Normalisatie en standaardisatie
Functieschalen is een techniek waarmee het bereik van waarden van een functie wordt gewijzigd. Dit helpt modellen sneller en robuuster te leren.
Normalisatie versus standaardisatie
Normalisatie betekent dat waarden zo moeten worden geschaald dat ze allemaal binnen een bepaald bereik passen, meestal 0-1. Als u bijvoorbeeld een lijst hebt met leeftijden van 0, 50 en 100 jaar, kunt u normaliseren door de leeftijden te delen door 100, zodat uw waarden 0, 0,5 en 1 zijn.
Standaardisatie is vergelijkbaar, maar in plaats daarvan trekken we het gemiddelde (ook wel het gemiddelde genoemd) van de waarden af en delen we door de standaarddeviatie. Als u niet bekend bent met de standaarddeviatie, hoeft u zich geen zorgen te maken, betekent dit dat na standaardisatie onze gemiddelde waarde nul is en dat ongeveer 95% van de waarden tussen -2 en 2 ligt.
Er zijn andere manieren om gegevens te schalen, maar de nuances hiervan gaan verder dan wat we nu moeten weten. Laten we eens kijken waarom we normalisatie of standaardisatie toepassen.
Waarom moeten we schalen?
Er zijn veel redenen waarom we gegevens normaliseren of standaardiseren vóór de training. U kunt deze gemakkelijker begrijpen met een voorbeeld. Stel dat we een model willen trainen om te voorspellen of een hond succesvol zal zijn in het werken in de sneeuw. Onze gegevens worden in de volgende grafiek weergegeven als puntjes en de trendlijn die we proberen te vinden, wordt weergegeven als een ononderbroken lijn:
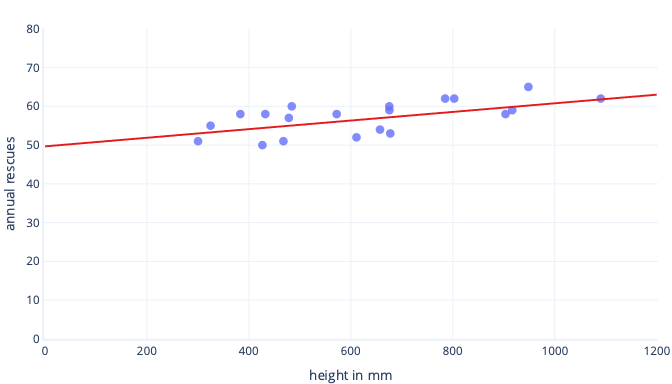
Schalen geeft leren een beter uitgangspunt
De optimale lijn in de voorgaande grafiek heeft twee parameters: het snijpunt, dat 50 is, de lijn op x=0, en de helling, die 0,01 is; elke 1000 millimeter verhoogt de reddingen met 10. Laten we ervan uitgaan dat we beginnen met trainen met initiële schattingen van 0 voor beide parameters.
Als onze trainingsiteraties parameters gemiddeld ongeveer 0,01 per iteratie wijzigen, duurt het ten minste 5000 iteraties voordat het snijpunt wordt gevonden: 50 / 0,01 = 5000 iteraties. Standaardisatie kan dit optimale snijpunt dichter bij nul brengen, wat betekent dat we het veel sneller kunnen vinden. Als we bijvoorbeeld het gemiddelde aftrekken van ons label (jaarlijkse reddingen) en onze functiehoogte, is het snijpunt -0,5, niet 50, wat we ongeveer 100 keer sneller kunnen vinden.
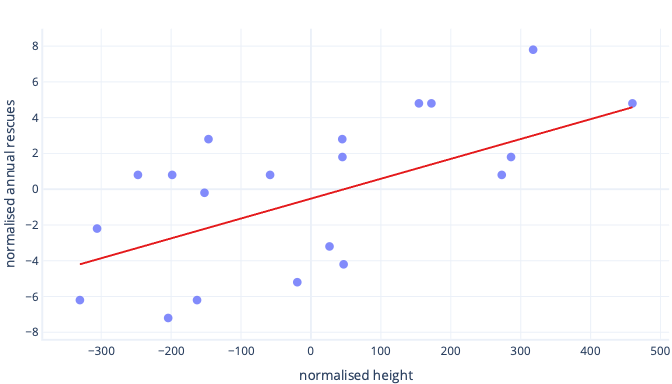
Er zijn andere redenen waarom complexe modellen erg traag kunnen worden getraind wanneer de eerste schatting ver van de markering ligt, maar de oplossing is nog steeds hetzelfde: verschoven functies naar iets dat dichter bij de eerste schatting ligt.
Met standaardisatie kunnen parameters met dezelfde snelheid worden getraind
In onze nieuwe offsetgegevens hebben we een ideale offset van -0,5 en een ideale helling van 0,01. Hoewel verschuivingen helpen om sneller te gaan, is het nog steeds veel langzamer om de offset te trainen dan om de helling te trainen. Dit kan dingen vertragen en de training instabiel maken.
Onze eerste schattingen voor verschuiving en helling zijn bijvoorbeeld beide nul. Als we onze parameters met ongeveer 0,1 bij elke iteratie wijzigen, vinden we de verschuiving snel, maar het zal erg moeilijk zijn om de juiste helling te vinden, omdat stijgingen in helling te groot zijn (0 + 0,1 > 0,01) en de ideale waarde kunnen overschrijden. We kunnen de aanpassingen kleiner maken, maar dit vertraagt hoe lang het duurt om het snijpunt te vinden.
Wat gebeurt er als we de functie van de hoogte schalen?
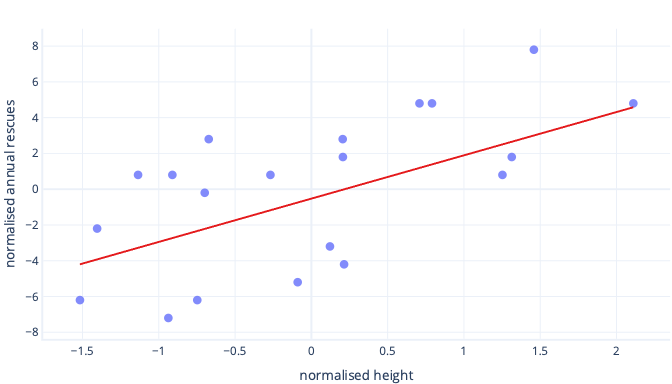
De helling van de lijn is nu 0,5. Let op de x-as. Ons optimale snijpunt van -0,5 en helling van 0,5 zijn dezelfde schaal! Het is nu eenvoudig om een redelijke stapgrootte te kiezen. Dit is hoe snel de parameters voor gradiëntafname worden bijgewerkt.
Schalen helpt bij meerdere functies
Wanneer we met meerdere functies werken, kan het hebben van deze functies op een andere schaal problemen veroorzaken bij het aanpassen, net zoals we zojuist zagen met de snijpunt- en hellingsvoorbeelden. Als we bijvoorbeeld een model trainen dat zowel hoogte in mm als gewicht in metrische tonnen accepteert, zullen veel soorten modellen moeite hebben om het belang van de gewichtsfunctie te waarderen, simpelweg omdat deze zo klein is ten opzichte van de hoogtefuncties.
Moet ik altijd schalen?
We hoeven niet altijd te schalen. Sommige soorten modellen, waaronder de voorgaande modellen met rechte lijnen, kunnen passen zonder een iteratieve procedure zoals gradiëntafname, dus ze vinden het niet erg dat functies de verkeerde grootte hebben. Andere modellen moeten wel worden geschaald om goed te trainen, maar hun bibliotheken voeren vaak automatisch functieschalen uit.
Over het algemeen zijn de enige echte nadelen van normalisatie of standaardisatie dat het moeilijker kan zijn om onze modellen te interpreteren en dat we iets meer code moeten schrijven. Daarom is het schalen van functies een standaardonderdeel van het maken van machine learning-modellen.