High-densitysampling van lijnen in Power BI
Het sampling-algoritme in Power BI verbetert visuals die high-densitygegevens samplen. U kunt bijvoorbeeld een lijndiagram maken op basis van de verkoopresultaten van uw winkels, waarbij elke winkel elk jaar meer dan 10.000 verkoopbevestigingen heeft. Een lijndiagram van dergelijke verkoopgegevens zou voorbeeldgegevens uit de gegevens voor elk archief bevatten en een lijndiagram met meerdere reeksen maken dat de onderliggende gegevens vertegenwoordigt. Zorg ervoor dat u een zinvolle weergave van die gegevens selecteert om te laten zien hoe de verkoop in de loop van de tijd varieert. Deze procedure is gebruikelijk bij het visualiseren van high-densitygegevens. De details van high-densitygegevenssampling worden beschreven in dit artikel.
Notitie
Het high-densitysampling-algoritme dat in dit artikel wordt beschreven, is beschikbaar in Power BI Desktop en de Power BI-service.
Hoe high-densitysampling van lijnen werkt
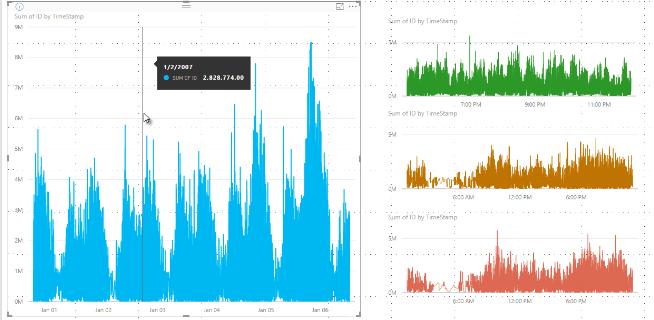
Eerder heeft Power BI een verzameling voorbeeldgegevenspunten geselecteerd in het volledige bereik van onderliggende gegevens op een deterministische manier. Met high-densitygegevens in een visual die één kalenderjaar beslaat, kunnen er bijvoorbeeld 350 voorbeeldgegevenspunten worden weergegeven in de visual, die elk zijn geselecteerd om ervoor te zorgen dat het volledige gegevensbereik in de visual wordt weergegeven. Als u wilt weten hoe dit gebeurt, stelt u zich een aandelenkoers voor een periode van één jaar voor en selecteert u 365 gegevenspunten om een visual voor een lijndiagram te maken. Dat is één gegevenspunt voor elke dag.
In die situatie zijn er veel waarden voor een aandelenkoers binnen elke dag. Natuurlijk is er een dagelijks hoog en laag, maar die kunnen zich op elk moment tijdens de dag voordoen wanneer de beurs open is. Als voor high-densitysampling van lijnen de onderliggende gegevensmonsters om 10:30 uur en 12:00 uur per dag zijn genomen, krijgt u een representatieve momentopname van de onderliggende gegevens, zoals de prijs om 10:30 uur en 12:00 uur. De momentopname legt echter mogelijk niet de werkelijke hoge en lage aandelenkoers vast voor dat representatieve gegevenspunt die dag. In die situatie en andere is de steekproef representatief voor de onderliggende gegevens, maar legt deze niet altijd belangrijke punten vast, wat in dit geval de hoogste en laagste koers van de dag zou zijn.
High-densitygegevens worden per definitie genomen om redelijk snel visualisaties te maken die reageren op interactiviteit. Te veel gegevenspunten in een visual kunnen deze verpesten en kunnen de zichtbaarheid van trends afleiden. Hoe de gegevens worden bemonsterd, is wat het maken van het sampling-algoritme aanstuurt om de beste visualisatie-ervaring te bieden. In Power BI Desktop biedt het algoritme de beste combinatie van reactiesnelheid, weergave en duidelijk behoud van belangrijke punten in elk tijdssegment.
Hoe het nieuwe algoritme voor lijnsampling werkt
Het algoritme voor high-densitysampling van lijnen is beschikbaar voor lijndiagram- en vlakdiagramvisuals met een doorlopende x-as.
Voor een high-densityvisual segmenteert Power BI uw gegevens op intelligente wijze in segmenten met hoge resolutie en kiest u vervolgens belangrijke punten om elk segment weer te geven. Dit proces voor het segmenteren van gegevens met een hoge resolutie is afgestemd om ervoor te zorgen dat de resulterende grafiek visueel niet te onderscheiden is van het weergeven van alle onderliggende gegevenspunten, maar sneller en interactiever is.
Minimum- en maximumwaarden voor high-densitylijnvisuals
Voor elke visualisatie gelden de volgende beperkingen:
3500 is het maximum aantal gegevenspunten dat op de meeste visuals wordt weergegeven, ongeacht het aantal onderliggende gegevenspunten of reeksen, zie uitzonderingen in de volgende lijst. Als u bijvoorbeeld 10 reeksen met elk 350 gegevenspunten hebt, heeft de visual de maximale totale gegevenspuntenlimiet bereikt. Als u één reeks hebt, kan het maximaal 3500 gegevenspunten bevatten als het algoritme denkt dat de beste steekproeven voor de onderliggende gegevens zijn.
Er is maximaal 60 reeksen voor elke visual. Als u meer dan 60 reeksen hebt, kunt u de gegevens opsplitsen en meerdere visuals met elk 60 of minder reeksen maken. Het is raadzaam om een slicer te gebruiken om alleen segmenten van de gegevens weer te geven, maar alleen voor bepaalde reeksen. Als u bijvoorbeeld alle subcategorieën in de legenda weergeeft, kunt u een slicer gebruiken om te filteren op de algehele categorie op dezelfde rapportpagina.
Het maximum aantal gegevenslimieten is hoger voor de volgende typen visuals. Dit zijn uitzonderingen op de limiet van 3500 gegevenspunten:
- Maximaal 150.000 gegevenspunten voor R-visuals.
- 30.000 gegevenspunten voor Azure Map-visuals.
- 10.000 gegevenspunten voor sommige configuraties van spreidingsdiagrammen (spreidingsdiagrammen zijn standaard ingesteld op 3500).
- 3500 voor alle andere visuals met high-densitysampling. Sommige andere visuals visualiseren mogelijk meer gegevens, maar ze gebruiken geen steekproeven.
Deze parameters zorgen ervoor dat visuals in Power BI Desktop snel worden weergegeven, reageren op interactie met gebruikers en niet leiden tot onnodige rekenoverhead op de computer die de visual weergeeft.
Representatieve gegevenspunten evalueren voor high-densitylijnvisuals
Wanneer het aantal onderliggende gegevenspunten de maximumgegevenspunten overschrijdt die in de visual kunnen worden weergegeven, begint een proces dat binning wordt genoemd. Met binning worden de onderliggende gegevens onderverdeeld in groepen met de naam bins en worden deze bins vervolgens iteratief verfijnd.
Het algoritme maakt zoveel mogelijk bins om de grootste granulariteit voor de visual te maken. Binnen elke bin vindt het algoritme de minimum- en maximumgegevenswaarde om ervoor te zorgen dat belangrijke en significante waarden, zoals uitbijters, worden vastgelegd en weergegeven in de visual. Op basis van de resultaten van de binning en de daaropvolgende evaluatie van de gegevens door Power BI wordt de minimale resolutie voor de x-as voor de visual bepaald om maximale granulariteit voor de visual te garanderen.
Zoals eerder vermeld, is de minimale granulariteit voor elke reeks 350 punten en is het maximum 3500 voor de meeste visuals. De uitzonderingen worden vermeld in de vorige alinea's.
Elke bin wordt vertegenwoordigd door twee gegevenspunten, die de representatieve gegevenspunten van de bin in de visual worden. De gegevenspunten zijn de hoge en lage waarde voor die bin. Door het hoog en laag te selecteren, zorgt het binning-proces ervoor dat elke belangrijke hoge waarde of significante lage waarde wordt vastgelegd en weergegeven in de visual.
Als dat lijkt op een groot aantal analyses om ervoor te zorgen dat de incidentele uitbijter wordt vastgelegd en correct wordt weergegeven in de visual, bent u juist. Dat is de exacte reden voor het algoritme en het binning-proces.
Knopinfo en high-densitysampling van lijnen
Het is belangrijk om te weten dat dit binning-proces, wat resulteert in de minimum- en maximumwaarde in een bepaalde bin die wordt vastgelegd en weergegeven, van invloed kan zijn op de wijze waarop knopinfo gegevens weergeeft wanneer u de muisaanwijzer over de gegevenspunten beweegt. Als u wilt uitleggen hoe en waarom dit gebeurt, gaan we terug naar ons voorbeeld over aandelenkoersen.
Stel dat u een visual maakt op basis van de aandelenkoers en dat u twee verschillende aandelen vergelijkt, die beide gebruikmaken van high-densitysampling. De onderliggende gegevens voor elke reeks bevatten veel gegevenspunten. Stel dat u de aandelenkoers elke seconde van de dag vastlegt. Het high-densitysampling-algoritme voor lijnen voert binning uit voor elke reeks onafhankelijk van de andere reeksen.
Stel nu dat het eerste aandeel tegen 12:02 uur in prijs springt en vervolgens 10 seconden later snel terugvalt. Dat is een belangrijk gegevenspunt. Wanneer binning plaatsvindt voor dat aandeel, is de hoog om 12:02 een representatief gegevenspunt voor die bin.
Voor het tweede aandeel was 12:02 echter geen hoog of laag in de bin die die tijd bevatte. Misschien is het hoog en laag voor de bin met 12:02 drie minuten later opgetreden. Wanneer het lijndiagram wordt gemaakt en u de muisaanwijzer boven 12:02 houdt, ziet u een waarde in de knopinfo voor het eerste aandeel. Dit komt doordat deze om 12:02 is gesprongen en die waarde is geselecteerd als het hoge gegevenspunt van die bin. U ziet echter geen waarde in de knopinfo om 12:02 voor het tweede aandeel. Dat komt doordat het tweede aandeel geen hoog of laag had voor de bin die 12:02 bevatte. Er zijn dus geen gegevens om de tweede voorraad om 12:02 weer te geven en daarom worden er geen knopinfogegevens weergegeven.
Deze situatie treedt regelmatig op met knopinfo. De hoge en lage waarden voor een specifieke bin komen waarschijnlijk niet perfect overeen met de gelijkmatig geschaalde x-aswaardepunten en de knopinfo geeft de waarde niet weer.
High-densitysampling van lijnen inschakelen
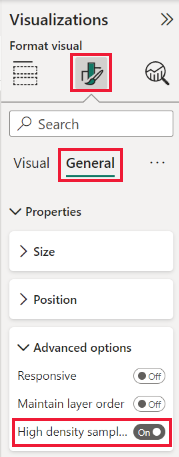
Het algoritme is standaard ingeschakeld. Als u deze instelling wilt wijzigen, gaat u naar het opmaakvenster , in de kaart Algemeen en onderaan ziet u de schuifregelaar voor high-densitysampling . Selecteer de schuifregelaar om in of uit te schakelen.
Overwegingen en beperkingen
Het algoritme voor high-densitysampling van lijnen is een belangrijke verbetering in Power BI, maar er zijn enkele overwegingen die u moet weten wanneer u werkt met high-densitywaarden en -gegevens.
Vanwege een verhoogde granulariteit en het binning-proces kan knopinfo alleen een waarde weergeven als de representatieve gegevens zijn uitgelijnd met de cursor. Zie de sectie Tooltips en high-densitysampling van lijnen in dit artikel voor meer informatie.
Wanneer de grootte van een algemene gegevensbron te groot is, elimineert het algoritme reeksen (legenda-elementen) om de maximale beperking voor het importeren van gegevens mogelijk te maken.
- In deze situatie rangschikt het algoritme legendareeks alfabetisch, waarbij de lijst met legenda-elementen in alfabetische volgorde wordt gestart totdat het maximum voor het importeren van gegevens is bereikt en er niet meer reeksen worden geïmporteerd.
Wanneer een onderliggende gegevensset meer dan 60 reeksen heeft, wordt het maximum aantal reeksen door het algoritme alfabetisch gerangschikt en worden reeksen buiten de 60e alfabetische volgorde weggenomen.
Als de waarden in de gegevens niet van het type numeriek of datum/tijd zijn, gebruikt Power BI het algoritme niet en wordt het vorige, niet-high-densitysampling-algoritme hersteld.
De instelling Items zonder gegevens weergeven wordt niet ondersteund met het algoritme.
Het algoritme wordt niet ondersteund wanneer u een liveverbinding gebruikt met een model dat wordt gehost in SQL Server Analysis Services versie 2016 of eerder. Het wordt ondersteund in modellen die worden gehost in Power BI of Azure Analysis Services.