Konfigurowanie grupy trybu failover dla usługi Azure SQL Managed Instance
Dotyczy:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
W tym artykule przedstawiono sposób konfigurowania grupy trybu failover dla usługi Azure SQL Managed Instance przy użyciu witryny Azure Portal i programu Azure PowerShell.
Aby uzyskać pełny skrypt programu PowerShell umożliwiający utworzenie obu wystąpień w grupie trybu failover, zapoznaj się z artykułem Dodawanie wystąpienia do grupy trybu failover.
Wymagania wstępne
Weź pod uwagę następujące wymagania wstępne:
- Pomocnicze wystąpienie zarządzane musi być puste, a nie zawiera żadnych baz danych użytkowników.
- Obydwa wystąpienia usługi SQL Managed Instance muszą mieć tę samą warstwę usługi i ten sam rozmiar magazynu. Chociaż nie jest to wymagane, zdecydowanie zaleca się, aby dwa wystąpienia miały równy rozmiar obliczeniowy, aby upewnić się, że wystąpienie pomocnicze może trwale przetwarzać zmiany replikowane z wystąpienia podstawowego, w tym okresy szczytowej aktywności.
- Zakres adresów IP dla sieci wirtualnej wystąpienia podstawowego nie może pokrywać się z zakresem adresów sieci wirtualnej dla pomocniczego wystąpienia zarządzanego lub żadna inna sieć wirtualna równorzędna z podstawową lub pomocniczą siecią wirtualną.
- Podczas tworzenia pomocniczego wystąpienia zarządzanego należy określić identyfikator strefy DNS wystąpienia podstawowego jako wartość parametru
DnsZonePartner. Jeśli nie określisz wartości ,DnsZonePartneridentyfikator strefy jest generowany jako losowy ciąg, gdy pierwsze wystąpienie zostanie utworzone w każdej sieci wirtualnej, a ten sam identyfikator zostanie przypisany do wszystkich innych wystąpień w tej samej podsieci. Przypisanej strefy DNS nie można modyfikować. - Reguły sieciowych grup zabezpieczeń w wystąpieniu hostingu podsieci muszą mieć port 5022 (TCP) i zakres portów 11000-11999 (TCP) otwierania ruchu przychodzącego i wychodzącego dla połączeń z i do podsieci hostowania innego wystąpienia zarządzanego. Dotyczy to obu podsieci, hostowania wystąpienia podstawowego i pomocniczego.
- Sortowanie i strefa czasowa pomocniczego wystąpienia zarządzanego muszą być zgodne z podstawowym wystąpieniem zarządzanym.
- Wystąpienia zarządzane powinny być wdrażane w sparowanych regionach ze względu na wydajność. Wystąpienia zarządzane znajdujące się w regionach sparowanych geograficznie korzystają z znacznie większej szybkości replikacji geograficznej w porównaniu z nieparzystymi regionami.
Zakres przestrzeni adresowej
Aby sprawdzić przestrzeń adresową wystąpienia podstawowego, przejdź do zasobu sieci wirtualnej dla wystąpienia podstawowego i wybierz pozycję Przestrzeń adresowa w obszarze Ustawienia. Sprawdź zakres w obszarze Zakres adresów:
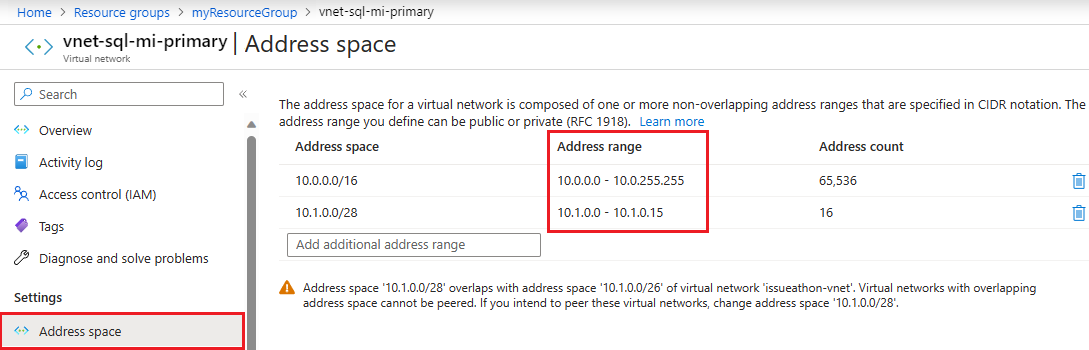
Określanie identyfikatora strefy wystąpienia podstawowego
Podczas tworzenia wystąpienia pomocniczego należy określić identyfikator strefy wystąpienia podstawowego jako DnsZonePartner.
Jeśli tworzysz wystąpienie pomocnicze w witrynie Azure Portal, na karcie Dodatkowe ustawienia w obszarze Replikacja geograficzna wybierz pozycję Tak , aby użyć jako pomocniczego trybu failover, a następnie wybierz wystąpienie podstawowe z listy rozwijanej:
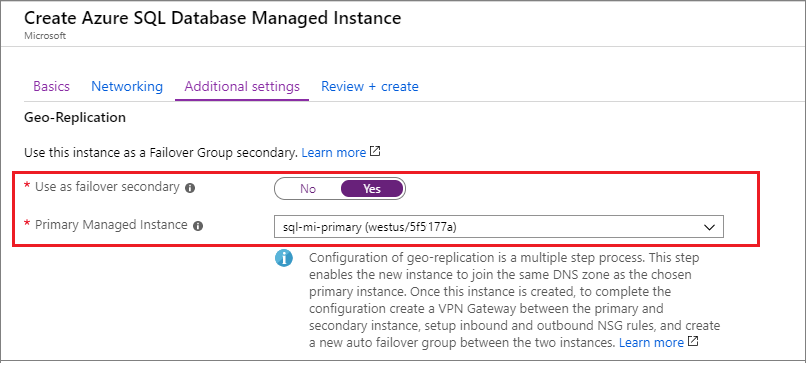
Włączanie łączności między wystąpieniami
Połączenie ivity między podsieciami sieci wirtualnej hostowania wystąpienia podstawowego i pomocniczego należy ustanowić w celu nieprzerwanego przepływu ruchu replikacji geograficznej. Istnieje wiele sposobów nawiązywania łączności między wystąpieniami zarządzanymi w różnych regionach świadczenia usługi Azure, w tym:
- Globalna komunikacja równorzędna sieci wirtualnych
- Azure ExpressRoute
- Bramy sieci VPN
Globalna komunikacja równorzędna sieci wirtualnych jest zalecana jako najbardziej wydajny i niezawodny sposób nawiązywania łączności między wystąpieniami w grupie trybu failover. Globalna komunikacja równorzędna sieci wirtualnych zapewnia połączenie prywatne o małych opóźnieniach i dużej przepustowości między równorzędną siecią wirtualną przy użyciu infrastruktury szkieletowej firmy Microsoft. W komunikacji między równorzędnymi sieciami wirtualnymi nie jest wymagany żaden publiczny Internet, bramy ani dodatkowe szyfrowanie.
Ważne
Alternatywne sposoby łączenia wystąpień obejmujących dodatkowe urządzenia sieciowe mogą komplikować rozwiązywanie problemów z łącznością lub szybkością replikacji, prawdopodobnie wymagających aktywnego zaangażowania administratorów sieci i potencjalnie znacznie przedłużającego czas rozwiązywania problemów.
Niezależnie od mechanizmu łączności istnieją wymagania, które muszą zostać spełnione, aby był możliwy przepływ ruchu replikacji geograficznej:
- Tabela tras i sieciowe grupy zabezpieczeń przypisane do podsieci wystąpienia zarządzanego nie są współużytkowane przez dwie równorzędne sieci wirtualne.
- Reguły sieciowej grupy zabezpieczeń (NSG) w podsieci hostowania wystąpienia podstawowego zezwalają:
- Ruch przychodzący na porcie 5022 i zakres portów 11000–11999 z podsieci obsługującej wystąpienie pomocnicze.
- Ruch wychodzący na porcie 5022 i zakres portów 11000-11999 do podsieci obsługującej wystąpienie pomocnicze.
- Reguły sieciowej grupy zabezpieczeń (NSG) w podsieci obsługującej wystąpienie pomocnicze zezwalają:
- Ruch przychodzący na porcie 5022 i zakres portów 11000–11999 z podsieci hostowania wystąpienia podstawowego.
- Ruch wychodzący na porcie 5022 i zakres portów 11000-11999 do podsieci obsługującej wystąpienie podstawowe.
- Zakresy adresów IP sieci wirtualnych hostowania wystąpienia podstawowego i pomocniczego nie mogą się nakładać.
- Nie ma pośredniego nakładania się zakresów adresów IP między sieciami wirtualnymi hostjącymi wystąpienie podstawowe i pomocnicze lub innymi sieciami wirtualnymi, z którymi są równorzędne za pośrednictwem lokalnej komunikacji równorzędnej sieci wirtualnej lub innych środków.
Ponadto, jeśli używasz innych mechanizmów zapewniających łączność między wystąpieniami niż zalecana globalna komunikacja równorzędna sieci wirtualnych, należy zapewnić następujące kwestie:
- Wszystkie używane urządzenia sieciowe, takie jak zapory lub wirtualne urządzenia sieciowe (WUS), nie blokują ruchu na portach wymienionych wcześniej.
- Routing jest poprawnie skonfigurowany i zastosowano uniknięcie routingu asymetrycznego.
- W przypadku wdrażania grup trybu failover w topologii sieci piasty i szprych między regionami ruch replikacji powinien przechodzić bezpośrednio między dwiema podsieciami wystąpienia zarządzanego, a nie kierowanymi przez sieci koncentratora. Pomaga uniknąć problemów z łącznością i szybkością replikacji.
- W witrynie Azure Portal przejdź do zasobu sieć wirtualna dla podstawowego wystąpienia zarządzanego.
- Wybierz pozycję Komunikacje równorzędne w obszarze Ustawienia, a następnie wybierz pozycję + Dodaj.
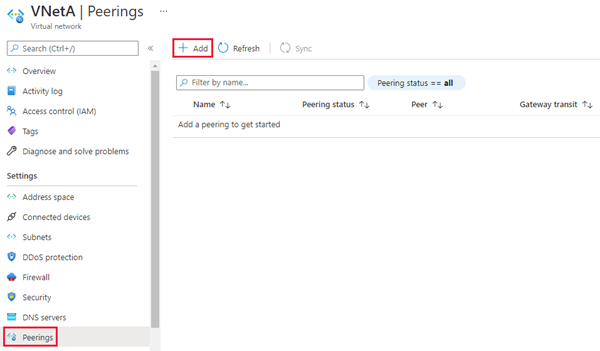
Wprowadź lub wybierz wartości następujących ustawień:
Ustawienia Opis Ta sieć wirtualna Nazwa łącza komunikacji równorzędnej Nazwa komunikacji równorzędnej musi być unikatowa w sieci wirtualnej. Ruch do zdalnej sieci wirtualnej Wybierz pozycję Zezwalaj (ustawienie domyślne), aby włączyć komunikację między dwiema sieciami wirtualnymi za pośrednictwem przepływu domyślnego VirtualNetwork. Włączenie komunikacji między sieciami wirtualnymi umożliwia zasobom połączonym z jedną z sieci wirtualnych komunikację ze sobą z taką samą przepustowością i opóźnieniem, jakby były połączone z tą samą siecią wirtualną. Cała komunikacja między zasobami w dwóch sieciach wirtualnych odbywa się za pośrednictwem sieci prywatnej platformy Azure.Ruch przekazywany z zdalnej sieci wirtualnej W tym samouczku będzie działać opcja Dozwolone (wartość domyślna) i Blokuj . Aby uzyskać więcej informacji, zobacz Tworzenie komunikacji równorzędnej Brama sieci wirtualnej lub serwer route server Wybierz pozycję Brak. Aby uzyskać więcej informacji na temat innych dostępnych opcji, zobacz Tworzenie komunikacji równorzędnej. Zdalna sieć wirtualna Nazwa łącza komunikacji równorzędnej Nazwa tej samej komunikacji równorzędnej, która ma być używana w sieci wirtualnej hostujące wystąpienie pomocnicze. Model wdrażania sieci wirtualnej Wybierz pozycję Resource Manager. Znam identyfikator zasobu Pozostaw to pole wyboru niezaznaczone. Subskrypcja Wybierz subskrypcję platformy Azure sieci wirtualnej hostujące wystąpienie pomocnicze, z którym chcesz się połączyć. Sieć wirtualna Wybierz sieć wirtualną hostująca wystąpienie pomocnicze, z którym chcesz się połączyć. Jeśli sieć wirtualna jest wyświetlana na liście, ale wyszarana, może to być spowodowane tym, że przestrzeń adresowa sieci wirtualnej nakłada się na przestrzeń adresową dla tej sieci wirtualnej. Jeśli przestrzenie adresowe sieci wirtualnej nakładają się na siebie, nie można ich połączyć za pomocą komunikacji równorzędnej. Ruch do zdalnej sieci wirtualnej Wybierz pozycję Zezwalaj (ustawienie domyślne) Ruch przekazywany z zdalnej sieci wirtualnej W tym samouczku będzie działać opcja Dozwolone (wartość domyślna) i Blokuj . Aby uzyskać więcej informacji, zobacz Tworzenie komunikacji równorzędnej. Brama sieci wirtualnej lub serwer route server Wybierz pozycję Brak. Aby uzyskać więcej informacji na temat innych dostępnych opcji, zobacz Tworzenie komunikacji równorzędnej. Wybierz pozycję Dodaj , aby skonfigurować komunikację równorzędną z wybraną siecią wirtualną. Po kilku sekundach wybierz przycisk Odśwież, a stan komunikacji równorzędnej zmieni się z Aktualizowanie na Połączenie.
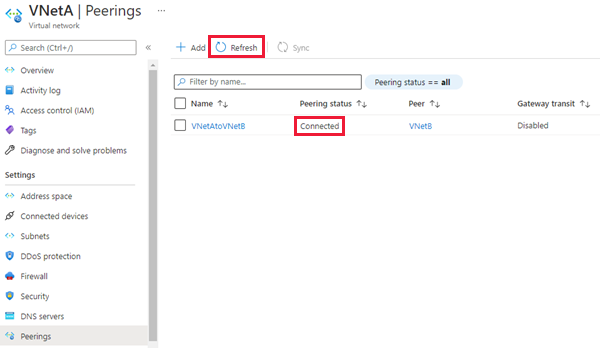
Tworzenie grupy trybu failover
Utwórz grupę trybu failover dla wystąpień zarządzanych przy użyciu witryny Azure Portal lub programu PowerShell.
Utwórz grupę trybu failover dla usługi SQL Managed Instances przy użyciu witryny Azure Portal.
Wybierz pozycję Azure SQL w menu po lewej stronie witryny Azure Portal. Jeśli usługa Azure SQL nie znajduje się na liście, wybierz pozycję Wszystkie usługi, a następnie wpisz azure SQL w polu wyszukiwania. (Opcjonalnie) Wybierz gwiazdkę obok pozycji Azure SQL , aby dodać ją jako ulubiony element do nawigacji po lewej stronie.
Wybierz podstawowe wystąpienie zarządzane, które chcesz dodać do grupy trybu failover.
W obszarze Ustawienia przejdź do pozycji Grupy trybu failover wystąpienia, a następnie wybierz pozycję Dodaj grupę, aby otworzyć stronę tworzenia grupy trybu failover wystąpienia.
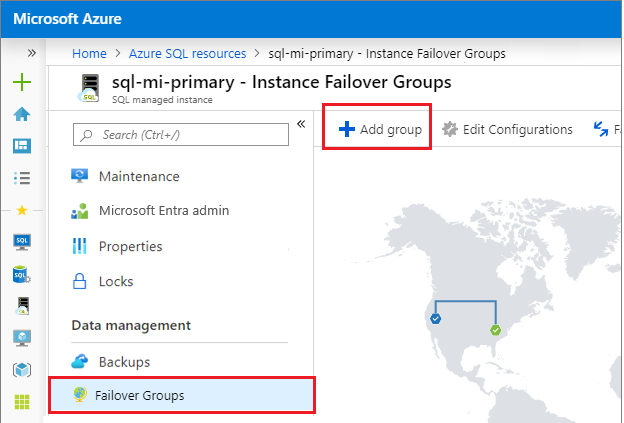
Na stronie Grupa trybu failover wystąpienia wpisz nazwę grupy trybu failover, a następnie wybierz pomocnicze wystąpienie zarządzane z listy rozwijanej. Wybierz pozycję Utwórz, aby utworzyć grupę trybu failover.
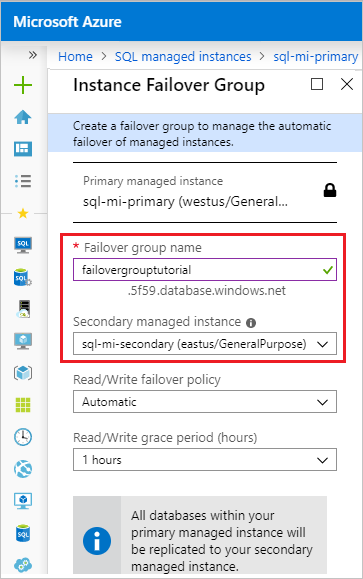
Po zakończeniu wdrażania grupy trybu failover następuje powrót do strony grupy trybu failover.
Testowanie pracy w trybie failover
Przetestuj tryb failover grupy trybu failover przy użyciu witryny Azure Portal lub programu PowerShell.
Przetestuj tryb failover grupy trybu failover przy użyciu witryny Azure Portal.
Przejdź do pomocniczego wystąpienia zarządzanego w witrynie Azure Portal i wybierz pozycję Grupy trybu failover wystąpienia w obszarze ustawienia.
Zwróć uwagę na wystąpienia zarządzane w roli podstawowej i pomocniczej.
Wybierz pozycję Tryb failover , a następnie wybierz pozycję Tak w ostrzeżeniu o rozłączeniu sesji TDS.
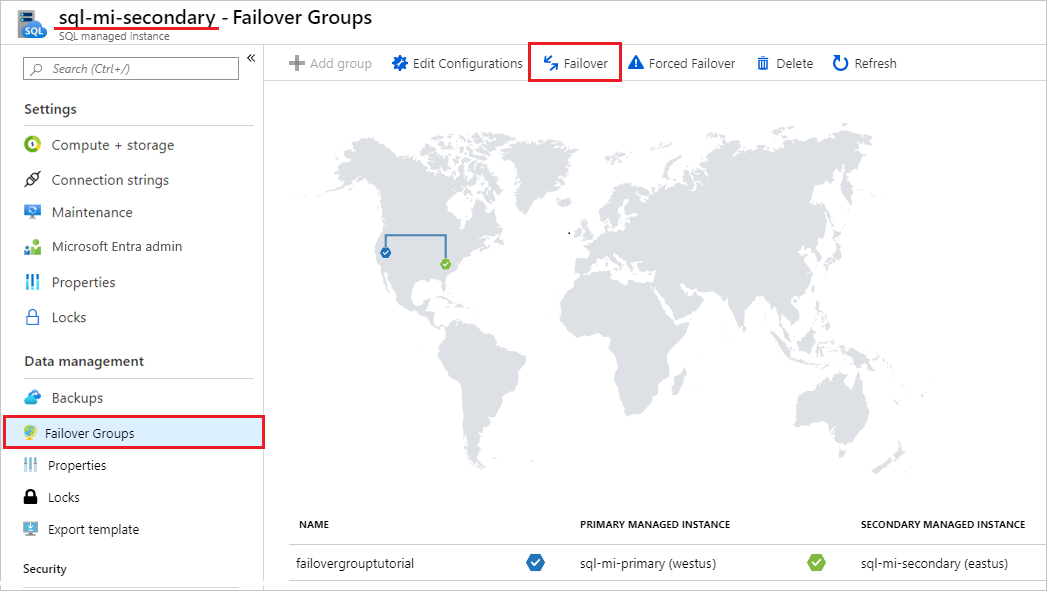
Zwróć uwagę na wystąpienia zarządzane w roli podstawowej i pomocniczej. Jeśli przejście w tryb failover zakończyło się pomyślnie, dwa wystąpienia powinny mieć przełączone role.

Ważne
Jeśli role nie przełączyły się, sprawdź łączność między wystąpieniami i powiązanymi regułami sieciowej grupy zabezpieczeń i zapory. Przejdź do następnego kroku dopiero po przełączeniu ról.
- Przejdź do nowego pomocniczego wystąpienia zarządzanego i ponownie wybierz pozycję Tryb failover , aby przywrócić wystąpienie podstawowe do roli podstawowej.
Lokalizowanie punktu końcowego odbiornika
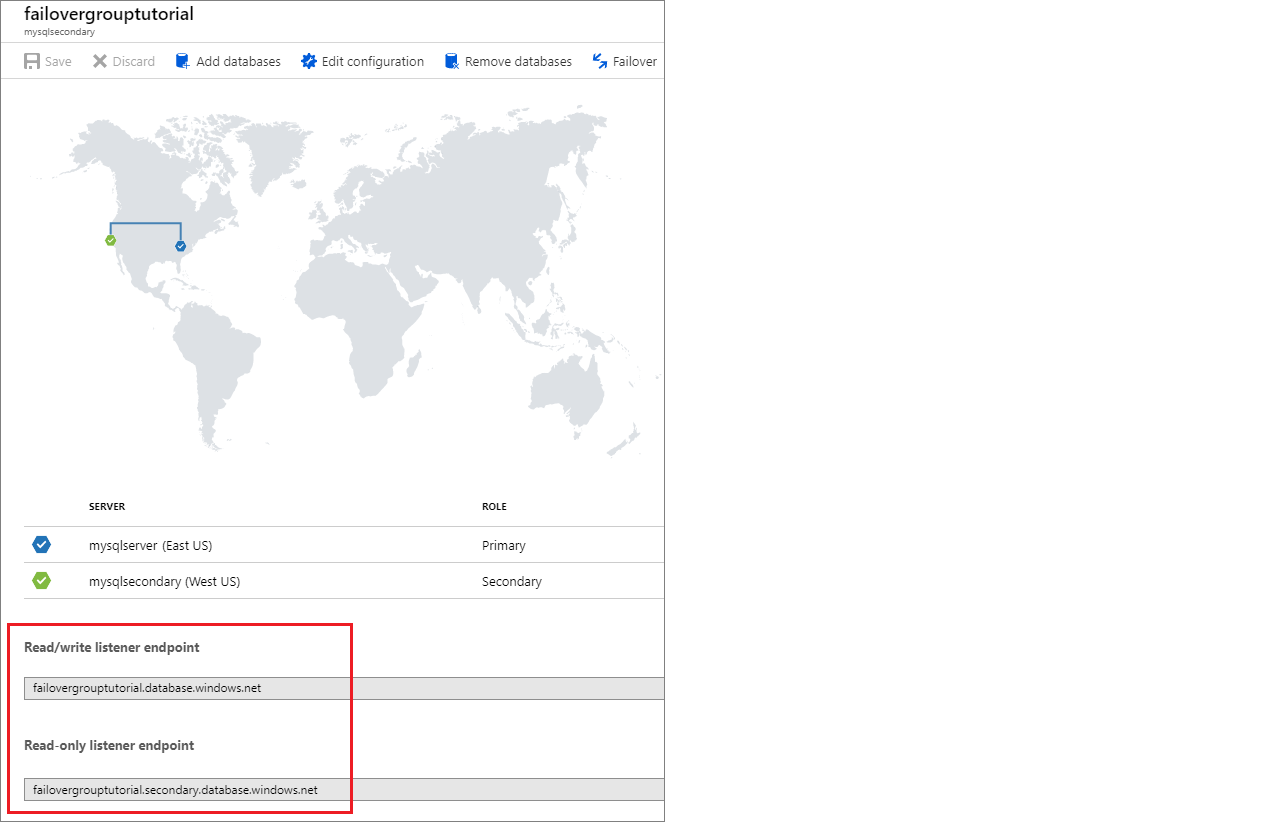
Po skonfigurowaniu grupy trybu failover zaktualizuj parametry połączenia aplikacji do punktu końcowego odbiornika. Utrzymuje ona aplikację połączoną z odbiornikiem grupy trybu failover, a nie podstawową bazą danych, elastyczną pulą lub bazą danych wystąpień. W ten sposób nie trzeba ręcznie aktualizować parametry połączenia za każdym razem, gdy jednostka bazy danych ulegnie awarii, a ruch jest kierowany do jednostki, która jest obecnie podstawowa.
Punkt końcowy odbiornika ma postać fog-name.database.windows.neti jest widoczny w witrynie Azure Portal podczas wyświetlania grupy trybu failover:
Tworzenie grupy między wystąpieniami w różnych subskrypcjach
Grupę trybu failover można utworzyć między wystąpieniami zarządzanymi SQL w dwóch różnych subskrypcjach, o ile subskrypcje są skojarzone z tą samą dzierżawą firmy Microsoft Entra.
- W przypadku korzystania z interfejsu API programu PowerShell można to zrobić, określając
PartnerSubscriptionIdparametr pomocniczego wystąpienia zarządzanego SQL. - W przypadku korzystania z interfejsu API REST każdy identyfikator wystąpienia uwzględniony w parametrze
properties.managedInstancePairsmoże mieć własny identyfikator subskrypcji. - Witryna Azure Portal nie obsługuje tworzenia grup trybu failover w różnych subskrypcjach.
Ważne
Witryna Azure Portal nie obsługuje tworzenia grup trybu failover w różnych subskrypcjach. W przypadku grup trybu failover w różnych subskrypcjach i/lub grupach zasobów nie można zainicjować trybu failover ręcznie za pośrednictwem witryny Azure Portal z podstawowego wystąpienia zarządzanego SQL. Zamiast tego należy zainicjować go z wystąpienia pomocniczego obszaru geograficznego.
Zapobieganie utracie krytycznych danych
Ze względu na duże opóźnienie sieci rozległe replikacja geograficzna używa mechanizmu replikacji asynchronicznej. Replikacja asynchroniczna sprawia, że utrata danych jest nieunikniona w przypadku awarii podstawowej. Aby chronić krytyczne transakcje przed utratą danych, deweloper aplikacji może wywołać procedurę składowaną sp_wait_for_database_copy_sync natychmiast po zatwierdzeniu transakcji. Wywołanie sp_wait_for_database_copy_sync blokuje wątek wywołujący do czasu przesyłania ostatniej zatwierdzonej transakcji i wzmacniania zabezpieczeń w dzienniku transakcji pomocniczej bazy danych. Jednak nie czeka na ponowne odtworzenie przesyłanych transakcji (redone) na pomocniczym. sp_wait_for_database_copy_sync jest ograniczona do określonego łącza replikacji geograficznej. Każdy użytkownik z prawami połączenia do podstawowej bazy danych może wywołać tę procedurę.
Uwaga
sp_wait_for_database_copy_sync zapobiega utracie danych po przejściu w tryb failover geograficznym dla określonych transakcji, ale nie gwarantuje pełnej synchronizacji w celu uzyskania dostępu do odczytu. Opóźnienie spowodowane sp_wait_for_database_copy_sync wywołaniem procedury może być znaczące i zależy od rozmiaru dziennika transakcji, który nie został jeszcze przesłany na serwerze podstawowym w momencie wywołania.
Zmienianie regionu pomocniczego
Załóżmy, że wystąpienie A jest wystąpieniem podstawowym, wystąpienie B jest istniejącym wystąpieniem pomocniczym, a wystąpienie C jest nowym wystąpieniem pomocniczym w trzecim regionie. Aby wykonać przejście, wykonaj następujące kroki:
- Utwórz wystąpienie C o takim samym rozmiarze jak A i w tej samej strefie DNS.
- Usuń grupę trybu failover między wystąpieniami A i B. W tym momencie próby zalogowania się kończą się niepowodzeniem, ponieważ aliasy SQL dla odbiorników grupy trybu failover zostały usunięte, a brama nie rozpozna nazwy grupy trybu failover. Pomocnicze bazy danych są odłączone od prawyborów i stają się bazami danych odczytu i zapisu.
- Utwórz grupę trybu failover o tej samej nazwie między wystąpieniem A i C. Postępuj zgodnie z instrukcjami w przewodniku konfigurowania grupy trybu failover. Jest to operacja rozmiaru danych i kończy się, gdy wszystkie bazy danych z wystąpienia A są rozmieszczane i synchronizowane.
- Usuń wystąpienie B, jeśli nie jest potrzebne, aby uniknąć niepotrzebnych opłat.
Uwaga
Po kroku 2 i do momentu ukończenia kroku 3 bazy danych w wystąpieniu A pozostaną niechronione z powodu katastrofalnego błędu wystąpienia A.
Zmienianie regionu podstawowego
Załóżmy, że wystąpienie A jest wystąpieniem podstawowym, wystąpienie B jest istniejącym wystąpieniem pomocniczym, a wystąpienie C jest nowym wystąpieniem podstawowym w trzecim regionie. Aby wykonać przejście, wykonaj następujące kroki:
- Utwórz wystąpienie C o takim samym rozmiarze jak B i w tej samej strefie DNS.
- Połączenie do wystąpienia B i ręczne przełączenie wystąpienia w tryb failover w celu przełączenia wystąpienia podstawowego na B. Wystąpienie A staje się nowym wystąpieniem pomocniczym automatycznie.
- Usuń grupę trybu failover między wystąpieniami A i B. W tym momencie próby logowania przy użyciu punktów końcowych grupy trybu failover zaczynają się wieść. Pomocnicze bazy danych w usłudze A są odłączone od prawyborów i stają się bazami danych odczytu i zapisu.
- Utwórz grupę trybu failover o tej samej nazwie między wystąpieniem B i C. Postępuj zgodnie z instrukcjami w przewodniku grupy trybu failover. Jest to operacja rozmiaru danych i kończy się, gdy wszystkie bazy danych z wystąpienia A są rozmieszczane i synchronizowane. W tym momencie próby logowania zakończą się niepowodzeniem.
- Ręczne przełączenie w tryb failover w celu przełączenia wystąpienia C na rolę podstawową. Wystąpienie B automatycznie staje się nowym wystąpieniem pomocniczym.
- Usuń wystąpienie A, jeśli nie jest potrzebne, aby uniknąć niepotrzebnych opłat.
Uwaga
Po wykonaniu kroku 3 i do momentu ukończenia kroku 4 bazy danych w wystąpieniu A pozostaną niechronione z powodu katastrofalnego błędu wystąpienia A.
Ważne
Po usunięciu grupy trybu failover rekordy DNS dla punktów końcowych odbiornika również zostaną usunięte. W tym momencie istnieje niezerowe prawdopodobieństwo utworzenia grupy trybu failover o tej samej nazwie. Ponieważ nazwy grup trybu failover muszą być globalnie unikatowe, uniemożliwi to ponowne użycie tej samej nazwy. Aby zminimalizować to ryzyko, nie używaj ogólnych nazw grup trybu failover.
Włączanie scenariuszy zależnych od obiektów z systemowych baz danych
Systemowe bazy danych nie są replikowane do wystąpienia pomocniczego w grupie trybu failover. Aby włączyć scenariusze zależne od obiektów z systemowych baz danych, pamiętaj, aby utworzyć takie same obiekty w wystąpieniu pomocniczym i zachować ich synchronizację z wystąpieniem podstawowym.
Jeśli na przykład planujesz używać tych samych identyfikatorów logowania w wystąpieniu pomocniczym, pamiętaj, aby utworzyć je przy użyciu identycznego identyfikatora SID.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Aby dowiedzieć się więcej, zobacz temat Replication of logins and agent jobs (Replikacja identyfikatorów logowania i zadań agenta).
Synchronizowanie właściwości wystąpienia i wystąpień zasad przechowywania
Wystąpienia w grupie trybu failover pozostają oddzielnymi zasobami platformy Azure, a żadne zmiany konfiguracji wystąpienia podstawowego nie zostaną automatycznie zreplikowane do wystąpienia pomocniczego. Upewnij się, że wszystkie istotne zmiany są wykonywane zarówno w wystąpieniu podstawowym , jak i pomocniczym. Jeśli na przykład zmienisz nadmiarowość magazynu kopii zapasowych lub zasady długoterminowego przechowywania kopii zapasowych w wystąpieniu podstawowym, pamiętaj o zmianie go również w wystąpieniu pomocniczym.
Skalowanie wystąpień
Możesz skalować w górę lub skalować w dół wystąpienie podstawowe i pomocnicze do innego rozmiaru obliczeniowego w ramach tej samej warstwy usługi lub do innej warstwy usługi. Podczas skalowania w górę w tej samej warstwie usługi zalecamy najpierw skalowanie w górę pomocniczego obszaru geograficznego, a następnie skalowanie w górę podstawowego. Podczas skalowania w dół w ramach tej samej warstwy usługi należy odwrócić kolejność: najpierw przeskaluj w dół podstawową, a następnie przeprowadź skalowanie w dół pomocniczej. W przypadku wystąpienia skalowania do innej warstwy usługi to zalecenie jest wymuszane.
Ta sekwencja jest zalecana specjalnie po to, aby uniknąć problemu polegającego na tym, że geograficzne wystąpienie pomocnicze z niższym poziomem jednostki SKU zostaje przeciążone i musi zostać ponownie rozmieszczone podczas procesu podwyższania lub obniżania poziomu.
Uprawnienia
Uprawnienia do grupy trybu failover są zarządzane za pośrednictwem kontroli dostępu opartej na rolach (RBAC) platformy Azure.
Dostęp do zapisu RBAC platformy Azure jest niezbędny do tworzenia grup trybu failover i zarządzania nimi. Rola Współautor wystąpienia zarządzanego SQL ma wszystkie niezbędne uprawnienia do zarządzania grupami trybu failover.
W poniższej tabeli wymieniono określone zakresy uprawnień dla usługi Azure SQL Managed Instance:
| Akcja | Uprawnienie | Scope |
|---|---|---|
| Tworzenie grupy trybu failover | Dostęp do zapisu kontroli dostępu opartej na rolach platformy Azure | Podstawowe wystąpienie zarządzane pomocnicze wystąpienie zarządzane |
| Aktualizowanie grupy trybu failover | Dostęp do zapisu kontroli dostępu opartej na rolach platformy Azure | Grupa trybu failover Wszystkie bazy danych w wystąpieniu zarządzanym |
| Grupa trybu failover w trybie failover | Dostęp do zapisu kontroli dostępu opartej na rolach platformy Azure | Grupa trybu failover w nowym podstawowym wystąpieniu zarządzanym |
Ograniczenia
Należy pamiętać o następujących ograniczeniach:
- Nie można utworzyć grup trybu failover między dwoma wystąpieniami w tym samym regionie świadczenia usługi Azure.
- Nazw grup trybu failover nie można zmieniać. Należy usunąć grupę i utworzyć ją ponownie z inną nazwą.
- Grupa trybu failover zawiera dokładnie dwa wystąpienia zarządzane. Dodawanie dodatkowych wystąpień do grupy trybu failover nie jest obsługiwane.
- Wystąpienie może uczestniczyć tylko w jednej grupie trybu failover w dowolnym momencie.
- Nie można utworzyć grupy trybu failover między dwoma wystąpieniami należącymi do różnych dzierżaw platformy Azure.
- Nie można utworzyć grupy trybu failover między dwoma wystąpieniami należącymi do różnych subskrypcji platformy Azure przy użyciu witryny Azure Portal ani interfejsu wiersza polecenia platformy Azure. Zamiast tego użyj programu Azure PowerShell lub interfejsu API REST, aby utworzyć taką grupę trybu failover. Po utworzeniu grupa trybu failover między subskrypcjami jest regularnie widoczna w witrynie Azure Portal, a wszystkie kolejne operacje, w tym tryb failover, można zainicjować z poziomu witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
- Zmiana nazwy bazy danych nie jest obsługiwana w przypadku baz danych w grupie trybu failover. Aby móc zmienić nazwę bazy danych, musisz tymczasowo usunąć grupę trybu failover.
- Systemowe bazy danych nie są replikowane do wystąpienia pomocniczego w grupie trybu failover. W związku z tym scenariusze zależne od obiektów z systemowych baz danych, takich jak identyfikatory logowania serwera i zadania agenta, wymagają ręcznego utworzenia obiektów w wystąpieniach pomocniczych, a także ręcznej synchronizacji po wprowadzeniu zmian w wystąpieniu podstawowym. Jedynym wyjątkiem jest klucz główny usługi (SMK) dla wystąpienia zarządzanego SQL, który jest replikowany automatycznie do wystąpienia pomocniczego podczas tworzenia grupy trybu failover. Wszelkie kolejne zmiany zestawu SMK w wystąpieniu podstawowym nie zostaną jednak zreplikowane do wystąpienia pomocniczego. Aby dowiedzieć się więcej, zobacz, jak włączyć scenariusze zależne od obiektów z systemowych baz danych.
- Nie można utworzyć grup trybu failover między wystąpieniami, jeśli którykolwiek z nich znajduje się w puli wystąpień.
Programowe zarządzanie grupami trybu failover
Grupy trybu failover można również zarządzać programowo przy użyciu programu Azure PowerShell, interfejsu wiersza polecenia platformy Azure i interfejsu API REST. W poniższych tabelach opisano zestaw dostępnych poleceń. Grupy trybu failover obejmują zestaw interfejsów API usługi Azure Resource Manager do zarządzania, w tym interfejs API REST usługi Azure SQL Database i polecenia cmdlet programu Azure PowerShell. Te interfejsy API wymagają użycia grup zasobów i obsługi kontroli dostępu opartej na rolach platformy Azure (Azure RBAC). Aby uzyskać więcej informacji na temat implementowania ról dostępu, zobacz Kontrola dostępu oparta na rolach (RBAC) platformy Azure.
| Polecenia cmdlet | opis |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | To polecenie tworzy grupę trybu failover i rejestruje ją w wystąpieniach podstawowych i pomocniczych |
| Set-AzSqlDatabaseInstanceFailoverGroup | Modyfikuje konfigurację grupy trybu failover |
| Get-AzSqlDatabaseInstanceFailoverGroup | Pobiera konfigurację grupy trybu failover |
| Switch-AzSqlDatabaseInstanceFailoverGroup | Wyzwala tryb failover grupy trybu failover do wystąpienia pomocniczego |
| Remove-AzSqlDatabaseInstanceFailoverGroup | Usuwa grupę trybu failover |
Następne kroki
Aby uzyskać instrukcje konfigurowania grupy trybu failover, zobacz Przewodnik Dodawanie wystąpienia zarządzanego do grupy trybu failover.
Aby zapoznać się z omówieniem funkcji, zobacz Grupy trybu failover. Aby dowiedzieć się, jak zaoszczędzić na kosztach licencjonowania, zobacz Konfigurowanie repliki rezerwowej.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla