Mapowanie schematu i typu danych w działaniu kopiowania
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano, jak działanie kopiowania usługi Azure Data Factory wykonuje mapowanie schematu i mapowanie typu danych ze źródłowych danych na dane ujścia.
Mapowanie schematu
Mapowanie domyślne
Domyślnie działanie kopiowania mapuje dane źródłowe na ujście według nazw kolumn w sposób uwzględniający wielkość liter. Jeśli ujście nie istnieje, na przykład zapisywanie w plikach, nazwy pól źródłowych będą utrwalane jako nazwy ujścia. Jeśli ujście już istnieje, musi zawierać wszystkie kolumny kopiowane ze źródła. Takie mapowanie domyślne obsługuje elastyczne schematy i dryf schematu od źródła do ujścia od wykonania do wykonania — wszystkie dane zwrócone przez źródłowy magazyn danych można skopiować do ujścia.
Jeśli źródło jest plikiem tekstowym bez wiersza nagłówka, jawne mapowanie jest wymagane, ponieważ źródło nie zawiera nazw kolumn.
Jawne mapowanie
Możesz również określić jawne mapowanie, aby dostosować mapowanie kolumny/pola ze źródła do ujścia w zależności od potrzeb. Za pomocą jawnego mapowania można kopiować tylko częściowe dane źródłowe do ujścia lub mapować dane źródłowe na ujście z różnymi nazwami lub przekształcać dane tabelaryczne/hierarchiczne. działanie Kopiuj:
- Odczytuje dane ze źródła i określa schemat źródłowy.
- Stosuje zdefiniowane mapowanie.
- Zapisuje dane do ujścia.
Dowiedz się więcej na następujące tematy:
- Tabelaryczne źródło do ujścia tabelarycznego
- Hierarchiczne źródło do ujścia tabelarycznego
- Tabelaryczne/hierarchiczne źródło ujścia hierarchicznego
Mapowanie można skonfigurować w interfejsie użytkownika tworzenia — działanie kopiowania —>> kartę mapowania lub programowo określić mapowanie w działaniu kopiowania —>translator właściwość. Następujące właściwości są obsługiwane w translator :mappings> tablica -> obiekty ->source i sink, które wskazują konkretną kolumnę/pole do mapowania danych.
| Właściwości | Opis | Wymagania |
|---|---|---|
| name | Nazwa źródła lub pola ujścia. Zastosuj do tabelarycznego źródła i ujścia. | Tak |
| Porządkowych | Indeks kolumny. Zacznij od 1. Zastosuj i wymagane w przypadku używania tekstu rozdzielanego bez wiersza nagłówka. |
Nie. |
| path | Wyrażenie ścieżki JSON dla każdego pola w celu wyodrębnienia lub mapowania. Zastosuj do hierarchicznego źródła i ujścia, na przykład łączników Azure Cosmos DB, MongoDB lub REST. W przypadku pól w obiekcie głównym ścieżka JSON zaczyna się od katalogu głównego $; w przypadku pól wewnątrz tablicy wybranej przez collectionReference właściwość ścieżka JSON rozpoczyna się od elementu tablicy bez $. |
Nie. |
| type | Tymczasowy typ danych kolumny źródłowej lub ujścia. Ogólnie rzecz biorąc, nie trzeba określać ani zmieniać tej właściwości. Dowiedz się więcej o mapowaniu typów danych. | Nie. |
| kultura | Kultura kolumny źródłowej lub ujścia. Zastosuj, gdy typ ma wartość Datetime lub Datetimeoffset. Wartość domyślna to en-us.Ogólnie rzecz biorąc, nie trzeba określać ani zmieniać tej właściwości. Dowiedz się więcej o mapowaniu typów danych. |
Nie. |
| format | Ciąg formatu, który ma być używany, gdy typ to Datetime lub Datetimeoffset. Zapoznaj się z tematem Niestandardowe ciągi formatu daty i godziny, aby dowiedzieć się, jak formatować datę/godzinę. Ogólnie rzecz biorąc, nie trzeba określać ani zmieniać tej właściwości. Dowiedz się więcej o mapowaniu typów danych. |
Nie. |
Następujące właściwości są obsługiwane translator poza elementem mappings:
| Właściwości | Opis | Wymagania |
|---|---|---|
| collectionReference | Zastosuj podczas kopiowania danych ze źródła hierarchicznego, takiego jak Azure Cosmos DB, MongoDB lub łączniki REST. Jeśli chcesz iterować i wyodrębniać dane z obiektów wewnątrz pola tablicy z tym samym wzorcem i konwertować na wiersz dla każdego obiektu, określ ścieżkę JSON tej tablicy do wykonania krzyżowego. |
Nie. |
Tabelaryczne źródło do ujścia tabelarycznego
Na przykład aby skopiować dane z usługi Salesforce do usługi Azure SQL Database i jawnie zamapować trzy kolumny:
Na działaniu kopiowania —> mapowanie kliknij przycisk Importuj schematy, aby zaimportować schematy źródłowe i ujścia.
Zamapuj wymagane pola i wyklucz/usuń resztę.

To samo mapowanie można skonfigurować jako następujące w ładunku działania kopiowania (zobacz translator):
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Aby skopiować dane z rozdzielonych plików tekstowych bez wiersza nagłówka, kolumny są reprezentowane przez porządkowe zamiast nazw.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Hierarchiczne źródło do ujścia tabelarycznego
Podczas kopiowania danych z hierarchicznego źródła do ujścia tabelarycznego działanie kopiowania obsługuje następujące możliwości:
- Wyodrębnianie danych z obiektów i tablic.
- Krzyżowe stosowanie wielu obiektów z tym samym wzorcem z tablicy, w tym przypadku w celu przekonwertowania jednego obiektu JSON na wiele rekordów w wyniku tabelarycznym.
Aby uzyskać bardziej zaawansowaną transformację hierarchiczną-tabelaryczną, można użyć Przepływ danych.
Jeśli na przykład masz źródłowy dokument bazy danych MongoDB z następującą zawartością:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
I chcesz skopiować go do pliku tekstowego w następującym formacie z wierszem nagłówka, spłaszczając dane wewnątrz tablicy (order_pd i order_price) i sprzężenie krzyżowe ze wspólnymi informacjami głównymi (liczba, data i miasto):
| Ordernumber | orderDate | order_pd | order_price | miejscowość |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Takie mapowanie można zdefiniować w interfejsie użytkownika tworzenia usługi Data Factory:
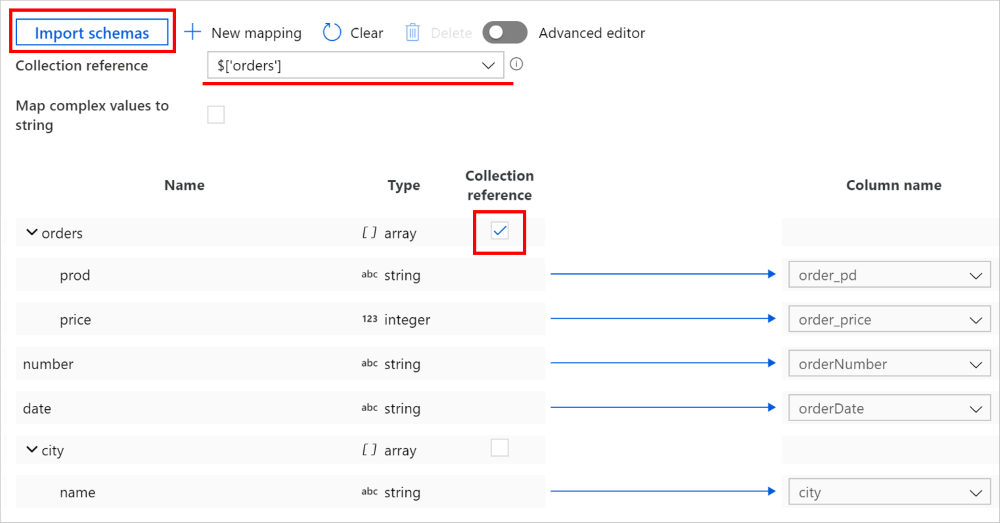
Na działaniu kopiowania —> mapowanie kliknij przycisk Importuj schematy, aby zaimportować schematy źródłowe i ujścia. Ponieważ usługa próbkuje kilka pierwszych obiektów podczas importowania schematu, jeśli jakiekolwiek pole nie jest wyświetlane, możesz dodać go do właściwej warstwy w hierarchii — umieść kursor na istniejącej nazwie pola i wybierz dodanie węzła, obiektu lub tablicy.
Wybierz tablicę, z której chcesz iterować i wyodrębniać dane. Zostanie on automatycznie wypełniony jako odwołanie do kolekcji. Uwaga tylko jedna tablica jest obsługiwana w przypadku takiej operacji.
Zamapuj wymagane pola do ujścia. Usługa automatycznie określa odpowiednie ścieżki JSON dla strony hierarchicznej.
Uwaga
W przypadku rekordów, w których tablica oznaczona jako odwołanie do kolekcji jest pusta, a pole wyboru jest zaznaczone, cały rekord jest pomijany.
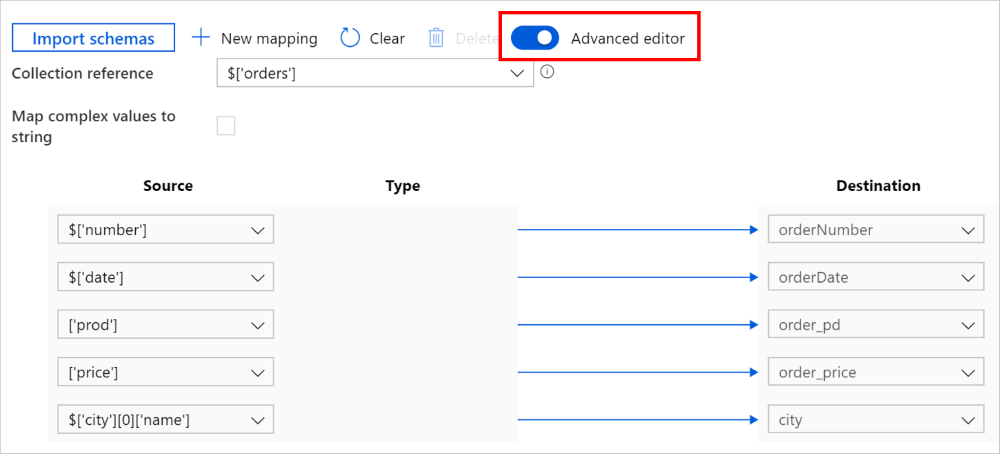
Możesz również przełączyć się do edytora zaawansowanego. W tym przypadku możesz bezpośrednio wyświetlić i edytować ścieżki JSON pól. Jeśli zdecydujesz się dodać nowe mapowanie w tym widoku, określ ścieżkę JSON.
To samo mapowanie można skonfigurować jako następujące w ładunku działania kopiowania (zobacz translator):
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
Tabelaryczne/hierarchiczne źródło ujścia hierarchicznego
Przepływ środowiska użytkownika jest podobny do hierarchicznego źródła do ujścia tabelarycznego.
Podczas kopiowania danych ze źródła tabelarycznego do ujścia hierarchicznego zapisywanie w tablicy wewnątrz obiektu nie jest obsługiwane.
Podczas kopiowania danych ze źródła hierarchicznego do ujścia hierarchicznego można dodatkowo zachować hierarchię całej warstwy, wybierając obiekt/tablicę i mapując ją na ujście bez dotykania pól wewnętrznych.
Aby uzyskać bardziej zaawansowane przekształcanie danych, można użyć Przepływ danych.
Mapowanie parametrów
Jeśli chcesz utworzyć potok templatized w celu dynamicznego kopiowania dużej liczby obiektów, ustal, czy możesz użyć domyślnego mapowania, czy musisz zdefiniować jawne mapowanie dla odpowiednich obiektów.
Jeśli wymagane jest jawne mapowanie, możesz:
Zdefiniuj parametr z typem obiektu na poziomie potoku, na przykład
mapping.Parametryzowanie mapowania: na działaniu kopiowania —> karta mapowania wybierz, aby dodać zawartość dynamiczną i wybrać powyższy parametr. Ładunek działania będzie następujący:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Skonstruuj wartość, która ma być przekazywana do parametru mapowania. Powinien on być całym obiektem definicji, odwoływać się do przykładów w sekcji jawnego
translatormapowania. Na przykład w przypadku źródła tabelarycznego do kopii ujścia tabelarycznego wartość powinna mieć wartość{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}.
Mapowanie typu danych
działanie Kopiuj wykonuje typy źródłowe do mapowania typów ujścia przy użyciu następującego przepływu:
- Konwertowanie z natywnych typów danych źródłowych na tymczasowe typy danych używane przez potoki usługi Azure Data Factory i Synapse.
- Automatycznie konwertuj typ danych tymczasowych zgodnie z potrzebami, aby dopasować odpowiednie typy ujścia, które mają zastosowanie zarówno do mapowania domyślnego, jak i jawnego mapowania.
- Konwertowanie z typów danych tymczasowych na natywne typy danych ujścia.
działanie Kopiuj obecnie obsługuje następujące tymczasowe typy danych: Boolean, Byte, Byte array, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 i UInt64.
Następujące konwersje typów danych są obsługiwane między typami tymczasowymi ze źródła do ujścia.
| Źródło\ujście | Wartość logiczna | Tablica bajtów | Dziesiętne | Data/godzina (1) | Zmiennoprzecinkowy (2) | Identyfikator GUID | Liczba całkowita (3) | String | przedział_czasu |
|---|---|---|---|---|---|---|---|---|---|
| Wartość logiczna | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Tablica bajtów | ✓ | ✓ | |||||||
| Data/godzina | ✓ | ✓ | |||||||
| Dziesiętne | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Zmiennoprzecinkowy | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Identyfikator GUID | ✓ | ✓ | |||||||
| Liczba całkowita | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| przedział_czasu | ✓ | ✓ |
(1) Data/godzina obejmuje wartości DateTime i DateTimeOffset.
(2) Zmiennoprzecinkowy zawiera pojedynczy i podwójny.
(3) Liczba całkowita obejmuje SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 i UInt64.
Uwaga
- Obecnie taka konwersja typu danych jest obsługiwana podczas kopiowania między danymi tabelarycznymi. Hierarchiczne źródła/ujścia nie są obsługiwane, co oznacza, że między typami tymczasowymi źródła i ujścia nie ma zdefiniowanej przez system konwersji typu danych.
- Ta funkcja działa z najnowszym modelem zestawu danych. Jeśli ta opcja nie jest widoczna w interfejsie użytkownika, spróbuj utworzyć nowy zestaw danych.
Następujące właściwości są obsługiwane w działaniu kopiowania na potrzeby konwersji typu danych (w translator sekcji dotyczącej programowego tworzenia):
| Właściwości | Opis | Wymagania |
|---|---|---|
| typeConversion | Włącz nowe środowisko konwersji typów danych. Wartość domyślna jest fałszywa ze względu na zgodność z poprzednimi wersjami. W przypadku nowych działań kopiowania utworzonych za pośrednictwem interfejsu użytkownika tworzenia usługi Data Factory od końca czerwca 2020 r. ta konwersja typu danych jest domyślnie włączona w celu uzyskania najlepszego środowiska i można zobaczyć następujące ustawienia konwersji typów w działaniu kopiowania —> karta mapowania dla odpowiednich scenariuszy. Aby programowo utworzyć potok, należy jawnie ustawić typeConversion właściwość true, aby ją włączyć.W przypadku istniejących działań kopiowania utworzonych przed wydaniem tej funkcji nie będą widoczne opcje konwersji typów w interfejsie użytkownika tworzenia w celu zapewnienia zgodności z poprzednimi wersjami. |
Nie. |
| typeConversion Ustawienia | Grupa ustawień konwersji typów. Zastosuj, gdy typeConversion jest ustawiona wartość true. Wszystkie poniższe właściwości znajdują się w tej grupie. |
Nie. |
Pod typeConversionSettings |
||
| allowDataTruncation | Zezwalaj na obcinanie danych podczas konwertowania danych źródłowych na ujście z innym typem podczas kopiowania, na przykład z liczby dziesiętnej do liczby całkowitej, od datetimeOffset do daty/godziny. Domyślna wartość to true. |
Nie. |
| treatBooleanAsNumber | Traktuj wartości logiczne jako liczby, na przykład wartość true jako 1. Wartość domyślna to false. |
Nie. |
| Datetimeformat | Formatuj ciąg podczas konwertowania między datami bez przesunięcia strefy czasowej i ciągów, na przykład yyyy-MM-dd HH:mm:ss.fff. Aby uzyskać szczegółowe informacje, zobacz Niestandardowe ciągi formatu daty i godziny. |
Nie. |
| dateTimeOffsetFormat | Formatuj ciąg podczas konwertowania między datami z przesunięciem strefy czasowej i ciągami, na przykład yyyy-MM-dd HH:mm:ss.fff zzz. Aby uzyskać szczegółowe informacje, zobacz Niestandardowe ciągi formatu daty i godziny. |
Nie. |
| timeSpanFormat | Formatuj ciąg podczas konwertowania między okresami i ciągami, na przykład dd\.hh\:mm. Szczegółowe informacje można znaleźć w artykule Custom TimeSpan Format Strings (Niestandardowe ciągi formatu TimeSpan). |
Nie. |
| kultura | Informacje o kulturze, które mają być używane podczas konwertowania typów, na przykład en-us lub fr-fr. |
Nie. |
Przykład:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Starsze modele
Uwaga
Poniższe modele do mapowania kolumn źródłowych/pól na ujście są nadal obsługiwane w przypadku zgodności z poprzednimi wersjami. Zalecamy użycie nowego modelu wymienionego w mapowaniu schematu. Interfejs użytkownika tworzenia został przełączony na generowanie nowego modelu.
Alternatywne mapowanie kolumn (starszy model)
Możesz określić działanie kopiowania —>translator do>columnMappings mapowania między danymi w kształcie tabelarycznego. W takim przypadku sekcja "struktura" jest wymagana zarówno dla zestawów danych wejściowych, jak i wyjściowych. Mapowanie kolumn obsługuje mapowanie wszystkich lub podzestawu kolumn w źródłowym zestawie danych "struktura" na wszystkie kolumny w zestawie danych ujścia "struktura". Poniżej przedstawiono warunki błędów, które powodują wyjątek:
- Wynik zapytania magazynu danych źródłowych nie ma nazwy kolumny określonej w sekcji "struktura" wejściowego zestawu danych.
- Magazyn danych ujścia (jeśli ze wstępnie zdefiniowanym schematem) nie ma nazwy kolumny określonej w sekcji "struktura" wyjściowego zestawu danych.
- Mniej kolumn lub więcej kolumn w "strukturze" zestawu danych ujścia niż określono w mapowaniu.
- Zduplikowane mapowanie.
W poniższym przykładzie wejściowy zestaw danych ma strukturę i wskazuje tabelę w lokalnej bazie danych Oracle.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
W tym przykładzie wyjściowy zestaw danych ma strukturę i wskazuje tabelę w usłudze Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
Poniższy kod JSON definiuje działanie kopiowania w potoku. Kolumny ze źródła zamapowane na kolumny w ujściu przy użyciu właściwości translator ->columnMappings .
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
Jeśli używasz składni "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" w celu określenia mapowania kolumn, nadal jest obsługiwana zgodnie z rzeczywistym użyciem.
Alternatywne mapowanie schematu (starszy model)
Możesz określić działanie kopiowania —>translator aby>schemaMapping mapować dane w kształcie hierarchii i dane tabelaryczne, na przykład skopiować z bazy danych MongoDB/REST do pliku tekstowego i skopiować z bazy danych Oracle do usługi Azure Cosmos DB dla bazy danych MongoDB. Następujące właściwości są obsługiwane w sekcji działania translator kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type translatora działań kopiowania musi być ustawiona na: TabularTranslator | Tak |
| schemaMapping | Kolekcja par klucz-wartość, która reprezentuje relację mapowania z boku źródła do strony ujścia. - Klucz: reprezentuje źródło. W przypadku źródła tabelarycznego określ nazwę kolumny zdefiniowaną w strukturze zestawu danych. W przypadku źródła hierarchicznego określ wyrażenie ścieżki JSON dla każdego pola do wyodrębniania i mapowania. - Wartość: reprezentuje ujście. W przypadku ujścia tabelarycznego określ nazwę kolumny zdefiniowaną w strukturze zestawu danych. W przypadku ujścia hierarchicznego określ wyrażenie ścieżki JSON dla każdego pola do wyodrębniania i mapowania. W przypadku danych hierarchicznych w przypadku pól w obiekcie głównym ścieżka JSON zaczyna się od katalogu głównego $; w przypadku pól wewnątrz tablicy wybranej przez collectionReference właściwość ścieżka JSON rozpoczyna się od elementu tablicy. |
Tak |
| collectionReference | Jeśli chcesz iterować i wyodrębniać dane z obiektów wewnątrz pola tablicy z tym samym wzorcem i konwertować na wiersz dla każdego obiektu, określ ścieżkę JSON tej tablicy do wykonania krzyżowego. Ta właściwość jest obsługiwana tylko wtedy, gdy dane hierarchiczne są źródłem. | Nie. |
Przykład: kopiowanie z bazy danych MongoDB do bazy danych Oracle:
Jeśli na przykład masz dokument bazy danych MongoDB z następującą zawartością:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
i chcesz skopiować je do tabeli Azure SQL w następującym formacie, spłaszczając dane wewnątrz tablicy (order_pd i order_price) oraz sprzężenie krzyżowe ze wspólnymi informacjami głównymi (liczba, data i miasto):
| Ordernumber | orderDate | order_pd | order_price | miejscowość |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Skonfiguruj regułę mapowania schematu jako następujący przykładowy kod JSON działania kopiowania:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Powiązana zawartość
Zobacz inne artykuły dotyczące działania kopiowania: