Kopiowanie danych z serwera HDFS przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób kopiowania danych z serwera rozproszonego systemu plików Hadoop (HDFS). Aby dowiedzieć się więcej, przeczytaj artykuły wprowadzające dotyczące usług Azure Data Factory i Synapse Analytics.
Obsługiwane możliwości
Ten łącznik systemu plików HDFS jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/-) | ① ② |
| Działanie Lookup | ① ② |
| Działanie usuwania | ① ② |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
W szczególności łącznik HDFS obsługuje następujące funkcje:
- Kopiowanie plików przy użyciu systemu Windows (Kerberos) lub uwierzytelniania anonimowego .
- Kopiowanie plików przy użyciu protokołu webhdfs lub wbudowanej obsługi narzędzia DistCp .
- Kopiowanie plików w formacie is lub przez analizowanie lub generowanie plików z obsługiwanymi formatami plików i koderami kompresji.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować własne środowisko Integration Runtime , aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji środowiska Integration Runtime zarządzanej sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania własnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Uwaga
Upewnij się, że środowisko Integration Runtime może uzyskać dostęp do wszystkich serwerów [name node]:[name node port] i [serwery węzłów danych]:[port węzła danych] klastra Hadoop. Domyślny [port węzła nazwy] to 50070, a domyślny [port węzła danych] to 50075.
Rozpocznij
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z systemem plików HDFS przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z systemem plików HDFS w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj plik HDFS i wybierz łącznik HDFS.
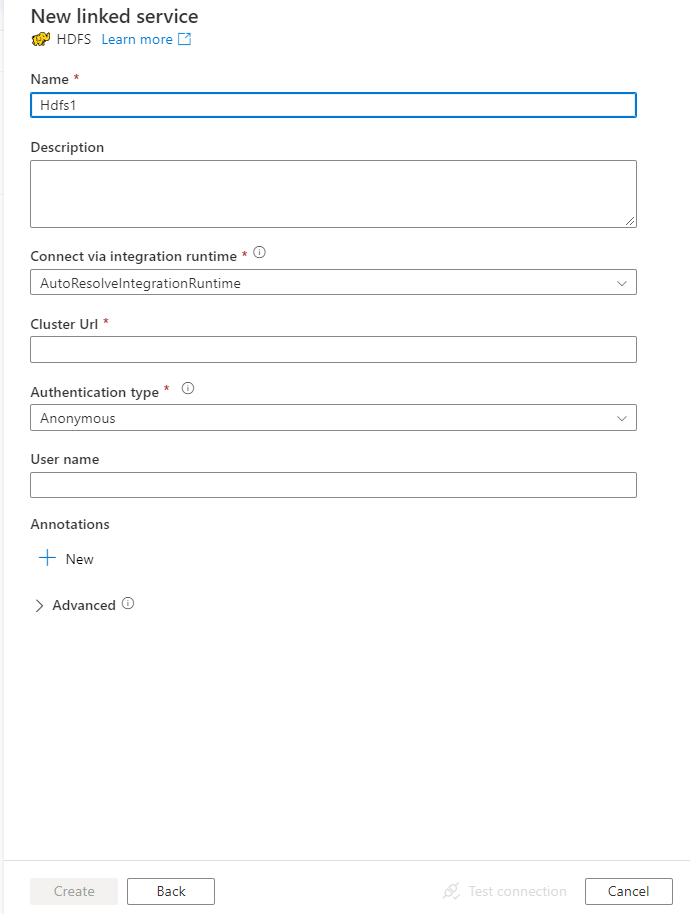
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
szczegóły konfiguracji Połączenie or
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla systemu plików HDFS.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi HDFS:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na hdfs. | Tak |
| Adres URL | Adres URL systemu plików HDFS | Tak |
| authenticationType | Dozwolone wartości to Anonimowe lub Windows. Aby skonfigurować środowisko lokalne, zobacz sekcję Use Kerberos authentication for the HDFS connector (Używanie uwierzytelniania Kerberos dla łącznika systemu plików HDFS). |
Tak |
| userName | Nazwa użytkownika uwierzytelniania systemu Windows. W przypadku uwierzytelniania Kerberos określ nazwę użytkownika>@<domenę.com>.< | Tak (w przypadku uwierzytelniania systemu Windows) |
| hasło | Hasło do uwierzytelniania systemu Windows. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w magazynie kluczy platformy Azure. | Tak (w przypadku uwierzytelniania systemu Windows) |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Aby dowiedzieć się więcej, zobacz sekcję Wymagania wstępne . Jeśli środowisko Integration Runtime nie zostanie określone, usługa używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Przykład: używanie uwierzytelniania anonimowego
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: używanie uwierzytelniania systemu Windows
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz Zestawy danych.
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w systemie plików HDFS w ustawieniach location w zestawie danych opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze location w zestawie danych musi być ustawiona na HdfsLocation. |
Tak |
| folderPath | Ścieżka do folderu. Jeśli chcesz użyć symbolu wieloznakowego do filtrowania folderu, pomiń to ustawienie i określ ścieżkę w ustawieniach źródła działań. | Nie. |
| fileName | Nazwa pliku w określonym folderPath. Jeśli chcesz używać symbolu wieloznakowego do filtrowania plików, pomiń to ustawienie i określ nazwę pliku w ustawieniach źródła działań. | Nie. |
Przykład:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz Potoki i działania. Ta sekcja zawiera listę właściwości obsługiwanych przez źródło systemu plików HDFS.
System plików HDFS jako źródło
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w systemie plików HDFS w ustawieniach storeSettings w źródle kopiowania opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na HdfsRead Ustawienia. |
Tak |
| Lokalizowanie plików do skopiowania | ||
| OPCJA 1: ścieżka statyczna |
Skopiuj z folderu lub ścieżki pliku określonej w zestawie danych. Jeśli chcesz skopiować wszystkie pliki z folderu, dodatkowo określ wildcardFileName jako *. |
|
| OPCJA 2: symbol wieloznaczny - symbol wieloznacznyFolderPath |
Ścieżka folderu z symbolami wieloznacznymi do filtrowania folderów źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku). Użyj ^ polecenia , aby uniknąć, jeśli rzeczywista nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. Aby uzyskać więcej przykładów, zobacz Przykłady filtrów folderów i plików. |
Nie. |
| OPCJA 2: symbol wieloznaczny - symbol wieloznacznyFileName |
Nazwa pliku z symbolami wieloznacznymi w ramach określonego folderuPath/symbol wieloznacznyFolderPath do filtrowania plików źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj klawisza ^ , aby uniknąć, jeśli rzeczywista nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz. Aby uzyskać więcej przykładów, zobacz Przykłady filtrów folderów i plików. |
Tak |
| OPCJA 3: lista plików - fileListPath |
Wskazuje, aby skopiować określony zestaw plików. Wskaż plik tekstowy zawierający listę plików, które chcesz skopiować (jeden plik na wiersz ze ścieżką względną do ścieżki skonfigurowanej w zestawie danych). Jeśli używasz tej opcji, nie należy określać nazwy pliku w zestawie danych. Aby uzyskać więcej przykładów, zobacz Przykłady listy plików. |
Nie. |
| Ustawienia dodatkowe | ||
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Gdy recursive jest ustawiona wartość true , a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie jest kopiowany ani tworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| deleteFilesAfterCompletion | Wskazuje, czy pliki binarne zostaną usunięte z magazynu źródłowego po pomyślnym przeniesieniu do magazynu docelowego. Usunięcie pliku jest na plik, więc gdy działanie kopiowania nie powiedzie się, zobaczysz, że niektóre pliki zostały już skopiowane do miejsca docelowego i usunięte ze źródła, podczas gdy inne nadal pozostają w magazynie źródłowym. Ta właściwość jest prawidłowa tylko w scenariuszu kopiowania plików binarnych. Wartość domyślna: false. |
Nie. |
| modifiedDatetimeStart | Pliki są filtrowane na podstawie atrybutu Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie 2018-12-01T05:00:00Z. Właściwości mogą mieć wartość NULL, co oznacza, że żaden filtr atrybutu pliku nie jest stosowany do zestawu danych. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość typu data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, są zaznaczone.Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| modifiedDatetimeEnd | Jak wyżej. | |
| enablePartitionDiscovery | W przypadku plików podzielonych na partycje określ, czy analizować partycje ze ścieżki pliku i dodać je jako dodatkowe kolumny źródłowe. Dozwolone wartości to false (wartość domyślna) i true. |
Nie. |
| partitionRootPath | Po włączeniu odnajdywania partycji określ bezwzględną ścieżkę katalogu głównego, aby odczytywać foldery podzielone na partycje jako kolumny danych. Jeśli nie zostanie określony, domyślnie, — Jeśli używasz ścieżki pliku w zestawie danych lub liście plików w źródle, ścieżka główna partycji jest ścieżką skonfigurowaną w zestawie danych. — W przypadku używania filtru folderów wieloznacznych ścieżka główna partycji jest ścieżką podrzędną przed pierwszym symbolem wieloznacznymi. Załóżmy na przykład, że ścieżka w zestawie danych zostanie skonfigurowana jako "root/folder/year=2020/month=08/day=27": - Jeśli określisz ścieżkę główną partycji jako "root/folder/year=2020", działanie kopiowania wygeneruje dwie kolejne kolumny month i day z wartością "08" i "27" odpowiednio, oprócz kolumn wewnątrz plików.— Jeśli nie określono ścieżki głównej partycji, nie zostanie wygenerowana żadna dodatkowa kolumna. |
Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
| Ustawienia DistCp | ||
| distcp Ustawienia | Grupa właściwości do użycia podczas korzystania z hdFS DistCp. | Nie. |
| resourceManagerEndpoint | Punkt końcowy YARN (jeszcze inny negocjator zasobów) | Tak, jeśli używasz narzędzia DistCp |
| tempScriptPath | Ścieżka folderu używana do przechowywania skryptu polecenia temp DistCp. Plik skryptu jest generowany i zostanie usunięty po zakończeniu zadania kopiowania. | Tak, jeśli używasz narzędzia DistCp |
| distcpOptions | Dodatkowe opcje udostępniane do polecenia DistCp. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Przykłady filtrów folderów i plików
W tej sekcji opisano wynikowe zachowanie, jeśli używasz filtru wieloznacznych ze ścieżką folderu i nazwą pliku.
| folderPath | fileName | Cykliczne | Struktura folderu źródłowego i wynik filtru (pobierane są pliki pogrubione ) |
|---|---|---|---|
Folder* |
(puste, użyj wartości domyślnej) | fałsz | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Folder* |
(puste, użyj wartości domyślnej) | prawda | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Folder* |
*.csv |
fałsz | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Folder* |
*.csv |
prawda | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Przykłady listy plików
W tej sekcji opisano zachowanie, które wynika z używania ścieżki listy plików w źródle działanie Kopiuj. Przyjęto założenie, że masz następującą strukturę folderu źródłowego i chcesz skopiować pliki, które mają pogrubiony typ:
| Przykładowa struktura źródła | Zawartość w pliku FileListToCopy.txt | Konfigurowanie |
|---|---|---|
| root FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv Metadane FileListToCopy.txt |
Plik1.csv Podfolder1/File3.csv Podfolder1/File5.csv |
W zestawie danych: - Ścieżka folderu: root/FolderAW źródle działanie Kopiuj: - Ścieżka listy plików: root/Metadata/FileListToCopy.txt Ścieżka listy plików wskazuje plik tekstowy w tym samym magazynie danych, który zawiera listę plików, które chcesz skopiować (jeden plik na wiersz, ze ścieżką względną do ścieżki skonfigurowanej w zestawie danych). |
Kopiowanie danych z systemu plików HDFS przy użyciu narzędzia DistCp
DistCp to natywne narzędzie wiersza polecenia platformy Hadoop do wykonywania kopii rozproszonej w klastrze Hadoop. Po uruchomieniu polecenia w narzędziu DistCp najpierw wyświetla listę wszystkich plików do skopiowania, a następnie tworzy kilka zadań mapy w klastrze Hadoop. Każde zadanie mapy wykonuje kopię binarną ze źródła do ujścia.
Działanie Kopiuj obsługuje używanie narzędzia DistCp do kopiowania plików w taki sposób, jak w usłudze Azure Blob Storage (w tym kopiowania etapowego) lub usługi Azure Data Lake Store. W takim przypadku narzędzie DistCp może korzystać z możliwości klastra zamiast działać w własnym środowisku Integration Runtime. Użycie narzędzia DistCp zapewnia lepszą przepływność kopiowania, zwłaszcza jeśli klaster jest bardzo wydajny. Na podstawie konfiguracji działanie Kopiuj automatycznie konstruuje polecenie DistCp, przesyła je do klastra Usługi Hadoop i monitoruje stan kopiowania.
Wymagania wstępne
Aby użyć narzędzia DistCp do kopiowania plików z systemu plików HDFS do usługi Azure Blob Storage (w tym kopii etapowej) lub usługi Azure Data Lake Store, upewnij się, że klaster Hadoop spełnia następujące wymagania:
Usługi MapReduce i YARN są włączone.
Wersja YARN to 2.5 lub nowsza.
Serwer HDFS jest zintegrowany z docelowym magazynem danych: Azure Blob Storage lub Azure Data Lake Store (ADLS Gen1):
- System plików obiektów blob platformy Azure jest natywnie obsługiwany, ponieważ usługa Hadoop 2.7. Musisz tylko określić ścieżkę JAR w konfiguracji środowiska Hadoop.
- System plików usługi Azure Data Lake Store jest spakowany od usługi Hadoop 3.0.0-alpha1. Jeśli wersja klastra Hadoop jest starsza niż ta wersja, musisz ręcznie zaimportować pakiety JAR powiązane z usługą Azure Data Lake Store (azure-datalake-store.jar) do klastra z tego miejsca i określić ścieżkę pliku JAR w konfiguracji środowiska Hadoop.
Przygotowywanie folderu tymczasowego w systemie plików HDFS. Ten folder tymczasowy jest używany do przechowywania skryptu powłoki DistCp, więc zajmie miejsce na poziomie KB.
Upewnij się, że konto użytkownika podane w połączonej usłudze HDFS ma uprawnienia:
- Prześlij aplikację w usłudze YARN.
- Utwórz podfolder i pliki odczytu/zapisu w folderze tymczasowym.
Konfiguracje
W przypadku konfiguracji i przykładów związanych z platformą DistCp przejdź do sekcji HDFS jako źródła .
Używanie uwierzytelniania Kerberos dla łącznika systemu plików HDFS
Istnieją dwie opcje konfigurowania środowiska lokalnego do korzystania z uwierzytelniania Kerberos dla łącznika systemu plików HDFS. Możesz wybrać ten, który lepiej pasuje do Twojej sytuacji.
- Opcja 1. Dołączanie do własnego środowiska Integration Runtime w obszarze Protokołu Kerberos
- Opcja 2. Włączanie wzajemnego zaufania między domeną systemu Windows i obszarem Protokołu Kerberos
W przypadku każdej opcji upewnij się, że włączono funkcję webhdfs dla klastra Hadoop:
Utwórz jednostkę HTTP i kartę klucza dla plików webhdfs.
Ważne
Podmiot zabezpieczeń protokołu Kerberos HTTP musi rozpoczynać się od ciągu "HTTP/" zgodnie ze specyfikacją PROTOKOŁU HTTP SPNEGO protokołu Kerberos. Dowiedz się więcej tutaj.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>Opcje konfiguracji systemu plików HDFS: dodaj następujące trzy właściwości w pliku
hdfs-site.xml.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Opcja 1. Dołączanie do własnego środowiska Integration Runtime w obszarze Protokołu Kerberos
Wymagania
- Maszyna własnego środowiska Integration Runtime musi dołączyć do obszaru Protokołu Kerberos i nie może dołączyć żadnej domeny systemu Windows.
Sposób konfigurowania
Na serwerze centrum dystrybucji kluczy:
Utwórz podmiot zabezpieczeń i określ hasło.
Ważne
Nazwa użytkownika nie powinna zawierać nazwy hosta.
Kadmin> addprinc <username>@<REALM.COM>
Na maszynie własnego środowiska Integration Runtime:
Uruchom narzędzie Ksetup, aby skonfigurować serwer i obszar centrum dystrybucji kluczy Kerberos (KDC).
Maszyna musi być skonfigurowana jako członek grupy roboczej, ponieważ obszar Kerberos różni się od domeny systemu Windows. Tę konfigurację można osiągnąć, ustawiając obszar Protokołu Kerberos i dodając serwer centrum dystrybucji kluczy, uruchamiając następujące polecenia. Zastąp REALM.COM własną nazwą obszaru.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>Po uruchomieniu tych poleceń uruchom ponownie maszynę.
Sprawdź konfigurację za
Ksetuppomocą polecenia . Dane wyjściowe powinny wyglądać następująco:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
W obszarze roboczym fabryki danych lub synapse:
- Skonfiguruj łącznik HDFS przy użyciu uwierzytelniania systemu Windows wraz z główną nazwą protokołu Kerberos i hasłem, aby nawiązać połączenie ze źródłem danych systemu PLIKÓW HDFS. Aby uzyskać szczegółowe informacje o konfiguracji, zapoznaj się z sekcją właściwości połączonej usługi HDFS.
Opcja 2. Włączanie wzajemnego zaufania między domeną systemu Windows i obszarem Protokołu Kerberos
Wymagania
- Maszyna własnego środowiska Integration Runtime musi dołączyć do domeny systemu Windows.
- Musisz mieć uprawnienia do aktualizowania ustawień kontrolera domeny.
Sposób konfigurowania
Uwaga
Zastąp REALM.COM i AD.COM w poniższym samouczku własną nazwą obszaru i kontrolerem domeny.
Na serwerze centrum dystrybucji kluczy:
Edytuj konfigurację centrum dystrybucji kluczy w pliku krb5.conf , aby umożliwić centrum dystrybucji kluczy zaufania domenie systemu Windows, odwołując się do następującego szablonu konfiguracji. Domyślnie konfiguracja znajduje się w lokalizacji /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }Po skonfigurowaniu pliku uruchom ponownie usługę KDC.
Przygotuj podmiot zabezpieczeń o nazwie krbtgt/REALM.COM@AD.COM na serwerze centrum dystrybucji kluczy za pomocą następującego polecenia:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMW pliku konfiguracji usługi hadoop.security.auth_to_local HDFS dodaj plik
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//.
Na kontrolerze domeny:
Uruchom następujące
Ksetuppolecenia, aby dodać wpis obszaru:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMUstanów relację zaufania z domeny systemu Windows z obszarem Protokołu Kerberos. [hasło] to hasło dla podmiotu zabezpieczeń krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Wybierz algorytm szyfrowania używany w protokole Kerberos.
a. Wybierz pozycję Menedżer serwera> Zasadzanie zasadami>>grupy grupy obiektów domyślnych>lub aktywnych zasad domeny, a następnie wybierz pozycję Edytuj.
b. W okienku Edytor zarządzania zasadami grupy wybierz pozycję Zasady>konfiguracji>komputera Windows Ustawienia Zabezpieczenia Ustawienia>> Lokalne opcje zabezpieczeń zasad>, a następnie skonfiguruj zabezpieczenia sieciowe: Skonfiguruj typy szyfrowania dozwolone dla protokołu Kerberos.
c. Wybierz algorytm szyfrowania, którego chcesz użyć podczas nawiązywania połączenia z serwerem centrum dystrybucji kluczy. Możesz wybrać wszystkie opcje.
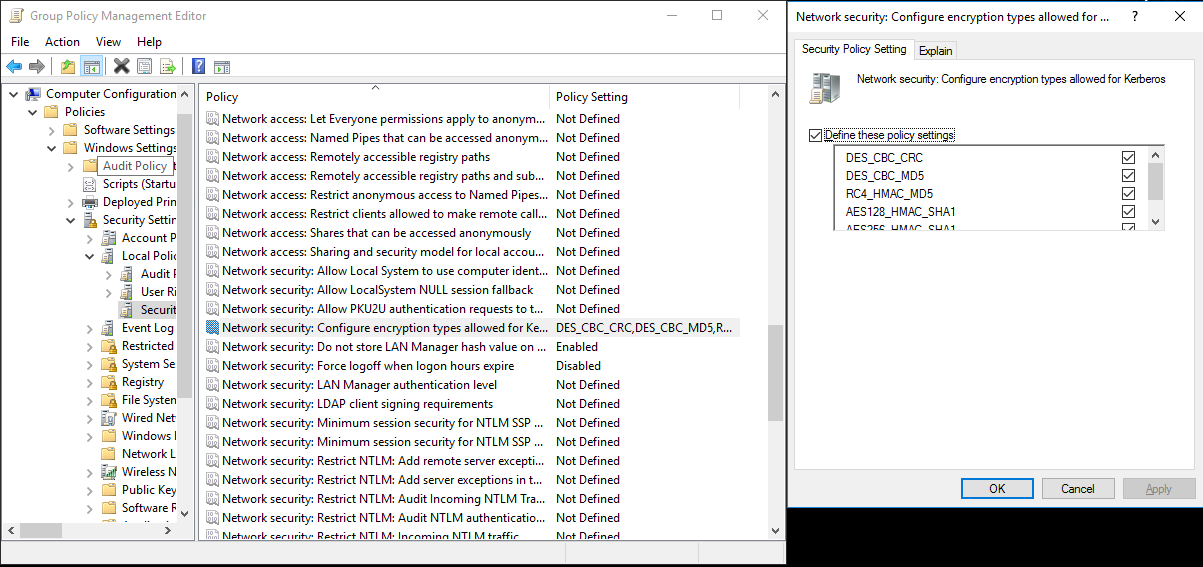
d.
KsetupUżyj polecenia , aby określić algorytm szyfrowania, który ma być używany w określonym obszarze.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Utwórz mapowanie między kontem domeny i podmiotem zabezpieczeń protokołu Kerberos, aby można było użyć podmiotu zabezpieczeń protokołu Kerberos w domenie systemu Windows.
a. Wybierz pozycję narzędzia Administracja istracyjne> Użytkownicy i komputery usługi Active Directory.
b. Skonfiguruj funkcje zaawansowane, wybierając pozycję Wyświetl>funkcje zaawansowane.
c. W okienku Funkcje zaawansowane kliknij prawym przyciskiem myszy konto, do którego chcesz utworzyć mapowania, a następnie w okienku Mapowania nazw wybierz kartę Nazwy protokołu Kerberos.
d. Dodaj podmiot zabezpieczeń z obszaru.
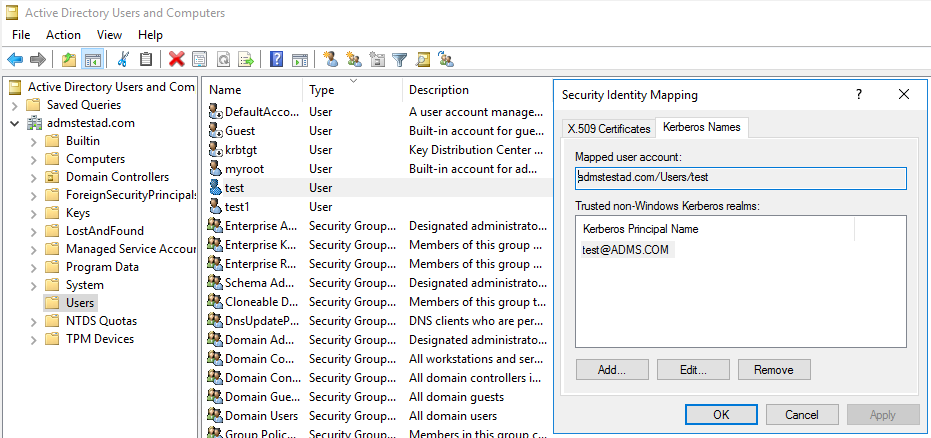
Na maszynie własnego środowiska Integration Runtime:
Uruchom następujące
Ksetuppolecenia, aby dodać wpis obszaru.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
W obszarze roboczym fabryki danych lub synapse:
- Skonfiguruj łącznik HDFS przy użyciu uwierzytelniania systemu Windows razem z kontem domeny lub podmiotem zabezpieczeń protokołu Kerberos, aby nawiązać połączenie ze źródłem danych hdFS. Aby uzyskać szczegółowe informacje o konfiguracji, zobacz sekcję właściwości połączonej usługi HDFS.
Właściwości działania wyszukiwania
Aby uzyskać informacje o właściwościach działania wyszukiwania, zobacz Działanie wyszukiwania.
Usuń właściwości działania
Aby uzyskać informacje o właściwościach działania Usuwania, zobacz Usuwanie działania.
Starsze modele
Uwaga
Następujące modele są nadal obsługiwane w celu zapewnienia zgodności z poprzednimi wersjami. Zalecamy użycie wcześniej omówionego nowego modelu, ponieważ interfejs użytkownika tworzenia zmienił się na generowanie nowego modelu.
Starszy model zestawu danych
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na FileShare | Tak |
| folderPath | Ścieżka do folderu. Obsługiwany jest filtr wieloznaczny. Dozwolone symbole wieloznaczne to * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj ^ klawisza , aby uciec, jeśli rzeczywista nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz. Przykłady: folder główny/podfolder/, zobacz więcej przykładów w przykładach filtru folderów i plików. |
Tak |
| fileName | Filtr nazwy lub symboli wieloznacznych dla plików w ramach określonego "folderPath". Jeśli nie określisz wartości dla tej właściwości, zestaw danych wskazuje wszystkie pliki w folderze. W przypadku filtru dozwolone symbole wieloznaczne są * (dopasowywały zero lub więcej znaków) i ? (dopasowywały zero lub pojedynczy znak).- Przykład 1: "fileName": "*.csv"— Przykład 2: "fileName": "???20180427.txt"Użyj ^ polecenia , aby uniknąć, jeśli rzeczywista nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. |
Nie. |
| modifiedDatetimeStart | Pliki są filtrowane na podstawie atrybutu Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie 2018-12-01T05:00:00Z. Należy pamiętać, że ogólna wydajność przenoszenia danych będzie miała wpływ na włączenie tego ustawienia, gdy chcesz zastosować filtr plików do dużej liczby plików. Właściwości mogą mieć wartość NULL, co oznacza, że żaden filtr atrybutu pliku nie jest stosowany do zestawu danych. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość typu data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, są zaznaczone. |
Nie. |
| modifiedDatetimeEnd | Pliki są filtrowane na podstawie atrybutu Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie 2018-12-01T05:00:00Z. Należy pamiętać, że ogólna wydajność przenoszenia danych będzie miała wpływ na włączenie tego ustawienia, gdy chcesz zastosować filtr plików do dużej liczby plików. Właściwości mogą mieć wartość NULL, co oznacza, że żaden filtr atrybutu pliku nie jest stosowany do zestawu danych. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość typu data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, są zaznaczone. |
Nie. |
| format | Jeśli chcesz skopiować pliki w postaci między magazynami opartymi na plikach (kopiowanie binarne), pomiń sekcję formatowania zarówno w definicjach zestawu danych wejściowych, jak i wyjściowych. Jeśli chcesz przeanalizować pliki w określonym formacie, obsługiwane są następujące typy formatów plików: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Ustaw właściwość type w formacie na jedną z tych wartości. Aby uzyskać więcej informacji, zobacz sekcje Format tekstu, Format JSON, Format Avro, FORMAT ORC i Parquet Format. |
Nie (tylko w scenariuszu kopiowania binarnego) |
| kompresja | Określ typ i poziom kompresji danych. Aby uzyskać więcej informacji, zobacz Obsługiwane formaty plików i koderów kompresji. Obsługiwane typy to: Gzip, Deflate, Bzip2 i ZipDeflate. Obsługiwane poziomy to: Optymalne i najszybsze. |
Nie. |
Napiwek
Aby skopiować wszystkie pliki w folderze, określ tylko folderPath .
Aby skopiować pojedynczy plik o określonej nazwie, określ folderPath ze częścią folderu i fileName nazwą pliku.
Aby skopiować podzbiór plików w folderze, określ folderPath ze częścią folderu i fileName z filtrem wieloznacznymi.
Przykład:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Starszy model źródłowy działanie Kopiuj
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działanie Kopiuj musi być ustawiona na HdfsSource. | Tak |
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Gdy rekursywna ma wartość true , a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie zostanie skopiowany ani utworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. |
Nie. |
| distcp Ustawienia | Grupa właściwości podczas korzystania z narzędzia DistCp systemu plików HDFS. | Nie. |
| resourceManagerEndpoint | Punkt końcowy usługi Resource Manager usługi YARN | Tak, jeśli używasz narzędzia DistCp |
| tempScriptPath | Ścieżka folderu używana do przechowywania skryptu polecenia temp DistCp. Plik skryptu jest generowany i zostanie usunięty po zakończeniu zadania kopiowania. | Tak, jeśli używasz narzędzia DistCp |
| distcpOptions | Dodatkowe opcje są udostępniane do polecenia DistCp. | Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład: źródło hdFS w działanie Kopiuj przy użyciu narzędzia DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia przez działanie Kopiuj, zobacz obsługiwane magazyny danych.