabellen kunt maken op bestanden met alleen toevoeggegevens.
Query mislukt met fout bij gegevensconversie
Uw query kan mislukken met het foutbericht Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. Dit bericht betekent dat uw gegevenstypen niet overeenkomen met de werkelijke gegevens voor rijnummer n en kolom m.
Als u bijvoorbeeld alleen gehele getallen in uw gegevens verwacht, maar in rij n er een tekenreeks is, wordt dit foutbericht weergegeven.
Om dit probleem op te lossen, inspecteert u het bestand en de gegevenstypen die u hebt gekozen. Controleer ook of de instellingen voor het scheidingsteken voor rijen en veldeindtekens juist zijn. In het volgende voorbeeld ziet u hoe controle kan worden uitgevoerd door VARCHAR als kolomtype te gebruiken.
Zie CSV-bestanden opvragen voor meer informatie over veldeindtekens, rijscheidingstekens en escape-aanhalingstekens.
Opmerking
Als u een query wilt uitvoeren op het bestand names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Met de volgende query:
Query 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Serverloze SQL-pool van Azure Synapse retourneert de fout Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Het is nodig om door de gegevens te bladeren en een weloverwogen beslissing te nemen om dit probleem op te lossen. Als u de gegevens wilt bekijken die dit probleem veroorzaken, moet het gegevenstype eerst worden gewijzigd. In plaats van een query uit te voeren op de id-kolom met het gegevenstype SMALLINT, wordt VARCHAR(100) nu gebruikt om dit probleem te analyseren.
Met deze enigszins gewijzigde query 2 kunnen de gegevens nu worden verwerkt om de lijst met namen te retourneren.
Query 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Mogelijk ziet u dat de gegevens onverwachte waarden voor de id in de vijfde rij bevatten. In dergelijke omstandigheden is het belangrijk om in overeenstemming te zijn met de bedrijfseigenaar van de gegevens om te bepalen hoe beschadigde gegevens, zoals dit voorbeeld, kunnen worden vermeden. Als preventie niet mogelijk is op toepassingsniveau, is VARCHAR mogelijk de enige optie hier.
Tip
Probeer VARCHAR() zo kort mogelijk te maken. Vermijd INDIEN MOGELIJK VARCHAR(MAX) omdat dit de prestaties kan beïnvloeden.
Het queryresultaat ziet er niet uit zoals verwacht
Uw query mislukt mogelijk niet, maar mogelijk ziet u dat uw resultatenset niet zoals verwacht is. De resulterende kolommen zijn mogelijk leeg of onverwachte gegevens worden geretourneerd. In dit scenario is waarschijnlijk een rijscheidingsteken of veldeindteken onjuist gekozen.
Als u dit probleem wilt oplossen, bekijkt u nog eens de gegevens en wijzigt u deze instellingen. Foutopsporing van deze query is eenvoudig, zoals wordt weergegeven in het volgende voorbeeld.
Opmerking
Als u een query wilt uitvoeren op het bestand names.csv met de query in Query 1, retourneert de serverloze SQL-pool van Azure Synapse een resultaat dat er oneven uitziet:
In names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Er lijkt geen waarde in de kolom Firstnamete zijn. In plaats daarvan zijn alle waarden in de ID kolom terechtgekomen. Deze waarden worden gescheiden door een komma. Het probleem is veroorzaakt door deze coderegel omdat het nodig is om de komma te kiezen in plaats van het puntkomma-symbool als veldeindteken:
FIELDTERMINATOR =';',
Als u dit ene teken wijzigt, wordt het probleem opgelost:
FIELDTERMINATOR =',',
De resultatenset die door Query 2 is gemaakt, ziet er nu als verwacht uit:
Query 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Retourneert:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Kolom van het type is niet compatibel met extern gegevenstype
Als uw query mislukt met het foutbericht Column [column-name] of type [type-name] is not compatible with external data type […], , is het waarschijnlijk dat een PARQUET-gegevenstype is toegewezen aan een onjuist SQL-gegevenstype.
Als uw Parquet-bestand bijvoorbeeld een kolomprijs heeft met floatnummers (zoals 12,89) en u het bestand probeert toe te wijzen aan INT, wordt dit foutbericht weergegeven.
Als u dit probleem wilt oplossen, inspecteert u het bestand en de gegevenstypen die u hebt gekozen. Deze toewijzingstabel helpt bij het kiezen van een correct SQL-gegevenstype. Geef als best practice alleen toewijzing op voor kolommen die anders zouden worden omgezet in het VARCHAR-gegevenstype. Het vermijden van VARCHAR indien mogelijk leidt tot betere prestaties in query's.
Opmerking
Als u een query wilt uitvoeren op het bestand taxi-data.parquet met deze query 1, retourneert de serverloze SQL-pool van Azure Synapse de volgende fout:
Het bestand taxi-data.parquet bevat:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Query 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Dit foutbericht geeft aan dat gegevenstypen niet compatibel zijn en worden geleverd met de suggestie om FLOAT te gebruiken in plaats van INT. De fout wordt veroorzaakt door deze coderegel:
SumTripDistance INT,
Met deze enigszins gewijzigde query 2 kunnen de gegevens nu worden verwerkt en worden alle drie de kolommen weergegeven:
Query 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Query verwijst naar een object dat niet wordt ondersteund in de gedistribueerde verwerkingsmodus
De fout The query references an object that is not supported in distributed processing mode geeft aan dat u een object of functie hebt gebruikt die niet kan worden gebruikt tijdens het opvragen van gegevens in Azure Storage of analytische opslag van Azure Cosmos DB.
Sommige objecten, zoals systeemweergaven en functies, kunnen niet worden gebruikt terwijl u query's uitvoert op gegevens die zijn opgeslagen in Azure Data Lake of analytische opslag van Azure Cosmos DB. Vermijd het gebruik van de query's waarmee externe gegevens worden samengevoegd met systeemweergaven, externe gegevens in een tijdelijke tabel laden of sommige functies voor beveiliging of metagegevens gebruiken om externe gegevens te filteren.
WaitIOCompletion-aanroep is mislukt
Het foutbericht WaitIOCompletion call failed geeft aan dat de query is mislukt tijdens het wachten op het voltooien van de I/O-bewerking die gegevens leest uit de externe opslag, Azure Data Lake.
Het foutbericht heeft het volgende patroon: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Zorg ervoor dat uw opslag zich in dezelfde regio bevindt als een serverloze SQL-pool. Controleer de metrische opslaggegevens en controleer of er geen andere workloads zijn op de opslaglaag, zoals het uploaden van nieuwe bestanden, die I/O-aanvragen kunnen bevatten.
Het veld HRESULT bevat de resultaatcode. De volgende foutcodes komen het meest voor in combinatie met de mogelijke oplossingen.
Deze foutcode betekent dat het bronbestand zich niet in de opslag bevindt.
Er zijn redenen waarom deze foutcode kan optreden:
- Het bestand is verwijderd door een andere toepassing.
- In dit veelvoorkomende scenario wordt de uitvoering van de query gestart, worden de bestanden opgesomd en worden de bestanden gevonden. Later wordt tijdens de uitvoering van de query een bestand verwijderd. Het kan bijvoorbeeld worden verwijderd door Databricks, Spark of Azure Data Factory. De query mislukt omdat het bestand niet is gevonden.
- Dit probleem kan ook optreden met de Delta-indeling. De query kan slagen bij opnieuw proberen omdat er een nieuwe versie van de tabel is en het verwijderde bestand niet opnieuw wordt opgevraagd.
- Er wordt een ongeldig uitvoeringsplan in de cache opgeslagen.
- Voer als tijdelijke oplossing de opdracht
DBCC FREEPROCCACHEuit. Als het probleem zich blijft voordoen, maakt u een ondersteuningsticket.
- Voer als tijdelijke oplossing de opdracht
Onjuiste syntaxis in de buurt van NOT
De fout Incorrect syntax near 'NOT' geeft aan dat er enkele externe tabellen zijn met kolommen die de BEPERKING NOT NULL in de kolomdefinitie bevatten.
- Werk de tabel bij om NOT NULL uit de kolomdefinitie te verwijderen.
- Deze fout kan soms ook tijdelijk optreden met tabellen die zijn gemaakt op basis van een CETAS-instructie. Als het probleem niet wordt opgelost, kunt u proberen de externe tabel te verwijderen en opnieuw te maken.
Partitiekolom retourneert NULL-waarden
Als uw query NULL-waarden retourneert in plaats van kolommen te partitioneren of de partitiekolommen niet kunt vinden, hebt u enkele mogelijke stappen voor probleemoplossing:
- Als u tabellen gebruikt om een query uit te voeren op een gepartitioneerde gegevensset, bieden tabellen geen ondersteuning voor partitionering. Vervang de tabel door de gepartitioneerde weergaven.
- Als u de gepartitioneerde weergaven gebruikt met de OPENROWSET waarmee gepartitioneerde bestanden worden opgevraagd met behulp van de functie FILEPATH(), moet u ervoor zorgen dat u het jokertekenpatroon op de locatie correct hebt opgegeven en de juiste index hebt gebruikt om te verwijzen naar het jokerteken.
- Als u de bestanden rechtstreeks in de gepartitioneerde map opvraagt, zijn de partitioneringskolommen niet de onderdelen van de bestandskolommen. De partitioneringswaarden worden in de mappaden geplaatst en niet in de bestanden. Daarom bevatten de bestanden niet de partitioneringswaarden.
Waarde invoegen in batch voor kolomtype DATETIME2 mislukt
De fout Inserting value to batch for column type DATETIME2 failed geeft aan dat de serverloze pool de datumwaarden uit de onderliggende bestanden niet kan lezen. De datum/tijd-waarde die is opgeslagen in het Parquet- of Delta Lake-bestand, kan niet worden weergegeven als een DATETIME2 kolom.
Inspecteer de minimumwaarde in het bestand met behulp van Spark en controleer of sommige datums kleiner zijn dan 0001-01-03. Als u de bestanden hebt opgeslagen met behulp van de Versie van Spark 2.4 (niet-ondersteunde runtimeversie) of met de hogere Spark-versie die nog steeds een verouderde opslagindeling voor datum/tijd gebruikt, worden de datum/tijd-waarden geschreven met behulp van de Juliaanse kalender die niet is afgestemd op de proleptische Gregoriaanse kalender die wordt gebruikt in serverloze SQL-pools.
Er kan een verschil van twee dagen zijn tussen de Juliaanse kalender die wordt gebruikt voor het schrijven van de waarden in Parquet (in sommige Spark-versies) en de proleptische Gregoriaanse kalender die wordt gebruikt in een serverloze SQL-pool. Dit verschil kan leiden tot een negatieve datumwaarde, die ongeldig is.
Gebruik Spark om deze waarden bij te werken omdat ze worden behandeld als ongeldige datumwaarden in SQL. In het volgende voorbeeld ziet u hoe u de waarden die buiten SQL-datumbereiken liggen, bijwerkt naar NULL in Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Met deze wijziging worden de waarden verwijderd die niet kunnen worden weergegeven. De andere datumwaarden zijn mogelijk correct geladen, maar onjuist weergegeven omdat er nog steeds een verschil is tussen Juliaanse en proleptische Gregoriaanse kalenders. Mogelijk ziet u onverwachte datumwisselingen, zelfs voor de datums voordat 1900-01-01 u Spark 3.0 of oudere versies gebruikt.
Overweeg om te migreren naar Spark 3.1 of hoger en over te schakelen naar de proleptische Gregoriaanse kalender. De nieuwste Spark-versies gebruiken standaard een proleptische Gregoriaanse kalender die is afgestemd op de agenda in een serverloze SQL-pool. Laad uw verouderde gegevens opnieuw met de hogere versie van Spark en gebruik de volgende instelling om de datums te corrigeren:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Query is mislukt vanwege een topologiewijziging of rekencontainerfout
Deze fout kan erop wijzen dat er een intern procesprobleem is opgetreden in een serverloze SQL-pool. Dien een ondersteuningsticket in met alle benodigde details waarmee het ondersteuning voor Azure team het probleem kan onderzoeken.
Beschrijf alles wat ongebruikelijk kan zijn in vergelijking met de normale werkbelasting. Er is bijvoorbeeld een groot aantal gelijktijdige aanvragen of een speciale workload of query gestart voordat deze fout is opgetreden.
Er is een time-out opgetreden voor uitbreiding met jokertekens
Zoals beschreven in de sectie Querymappen en meerdere bestanden , ondersteunt een serverloze SQL-pool het lezen van meerdere bestanden/mappen met behulp van jokertekens. Er is een maximumlimiet van 10 jokertekens per query. U moet er rekening mee houden dat deze functionaliteit tegen een vergoeding wordt geleverd. Het duurt even voordat de serverloze pool alle bestanden weergeeft die overeenkomen met het jokerteken. Dit introduceert latentie en deze latentie kan toenemen als het aantal bestanden dat u probeert op te vragen hoog is. In dit geval kunt u de volgende fout tegenkomen:
"Wildcard expansion timed out after X seconds."
Er zijn verschillende risicobeperkingsstappen die u kunt uitvoeren om dit te voorkomen:
- Best practices toepassen die worden beschreven in serverloze SQL-pool met best practices.
- Probeer het aantal bestanden dat u probeert op te vragen, te verminderen door bestanden te comprimeren in grotere bestanden. Probeer uw bestandsgrootten boven de 100 MB te houden.
- Zorg ervoor dat filters over partitioneringskolommen waar mogelijk worden gebruikt.
- Als u de Delta-bestandsindeling gebruikt, gebruikt u de functie voor het optimaliseren van schrijfbewerkingen in Spark. Dit kan de prestaties van query's verbeteren door de hoeveelheid gegevens te verminderen die moet worden gelezen en verwerkt. Het gebruik van geoptimaliseerde schrijfbewerkingen wordt beschreven in Het gebruik van geoptimaliseerde schrijfbewerkingen in Apache Spark.
- Als u sommige jokertekens op het hoogste niveau wilt voorkomen door de impliciete filters voor het partitioneren van kolommen effectief te coderen, gebruikt u dynamische SQL.
Ontbrekende kolom bij het gebruik van automatische schemadeductie
U kunt eenvoudig query's uitvoeren op bestanden zonder schema te kennen of op te geven door de WITH-component weg te laten. In dat geval worden kolomnamen en gegevenstypen afgeleid uit de bestanden. Houd er rekening mee dat als u het aantal bestanden tegelijk leest, het schema wordt afgeleid van de eerste bestandsservice uit de opslag. Dit kan betekenen dat sommige van de verwachte kolommen worden weggelaten, allemaal omdat het bestand dat door de service wordt gebruikt om het schema te definiëren, deze kolommen niet bevat. Als u het schema expliciet wilt opgeven, gebruikt u de COMPONENT OPENROWSET WITH. Als u een schema opgeeft (met behulp van een externe tabel of OPENROWSET WITH-component), wordt de standaard lax-padmodus gebruikt. Dit betekent dat de kolommen die niet in sommige bestanden bestaan, worden geretourneerd als NULL's (voor rijen uit die bestanden). Als u wilt weten hoe de padmodus wordt gebruikt, raadpleegt u de volgende documentatie en het volgende voorbeeld.
Configuratie
Met serverloze SQL-pools kunt u T-SQL gebruiken om databaseobjecten te configureren. Er zijn enkele beperkingen:
- U kunt geen objecten maken in
masterenlakehouseof Spark-databases. - U moet een hoofdsleutel hebben om referenties te maken.
- U moet gemachtigd zijn om te verwijzen naar gegevens die worden gebruikt in de objecten.
Kan geen database maken
Als u de fout CREATE DATABASE failed. User database limit has been already reached.krijgt, hebt u het maximale aantal databases gemaakt dat in één werkruimte wordt ondersteund. Zie Beperkingen voor meer informatie.
- Als u de objecten wilt scheiden, gebruikt u schema's in de databases.
- Als u naar Azure Data Lake Storage wilt verwijzen, maakt u Lakehouse-databases of Spark-databases die worden gesynchroniseerd in een serverloze SQL-pool.
Tabel maken of wijzigen is mislukt omdat de minimale rijgrootte groter is dan de maximaal toegestane tabelrijgrootte van 8060 bytes
Elke tabel kan maximaal 8 kB per rij hebben (niet inclusief VARCHAR(MAX)/VARBINARY(MAX)-gegevens. Als u een tabel maakt waarbij de totale grootte van cellen in de rij groter is dan 8060 bytes, krijgt u de volgende fout:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Deze fout kan ook optreden in de Lake-database als u een Spark-tabel maakt met de kolomgrootten die groter zijn dan 8060 bytes. De serverloze SQL-pool kan geen tabel maken die verwijst naar de Spark-tabelgegevens.
Vermijd als beperking het gebruik van de typen vaste grootten, zoals CHAR(N) en vervang ze door variabele groottetypen VARCHAR(N) of verklein de grootte in CHAR(N). Zie de beperking van de groep met 8 kB-rijen in SQL Server.
Maak een hoofdsleutel in de database of open de hoofdsleutel in de sessie voordat u deze bewerking uitvoert
Als uw query mislukt met het foutbericht Please create a master key in the database or open the master key in the session before performing this operation., betekent dit dat uw gebruikersdatabase momenteel geen toegang heeft tot een hoofdsleutel.
Waarschijnlijk hebt u een nieuwe gebruikersdatabase gemaakt en nog geen hoofdsleutel gemaakt.
Maak een hoofdsleutel met de volgende query om dit probleem op te lossen:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Notitie
Vervang 'strongpasswordhere' hier door een ander geheim.
CREATE-instructie wordt niet ondersteund in de hoofddatabase
Als uw query mislukt met het foutbericht Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database., betekent dit dat de master database in een serverloze SQL-pool geen ondersteuning biedt voor het maken van:
- Externe tabellen.
- Externe gegevensbronnen.
- Referenties voor databasebereik.
- Externe bestandsindelingen.
Dit is de oplossing:
Een gebruikersdatabase maken:
CREATE DATABASE <DATABASE_NAME>Voer een CREATE-instructie uit in de context van <DATABASE_NAME>, die eerder is mislukt voor de
masterdatabase.Hier volgt een voorbeeld van het maken van een externe bestandsindeling:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Kan microsoft Entra-aanmelding of gebruiker niet maken
Als er een fout optreedt tijdens het maken van een nieuwe Microsoft Entra-aanmelding of gebruiker in een database, controleert u de aanmelding die u hebt gebruikt om verbinding te maken met uw database. De aanmelding die probeert een nieuwe Microsoft Entra-gebruiker te maken, moet gemachtigd zijn om toegang te krijgen tot het Microsoft Entra-domein en te controleren of de gebruiker bestaat. Houd er rekening mee dat:
- SQL-aanmeldingen hebben deze machtiging niet, dus u krijgt deze fout altijd als u SQL-verificatie gebruikt.
- Als u een Microsoft Entra-aanmelding gebruikt om nieuwe aanmeldingen te maken, controleert u of u gemachtigd bent om toegang te krijgen tot het Microsoft Entra-domein.
Azure Cosmos DB
Met serverloze SQL-pools kunt u query's uitvoeren op analytische opslag van Azure Cosmos DB met behulp van de OPENROWSET functie. Zorg ervoor dat uw Azure Cosmos DB-container analytische opslag heeft. Zorg ervoor dat u het account, de database en de containernaam juist hebt opgegeven. Zorg er ook voor dat uw Azure Cosmos DB-accountsleutel geldig is. Zie Vereisten voor meer informatie.
Kan geen query's uitvoeren op Azure Cosmos DB met behulp van de functie OPENROWSET
Als u geen verbinding kunt maken met uw Azure Cosmos DB-account, bekijkt u de vereisten. Mogelijke fouten en probleemoplossingsacties worden vermeld in de volgende tabel.
| Error | Hoofdoorzaak |
|---|---|
| Syntaxisfouten: - Onjuiste syntaxis in de buurt OPENROWSET.- ... is geen herkende BULK OPENROWSET provideroptie.- Onjuiste syntaxis in de buurt .... |
Mogelijke hoofdoorzaken: - Azure Cosmos DB niet gebruiken als de eerste parameter. - Een letterlijke tekenreeks gebruiken in plaats van een id in de derde parameter. - De derde parameter (containernaam) wordt niet opgegeven. |
| Er is een fout opgetreden in de Azure Cosmos DB-verbindingsreeks. | - Het account, de database of de sleutel is niet opgegeven. - Een optie in een verbindingsreeks wordt niet herkend. - Een puntkomma ( ;) wordt aan het einde van een verbindingsreeks geplaatst. |
| Het oplossen van het Azure Cosmos DB-pad is mislukt met de fout 'Onjuiste accountnaam' of 'Onjuiste databasenaam'. | De opgegeven accountnaam, databasenaam of container kan niet worden gevonden of analytische opslag is niet ingeschakeld voor de opgegeven verzameling. |
| Het oplossen van het Azure Cosmos DB-pad is mislukt met de fout 'Onjuiste geheime waarde' of 'Geheim is null of leeg'. | De accountsleutel is niet geldig of ontbreekt. |
Er wordt een waarschuwing over UTF-8-sortering geretourneerd tijdens het lezen van Azure Cosmos DB-tekenreekstypen
Serverloze SQL-pool retourneert een waarschuwing over compileertijd als de OPENROWSET kolomsortering geen UTF-8-codering heeft. U kunt eenvoudig de standaardsortering wijzigen voor alle OPENROWSET functies die in de huidige database worden uitgevoerd met behulp van de T-SQL-instructie:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Een Latin1_General_100_BIN2_UTF8-sortering biedt de beste prestaties wanneer u uw gegevens filtert met behulp van tekenreekspredicaten.
Ontbrekende rijen in analytische opslag van Azure Cosmos DB
Sommige items uit Azure Cosmos DB worden mogelijk niet geretourneerd door de OPENROWSET functie. Houd er rekening mee dat:
- Er is een synchronisatievertraging tussen de transactionele en analytische opslag. Het document dat u hebt ingevoerd in het transactionele archief van Azure Cosmos DB, kan na twee tot drie minuten worden weergegeven in de analytische opslag.
- Het document kan een aantal schemabeperkingen schenden.
Query retourneert NULL-waarden in sommige Azure Cosmos DB-items
Azure Synapse SQL retourneert NULL in plaats van de waarden die u in het transactiearchief ziet in de volgende gevallen:
- Er is een synchronisatievertraging tussen de transactionele en analytische opslag. De waarde die u hebt ingevoerd in het transactionele archief van Azure Cosmos DB, kan na twee tot drie minuten worden weergegeven in de analytische opslag.
- Er is mogelijk een verkeerde kolomnaam of padexpressie in de WITH-component. De kolomnaam (of padexpressie na het kolomtype) in de WITH-component moet overeenkomen met de eigenschapsnamen in de Azure Cosmos DB-verzameling. Vergelijking is hoofdlettergevoelig. Dit zijn bijvoorbeeld
productCodeProductCodeverschillende eigenschappen. Zorg ervoor dat de kolomnamen exact overeenkomen met de eigenschapsnamen van Azure Cosmos DB. - De eigenschap wordt mogelijk niet verplaatst naar de analytische opslag omdat deze in strijd is met bepaalde schemabeperkingen, zoals meer dan 1000 eigenschappen of meer dan 127 nestniveaus.
- Als u een goed gedefinieerde schemaweergave gebruikt, heeft de waarde in het transactionele archief mogelijk een onjuist type. Met een goed gedefinieerd schema worden de typen voor elke eigenschap vergrendeld door een steekproef van de documenten te nemen. Elke toegevoegde waarde in het transactionele archief dat niet overeenkomt met het type, wordt behandeld als een verkeerde waarde en niet gemigreerd naar de analytische opslag.
- Als u een schemaweergave van volledige kwaliteit gebruikt, moet u ervoor zorgen dat u het achtervoegsel van het type toevoegt na de naam van de eigenschap, zoals
$.price.int64. Als u geen waarde ziet voor het pad waarnaar wordt verwezen, wordt het mogelijk opgeslagen onder een ander typepad, bijvoorbeeld$.price.float64. Zie Query's uitvoeren op Azure Cosmos DB-verzamelingen in het schema met volledige betrouwbaarheid voor meer informatie.
Kolom is niet compatibel met extern gegevenstype
De fout Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. wordt geretourneerd als het opgegeven kolomtype in de WITH-component niet overeenkomt met het type in de Azure Cosmos DB-container. Probeer het kolomtype te wijzigen zoals wordt beschreven in de sectie Azure Cosmos DB in SQL-typetoewijzingen of gebruik het VARCHAR-type.
Oplossen: Het Azure Cosmos DB-pad is mislukt met de fout
Als u de foutcontrole Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. krijgt om te zien of u privé-eindpunten hebt gebruikt in Azure Cosmos DB. Als u wilt dat een serverloze SQL-pool toegang krijgt tot een analytische opslag met privé-eindpunten, moet u privé-eindpunten configureren voor de analytische opslag van Azure Cosmos DB.
Prestatieproblemen met Azure Cosmos DB
Als u onverwachte prestatieproblemen ondervindt, moet u ervoor zorgen dat u aanbevolen procedures hebt toegepast, zoals:
- Zorg ervoor dat u de clienttoepassing, serverloze pool en analytische opslag van Azure Cosmos DB in dezelfde regio hebt geplaatst.
- Zorg ervoor dat u de WITH-component gebruikt met optimale gegevenstypen.
- Zorg ervoor dat u Latin1_General_100_BIN2_UTF8 sortering gebruikt wanneer u uw gegevens filtert met tekenreekspredicaten.
- Als u herhalende query's hebt die in de cache kunnen worden opgeslagen, kunt u CETAS gebruiken om queryresultaten op te slaan in Azure Data Lake Storage.
Delta Lake
Er zijn enkele beperkingen die u kunt zien in delta lake-ondersteuning in serverloze SQL-pools:
- Zorg ervoor dat u verwijst naar de hoofdmap Delta Lake in de functie OPENROWSET of de locatie van de externe tabel.
- De hoofdmap moet een submap met de naam
_delta_loghebben. De query mislukt als er geen_delta_logmap is. Als u die map niet ziet, verwijst u naar gewone Parquet-bestanden die moeten worden geconverteerd naar Delta Lake met behulp van Apache Spark-pools. - Geef geen jokertekens op om het partitieschema te beschrijven. De Delta Lake-query identificeert automatisch de Delta Lake-partities.
- De hoofdmap moet een submap met de naam
- Delta Lake-tabellen die zijn gemaakt in de Apache Spark-pools, zijn automatisch beschikbaar in een serverloze SQL-pool, maar het schema wordt niet bijgewerkt (beperking voor openbare preview). Als u kolommen toevoegt in de Delta-tabel met behulp van een Spark-pool, worden de wijzigingen niet weergegeven in de serverloze SQL-pooldatabase.
- Externe tabellen bieden geen ondersteuning voor partitionering. Gebruik gepartitioneerde weergaven in de map Delta Lake om de partitie-verwijdering te gebruiken. Zie bekende problemen en tijdelijke oplossingen verderop in het artikel.
- Serverloze SQL-pools bieden geen ondersteuning voor query's voor tijdreizen. Gebruik Apache Spark-pools in Synapse Analytics om historische gegevens te lezen.
- Serverloze SQL-pools bieden geen ondersteuning voor het bijwerken van Delta Lake-bestanden. U kunt een serverloze SQL-pool gebruiken om een query uit te voeren op de nieuwste versie van Delta Lake. Gebruik Apache Spark-pools in Synapse Analytics om Delta Lake bij te werken.
- U kunt geen queryresultaten opslaan in de Delta Lake-indeling met behulp van de CETAS-opdracht. De CETAS-opdracht ondersteunt alleen Parquet en CSV als uitvoerindeling.
- Serverloze SQL-pools in Synapse Analytics zijn compatibel met deltalezer versie 1.
- Serverloze SQL-pools in Synapse Analytics bieden geen ondersteuning voor de gegevenssets met het BLOOM-filter. De serverloze SQL-pool negeert de BLOOM-filters.
- Delta Lake-ondersteuning is niet beschikbaar in toegewezen SQL-pools. Zorg ervoor dat u serverloze SQL-pools gebruikt om query's uit te voeren op Delta Lake-bestanden.
- Zie bekende problemen met serverloze SQL-pools in Azure Synapse Analytics voor meer informatie over bekende problemen met serverloze SQL-pools.
Serverloze ondersteuning voor Delta 1.0-versie
Serverloze SQL-pools lezen alleen de Delta Lake 1.0-versie. Serverloze SQL-pools is een Delta-lezer met niveau 1 en biedt geen ondersteuning voor de volgende functies:
- Kolomtoewijzingen worden genegeerd. Serverloze SQL-pools retourneren oorspronkelijke kolomnamen.
- Verwijdervectoren worden genegeerd en de oude versie van verwijderde/bijgewerkte rijen wordt geretourneerd (mogelijk verkeerde resultaten).
- De volgende Delta Lake-functies worden niet ondersteund: V2-controlepunten, tijdstempel zonder tijdzone, VACUUM-protocolcontrole
Verwijdervectoren worden genegeerd
Als uw Delta Lake-tabel is geconfigureerd voor het gebruik van Delta Writer versie 7, worden verwijderde rijen en oude versies van bijgewerkte rijen opgeslagen in Delete Vectors (DV). Omdat serverloze SQL-pools deltalezer 1 niveau hebben, negeren ze de verwijdervectoren en produceren ze waarschijnlijk verkeerde resultaten bij het lezen van een niet-ondersteunde Delta Lake-versie.
Kolomnaam wijzigen in Delta-tabel wordt niet ondersteund
De serverloze SQL-pool biedt geen ondersteuning voor het uitvoeren van query's op Delta Lake-tabellen met de gewijzigde kolommen. Serverloze SQL-pool kan geen gegevens lezen uit de kolom met de naam ervan.
De waarde van een kolom in de Delta-tabel is NULL
Als u een Delta-gegevensset gebruikt waarvoor een Delta-lezer versie 2 of hoger is vereist en de functies worden gebruikt die niet worden ondersteund in versie 1 (bijvoorbeeld het wijzigen van de naam van kolommen, het verwijderen van kolommen of kolomtoewijzing), worden de waarden in de kolommen waarnaar wordt verwezen mogelijk niet weergegeven.
JSON-tekst is niet juist opgemaakt
Deze fout geeft aan dat de serverloze SQL-pool het Delta Lake-transactielogboek niet kan lezen. U ziet waarschijnlijk de volgende fout:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Zorg ervoor dat uw Delta Lake-gegevensset niet is beschadigd. Controleer of u de inhoud van de Delta Lake-map kunt lezen met behulp van een Apache Spark-pool in Azure Synapse. Op deze manier zorgt u ervoor dat het _delta_log bestand niet is beschadigd.
Tijdelijke oplossing
Probeer een controlepunt te maken in de Delta Lake-gegevensset met behulp van de Apache Spark-pool en voer de query opnieuw uit. Het controlepunt voegt transactionele JSON-logboekbestanden samen en lost het probleem mogelijk op.
Als de gegevensset geldig is, maakt u een ondersteuningsticket en geeft u meer informatie op:
- Breng geen wijzigingen aan, zoals het toevoegen of verwijderen van de kolommen of het optimaliseren van de tabel, omdat deze bewerking de status van de Delta Lake-transactielogboekbestanden kan wijzigen.
- Kopieer de inhoud van de
_delta_logmap naar een nieuwe lege map. Kopieer de.parquet databestanden niet. - Lees de inhoud die u in de nieuwe map hebt gekopieerd en controleer of u dezelfde fout krijgt.
- Verzend de inhoud van het gekopieerde
_delta_logbestand naar ondersteuning voor Azure.
U kunt nu de map Delta Lake blijven gebruiken met een Spark-pool. U geeft gekopieerde gegevens aan microsoft-ondersteuning als u deze informatie mag delen. Het Azure-team onderzoekt de inhoud van het delta_log bestand en biedt meer informatie over mogelijke fouten en tijdelijke oplossingen.
Delta-logboeken oplossen is mislukt
De volgende fout geeft aan dat een serverloze SQL-pool deltalogboeken niet kan oplossen: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. de meest voorkomende oorzaak is dat last_checkpoint_file in _delta_log de map groter is dan 200 bytes vanwege het checkpointSchema veld dat is toegevoegd in Spark 3.3.
Er zijn twee opties beschikbaar om deze fout te omzeilen:
- Wijzig de juiste configuratie in spark-notebook en genereer een nieuw controlepunt, zodat
last_checkpoint_filedeze opnieuw wordt gemaakt. Als u Azure Databricks gebruikt, is de configuratiewijziging het volgende:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Downgraden naar Spark 3.2.1.
Ons technische team werkt momenteel aan een volledige ondersteuning voor Spark 3.3.
Delta-tabel die in Spark is gemaakt, wordt niet weergegeven in een serverloze pool
Notitie
Replicatie van Delta-tabellen die zijn gemaakt in Spark, is nog steeds in openbare preview.
Als u een Delta-tabel in Spark hebt gemaakt en deze niet wordt weergegeven in de serverloze SQL-pool, controleert u het volgende:
- Wacht enige tijd (meestal 30 seconden) omdat de Spark-tabellen met vertraging worden gesynchroniseerd.
- Als de tabel na enige tijd niet in de serverloze SQL-pool werd weergegeven, controleert u het schema van de Spark Delta-tabel. Spark-tabellen met complexe typen of de typen die niet worden ondersteund in serverloos, zijn niet beschikbaar. Probeer een Spark Parquet-tabel te maken met hetzelfde schema in een lake-database en controleer of die tabel wordt weergegeven in de serverloze SQL-pool.
- Controleer de beheerde identiteit van de werkruimte toegang tot de Delta Lake-map waarnaar wordt verwezen door de tabel. Serverloze SQL-pool maakt gebruik van beheerde identiteit voor werkruimten om de tabelkolomgegevens op te halen uit de opslag om de tabel te maken.
Lake-database
De Lake-databasetabellen die zijn gemaakt met Spark of Synapse Designer, zijn automatisch beschikbaar in een serverloze SQL-pool voor het uitvoeren van query's. U kunt een serverloze SQL-pool gebruiken om query's uit te voeren op de Parquet-, CSV- en Delta Lake-tabellen die zijn gemaakt met behulp van Spark-pool en andere schema's, weergaven, procedures, tabelwaardefuncties en Microsoft Entra-gebruikers in db_datareader rol toe te voegen aan uw Lake-database. Mogelijke problemen worden vermeld in deze sectie.
Een tabel die in Spark is gemaakt, is niet beschikbaar in een serverloze pool
Tabellen die worden gemaakt, zijn mogelijk niet direct beschikbaar in een serverloze SQL-pool.
- De tabellen zijn beschikbaar in serverloze pools met enige vertraging. Mogelijk moet u 5-10 minuten wachten nadat u een tabel in Spark hebt gemaakt om deze te zien in een serverloze SQL-pool.
- Alleen de tabellen die verwijzen naar Parquet-, CSV- en Delta-indelingen zijn beschikbaar in een serverloze SQL-pool. Andere tabeltypen zijn niet beschikbaar.
- Een tabel met een aantal niet-ondersteunde kolomtypen is niet beschikbaar in een serverloze SQL-pool.
- Toegang tot Delta Lake-tabellen in Lake-databases is in openbare preview. Controleer andere problemen die worden vermeld in deze sectie of in de sectie Delta Lake.
Een externe tabel die in Spark is gemaakt, toont onverwachte resultaten in een serverloze pool
Het kan gebeuren dat er een onjuiste overeenkomst is tussen de externe brontabel van Spark en de gerepliceerde externe tabel in de serverloze pool. Dit kan gebeuren als de bestanden die worden gebruikt bij het maken van externe Spark-tabellen, geen extensies hebben. Als u de juiste resultaten wilt krijgen, moet u ervoor zorgen dat alle bestanden met extensies zoals .parquet zijn.
Bewerking is niet toegestaan voor een gerepliceerde database
Deze fout wordt geretourneerd als u een Lake-database wilt wijzigen, externe tabellen, externe gegevensbronnen, referenties voor databases of andere objecten in uw Lake-database wilt maken. Deze objecten kunnen alleen worden gemaakt in SQL-databases.
De Lake-databases worden gerepliceerd vanuit de Apache Spark-pool en beheerd door Apache Spark. Daarom kunt u geen objecten zoals in SQL Databases maken met behulp van de T-SQL-taal.
Alleen de volgende bewerkingen zijn toegestaan in de Lake-databases:
- Weergaven, procedures en inline tabelwaardefuncties (iTVF) maken, verwijderen of wijzigen in de andere schema's dan
dbo. - De databasegebruikers maken en verwijderen uit Microsoft Entra ID.
- Databasegebruikers toevoegen aan of verwijderen uit
db_datareaderschema.
Andere bewerkingen zijn niet toegestaan in Lake-databases.
Notitie
Als u een weergave, procedure of functie maakt in dbo een schema (of schema weglaat en het standaardschema gebruikt dat meestal dbois), krijgt u het foutbericht.
Delta-tabellen in Lake-databases zijn niet beschikbaar in een serverloze SQL-pool
Zorg ervoor dat de beheerde identiteit van uw werkruimte leestoegang heeft tot de ADLS-opslag die de Delta-map bevat. De serverloze SQL-pool leest het Delta Lake-tabelschema uit de Delta-logboeken die in ADLS worden geplaatst en gebruikt de beheerde identiteit van de werkruimte voor toegang tot de Delta-transactielogboeken.
Probeer een gegevensbron in een SQL Database in te stellen die verwijst naar uw Azure Data Lake-opslag met behulp van de referenties voor beheerde identiteit en probeer een externe tabel te maken boven op de gegevensbron met Beheerde identiteit om te bevestigen dat een tabel met de beheerde identiteit toegang heeft tot uw opslag.
Delta-tabellen in Lake-databases hebben geen identiek schema in Spark- en serverloze pools
Met serverloze SQL-pools hebt u toegang tot Parquet-, CSV- en Delta-tabellen die zijn gemaakt in De Lake-database met behulp van Spark of Synapse Designer. Toegang tot de Delta-tabellen bevindt zich nog steeds in openbare preview en momenteel wordt een Delta-tabel zonder server gesynchroniseerd met Spark tijdens het maken, maar wordt het schema niet bijgewerkt als de kolommen later worden toegevoegd met behulp van de ALTER TABLE instructie in Spark.
Dit is een beperking voor openbare preview. Verwijder en maak de Delta-tabel in Spark (indien mogelijk) in plaats van tabellen te wijzigen om dit probleem op te lossen.
Prestaties
Serverloze SQL-pool wijst de resources toe aan de query's op basis van de grootte van de gegevensset en querycomplexiteit. U kunt de resources die aan de query's worden verstrekt, niet wijzigen of beperken. Er zijn enkele gevallen waarin u onverwachte prestatieverminderingen van query's ondervindt en mogelijk moet u de hoofdoorzaken identificeren.
Queryduur is erg lang
Als u query's hebt met een queryduur die langer is dan 30 minuten, zijn de resultaten langzaam naar de client geretourneerd. Serverloze SQL-pool heeft een limiet van 30 minuten voor uitvoering. Er wordt meer tijd besteed aan resultaatstreaming. Probeer de volgende tijdelijke oplossingen:
- Als u Synapse Studio gebruikt, probeert u de problemen met een andere toepassing, zoals SQL Server Management Studio of Azure Data Studio, te reproduceren.
- Als uw query traag is wanneer deze wordt uitgevoerd met behulp van SQL Server Management Studio, Azure Data Studio, Power BI of een andere toepassing, controleert u netwerkproblemen en aanbevolen procedures.
- Plaats de query in de CETAS-opdracht en meet de duur van de query. De CETAS-opdracht slaat de resultaten op in Azure Data Lake Storage en is niet afhankelijk van de clientverbinding. Als de CETAS-opdracht sneller is voltooid dan de oorspronkelijke query, controleert u de netwerkbandbreedte tussen de client en de serverloze SQL-pool.
Query is traag wanneer deze wordt uitgevoerd met behulp van Synapse Studio
Als u Synapse Studio gebruikt, kunt u een desktopclient zoals SQL Server Management Studio of Azure Data Studio gebruiken. Synapse Studio is een webclient die verbinding maakt met een serverloze SQL-pool met behulp van het HTTP-protocol. Dit is doorgaans langzamer dan de systeemeigen SQL-verbindingen die worden gebruikt in SQL Server Management Studio of Azure Data Studio.
Query is traag wanneer de query wordt uitgevoerd met behulp van een toepassing
Controleer de volgende problemen als u trage uitvoering van query's ondervindt:
- Zorg ervoor dat de clienttoepassingen worden samengevoegd met het eindpunt van de serverloze SQL-pool. Het uitvoeren van een query in de regio kan leiden tot extra latentie en trage streaming van de resultatenset.
- Zorg ervoor dat u geen netwerkproblemen hebt die de trage streaming van de resultatenset kunnen veroorzaken
- Zorg ervoor dat de clienttoepassing voldoende resources heeft (bijvoorbeeld niet 100% CPU gebruiken).
- Zorg ervoor dat het opslagaccount of de analytische opslag van Azure Cosmos DB in dezelfde regio wordt geplaatst als uw serverloze SQL-eindpunt.
Bekijk de aanbevolen procedures voor het collocateren van de resources.
Hoge variaties in queryduur
Als u dezelfde query uitvoert en variaties in de queryduur bekijkt, kunnen verschillende redenen dit gedrag veroorzaken:
- Controleer of dit de eerste uitvoering van een query is. De eerste uitvoering van een query verzamelt de statistieken die nodig zijn om een plan te maken. De statistieken worden verzameld door de onderliggende bestanden te scannen en de queryduur te verlengen. In Synapse Studio ziet u de query's voor het maken van globale statistieken in de SQL-aanvraaglijst die vóór uw query worden uitgevoerd.
- Statistieken kunnen na enige tijd verlopen. Het kan regelmatig zijn dat u een impact op de prestaties ziet, omdat de serverloze pool de statistieken moet scannen en herbouwen. Mogelijk ziet u nog een 'globale statistieken maken' query's in de SQL-aanvraaglijst die vóór uw query worden uitgevoerd.
- Controleer of er een workload is die wordt uitgevoerd op hetzelfde eindpunt wanneer u de query met de langere duur hebt uitgevoerd. Het serverloze SQL-eindpunt wijst de resources ook toe aan alle query's die parallel worden uitgevoerd en de query kan worden vertraagd.
Connecties
Met een serverloze SQL-pool kunt u verbinding maken met behulp van het TDS-protocol en met behulp van de T-SQL-taal om query's uit te voeren op gegevens. De meeste hulpprogramma's die verbinding kunnen maken met SQL Server of Azure SQL Database, kunnen ook verbinding maken met een serverloze SQL-pool.
SQL-pool wordt opgewarmd
Na een langere periode van inactiviteit wordt een serverloze SQL-pool gedeactiveerd. De activering vindt automatisch plaats bij de eerste volgende activiteit, zoals de eerste verbindingspoging. Het activeringsproces kan iets langer duren dan één interval voor een verbindingspoging, waardoor het foutbericht wordt weergegeven. Het opnieuw proberen van de verbindingspoging moet voldoende zijn.
Als best practice kunt u voor de clients die dit ondersteunen, ConnectionRetryCount en ConnectRetryInterval verbindingsreeks trefwoorden gebruiken om het gedrag van opnieuw verbinden te beheren.
Als het foutbericht zich blijft voordoen, dient u een ondersteuningsticket in via Azure Portal.
Kan geen verbinding maken vanuit Synapse Studio
Zie de sectie Synapse Studio.
Kan geen verbinding maken met de Azure Synapse-pool vanuit een hulpprogramma
Sommige hulpprogramma's hebben mogelijk geen expliciete optie die u kunt gebruiken om verbinding te maken met de serverloze SQL-pool van Azure Synapse. Gebruik een optie die u zou gebruiken om verbinding te maken met SQL Server of SQL Database. Het verbindingsdialoogvenster hoeft niet als Synapse te worden aangeduid, omdat de serverloze SQL-pool hetzelfde protocol gebruikt als SQL Server of SQL Database.
Zelfs als u met een hulpprogramma alleen een logische servernaam en vooraf gedefinieerde database.windows.net domein kunt invoeren, plaatst u de naam van de Azure Synapse-werkruimte, gevolgd door het -ondemand achtervoegsel en het database.windows.net domein.
Beveiliging
Zorg ervoor dat een gebruiker machtigingen heeft voor toegang tot databases, machtigingen voor het uitvoeren van opdrachten en machtigingen voor toegang tot Azure Data Lake of Azure Cosmos DB-opslag.
Geen toegang tot het Azure Cosmos DB-account
U moet een alleen-lezen Azure Cosmos DB-sleutel gebruiken om toegang te krijgen tot uw analytische opslag. Zorg er dus voor dat deze niet is verlopen of dat deze niet opnieuw wordt gegenereerd.
Als u de fout 'Oplossen van Azure Cosmos DB-pad is mislukt met fout' krijgt, controleert u of u een firewall hebt geconfigureerd.
Geen toegang tot lakehouse of Spark-database
Als een gebruiker geen toegang heeft tot een Lakehouse- of Spark-database, is de gebruiker mogelijk niet gemachtigd om de database te openen en te lezen. Een gebruiker met de machtiging CONTROL SERVER moet volledige toegang hebben tot alle databases. Als beperkte machtiging kunt u PROBEREN VERBINDING TE MAKEN MET ELKE DATABASE en ALLE GEBRUIKERS SECURABLES SELECTEREN.
SQL-gebruiker heeft geen toegang tot Dataverse-tabellen
Dataverse-tabellen hebben toegang tot opslag met behulp van de Microsoft Entra-identiteit van de beller. Een SQL-gebruiker met hoge machtigingen kan proberen gegevens uit een tabel te selecteren, maar de tabel heeft geen toegang tot Dataverse-gegevens. Dit scenario wordt niet ondersteund.
Aanmeldingsfouten van Microsoft Entra-service-principal wanneer SPI een roltoewijzing maakt
Als u een roltoewijzing wilt maken voor een service-principal-id (SPI) of Microsoft Entra-app met behulp van een andere SPI, of als u er al een hebt gemaakt en u zich niet kunt aanmelden, krijgt u waarschijnlijk de volgende fout: Login error: Login failed for user '<token-identified principal>'.
Voor service-principals moet de aanmelding worden gemaakt met een toepassings-id als een beveiligings-id (SID), niet met een object-id. Er is een beperking voor service-principals bekend, waardoor Azure Synapse de toepassings-id niet kan ophalen uit Microsoft Graph wanneer er een roltoewijzing voor een andere SPI of app wordt gemaakt.
Oplossing 1
Ga naar Azure Portal>Synapse Studio>Manage>Access Control en voeg handmatig Synapse Administrator of Synapse SQL Administrator toe voor de gewenste service-principal.
Oplossing 2
U moet handmatig een juiste aanmelding maken met SQL-code:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Oplossing 3
U kunt ook een Azure Synapse-beheerder van een service-principal instellen met behulp van PowerShell. U moet de Az.Synapse-module hebben geïnstalleerd.
De oplossing is het gebruik van de cmdlet New-AzSynapseRoleAssignment met -ObjectId "parameter". Geef in dat parameterveld de toepassings-id op in plaats van de object-id met behulp van de referenties van de azure-service-principal van de werkruimtebeheerder.
PowerShell-script:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Validatie
Maak verbinding met het serverloze SQL-eindpunt en controleer of de externe aanmelding met SID (app_id_to_add_as_admin in het vorige voorbeeld) is gemaakt:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Of probeer u aan te melden bij het serverloze SQL-eindpunt met behulp van de ingestelde beheer-app.
Beperkingen
Sommige algemene systeembeperkingen kunnen van invloed zijn op uw workload:
| Eigenschappen | Beperking |
|---|---|
| Maximum aantal Azure Synapse-werkruimten per abonnement | Zie limieten. |
| Maximum aantal databases per serverloze pool | 100 (niet inclusief databases die zijn gesynchroniseerd vanuit Apache Spark-pool). |
| Maximum aantal databases dat is gesynchroniseerd vanuit een Apache Spark-pool | Niet beperkt. |
| Maximum aantal databaseobjecten per database | De som van het aantal objecten in een database mag niet groter zijn dan 2.147.483.647. Zie beperkingen in de SQL Server-database-engine. |
| Maximale lengte van id's in tekens | 128. Zie beperkingen in de SQL Server-database-engine. |
| Maximale queryduur | 30 minuten. |
| Maximale grootte van de resultatenset | Maximaal 400 GB gedeeld tussen gelijktijdige query's. |
| Maximale gelijktijdigheid | Niet beperkt en is afhankelijk van de complexiteit van de query en de hoeveelheid gescande gegevens. Een serverloze SQL-pool kan gelijktijdig 1000 actieve sessies verwerken die lichtgewicht query's uitvoeren. De getallen nemen af als de query's complexer zijn of een grotere hoeveelheid gegevens scannen, dus in dat geval kunt u overwegen om gelijktijdigheid te verlagen en query's uit te voeren gedurende een langere periode, indien mogelijk. |
| Maximale grootte van externe tabelnaam | 100 tekens. |
Kan geen database maken in een serverloze SQL-pool
Serverloze SQL-pools hebben beperkingen en u kunt niet meer dan 100 databases per werkruimte maken. Als u objecten wilt scheiden en isoleren, gebruikt u schema's.
Als u de fout CREATE DATABASE failed. User database limit has been already reached krijgt dat u het maximum aantal databases hebt gemaakt dat in één werkruimte wordt ondersteund.
U hoeft geen afzonderlijke databases te gebruiken om gegevens voor verschillende tenants te isoleren. Alle gegevens worden extern opgeslagen op een data lake en Azure Cosmos DB. De metagegevens, zoals tabellen, weergaven en functiedefinities, kunnen worden geïsoleerd met behulp van schema's. Isolatie op basis van schema's wordt ook gebruikt in Spark, waarbij databases en schema's dezelfde concepten zijn.