W tym artykule opisano zagadnienia dotyczące zarządzania danymi w architekturze mikrousług. Ponieważ każda mikrousługa zarządza własnymi danymi, integralność danych i spójność danych są kluczowymi wyzwaniami.
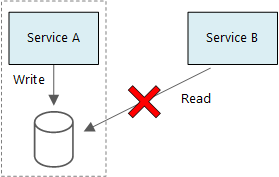
Podstawową zasadą dotyczącą mikrousług jest to, że każda usługa zarządza swoimi danymi. Dwie usługi nie powinny współużytkować magazynu danych. Zamiast tego każda usługa jest odpowiedzialna za własny prywatny magazyn danych, do którego inne usługi nie mogą uzyskać bezpośredniego dostępu.
Przyczyną tej reguły jest uniknięcie niezamierzonego sprzężenia między usługami, co może spowodować, że usługi współdzielą te same schematy danych bazowych. Jeśli istnieje zmiana schematu danych, zmiana musi być skoordynowana dla każdej usługi, która opiera się na tej bazie danych. Izolując magazyn danych każdej usługi, możemy ograniczyć zakres zmian i zachować elastyczność prawdziwie niezależnych wdrożeń. Innym powodem jest to, że każda mikrousługa może mieć własne modele danych, zapytania lub wzorce odczytu/zapisu. Użycie udostępnionego magazynu danych ogranicza możliwość optymalizacji magazynu danych dla danej usługi przez każdy zespół.
Takie podejście naturalnie prowadzi do trwałości wielolotowej — zastosowania wielu technologii przechowywania danych w jednej aplikacji. Jedna usługa może wymagać możliwości odczytu schematu bazy danych dokumentów. Inna może wymagać integralności referencyjnej dostarczonej przez program RDBMS. Każdy zespół jest bezpłatny, aby dokonać najlepszego wyboru dla swojej usługi.
Uwaga
Usługi mogą współużytkować ten sam fizyczny serwer bazy danych. Problem występuje, gdy usługi współużytkować ten sam schemat lub odczytywać i zapisywać w tym samym zestawie tabel bazy danych.
Wyzwania
Niektóre wyzwania wynikają z tego rozproszonego podejścia do zarządzania danymi. Po pierwsze może istnieć nadmiarowość w magazynach danych z tym samym elementem danych wyświetlanym w wielu miejscach. Na przykład dane mogą być przechowywane w ramach transakcji, a następnie przechowywane w innym miejscu na potrzeby analizy, raportowania lub archiwizowania. Zduplikowane lub partycjonowane dane mogą prowadzić do problemów z integralnością i spójnością danych. Gdy relacje danych obejmują wiele usług, nie można użyć tradycyjnych technik zarządzania danymi w celu wymuszenia relacji.
Tradycyjne modelowanie danych używa reguły "jednego faktu w jednym miejscu". Każda jednostka jest wyświetlana dokładnie raz w schemacie. Inne jednostki mogą zawierać odwołania do niego, ale nie zduplikowane. Oczywistą zaletą tradycyjnego podejścia jest to, że aktualizacje są wprowadzane w jednym miejscu, co pozwala uniknąć problemów ze spójnością danych. W architekturze mikrousług należy wziąć pod uwagę sposób propagacji aktualizacji w usługach oraz zarządzania spójnością ostateczną, gdy dane pojawiają się w wielu miejscach bez silnej spójności.
Podejścia do zarządzania danymi
Nie ma jednego podejścia, które jest poprawne we wszystkich przypadkach, ale poniżej przedstawiono pewne ogólne wytyczne dotyczące zarządzania danymi w architekturze mikrousług.
W miarę możliwości należy uwzględniać spójność ostateczną. Poznaj miejsca w systemie, w których potrzebna jest silna spójność lub transakcje ACID, oraz miejsca, w których spójność ostateczna jest akceptowalna.
Jeśli potrzebujesz gwarancji silnej spójności, jedna usługa może reprezentować źródło prawdy dla danej jednostki, która jest uwidaczniana za pośrednictwem interfejsu API. Inne usługi mogą przechowywać własną kopię danych lub podzbiór danych, który ostatecznie jest zgodny z danymi głównymi, ale nie jest uważany za źródło prawdy. Załóżmy na przykład, że system handlu elektronicznego ma usługę zamówienia klienta i usługę rekomendacji. Usługa rekomendacji może nasłuchiwać zdarzeń z usługi zamówienia, ale jeśli klient zażąda zwrotu kosztów, jest to usługa zamówienia, a nie usługa rekomendacji, która ma pełną historię transakcji.
W przypadku transakcji użyj wzorców, takich jak Nadzorca agenta harmonogramu i Transakcja wyrównywająca, aby zachować spójność danych w kilku usługach. Może być konieczne przechowywanie dodatkowego elementu danych, który przechwytuje stan jednostki pracy obejmującej wiele usług, aby uniknąć częściowej awarii między wieloma usługami. Na przykład zachowaj element roboczy w trwałej kolejce, gdy transakcja wieloetapowa jest w toku.
Przechowuj tylko dane wymagane przez usługę. Usługa może potrzebować tylko podzestawu informacji o jednostce domeny. Na przykład w kontekście wysyłki powiązanej musimy wiedzieć, który klient jest skojarzony z konkretnym dostarczaniem. Nie potrzebujemy jednak adresu rozliczeniowego klienta — zarządzanego przez kontekst ograniczony konta. Rozważnie myślenia o domenie i korzystaniu z podejścia DDD może pomóc tutaj.
Zastanów się, czy usługi są spójne i luźno powiązane. Jeśli dwie usługi nieustannie wymieniają ze sobą informacje, co skutkuje czatty interfejsami API, może być konieczne ponowne rysowanie granic usługi, scalając dwie usługi lub refaktoryzując ich funkcjonalność.
Użyj stylu architektury opartej na zdarzeniach. W tym stylu architektury usługa publikuje zdarzenie w przypadku zmian w jej modelach publicznych lub jednostkach. Zainteresowane usługi mogą subskrybować te zdarzenia. Na przykład inna usługa może użyć zdarzeń do skonstruowania zmaterializowanego widoku danych, który jest bardziej odpowiedni do wykonywania zapytań.
Usługa, która jest właścicielem zdarzeń, powinna opublikować schemat, który może służyć do automatyzowania serializacji i deserializacji zdarzeń, aby uniknąć ścisłego sprzężenia między wydawcami i subskrybentami. Rozważ użycie schematu JSON lub struktury, takiej jak Microsoft Bond, Protobuf lub Avro.
Na dużą skalę zdarzenia mogą stać się wąskim gardłem w systemie, dlatego rozważ użycie agregacji lub dzielenia na partie w celu zmniejszenia całkowitego obciążenia.
Przykład: wybieranie magazynów danych dla aplikacji Drone Delivery
W poprzednich artykułach z tej serii omówiono usługę dostarczania dronów jako działający przykład. Więcej informacji na temat scenariusza i odpowiedniej implementacji referencyjnej można znaleźć tutaj. Ten przykład jest idealny dla przemysłu lotniczego i lotniczego.
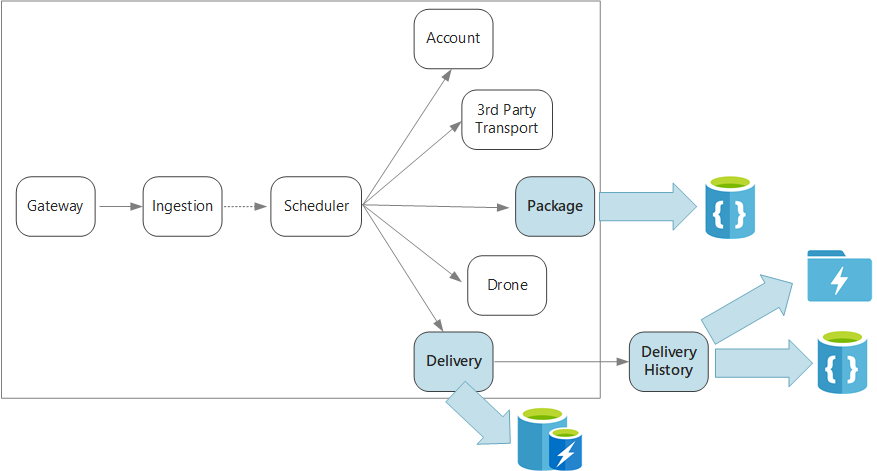
Aby podsumować, ta aplikacja definiuje kilka mikrousług do planowania dostaw za pomocą drona. Gdy użytkownik planuje nową dostawę, żądanie klienta zawiera informacje o dostawie, takie jak lokalizacje odbioru i wysyłki, oraz informacje o pakiecie, takie jak rozmiar i waga. Te informacje definiują jednostkę pracy.
Różne usługi zaplecza dbają o różne części informacji w żądaniu, a także mają różne profile odczytu i zapisu.
Usługa dostarczania
Usługa dostarczania przechowuje informacje o każdej dostawie, która jest obecnie zaplanowana lub w toku. Nasłuchuje zdarzeń z dronów i śledzi stan dostaw, które są w toku. Wysyła również zdarzenia domeny z aktualizacjami stanu dostarczania.
Oczekuje się, że użytkownicy będą często sprawdzać stan dostawy podczas oczekiwania na ich pakiet. W związku z tym usługa dostarczania wymaga magazynu danych, który podkreśla przepływność (odczyt i zapis) w magazynie długoterminowym. Ponadto usługa dostarczania nie wykonuje żadnych złożonych zapytań ani analiz, po prostu pobiera najnowszy stan dla danego dostarczania. Zespół usługi dostarczania wybrał usługę Azure Cache for Redis, aby uzyskać wysoką wydajność odczytu i zapisu. Informacje przechowywane w usłudze Redis są stosunkowo krótkotrwałe. Po zakończeniu dostarczania usługa Historia dostarczania jest systemem rekordów.
Usługa historii dostarczania
Usługa Historia dostarczania nasłuchuje zdarzeń stanu dostarczania z usługi dostarczania. Przechowuje te dane w magazynie długoterminowym. Istnieją dwa różne przypadki użycia dla tych danych historycznych, które mają różne wymagania dotyczące magazynu danych.
Pierwszy scenariusz polega na agregowaniu danych w celu analizy danych w celu zoptymalizowania firmy lub poprawy jakości usługi. Pamiętaj, że usługa Historia dostarczania nie wykonuje rzeczywistej analizy danych. Jest on odpowiedzialny tylko za pozyskiwanie i przechowywanie. W tym scenariuszu magazyn musi być zoptymalizowany pod kątem analizy danych w dużym zestawie danych przy użyciu podejścia schematu do odczytu w celu uwzględnienia różnych źródeł danych. Usługa Azure Data Lake Store jest dobrym rozwiązaniem w tym scenariuszu. Data Lake Store to system plików Apache Hadoop zgodny z rozproszonym systemem plików Hadoop (HDFS) i jest dostrojony pod kątem wydajności w scenariuszach analizy danych.
Drugi scenariusz umożliwia użytkownikom wyszukiwanie historii dostarczania po zakończeniu dostarczania. Usługa Azure Data Lake nie jest zoptymalizowana pod kątem tego scenariusza. Aby uzyskać optymalną wydajność, firma Microsoft zaleca przechowywanie danych szeregów czasowych w usłudze Data Lake w folderach podzielonych według daty. (Zobacz Dostrajanie usługi Azure Data Lake Store pod kątem wydajności). Jednak ta struktura nie jest optymalna do wyszukiwania poszczególnych rekordów według identyfikatora. Jeśli nie znasz również znacznika czasu, wyszukiwanie według identyfikatora wymaga skanowania całej kolekcji. W związku z tym usługa Historia dostarczania przechowuje również podzestaw danych historycznych w usłudze Azure Cosmos DB w celu szybszego wyszukiwania. Rekordy nie muszą pozostawać w usłudze Azure Cosmos DB na czas nieokreślony. Starsze dostawy można zarchiwizować — powiedzmy po miesiącu. Można to zrobić, uruchamiając okazjonalny proces wsadowy. Archiwizowanie starszych danych może obniżyć koszty usługi Cosmos DB, zachowując jednocześnie dostępne dane na potrzeby raportowania historycznego z usługi Data Lake.
Usługa pakietu
Usługa Package przechowuje informacje o wszystkich pakietach. Wymagania dotyczące magazynu dla pakietu to:
- Magazyn długoterminowy.
- Możliwość obsługi dużej liczby pakietów wymagających wysokiej przepływności zapisu.
- Obsługa prostych zapytań według identyfikatora pakietu. Brak złożonych sprzężeń ani wymagań dotyczących integralności referencyjnej.
Ponieważ dane pakietu nie są relacyjne, odpowiednia jest baza danych zorientowana na dokument, a usługa Azure Cosmos DB może osiągnąć wysoką przepływność przy użyciu kolekcji podzielonych na fragmenty. Zespół, który pracuje nad usługą Package, zna stos MEAN (MongoDB, Express.js, AngularJS i Node.js), dlatego wybierają interfejs API bazy danych MongoDB dla usługi Azure Cosmos DB. Dzięki temu mogą korzystać z istniejącego środowiska z bazą danych MongoDB, jednocześnie uzyskując korzyści z usługi Azure Cosmos DB, która jest zarządzaną usługą platformy Azure.
Następne kroki
Dowiedz się więcej o wzorcach projektowych, które mogą pomóc w ograniczeniu niektórych typowych wyzwań w architekturze mikrousług.