Tworzenie magazynu SQL
Administratorzy obszarów roboczych i wystarczająco uprzywilejowani użytkownicy mogą konfigurować magazyny SQL i zarządzać nimi. W tym artykule opisano sposób tworzenia, edytowania i monitorowania istniejących magazynów SQL.
Magazyny SQL można również tworzyć przy użyciu interfejsu API usługi SQL Warehouse lub narzędzia Terraform.
Usługa Databricks zaleca używanie bezserwerowych magazynów SQL, jeśli są dostępne.
Uwaga
Większość użytkowników nie może tworzyć magazynów SQL, ale może ponownie uruchomić dowolny magazyn SQL, z którą może nawiązać połączenie. Zobacz Co to jest usługa SQL Warehouse?.
Wymagania
Magazyny SQL mają następujące wymagania:
Aby utworzyć magazyn SQL Warehouse, musisz być administratorem obszaru roboczego lub użytkownikiem z nieograniczonymi uprawnieniami do tworzenia klastra.
Zanim będzie można utworzyć bezserwerowy magazyn SQL Warehouse w regionie obsługującym tę funkcję, mogą istnieć wymagane kroki. Zobacz Włączanie bezserwerowych magazynów SQL.
W przypadku magazynów klasycznych lub pro sql konto platformy Azure musi mieć odpowiedni limit przydziału procesorów wirtualnych. Domyślny limit przydziału procesorów wirtualnych jest zwykle odpowiedni do utworzenia bezserwerowego magazynu SQL Warehouse, ale może nie wystarczyć do skalowania magazynu SQL lub utworzenia dodatkowych magazynów. Zobacz Wymagany limit przydziału procesorów wirtualnych platformy Azure dla magazynów klasycznych i pro SQL. Możesz zażądać dodatkowego limitu przydziału procesorów wirtualnych. Twoje konto platformy Azure może mieć ograniczenia dotyczące limitu przydziału procesorów wirtualnych, które można zażądać. Aby uzyskać więcej informacji, skontaktuj się z zespołem ds. kont platformy Azure.
Tworzenie magazynu SQL
Aby utworzyć usługę SQL Warehouse przy użyciu internetowego interfejsu użytkownika:
- Kliknij pozycję SQL Warehouses (Magazyny SQL) na pasku bocznym.
- Kliknij pozycję Utwórz usługę SQL Warehouse.
- Wprowadź nazwę magazynu.
- (Opcjonalnie) Konfigurowanie ustawień magazynu. Zobacz Konfigurowanie ustawień usługi SQL Warehouse.
- (Opcjonalnie) Konfigurowanie opcji zaawansowanych. Zobacz Opcje zaawansowane.
- Kliknij pozycję Utwórz.
- (Opcjonalnie) Konfigurowanie dostępu do usługi SQL Warehouse. Zobacz Zarządzanie usługą SQL Warehouse.
Utworzony magazyn jest uruchamiany automatycznie.
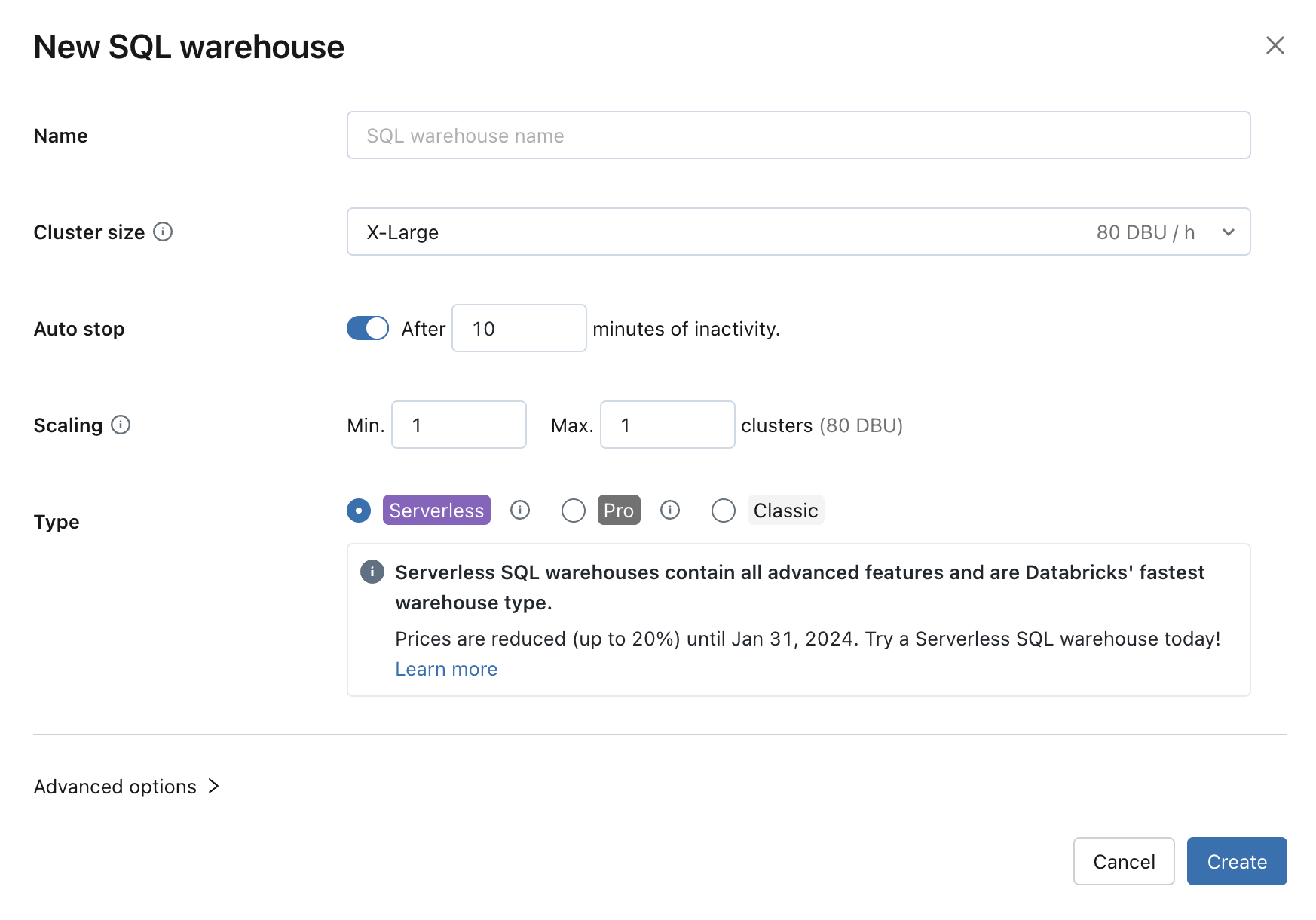
Konfigurowanie ustawień usługi SQL Warehouse
Podczas tworzenia lub edytowania usługi SQL Warehouse można zmodyfikować następujące ustawienia:
Rozmiar klastra reprezentuje rozmiar węzła sterownika i liczbę węzłów roboczych skojarzonych z klastrem. Wartość domyślna to X-Large. Aby zmniejszyć opóźnienie zapytań, zwiększ rozmiar.
Automatyczne zatrzymywanie określa, czy magazyn zatrzymuje się, jeśli jest bezczynny przez określoną liczbę minut. Bezczynne magazyny SQL nadal gromadzą opłaty za użycie jednostek DBU i wystąpień w chmurze, dopóki nie zostaną zatrzymane.
- Pro i klasyczne magazyny SQL: wartość domyślna to 45 minut, co jest zalecane do typowego użycia. Minimalna wartość to 10 minut.
- Bezserwerowe magazyny SQL: wartość domyślna to 10 minut, co jest zalecane do typowego użycia. Minimalna wartość to 5 minut, gdy używasz interfejsu użytkownika. Pamiętaj, że możesz utworzyć bezserwerową usługę SQL Warehouse przy użyciu interfejsu API usługi SQL Warehouses. W takim przypadku można ustawić wartość Automatycznego zatrzymywania nawet 1 minutę.
Skalowanie ustawia minimalną i maksymalną liczbę klastrów, które będą używane dla zapytania. Wartość domyślna to minimum i maksymalnie jeden klaster. Możesz zwiększyć maksymalną liczbę klastrów, jeśli chcesz obsługiwać więcej współbieżnych użytkowników dla danego zapytania. Usługa Azure Databricks zaleca klaster dla każdego 10 współbieżnych zapytań.
Aby zachować optymalną wydajność, usługa Databricks okresowo przetwarza klastry. W okresie recyklingu można tymczasowo zobaczyć liczbę klastrów, która przekracza maksymalną wartość, ponieważ usługa Databricks przenosi nowe obciążenia do nowego klastra i czeka na odtwarzanie starego klastra do momentu ukończenia wszystkich otwartych obciążeń.
Typ określa typ magazynu. Jeśli na twoim koncie jest włączona opcja bezserwerowa, wartość domyślna to bezserwerowa. Zobacz Typy usługi SQL Warehouse, aby zapoznać się z listą.
Opcje zaawansowane
Skonfiguruj następujące opcje zaawansowane, rozwijając obszar Opcje zaawansowane podczas tworzenia nowego magazynu SQL Lub edytując istniejący magazyn SQL Warehouse. Te opcje można również skonfigurować przy użyciu interfejsu API usługi SQL Warehouse.
Tagi: tagi umożliwiają monitorowanie kosztów zasobów w chmurze używanych przez użytkowników i grupy w organizacji. Tagi są określane jako pary klucz-wartość.
Wykaz aparatu Unity: jeśli katalog aparatu Unity jest włączony dla obszaru roboczego, jest to ustawienie domyślne dla wszystkich nowych magazynów w obszarze roboczym. Jeśli wykaz aparatu Unity nie jest włączony dla obszaru roboczego, nie widzisz tej opcji. Sprawdź temat Co to jest wykaz Unity?.
Kanał: użyj kanału w wersji zapoznawczej, aby przetestować nowe funkcje, w tym zapytania i pulpity nawigacyjne, zanim stanie się standardem SQL usługi Databricks.
Informacje o wersji zawierają informacje o najnowszej wersji zapoznawczej.
Ważne
Usługa Databricks zaleca używanie wersji zapoznawczej dla obciążeń produkcyjnych. Ponieważ tylko administratorzy obszaru roboczego mogą wyświetlać właściwości magazynu, w tym jego kanał, należy rozważyć wskazanie, że usługa Databricks SQL Warehouse używa wersji zapoznawczej w nazwie tego magazynu, aby uniemożliwić użytkownikom korzystanie z niej w przypadku obciążeń produkcyjnych.
Zarządzanie usługą SQL Warehouse
Administratorzy obszaru roboczego i użycie z uprawnieniami CAN MANAGE w usłudze SQL Warehouse mogą wykonywać następujące zadania w istniejącym magazynie SQL Warehouse:
- Aby zatrzymać uruchomiony magazyn, kliknij ikonę zatrzymania obok magazynu.
- Aby uruchomić zatrzymany magazyn, kliknij ikonę uruchamiania obok magazynu.
- Aby edytować magazyn, kliknij menu
 kebab, a następnie kliknij przycisk Edytuj.
kebab, a następnie kliknij przycisk Edytuj. - Aby dodać i edytować uprawnienia, kliknij menu kebab, a następnie kliknij pozycję Uprawnienia. Aby dowiedzieć się więcej na temat poziomów uprawnień, zobacz Listy ACL usługi SQL Warehouse.
- Aby uaktualnić usługę SQL Warehouse do bezserwerowej, kliknij menu kebab, a następnie kliknij pozycję Uaktualnij do bezserwerowego.
- Aby usunąć magazyn, kliknij menu kebab, a następnie kliknij pozycję Usuń.
Uwaga
Skontaktuj się z przedstawicielem usługi Databricks, aby przywrócić usunięte magazyny w ciągu 14 dni.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla