Dataverse-gegevens opnemen met Azure Data Factory
Na het exporteren van gegevens uit Microsoft Dataverse naar Azure Data Lake Storage Gen2 met Azure Synapse Link for Dataverse kunt u Azure Data Factory gebruiken om gegevensstromen te maken, uw gegevens te transformeren en analyses uit te voeren.
Notitie
Azure Synapse Link for Dataverse werd voorheen Exporteren naar data lake genoemd. De service is met ingang van mei 2021 hernoemd en gaat door met het exporteren van gegevens naar Azure Data Lake en Azure Synapse Analytics.
In dit artikel wordt beschreven hoe u de volgende taken kunt uitvoeren:
Stel het Data Lake Storage Gen2-opslagaccount in met de Dataverse-gegevens als bron in een Data Factory-gegevensstroom.
Transformeer de Dataverse-gegevens in Data Factory met een gegevensstroom.
Stel het Data Lake Storage Gen2-opslagaccount in met de Dataverse-gegevens als sink in een Data Factory-gegevensstroom.
Voer uw gegevensstroom uit door een pipeline te maken.
Vereisten
In dit gedeelte worden de vereisten beschreven die nodig zijn om geëxporteerde Dataverse-gegevens op te nemen met Data Factory.
Azure-rollen. Het gebruikersaccount dat wordt gebruikt om in te loggen bij Azure, moet van een lid zijn met de rol inzender of eigenaar, of van een beheerder van het Azure-abonnement. Als u de machtigingen wilt zien die u in het abonnement hebt, gaat u naar de Azure-portal, selecteert u uw gebruikersnaam in de rechterbovenhoek, ... en vervolgens Mijn machtigingen. Als u toegang hebt tot meerdere abonnementen, selecteert u het juiste. Als u onderliggende resources voor Data Factory in de Azure-portal wilt maken en beheren—inclusief gegevenssets, gekoppelde services, pipelines, triggers en integratieruntimes—moet u de rol Data Factory-inzender hebben op het niveau van de resourcegroep of hoger.
Azure Synapse Link for Dataverse. Deze handleiding gaat ervan uit dat u al Dataverse-gegevens hebt geëxporteerd met behulp van Azure Synapse Link for Dataverse. In dit voorbeeld worden de accounttabelgegevens geëxporteerd naar het data lake.
Azure Data Factory. In deze handleiding wordt ervan uitgegaan dat u al een data factory hebt gemaakt onder hetzelfde abonnement en dezelfde resourcegroep als het opslagaccount met de geëxporteerde Dataverse-gegevens.
Stel het Data Lake Storage Gen2-opslagaccount in als een bron
Open Azure Data Factory en selecteer de data factory die deel uitmaakt van hetzelfde abonnement en dezelfde resourcegroep als het opslagaccount met uw geëxporteerde Dataverse-gegevens. Selecteer vervolgens Gegevensstroom maken vanaf de startpagina.
Schakel de modus Foutopsporing in gegevensstroom in en selecteer de gewenste tijd voor Tijd tot live. Dit kan 10 minuten duren, maar u kunt doorgaan met de volgende stappen.

Selecteer Bron toevoegen.

Onder Broninstellingen doet u het volgende:
- Naam uitvoerstream: voer de gewenste naam in.
- Brontype: selecteer Inline.
- Inline gegevenssettype: selecteer Common Data Model.
- Gekoppelde service: selecteer het opslagaccount in het vervolgkeuzemenu en koppel vervolgens een nieuwe service door uw abonnementsgegevens op te geven en alle standaardconfiguraties te behouden.
- Bemonstering: als u al uw gegevens wilt gebruiken, selecteert u Uitschakelen.
Onder Bronopties doet u het volgende:
Indeling Metagegevens: selecteer Model.json.
Hoofdlocatie: voer de containernaam in het eerste vak in (Container) of blader voor de containernaam en selecteer OK.
Entiteit: Voer de tabelnaam in of blader voor de tabel.

Controleer het tabblad Projectie om ervoor te zorgen dat uw schema met succes is geïmporteerd. Als u geen kolommen ziet, selecteert u Schema-opties en schakelt u de optie Leid afwijkende kolomtypen af in. Configureer de opmaakopties zodat ze overeenkomen met uw gegevensset en selecteer vervolgens Toepassen.
U kunt uw gegevens inzien op het tabblad Gegevensvoorbeeld om er zeker van te zijn dat het maken van de bron volledig en nauwkeurig was.
Uw Dataverse-gegevens transformeren
Na het instellen van de geëxporteerde Dataverse-gegevens in het Azure Data Lake Storage Gen2-account als bron in de Data Factory-gegevensstroom zijn er veel mogelijkheden om uw data te transformeren. Meer informatie: Azure Data Factory
Volg deze instructies om een rangschikking te maken voor elke rij op het veld omzet van de accounttabel.
Selecteer + in de rechterbenedenhoek van de vorige transformatie en zoek en selecteer Rang.
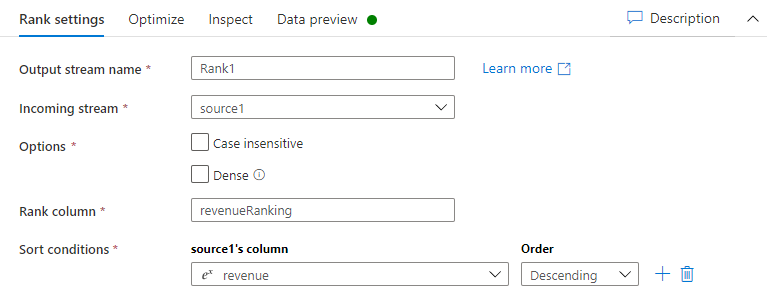
Ga op het tabblad Rang-instellingen als volgt te werk:
Naam uitvoerstroom: Voer de gewenste naam in, bijvoorbeeld Rang1.
Inkomende stroom: selecteer de gewenste bronnaam. In dit geval de bronnaam uit de vorige stap.
Opties: Laat de opties uitgeschakeld.
Rangkolom: Voer de naam in van de gegenereerde rangkolom.
Sorteerrwaarden: selecteer de omzet-kolom en sorteer op aflopende volgorde.
U kunt uw gegevens inzien op het tabblad Gegevensvoorbeeld waar u de nieuwe revenueRank-kolom op de meest rechtse positie ziet.
Stel het Data Lake Storage Gen2-opslagaccount in als een sink
Uiteindelijk moet u een sink instellen voor uw gegevensstroom. Volg deze instructies om uw getransformeerde gegevens als een tekstbestand met scheidingstekens in het data lake te plaatsen.
Selecteer + in de rechterbenedenhoek van de vorige transformatie en zoek en selecteer Sink.
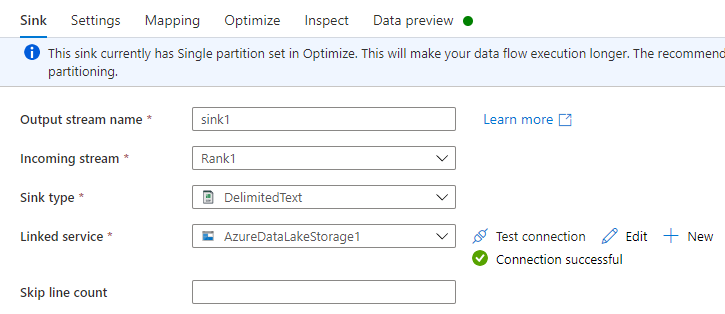
Doe het volgende op het tabblad Sink:
Naam uitvoerstream: voer de gewenste naam in, zoals Sink1.
Inkomende stroom: selecteer de gewenste bronnaam. In dit geval de bronnaam uit de vorige stap.
Type sink: Selecteer Tekst met scheidingstekens.
Gekoppelde service: selecteer uw Data Lake Storage Gen2-opslagcontainer met de gegevens die u hebt geëxporteerd met behulp van de Azure Synapse Link for Dataverse-service.
Doe het volgende op het tabblad Instellingen:
Mappad: voer de containernaam in het eerste vak in (Bestandssysteem) of blader voor de containernaam en selecteer OK.
Bestandsnaamoptie: Selecteer Uitvoer naar één bestand.
Uitvoer naar één bestand: Voer een bestandsnaam in, zoals ADFOutput
Laat alle andere standaardinstellingen staan.
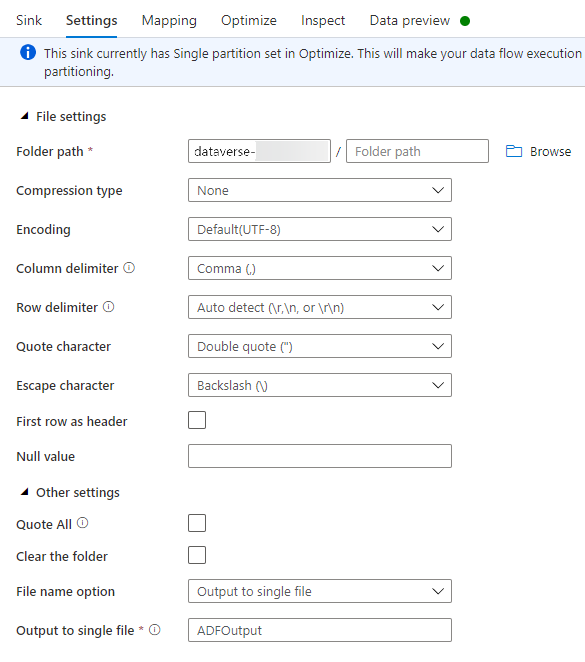
Stel op het tabblad Optimaliseren Partitie-optie in op Eén partitie.
U kunt uw gegevens inzien op het tabblad Gegevensvoorbeeld.
Uw gegevensstroom uitvoeren
Selecteer in het linkerdeelvenster onder Factory-resources + en vervolgens Pipeline.

Selecteer onder Activiteiten Verplaatsen en transformeren en sleep vervolgens Gegevensstroom naar de werkruimte.
Selecteer Bestaande gegevensstroom gebruiken en selecteer de gegevensstroom die u in de vorige stappen hebt gemaakt.
Selecteer Foutopsporing in de opdrachtbalk.
Blijf de gegevensstroom uitvoeren totdat in de onderste weergave wordt aangegeven dat deze is voltooid. Dit kan enkele minuten duren.
Ga naar de opslagcontainer van de uiteindelijke bestemming en zoek het getransformeerde tabelgegevensbestand.
Zie ook
Azure Synapse Link for Dataverse configureren met Azure Data Lake
Dataverse-gegevens analyseren in Azure Data Lake Storage Gen2 met Power BI
Notitie
Laat ons uw taalvoorkeuren voor documentatie weten! Beantwoord een korte enquête. (houd er rekening mee dat deze in het Engels is)
De enquête duurt ongeveer zeven minuten. Er worden geen persoonlijke gegevens verzameld (privacyverklaring).