Concepten van schaalbaarheid
Voordat u een schaaloplossing vindt, moet u weten wat schaalbaarheid is en hoe deze van toepassing is op Kubernetes-toepassingen.
In deze les bekijken we enkele schaalbaarheidsconcepten.
Schaalbaarheid
Schaalbaarheid beschrijft de mogelijkheid van een toepassing of systeem om een toenemende hoeveelheid werk af te handelen door er meer resources aan toe te voegen.
In ons voorbeeldscenario is de hoeveelheid werk met een toename het aantal klantaanvragen. De hoeveelheid toegevoegde resources kan op twee manieren worden weergegeven: verticale schaalbaarheid en horizontale schaalbaarheid.
Verticale schaalbaarheid
Verticale schaalbaarheid of omhoog schalen verwijst naar het schalen van een systeem door meer fysieke resources toe te voegen, zoals geheugen of CPU-vermogen. Als de website van uw bedrijf bijvoorbeeld te veel geheugen verbruikt, kunt u uw VM-exemplaar bijwerken om meer geheugen op te nemen terwijl dezelfde onderliggende toepassing behouden blijft.
Kortom, het verticaal schalen omvat het verhogen van de VM-grootte terwijl het aantal toepassingen hetzelfde blijft. Deze benadering is waardevol als u monolithische toepassingen hebt waarvoor veel rekenkracht is vereist, maar die te kostbaar zijn om in kleinere onderdelen op te splitsen. Deze toepassingen worden meestal gehost in VM's in plaats van gedistribueerde systemen.
Ondanks een beter beheersbare kosten kunnen zeer grote VM's erg duur worden. De kosten voor het toevoegen van meer rekenkracht zijn hoger dan de kosten voor het dupliceren van kleine VM's. Er is een bovengrens voor het aantal resources dat u aan één VIRTUELE machine kunt toevoegen. Dit betekent dat u de VIRTUELE machine uiteindelijk moet dupliceren zodra u de bovengrens bereikt.
Horizontale schaalbaarheid
Horizontale schaalbaarheid, of uitschalen, verwijst naar het schalen van een systeem door de toepassing te dupliceren en de belasting over de toepassingsexemplaren te verdelen.
Horizontaal schalen is waardevol voor gedistribueerde toepassingen, zoals toepassingen die zijn geïmplementeerd in AKS en staatloze systemen, omdat u meerdere containers met dezelfde toepassing in één VIRTUELE machine kunt instellen. Door uit te schalen kunt u de meeste resources extraheren terwijl u betaalt voor één virtuele machine.
In ons voorbeeldscenario is uw bedrijfssite staatloos. Dit betekent dat uitschalen de beste actie is. Kubernetes biedt out-of-the-box een resource met de naam HorizontalPodAutoscaler (HPA) waarmee u uw implementaties kunt uitschalen.
Handmatige schaalbaarheid in Kubernetes
Voordat we de HPA behandelen, gaan we kijken hoe u een Kubernetes-toepassing handmatig kunt schalen.
Elke implementatie is gebonden aan een andere resource die een ReplicaSet wordt genoemd. Een ReplicaSet is verantwoordelijk voor het onderhouden van een 'gewenste replicastatus' en het schalen van de echte toepassing in of uit om de gewenste status hetzelfde te houden als de werkelijke status. U kunt het aantal replica's in een implementatie beheren via de spec.replicas sleutel in de implementatiespecificatie. Met deze sleutel stelt u het aantal gewenste replica's in de onderliggende ReplicaSet in en dwingt u de replicatiecontroller om dit aantal replica's op elk gewenst moment te behouden.
U kunt ook het aantal replica's in een implementatie beheren met de kubectl scale deploy/contoso-website --replicas <number> opdracht. Met deze opdracht wordt het aantal gewenste replica's in een implementatie dynamisch gewijzigd en wordt de toepassing in- of uitgeschaald.
HorizontalPodAutoscaler (HPA)
De HPA is de systeemeigen Kubernetes 1.8+ resource die horizontale schaalbaarheid biedt voor pods in het cluster. De API voor metrische gegevens wordt elke 30 seconden gecontroleerd op wijzigingen in het gewenste aantal replica's. Als het gewenste aantal replica's verschilt van het huidige aantal replica's, wordt de implementatie in- of uitgeschaald door de controllerbeheerder, die HPA-objecten beheert.
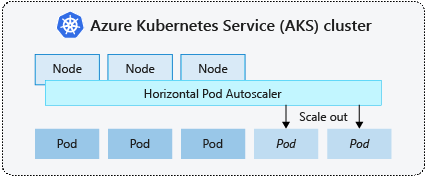
HPA's werken met de autoscaling API-groep in Kubernetes. Er zijn twee versies voor deze API-groep: v1 en v2. Met v1 de versie kan de implementatie alleen worden geschaald op basis van metrische CPU-gegevens. De v2 versie biedt systeemeigen bewaking van zowel CPU als geheugen. In deze module gebruiken we de v2 versie.
Elke HPA wordt gekoppeld aan een schaalreferentie, die is gedefinieerd in de spec.scaleTargetRef sleutel van het HPA-manifest. Deze schaalreferentie moet onderliggende pods hebben die moeten worden geschaald, anders werkt de HPA niet, omdat het niet mogelijk is om schaalaanpassing toe te passen op objecten die niet kunnen worden geschaald, zoals DaemonSets.
Het is belangrijk dat voor elke pod een resourceaanvraag is ingesteld in de specificatie. Het HPA-algoritme kan de metrische gegevens niet correct berekenen en het resourcegebruik bepalen zonder deze instelling. U kunt deze beperking instellen via de spec.template.spec.containers[].resources sleutel in het implementatiemanifest, zoals wordt weergegeven in het volgende voorbeeld:
spec:
template:
spec:
containers:
- resources:
requests:
cpu: 250m
memory: 256M
limits:
cpu: 500m
memory: 512M
Voorbeeld van HPA-manifest
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50