Samouczek: konfigurowanie grup dostępności dla programu SQL Server na maszynach wirtualnych z systemem Ubuntu na platformie Azure
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie maszyn wirtualnych, umieszczanie ich w zestawie dostępności
- Włączanie wysokiej dostępności (HA)
- Tworzenie klastra Pacemaker
- Konfigurowanie agenta ogrodzenia przez utworzenie urządzenia STONITH
- Instalowanie programu SQL Server i narzędzi mssql-tools w systemie Ubuntu
- Konfigurowanie zawsze włączonej grupy dostępności programu SQL Server
- Konfigurowanie zasobów grupy dostępności w klastrze Pacemaker
- Testowanie trybu failover i agenta ogrodzenia
Uwaga
Komunikacja bez uprzedzeń
Ten artykuł zawiera odwołania do terminu niewolnik, termin Microsoft uznaje za obraźliwe w przypadku użycia w tym kontekście. Termin pojawia się w tym artykule, ponieważ jest on obecnie wyświetlany w oprogramowaniu. Po usunięciu terminu z oprogramowania usuniemy go z artykułu.
W tym samouczku do wdrażania zasobów na platformie Azure jest używany interfejs wiersza polecenia platformy Azure.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Użyj środowiska powłoki Bash w usłudze Azure Cloud Shell. Aby uzyskać więcej informacji, zobacz Szybki start dotyczący powłoki Bash w usłudze Azure Cloud Shell.

Jeśli wolisz uruchamiać polecenia referencyjne interfejsu wiersza polecenia lokalnie, zainstaluj interfejs wiersza polecenia platformy Azure. Jeśli korzystasz z systemu Windows lub macOS, rozważ uruchomienie interfejsu wiersza polecenia platformy Azure w kontenerze Docker. Aby uzyskać więcej informacji, zobacz Jak uruchomić interfejs wiersza polecenia platformy Azure w kontenerze platformy Docker.
Jeśli korzystasz z instalacji lokalnej, zaloguj się do interfejsu wiersza polecenia platformy Azure za pomocą polecenia az login. Aby ukończyć proces uwierzytelniania, wykonaj kroki wyświetlane w terminalu. Aby uzyskać inne opcje logowania, zobacz Logowanie się przy użyciu interfejsu wiersza polecenia platformy Azure.
Po wyświetleniu monitu zainstaluj rozszerzenie interfejsu wiersza polecenia platformy Azure podczas pierwszego użycia. Aby uzyskać więcej informacji na temat rozszerzeń, zobacz Korzystanie z rozszerzeń w interfejsie wiersza polecenia platformy Azure.
Uruchom polecenie az version, aby znaleźć zainstalowane wersje i biblioteki zależne. Aby uaktualnić do najnowszej wersji, uruchom polecenie az upgrade.
- Ten artykuł wymaga wersji 2.0.30 lub nowszej interfejsu wiersza polecenia platformy Azure. W przypadku korzystania z usługi Azure Cloud Shell najnowsza wersja jest już zainstalowana.
Tworzenie grupy zasobów
Jeśli masz więcej niż jedną subskrypcję, ustaw subskrypcję, do której chcesz wdrożyć te zasoby.
Użyj następującego polecenia, aby utworzyć grupę <resourceGroupName> zasobów w regionie. Zastąp <resourceGroupName> ciąg wybraną nazwą. W tym samouczku użyto regionu East US 2. Aby uzyskać więcej informacji, zobacz następujący przewodnik Szybki start.
az group create --name <resourceGroupName> --location eastus2
Tworzenie zestawu dostępności
Następnym krokiem jest utworzenie zestawu dostępności. Uruchom następujące polecenie w usłudze Azure Cloud Shell i zastąp ciąg <resourceGroupName> nazwą grupy zasobów. Wybierz nazwę elementu <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Po zakończeniu polecenia należy uzyskać następujące wyniki:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Tworzenie sieci wirtualnej i podsieci
Utwórz nazwaną podsieć z wstępnie przydzielonym zakresem adresów IP. Zastąp te wartości w następującym poleceniu:
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24Poprzednie polecenie tworzy sieć wirtualną i podsieć zawierającą niestandardowy zakres adresów IP.
Tworzenie maszyn wirtualnych z systemem Ubuntu wewnątrz zestawu dostępności
Pobierz listę obrazów maszyn wirtualnych, które oferują system operacyjny oparty na systemie Ubuntu na platformie Azure.
az vm image list --all --offer "sql2022-ubuntupro2004"Podczas wyszukiwania obrazów BYOS powinny zostać wyświetlone następujące wyniki:
[ { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230808", "version": "16.0.230808" } ]W tym samouczku użyto regionu
Ubuntu 20.04.Ważne
Aby skonfigurować grupę dostępności, nazwy maszyn muszą mieć długość krótszą niż 15 znaków. Nazwy użytkowników nie mogą zawierać wyższej litery, a hasła muszą zawierać od 12 do 72 znaków.
Utwórz trzy maszyny wirtualne w zestawie dostępności. Zastąp te wartości w następującym poleceniu:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>— Przykładem może być "Standard_D16s_v3"<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "Canonical:0001-com-ubuntu-server-jammy:20_04-lts-gen2:latest" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
Poprzednie polecenie tworzy maszyny wirtualne przy użyciu wcześniej zdefiniowanej sieci wirtualnej. Aby uzyskać więcej informacji na temat różnych konfiguracji, zobacz artykuł az vm create .
Polecenie zawiera --os-disk-size-gb również parametr umożliwiający utworzenie niestandardowego rozmiaru dysku systemu operacyjnego 128 GB. Jeśli później zwiększysz ten rozmiar, rozwiń odpowiednie woluminy folderów, aby pomieścić instalację, skonfiguruj Menedżera woluminów logicznych (LVM).
Wyniki powinny być podobne do następujących po zakończeniu polecenia dla każdej maszyny wirtualnej:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/ubuntu1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Testowanie połączenia z utworzonymi maszynami wirtualnymi
Połączenie do każdej maszyny wirtualnej przy użyciu następującego polecenia w usłudze Azure Cloud Shell. Jeśli nie możesz znaleźć adresów IP maszyny wirtualnej, postępuj zgodnie z tym przewodnikiem Szybki start w usłudze Azure Cloud Shell.
ssh <username>@<publicIPAddress>
Jeśli połączenie zakończy się pomyślnie, powinny zostać wyświetlone następujące dane wyjściowe reprezentujące terminal systemu Linux:
[<username>@ubuntu1 ~]$
Wpisz exit , aby opuścić sesję SSH.
Konfigurowanie dostępu SSH bez hasła między węzłami
Dostęp SSH bez hasła umożliwia maszynom wirtualnym komunikowanie się ze sobą przy użyciu kluczy publicznych SSH. Należy skonfigurować klucze SSH w każdym węźle i skopiować te klucze do każdego węzła.
Generowanie nowych kluczy SSH
Wymagany rozmiar klucza SSH to 4096 bitów. Na każdej maszynie /root/.ssh wirtualnej przejdź do folderu i uruchom następujące polecenie:
ssh-keygen -t rsa -b 4096
W tym kroku może zostać wyświetlony monit o zastąpienie istniejącego pliku SSH. Musisz wyrazić zgodę na ten monit. Nie musisz wprowadzać hasła.
Kopiowanie publicznych kluczy SSH
Na każdej maszynie wirtualnej należy skopiować klucz publiczny z właśnie utworzonego węzła ssh-copy-id przy użyciu polecenia . Jeśli chcesz określić katalog docelowy na docelowej maszynie wirtualnej, możesz użyć parametru -i .
W poniższym poleceniu konto może być tym samym kontem skonfigurowanym <username> dla każdego węzła podczas tworzenia maszyny wirtualnej. Możesz również użyć root konta, ale ta opcja nie jest zalecana w środowisku produkcyjnym.
sudo ssh-copy-id <username>@ubuntu1
sudo ssh-copy-id <username>@ubuntu2
sudo ssh-copy-id <username>@ubuntu3
Weryfikowanie dostępu bez hasła z każdego węzła
Aby potwierdzić, że klucz publiczny SSH został skopiowany do każdego węzła, użyj ssh polecenia z każdego węzła. Jeśli klucze zostały skopiowane poprawnie, nie zostanie wyświetlony monit o podanie hasła i połączenie zakończy się pomyślnie.
W tym przykładzie nawiązujemy połączenie z drugim i trzecimi węzłami z pierwszej maszyny wirtualnej (ubuntu1). Po raz kolejny <username> konto może być tym samym kontem skonfigurowanym dla każdego węzła podczas tworzenia maszyny wirtualnej.
ssh <username>@ubuntu2
ssh <username>@ubuntu3
Powtórz ten proces ze wszystkich trzech węzłów, aby każdy węzeł mógł komunikować się z innymi bez konieczności stosowania haseł.
Konfigurowanie rozpoznawania nazw
Rozpoznawanie nazw można skonfigurować przy użyciu systemu DNS lub ręcznie edytując etc/hosts plik w każdym węźle.
Aby uzyskać więcej informacji na temat systemu DNS i usługi Active Directory, zobacz Dołączanie programu SQL Server na hoście z systemem Linux do domeny usługi Active Directory.
Ważne
Zalecamy użycie prywatnego adresu IP w poprzednim przykładzie. Użycie publicznego adresu IP w tej konfiguracji spowoduje niepowodzenie instalacji i uwidocznie maszynę wirtualną w sieciach zewnętrznych.
Maszyny wirtualne i ich adresy IP używane w tym przykładzie są wymienione w następujący sposób:
ubuntu1: 10.0.0.85ubuntu2: 10.0.0.86ubuntu3: 10.0.0.87
Włączanie wysokiej dostępności
Użyj protokołu SSH , aby nawiązać połączenie z każdą z 3 maszyn wirtualnych, a po nawiązaniu połączenia uruchom następujące polecenia, aby włączyć wysoką dostępność.
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Instalowanie i konfigurowanie klastra Pacemaker
Aby rozpocząć konfigurowanie klastra Pacemaker, należy zainstalować wymagane pakiety i agentów zasobów. Uruchom poniższe polecenia na każdej maszynie wirtualnej:
sudo apt-get install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure
Teraz przejdź do tworzenia klucza uwierzytelniania na serwerze podstawowym:
sudo corosync-keygen
Klucz uwierzytelniania jest generowany w /etc/corosync/authkey lokalizacji. Skopiuj klucz authkey do serwerów pomocniczych w tej lokalizacji: /etc/corosync/authkey
sudo scp /etc/corosync/authkey username@ubuntu2:~
sudo scp /etc/corosync/authkey username@ubuntu3:~
Przenieś klucz authkey z katalogu macierzystego do ./etc/corosync
sudo mv authkey /etc/corosync/authkey
Przejdź do utworzenia klastra przy użyciu następujących poleceń:
cd /etc/corosync/
sudo vi corosync.conf
Edytuj plik Corosync, aby przedstawić zawartość w następujący sposób:
totem {
version: 2
secauth: off
cluster_name: demo
transport: udpu
}
nodelist {
node {
ring0_addr: 10.0.0.85
name: ubuntu1
nodeid: 1
}
node {
ring0_addr: 10.0.0.86
name: ubuntu2
nodeid: 2
}
node {
ring0_addr: 10.0.0.87
name: ubuntu3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
two_node: 0
}
qb {
ipc_type: native
}
logging {
fileline: on
to_stderr: on
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: no
debug: off
}
corosync.conf Skopiuj plik do innych węzłów na :/etc/corosync/corosync.conf
sudo scp /etc/corosync/corosync.conf username@ubuntu2:~
sudo scp /etc/corosync/corosync.conf username@ubuntu3:~
sudo mv corosync.conf /etc/corosync/
Uruchom ponownie program Pacemaker i corosync i potwierdź stan:
sudo systemctl restart pacemaker corosync
sudo crm status
Dane wyjściowe wyglądają podobnie do następującego przykładu:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by hacluster via crmd on ubuntu1
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* No resources
Konfigurowanie agenta ogrodzenia
Konfigurowanie ogrodzenia w klastrze. Ogrodzenie to izolacja węzła, który zakończył się niepowodzeniem w klastrze. Spowoduje to ponowne uruchomienie węzła, które zakończyło się niepowodzeniem, co pozwoli mu przejść w dół, zresetować i wrócić, ponownie dołączając klaster.
Aby skonfigurować ogrodzenie, wykonaj następujące czynności:
- Rejestrowanie nowej aplikacji w identyfikatorze Entra firmy Microsoft i tworzenie wpisu tajnego
- Tworzenie roli niestandardowej na podstawie pliku json w programie PowerShell/interfejsie wiersza polecenia
- Przypisywanie roli i aplikacji do maszyn wirtualnych w klastrze
- Ustawianie właściwości agenta ogrodzenia
Rejestrowanie nowej aplikacji w identyfikatorze Entra firmy Microsoft i tworzenie wpisu tajnego
- Przejdź do pozycji Microsoft Entra ID w portalu i zanotuj identyfikator dzierżawy.
- Wybierz pozycję Rejestracje aplikacji w menu po lewej stronie, a następnie wybierz pozycję Nowa rejestracja.
- Wprowadź nazwę, a następnie wybierz pozycję Konta tylko w tym katalogu organizacji.
- W polu Typ aplikacji wybierz pozycję Sieć Web, wprowadź jako
http://localhostadres URL logowania, a następnie wybierz pozycję Zarejestruj. - Wybierz pozycję Certyfikaty i wpisy tajne w menu po lewej stronie, a następnie wybierz pozycję Nowy klucz tajny klienta.
- Wprowadź opis i wybierz okres wygaśnięcia.
- Zanotuj wartość wpisu tajnego, jest ona używana jako następujące hasło i identyfikator wpisu tajnego, który jest używany jako następująca nazwa użytkownika.
- Wybierz pozycję "Przegląd" i zanotuj identyfikator aplikacji. Jest on używany jako następujący identyfikator logowania.
Utwórz plik JSON o nazwie fence-agent-role.json i dodaj następujący kod (dodawanie identyfikatora subskrypcji):
{
"Name": "Linux Fence Agent Role-ap-server-01-fence-agent",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [],
"AssignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
]
}
Tworzenie roli niestandardowej na podstawie pliku JSON w programie PowerShell/interfejsie wiersza polecenia
az role definition create --role-definition fence-agent-role.json
Przypisywanie roli i aplikacji do maszyn wirtualnych w klastrze
- Dla każdej maszyny wirtualnej w klastrze wybierz pozycję Kontrola dostępu (zarządzanie dostępem i tożsamościami) z menu bocznego.
- Wybierz pozycję Dodaj przypisanie roli (użyj środowiska klasycznego).
- Wybierz utworzoną wcześniej rolę.
- Na liście Wybierz wprowadź nazwę utworzonej wcześniej aplikacji.
Teraz możemy utworzyć zasób agenta ogrodzenia przy użyciu poprzednich wartości i identyfikatora subskrypcji:
sudo crm configure primitive fence-vm stonith:fence_azure_arm \
params \
action=reboot \
resourceGroup="resourcegroupname" \
resourceGroup="$resourceGroup" \
username="$secretId" \
login="$applicationId" \
passwd="$password" \
tenantId="$tenantId" \
subscriptionId="$subscriptionId" \
pcmk_reboot_timeout=900 \
power_timeout=60 \
op monitor \
interval=3600 \
timeout=120
Ustawianie właściwości agenta ogrodzenia
Uruchom następujące polecenia, aby ustawić właściwości agenta ogrodzenia:
sudo crm configure property cluster-recheck-interval=2min
sudo crm configure property start-failure-is-fatal=true
sudo crm configure property stonith-timeout=900
sudo crm configure property concurrent-fencing=true
sudo crm configure property stonith-enabled=true
I potwierdź stan klastra:
sudo crm status
Dane wyjściowe wyglądają podobnie do następującego przykładu:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 1 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Instalowanie programu SQL Server i narzędzi mssql-tools
Do zainstalowania programu SQL Server służą następujące polecenia:
Zaimportuj klucze gpG repozytorium publicznego:
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascZarejestruj repozytorium Ubuntu:
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list)"Uruchom następujące polecenia, aby zainstalować program SQL Server:
sudo apt-get update sudo apt-get install -y mssql-serverPo zakończeniu instalacji pakietu uruchom
mssql-conf setuppolecenie i postępuj zgodnie z monitami, aby ustawić hasło administratora systemu i wybrać wersję. Przypominamy, że następujące wersje są licencjonowane bezpłatnie: Evaluation, Developer i Express.sudo /opt/mssql/bin/mssql-conf setupPo zakończeniu konfiguracji sprawdź, czy usługa jest uruchomiona:
systemctl status mssql-server --no-pagerInstalowanie narzędzi wiersza polecenia programu SQL Server
Aby utworzyć bazę danych, musisz nawiązać połączenie z narzędziem, które może uruchamiać instrukcje języka Transact-SQL w programie SQL Server. Poniższe kroki umożliwiają zainstalowanie narzędzi wiersza polecenia programu SQL Server: sqlcmd i bcp.
Wykonaj poniższe kroki, aby zainstalować narzędzie mssql-tools18 w systemie Ubuntu.
Uwaga
- System Ubuntu 18.04 jest obsługiwany od programu SQL Server 2019 CU 3.
- System Ubuntu 20.04 jest obsługiwany od programu SQL Server 2019 CU 10.
- System Ubuntu 22.04 jest obsługiwany od programu SQL Server 2022 CU 10.
Wprowadź tryb superużytkownika.
sudo suZaimportuj klucze gpG repozytorium publicznego.
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascZarejestruj repozytorium microsoft Ubuntu.
W przypadku systemu Ubuntu 22.04 użyj następującego polecenia:
curl https://packages.microsoft.com/config/ubuntu/22.04/prod.list > /etc/apt/sources.list.d/mssql-release.listW przypadku systemu Ubuntu 20.04 użyj następującego polecenia:
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list > /etc/apt/sources.list.d/mssql-release.listW przypadku systemu Ubuntu 18.04 użyj następującego polecenia:
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.listW przypadku systemu Ubuntu 16.04 użyj następującego polecenia:
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
Zamknij tryb superużytkownika.
exitZaktualizuj listę źródeł i uruchom polecenie instalacji przy użyciu pakietu dewelopera unixODBC.
sudo apt-get update sudo apt-get install mssql-tools18 unixodbc-devUwaga
Aby zaktualizować do najnowszej wersji narzędzi mssql-tools, uruchom następujące polecenia:
sudo apt-get update sudo apt-get install mssql-tools18Opcjonalnie: Dodaj
/opt/mssql-tools18/bin/doPATHzmiennej środowiskowej w powłoce powłoki bash.Aby program sqlcmd i bcp był dostępny z poziomu powłoki bash na potrzeby sesji logowania, zmodyfikuj
~/.bash_profileplikPATHza pomocą następującego polecenia:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bash_profileAby program sqlcmd i bcp były dostępne z poziomu powłoki bash dla sesji interakcyjnych/niezwiązanych z logowaniem, zmodyfikuj
PATHplik za~/.bashrcpomocą następującego polecenia:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc source ~/.bashrc
Instalowanie agenta wysokiej dostępności programu SQL Server
Uruchom następujące polecenie na wszystkich węzłach, aby zainstalować pakiet agenta wysokiej dostępności dla programu SQL Server:
sudo apt-get install mssql-server-ha
Konfigurowanie grupy dostępności
Wykonaj poniższe kroki, aby skonfigurować zawsze włączoną grupę dostępności programu SQL Server dla maszyn wirtualnych. Aby uzyskać więcej informacji, zobacz Konfigurowanie zawsze włączonych grup dostępności programu SQL Server pod kątem wysokiej dostępności w systemie Linux.
Włączanie grup dostępności i ponowne uruchamianie programu SQL Server
Włącz grupy dostępności w każdym węźle, który hostuje wystąpienie programu SQL Server. Następnie uruchom ponownie usługę mssql-server . Uruchom następujące polecenia w każdym węźle:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Tworzenie certyfikatu
Firma Microsoft nie obsługuje uwierzytelniania usługi Active Directory w punkcie końcowym grupy dostępności. W związku z tym należy użyć certyfikatu do szyfrowania punktu końcowego grupy dostępności.
Połączenie do wszystkich węzłów przy użyciu programu SQL Server Management Studio (SSMS) lub sqlcmd. Uruchom następujące polecenia, aby włączyć sesję AlwaysOn_health i utworzyć klucz główny:
Ważne
Jeśli łączysz się zdalnie z wystąpieniem programu SQL Server, musisz otworzyć port 1433 w zaporze. Należy również zezwolić na połączenia przychodzące z portem 1433 w sieciowej grupie zabezpieczeń dla każdej maszyny wirtualnej. Aby uzyskać więcej informacji, zobacz Tworzenie reguły zabezpieczeń na potrzeby tworzenia reguły zabezpieczeń dla ruchu przychodzącego.
- Zastąp element
<MasterKeyPassword>własnym hasłem.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GO- Zastąp element
Połączenie do repliki podstawowej przy użyciu programu SSMS lub sqlcmd. Poniższe polecenia tworzą certyfikat w lokalizacji
/var/opt/mssql/data/dbm_certificate.ceri klucz prywatny wvar/opt/mssql/data/dbm_certificate.pvkpodstawowej repliki programu SQL Server:- Zastąp element
<PrivateKeyPassword>własnym hasłem.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO- Zastąp element
Zamknij sesję sqlcmd , uruchamiając exit polecenie i wróć do sesji SSH.
Skopiuj certyfikat do replik pomocniczych i utwórz certyfikaty na serwerze
Skopiuj dwa pliki, które zostały utworzone do tej samej lokalizacji na wszystkich serwerach, które będą hostować repliki dostępności.
Na serwerze podstawowym uruchom następujące
scppolecenie, aby skopiować certyfikat na serwery docelowe:- Zastąp
<username>wartości isles2nazwą użytkownika i docelową nazwą maszyny wirtualnej, której używasz. - Uruchom to polecenie dla wszystkich replik pomocniczych.
Uwaga
Nie trzeba uruchamiać
sudo -ipolecenia , co daje środowisko główne. Zamiast tego można uruchomićsudopolecenie przed każdym poleceniem.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>- Zastąp
Na serwerze docelowym uruchom następujące polecenie:
- Zastąp
<username>ciąg nazwą użytkownika. - Polecenie
mvprzenosi pliki lub katalog z jednego miejsca do innego. - Polecenie
chownsłuży do zmiany właściciela i grupy plików, katalogów lub linków. - Uruchom te polecenia dla wszystkich replik pomocniczych.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Zastąp
Poniższy skrypt języka Transact-SQL tworzy certyfikat z kopii zapasowej utworzonej w podstawowej repliki programu SQL Server. Zaktualizuj skrypt przy użyciu silnych haseł. Hasło odszyfrowywania jest tym samym hasłem, które zostało użyte do utworzenia pliku pvk w poprzednim kroku. Aby utworzyć certyfikat, uruchom następujący skrypt przy użyciu narzędzia sqlcmd lub SSMS na wszystkich serwerach pomocniczych:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
Tworzenie punktów końcowych dublowania bazy danych na wszystkich replikach
Uruchom następujący skrypt we wszystkich wystąpieniach programu SQL Server przy użyciu narzędzia sqlcmd lub programu SSMS:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Tworzenie grupy dostępności
Połączenie do wystąpienia programu SQL Server, które hostuje replikę podstawową przy użyciu programu sqlcmd lub SSMS. Uruchom następujące polecenie, aby utworzyć grupę dostępności:
- Zastąp
ag1ciąg żądaną nazwą grupy dostępności. - Zastąp
ubuntu1wartości ,ubuntu2iubuntu3nazwami wystąpień programu SQL Server hostujących repliki.
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'ubuntu1'
WITH (
ENDPOINT_URL = N'tcp://ubuntu1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu2'
WITH (
ENDPOINT_URL = N'tcp://ubuntu2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu3'
WITH (
ENDPOINT_URL = N'tcp://ubuntu3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Tworzenie identyfikatora logowania programu SQL Server dla programu Pacemaker
We wszystkich wystąpieniach programu SQL Server utwórz identyfikator logowania programu SQL Server dla programu Pacemaker. Poniższy kod Transact-SQL tworzy identyfikator logowania.
- Zastąp
<password>ciąg własnym złożonym hasłem.
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
We wszystkich wystąpieniach programu SQL Server zapisz poświadczenia używane do logowania programu SQL Server.
Utwórz plik:
sudo vi /var/opt/mssql/secrets/passwdDodaj następujące dwa wiersze do pliku:
pacemakerLogin <password>Aby zamknąć edytor vi , najpierw naciśnij klawisz Esc , a następnie wprowadź polecenie
:wq, aby zapisać plik i zamknąć.Ustaw plik tylko do odczytu według katalogu głównego:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Dołączanie replik pomocniczych do grupy dostępności
W replikach pomocniczych uruchom następujące polecenia, aby dołączyć je do grupy dostępności:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOUruchom następujący skrypt Języka Transact-SQL w repliki podstawowej i każdej repliki pomocniczej:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOPo dołączeniu replik pomocniczych można je zobaczyć w programie SSMS Eksplorator obiektów, rozwijając węzeł Zawsze włączone wysokiej dostępności:
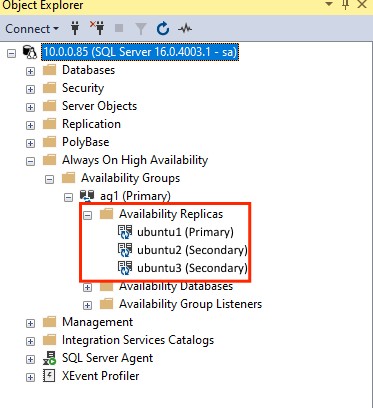
Dodawanie bazy danych do grupy dostępności
Ta sekcja jest zgodna z artykułem dotyczącym dodawania bazy danych do grupy dostępności.
W tym kroku są używane następujące polecenia języka Transact-SQL. Uruchom następujące polecenia w repliki podstawowej:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery mode
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Sprawdź, czy baza danych została utworzona na serwerach pomocniczych
Na każdej pomocniczej repliki programu SQL Server uruchom następujące zapytanie, aby sprawdzić, czy baza danych db1 została utworzona i ma stan SYNCD:
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
Jeśli lista synchronization_state_desc zsynchronizowana dla db1elementu oznacza, że repliki są synchronizowane. Sekundy są wyświetlane db1 w repliki podstawowej.
Tworzenie zasobów grupy dostępności w klastrze Pacemaker
Aby utworzyć zasób grupy dostępności w narzędziu Pacemaker, uruchom następujące polecenia:
sudo crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
To powyższe polecenie tworzy zasób ag1_cluster, czyli zasób grupy dostępności. Następnie tworzy zasób ms-ag1 (zasób podstawowy/pomocniczy w narzędziu Pacemaker, a następnie dodaje do niego zasób grupy dostępności. Dzięki temu zasób grupy dostępności działa we wszystkich trzech węzłach w klastrze, ale tylko jeden z tych węzłów jest podstawowy.
Aby wyświetlić zasób grupy dostępności i sprawdzić stan klastra:
sudo crm resource status ms-ag1
sudo crm status
Dane wyjściowe wyglądają podobnie do następującego przykładu:
resource ms-ag1 is running on: ubuntu1 Master
resource ms-ag1 is running on: ubuntu3
resource ms-ag1 is running on: ubuntu2
Dane wyjściowe wyglądają podobnie do poniższego przykładu. Aby dodać ograniczenia dotyczące kolokacji i podwyższania poziomu, zobacz Samouczek: konfigurowanie odbiornika grupy dostępności na maszynach wirtualnych z systemem Linux.
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Uruchom następujące polecenie, aby utworzyć zasób grupy, aby ograniczenia kolokacji i podwyższania poziomu zastosowane do odbiornika i modułu równoważenia obciążenia nie musiały być stosowane indywidualnie.
sudo crm configure group virtualip-group azure-load-balancer virtualip
Dane wyjściowe crm status polecenia będą wyglądać podobnie do następującego przykładu:
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 6 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* Resource Group: virtual ip-group:
* azure-load-balancer (ocf :: heartbeat:azure-lb): Started ubuntu1
* virtualip (ocf :: heartbeat: IPaddr2): Started ubuntu1
* fence-vm (stonith:fence_azure_arm): Started ubuntu1