Tworzenie i uruchamianie zadań usługi Azure Databricks
W tym artykule opisano sposób tworzenia i uruchamiania zadań usługi Azure Databricks przy użyciu interfejsu użytkownika zadań.
Aby dowiedzieć się więcej o opcjach konfiguracji zadań i sposobie edytowania istniejących zadań, zobacz Konfigurowanie ustawień dla zadań usługi Azure Databricks.
Aby dowiedzieć się, jak zarządzać przebiegami zadań i monitorować je, zobacz Wyświetlanie przebiegów zadań i zarządzanie nimi.
Aby utworzyć pierwszy przepływ pracy za pomocą zadania usługi Azure Databricks, zobacz przewodnik Szybki start.
Ważne
- Obszar roboczy jest ograniczony do 1000 współbieżnych uruchomień zadań. Odpowiedź
429 Too Many Requestsjest zwracana po zażądaniu uruchomienia, gdy natychmiastowe uruchomienie nie jest możliwe. - Liczba zadań, które można utworzyć w obszarze roboczym w ciągu godziny, jest ograniczona do 10000 (obejmuje "przesyłanie przebiegów"). Ten limit wpływa również na zadania utworzone przez przepływy pracy notesu i interfejsu API REST.
Tworzenie i uruchamianie zadań przy użyciu interfejsu wiersza polecenia, interfejsu API lub notesów
- Aby dowiedzieć się więcej na temat tworzenia i uruchamiania zadań przy użyciu interfejsu wiersza polecenia usługi Databricks, zobacz Co to jest interfejs wiersza polecenia usługi Databricks?.
- Aby dowiedzieć się więcej na temat tworzenia i uruchamiania zadań przy użyciu interfejsu API zadań, zobacz Zadania w dokumentacji interfejsu API REST.
- Aby dowiedzieć się, jak uruchamiać i planować zadania bezpośrednio w notesie usługi Databricks, zobacz Tworzenie zaplanowanych zadań notesu i zarządzanie nimi.
Tworzenie zadania
Wykonaj jedną z następujących czynności:
- Kliknij pozycję
 Przepływy pracy na pasku bocznym i kliknij pozycję .
Przepływy pracy na pasku bocznym i kliknij pozycję .
- Na pasku bocznym kliknij pozycję
 Nowy i wybierz pozycję Zadanie.
Nowy i wybierz pozycję Zadanie.
Na karcie Zadania zostanie wyświetlone okno dialogowe tworzenia zadania wraz z panelem bocznym Szczegóły zadania zawierającym ustawienia na poziomie zadania.
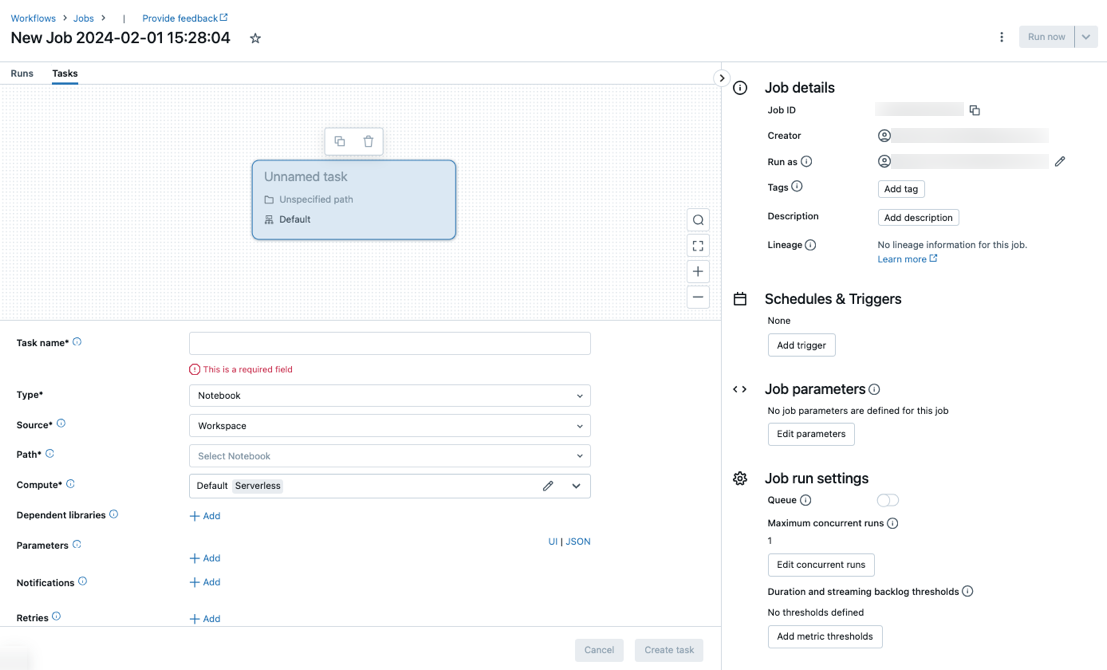
- Kliknij pozycję
Zastąp ciąg Nowe zadanie... nazwą zadania.
Wprowadź nazwę zadania w polu Nazwa zadania.
W menu rozwijanym Typ wybierz typ zadania do uruchomienia. Zobacz Opcje typu zadania.
Skonfiguruj klaster, w którym jest uruchamiane zadanie. Domyślnie środowisko obliczeniowe bezserwerowe jest wybierane, jeśli obszar roboczy znajduje się w obszarze roboczym obsługującym wykaz aparatu Unity i wybrano zadanie obsługiwane przez bezserwerowe obliczenia dla przepływów pracy. Zobacz Uruchamianie zadania usługi Azure Databricks z bezserwerowymi obliczeniami dla przepływów pracy. Jeśli przetwarzanie bezserwerowe jest niedostępne lub chcesz użyć innego typu obliczeniowego, możesz wybrać nowy klaster zadań lub istniejący klaster ogólnego przeznaczenia w menu rozwijanym Obliczenia .
- Nowy klaster zadań: kliknij pozycję Edytuj w menu rozwijanym Klaster i ukończ konfigurację klastra.
- Istniejący klaster all-purpose: wybierz istniejący klaster z menu rozwijanego Klaster . Aby otworzyć klaster na nowej stronie, kliknij ikonę
 po prawej stronie nazwy klastra i opisu.
po prawej stronie nazwy klastra i opisu.
Aby dowiedzieć się więcej na temat wybierania i konfigurowania klastrów do uruchamiania zadań, zobacz Używanie obliczeń usługi Azure Databricks z zadaniami.
Aby dodać biblioteki zależne, kliknij pozycję + Dodaj obok pozycji Biblioteki zależne. Zobacz Konfigurowanie bibliotek zależnych.
Parametry zadania można przekazać. Aby uzyskać informacje na temat wymagań dotyczących formatowania i przekazywania parametrów, zobacz Przekazywanie parametrów do zadania zadania usługi Azure Databricks.
Aby opcjonalnie otrzymywać powiadomienia o rozpoczęciu, powodzeniu lub niepowodzeniu zadania, kliknij pozycję + Dodaj obok pozycji Wiadomości e-mail. Powiadomienia o błędach są wysyłane w przypadku niepowodzenia zadania początkowego i wszelkich kolejnych ponownych prób. Aby filtrować powiadomienia i zmniejszyć liczbę wysłanych wiadomości e-mail, sprawdź powiadomienia wyciszenia dotyczące pominiętych przebiegów, wycisz powiadomienia dotyczące anulowanych przebiegów lub wycisz powiadomienia do ostatniej próby.
Aby opcjonalnie skonfigurować zasady ponawiania dla zadania, kliknij pozycję + Dodaj obok pozycji Ponawianie prób. Zobacz Konfigurowanie zasad ponawiania dla zadania.
Aby opcjonalnie skonfigurować oczekiwany czas trwania lub limit czasu zadania, kliknij pozycję + Dodaj obok pozycji Próg czasu trwania. Zobacz Konfigurowanie oczekiwanego czasu ukończenia lub limitu czasu dla zadania.
Kliknij pozycję Utwórz.
Po utworzeniu pierwszego zadania można skonfigurować ustawienia na poziomie zadania, takie jak powiadomienia, wyzwalacze zadań i uprawnienia. Zobacz Edytowanie zadania.
Aby dodać kolejne zadanie, kliknij  widok DAG. Opcja udostępnionego klastra jest udostępniana, jeśli wybrano opcję Obliczenia bezserwerowe lub skonfigurowano nowy klaster zadań dla poprzedniego zadania. Klaster można również skonfigurować dla każdego zadania podczas tworzenia lub edytowania zadania. Aby dowiedzieć się więcej na temat wybierania i konfigurowania klastrów do uruchamiania zadań, zobacz Używanie obliczeń usługi Azure Databricks z zadaniami.
widok DAG. Opcja udostępnionego klastra jest udostępniana, jeśli wybrano opcję Obliczenia bezserwerowe lub skonfigurowano nowy klaster zadań dla poprzedniego zadania. Klaster można również skonfigurować dla każdego zadania podczas tworzenia lub edytowania zadania. Aby dowiedzieć się więcej na temat wybierania i konfigurowania klastrów do uruchamiania zadań, zobacz Używanie obliczeń usługi Azure Databricks z zadaniami.
Opcjonalnie można skonfigurować ustawienia na poziomie zadania, takie jak powiadomienia, wyzwalacze zadań i uprawnienia. Zobacz Edytowanie zadania. Można również skonfigurować parametry na poziomie zadania, które są współużytkowane z zadaniami zadania. Zobacz Dodawanie parametrów dla wszystkich zadań podrzędnych zadania.
Opcje typu zadania
Poniżej przedstawiono typy zadań, które można dodać do zadania usługi Azure Databricks i dostępne opcje dla różnych typów zadań:
Notes: w menu rozwijanym Źródło wybierz pozycję Obszar roboczy , aby użyć notesu znajdującego się w folderze obszaru roboczego usługi Azure Databricks lub dostawcy usługi Git dla notesu znajdującego się w zdalnym repozytorium Git.
Obszar roboczy: użyj przeglądarki plików, aby znaleźć notes, kliknij nazwę notesu, a następnie kliknij przycisk Potwierdź.
Dostawca git: kliknij pozycję Edytuj lub Dodaj odwołanie git i wprowadź informacje o repozytorium Git. Zobacz Używanie notesu ze zdalnego repozytorium Git.
Uwaga
Łączne dane wyjściowe komórki notesu (połączone dane wyjściowe wszystkich komórek notesu) podlegają limitowi rozmiaru 20 MB. Ponadto dane wyjściowe poszczególnych komórek podlegają limitowi rozmiaru 8 MB. Jeśli łączne dane wyjściowe komórki przekraczają rozmiar 20 MB lub dane wyjściowe pojedynczej komórki są większe niż 8 MB, przebieg zostanie anulowany i oznaczony jako niepowodzenie.
Jeśli potrzebujesz pomocy w znalezieniu komórek w pobliżu lub poza limitem, uruchom notes dla klastra ogólnego przeznaczenia i użyj tej techniki automatycznego zapisywanie notesu.
JAR: określ klasę Main. Użyj w pełni kwalifikowanej nazwy klasy zawierającej metodę main, na przykład
org.apache.spark.examples.SparkPi. Następnie kliknij przycisk Dodaj w obszarze Biblioteki zależne, aby dodać biblioteki wymagane do uruchomienia zadania. Jedna z tych bibliotek musi zawierać klasę główną.Aby dowiedzieć się więcej na temat zadań JAR, zobacz Use a JAR in an Azure Databricks job (Używanie pliku JAR w zadaniu usługi Azure Databricks).
Przesyłanie platformy Spark: w polu tekstowym Parametry określ klasę główną, ścieżkę do biblioteki JAR i wszystkie argumenty sformatowane jako tablica ciągów JSON. Poniższy przykład umożliwia skonfigurowanie zadania przesyłania platformy Spark w celu uruchomienia
DFSReadWriteTestgo z przykładów platformy Apache Spark:["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]Ważne
Istnieje kilka ograniczeń dotyczących zadań przesyłania platformy Spark:
- Zadania przesyłania platformy Spark można uruchamiać tylko w nowych klastrach.
- Przesyłanie na platformie Spark nie obsługuje skalowania automatycznego klastra. Aby dowiedzieć się więcej na temat skalowania automatycznego, zobacz Skalowanie automatyczne klastra.
- Przesyłanie platformy Spark nie obsługuje dokumentacji narzędzi usługi Databricks (dbutils). Aby użyć narzędzi usługi Databricks, użyj zadań JAR.
- Jeśli używasz klastra z obsługą wykazu aparatu Unity, przesyłanie spark-submit jest obsługiwane tylko wtedy, gdy klaster korzysta z przypisanego trybu dostępu. Tryb dostępu współdzielonego nie jest obsługiwany.
- Zadania przesyłania strumieniowego platformy Spark nigdy nie powinny mieć maksymalnej liczby współbieżnych przebiegów ustawionych na wartość większą niż 1. Zadania przesyłania strumieniowego powinny być uruchamiane przy użyciu wyrażenia
"* * * * * ?"cron (co minutę). Ponieważ zadanie przesyłania strumieniowego jest uruchamiane w sposób ciągły, zawsze powinno być ostatnim zadaniem w zadaniu.
Skrypt języka Python: w menu rozwijanym Źródło wybierz lokalizację skryptu języka Python, obszar roboczy skryptu w lokalnym obszarze roboczym, system DBFS dla skryptu znajdującego się w systemie DBFS lub dostawcę Git dla skryptu znajdującego się w repozytorium Git. W polu tekstowym Ścieżka wprowadź ścieżkę do skryptu języka Python:
Obszar roboczy: w oknie dialogowym Wybieranie pliku języka Python przejdź do skryptu języka Python i kliknij przycisk Potwierdź.
DBFS: wprowadź identyfikator URI skryptu języka Python w systemie dbFS lub magazynie w chmurze,
dbfs:/FileStore/myscript.pyna przykład .Dostawca git: kliknij pozycję Edytuj i wprowadź informacje o repozytorium Git. Zobacz Używanie kodu w języku Python z zdalnego repozytorium Git.
Potok delta Live Tables: w menu rozwijanym Potok wybierz istniejący potok delta live tables .
Ważne
Za pomocą zadania Potok można używać tylko wyzwalanych potoków. Potoki ciągłe nie są obsługiwane jako zadanie zadania podrzędnego. Aby dowiedzieć się więcej na temat wyzwalanych i ciągłych potoków, zobacz Ciągłe i wyzwalane wykonywanie potoku.
Python Wheel: w polu tekstowym Nazwa pakietu wprowadź pakiet do zaimportowania, na przykład
myWheel-1.0-py2.py3-none-any.whl. W polu tekstowym Punkt wejścia wprowadź funkcję do wywołania podczas uruchamiania pliku wheel języka Python. Kliknij przycisk Dodaj w obszarze Biblioteki zależne, aby dodać biblioteki wymagane do uruchomienia zadania.SQL: w menu rozwijanym zadania SQL wybierz pozycję Zapytanie, Starszy pulpit nawigacyjny, Alert lub Plik.
Uwaga
- Zadanie SQL wymaga usługi Databricks SQL i bezserwerowego lub pro SQL Warehouse.
Zapytanie: w menu rozwijanym zapytanie SQL wybierz zapytanie, które ma zostać uruchomione po uruchomieniu zadania.
Starszy pulpit nawigacyjny: w menu rozwijanym pulpitu nawigacyjnego SQL wybierz pulpit nawigacyjny , który ma zostać zaktualizowany po uruchomieniu zadania.
Alert: w menu rozwijanym alertu SQL wybierz alert, który ma być wyzwalany do oceny.
Plik: Aby użyć pliku SQL znajdującego się w folderze obszaru roboczego usługi Azure Databricks, w menu rozwijanym Źródło wybierz pozycję Obszar roboczy, użyj przeglądarki plików, aby znaleźć plik SQL, kliknij nazwę pliku i kliknij przycisk Potwierdź. Aby użyć pliku SQL znajdującego się w zdalnym repozytorium Git, wybierz pozycję Dostawca Git, kliknij pozycję Edytuj lub Dodaj odwołanie git i wprowadź szczegóły repozytorium Git. Zobacz Używanie zapytań SQL z zdalnego repozytorium Git.
W menu rozwijanym usługi SQL Warehouse wybierz usługę bezserwerową lub pro SQL Warehouse, aby uruchomić zadanie.
dbt: zobacz Use dbt transformations in an Azure Databricks job (Używanie przekształceń dbt w zadaniu usługi Azure Databricks), aby zapoznać się ze szczegółowym przykładem konfigurowania zadania dbt.
Uruchom zadanie: w menu rozwijanym Zadanie wybierz zadanie, które ma zostać uruchomione przez zadanie. Aby wyszukać zadanie do uruchomienia, zacznij wpisywać nazwę zadania w menu Zadanie .
Ważne
Nie należy tworzyć zadań z zależnościami cyklicznymi podczas korzystania z
Run Jobzadania lub zadań, które zagnieżdżają więcej niż trzyRun Jobzadania. Zależności cykliczne toRun Jobzadania, które bezpośrednio lub pośrednio wyzwalają siebie nawzajem. Na przykład zadanie A wyzwala zadanie B i zadanie B wyzwala zadanie A. Usługa Databricks nie obsługuje zadań z zależnościami cyklicznymi ani zagnieżdżania więcej niż trzechRun Jobzadań i może nie zezwalać na uruchamianie tych zadań w przyszłych wersjach.Jeśli/else: Aby dowiedzieć się, jak używać
If/else conditionzadania, zobacz Dodawanie logiki rozgałęziania do zadania za pomocą zadania warunku If/else.
Przekazywanie parametrów do zadania zadania usługi Azure Databricks
Parametry można przekazać do wielu typów zadań zadania. Każdy typ zadania ma inne wymagania dotyczące formatowania i przekazywania parametrów.
Aby uzyskać dostęp do informacji o bieżącym zadaniu, takim jak nazwa zadania, lub przekazać kontekst dotyczący bieżącego przebiegu między zadaniami podrzędnymi, takimi jak godzina rozpoczęcia zadania lub identyfikator bieżącego uruchomienia zadania, użyj odwołań do wartości dynamicznych. Aby wyświetlić listę dostępnych odwołań do wartości dynamicznych, kliknij przycisk Przeglądaj wartości dynamiczne.
Jeśli parametry zadania są skonfigurowane w zadaniu, do którego należy zadanie, te parametry są wyświetlane podczas dodawania parametrów zadania. Jeśli parametry zadania i zadania współdzielą klucz, parametr zadania ma pierwszeństwo. Ostrzeżenie jest wyświetlane w interfejsie użytkownika, jeśli próbujesz dodać parametr zadania z tym samym kluczem co parametr zadania. Aby przekazać parametry zadania do zadań, które nie są skonfigurowane z parametrami klucz-wartość, takimi jak JAR lub Spark Submit zadania, sformatuj argumenty jako {{job.parameters.[name]}}, zastępując [name] element parametrem key , który identyfikuje parametr.
Notes: kliknij przycisk Dodaj i określ klucz i wartość każdego parametru, który ma zostać przekazany do zadania. Możesz zastąpić lub dodać dodatkowe parametry podczas ręcznego uruchamiania zadania przy użyciu opcji Uruchom zadanie z różnymi parametrami . Parametry ustawiają wartość widżetu notesu określonego przez klucz parametru.
JAR: użyj tablicy ciągów w formacie JSON, aby określić parametry. Te ciągi są przekazywane jako argumenty do metody main klasy main. Zobacz Konfigurowanie parametrów zadania JAR.
Przesyłanie platformy Spark: parametry są określane jako tablica ciągów w formacie JSON. Zgodnie z konwencją przesyłania platformy Spark platformy Apache Spark parametry po przekazaniu ścieżki JAR do głównej metody klasy głównej.
Python Wheel: w menu rozwijanym Parametry wybierz pozycję Argumenty pozycyjne , aby wprowadzić parametry jako tablicę ciągów w formacie JSON lub wybierz pozycję Argumenty > słów kluczowych Dodaj , aby wprowadzić klucz i wartość każdego parametru. Argumenty pozycyjne i kluczowe są przekazywane do zadania koła języka Python jako argumenty wiersza polecenia. Aby zobaczyć przykład odczytywania argumentów w skrypcie języka Python spakowanym w pliku wheel języka Python, zobacz Use a Python wheel file in an Azure Databricks job (Używanie pliku wheel języka Python w zadaniu usługi Azure Databricks).
Uruchom zadanie: wprowadź klucz i wartość każdego parametru zadania, który ma zostać przekazany do zadania.
Skrypt języka Python: użyj tablicy ciągów w formacie JSON, aby określić parametry. Te ciągi są przekazywane jako argumenty i mogą być odczytywane jako argumenty pozycyjne lub analizowane przy użyciu modułu argparse w języku Python. Aby zapoznać się z przykładem odczytywania argumentów pozycyjnych w skrypcie języka Python, zobacz Krok 2. Tworzenie skryptu w celu pobrania danych usługi GitHub.
SQL: Jeśli zadanie uruchamia sparametryzowane zapytanie lub sparametryzowany pulpit nawigacyjny, wprowadź wartości parametrów w podanych polach tekstowych.
Kopiowanie ścieżki zadania
Niektóre typy zadań, na przykład zadania notesu, umożliwiają skopiowanie ścieżki do kodu źródłowego zadania:
- Kliknij kartę Zadania .
- Wybierz zadanie zawierające ścieżkę do skopiowania.
- Kliknij
 obok ścieżki zadania, aby skopiować ścieżkę do schowka.
obok ścieżki zadania, aby skopiować ścieżkę do schowka.
Tworzenie zadania na podstawie istniejącego zadania
Nowe zadanie można szybko utworzyć, klonując istniejące zadanie. Klonowanie zadania powoduje utworzenie identycznej kopii zadania z wyjątkiem identyfikatora zadania. Na stronie zadania kliknij pozycję Więcej ... obok nazwy zadania i wybierz pozycję Klonuj z menu rozwijanego.
Tworzenie zadania na podstawie istniejącego zadania
Nowe zadanie można szybko utworzyć, klonując istniejące zadanie:
- Na stronie zadania kliknij kartę Zadania .
- Wybierz zadanie do sklonowania.
- Kliknij
 i wybierz pozycję Klonuj zadanie.
i wybierz pozycję Klonuj zadanie.
Usuwanie zadania
Aby usunąć zadanie, na stronie zadania kliknij pozycję Więcej ... obok nazwy zadania i wybierz pozycję Usuń z menu rozwijanego.
Usuwanie zadania
Aby usunąć zadanie:
- Kliknij kartę Zadania .
- Wybierz zadanie do usunięcia.
- Kliknij i wybierz pozycję Usuń zadanie.
Uruchamianie zadania
- Kliknij pozycję Przepływy pracy na pasku bocznym.
- Wybierz zadanie i kliknij kartę Uruchomienia . Zadanie można uruchomić natychmiast lub zaplanować uruchomienie zadania później.
Jeśli co najmniej jedno zadanie w zadaniu z wieloma zadaniami nie powiedzie się, możesz ponownie uruchomić podzbiór nieudanych zadań. Zobacz Ponowne uruchamianie nie powiodło się i pominięto zadania.
Natychmiastowe uruchamianie zadania
Aby natychmiast uruchomić zadanie, kliknij pozycję  .
.
Napiwek
Możesz wykonać testowy przebieg zadania za pomocą zadania notesu, klikając pozycję Uruchom teraz. Jeśli musisz wprowadzić zmiany w notesie, kliknij przycisk Uruchom teraz ponownie po edycji notesu automatycznie uruchomi nową wersję notesu.
Uruchamianie zadania z różnymi parametrami
Możesz użyć polecenia Uruchom teraz z różnymi parametrami , aby ponownie uruchomić zadanie z różnymi parametrami lub różnymi wartościami dla istniejących parametrów.
Uwaga
Nie można zastąpić parametrów zadania, jeśli zadanie, które zostało uruchomione przed wprowadzeniem parametrów zadania, zastąpi parametry zadania tym samym kluczem.
- Kliknij
 obok pozycji Uruchom teraz i wybierz pozycję Uruchom teraz z różnymi parametrami lub w tabeli Aktywne uruchomienia kliknij pozycję Uruchom teraz z różnymi parametrami. Wprowadź nowe parametry w zależności od typu zadania. Zobacz Przekazywanie parametrów do zadania zadania usługi Azure Databricks.
obok pozycji Uruchom teraz i wybierz pozycję Uruchom teraz z różnymi parametrami lub w tabeli Aktywne uruchomienia kliknij pozycję Uruchom teraz z różnymi parametrami. Wprowadź nowe parametry w zależności od typu zadania. Zobacz Przekazywanie parametrów do zadania zadania usługi Azure Databricks. - Kliknij Uruchom.
Uruchamianie zadania jako jednostki usługi
Uwaga
Jeśli zadanie uruchamia zapytania SQL przy użyciu zadania SQL, tożsamość używana do uruchamiania zapytań jest określana przez ustawienia udostępniania każdego zapytania, nawet jeśli zadanie jest uruchamiane jako jednostka usługi. Jeśli zapytanie jest skonfigurowane do Run as owner, zapytanie jest zawsze uruchamiane przy użyciu tożsamości właściciela, a nie tożsamości jednostki usługi. Jeśli zapytanie jest skonfigurowane na Run as viewerwartość , zapytanie jest uruchamiane przy użyciu tożsamości jednostki usługi. Aby dowiedzieć się więcej na temat ustawień udostępniania zapytań, zobacz Konfigurowanie uprawnień zapytania.
Domyślnie zadania są uruchamiane jako tożsamość właściciela zadania. Oznacza to, że zadanie przyjmuje uprawnienia właściciela zadania. Zadanie może uzyskiwać dostęp tylko do danych i obiektów usługi Azure Databricks, do których właściciel zadania ma uprawnienia dostępu. Możesz zmienić tożsamość, którą zadanie jest uruchomione jako na jednostkę usługi. Następnie zadanie przyjmuje uprawnienia tej jednostki usługi zamiast właściciela.
Aby zmienić ustawienie Uruchom jako , musisz mieć uprawnienie CAN MANAGE lub IS OWNER w zadaniu. Możesz ustawić ustawienie Uruchom jako na siebie lub dowolną jednostkę usługi w obszarze roboczym, w którym masz rolę użytkownika jednostki usługi. Aby uzyskać więcej informacji, zobacz Role do zarządzania jednostkami usługi.
Uwaga
RestrictWorkspaceAdmins Gdy ustawienie w obszarze roboczym jest ustawione na ALLOW ALL, administratorzy obszaru roboczego mogą również zmienić ustawienie Uruchom jako na dowolnego użytkownika w swoim obszarze roboczym. Aby ograniczyć administratorom obszaru roboczego tylko zmianę ustawienia Uruchom jako na siebie lub jednostki usługi, w których mają rolę użytkownika jednostki usługi, zobacz Ograniczanie administratorów obszaru roboczego.
Aby zmienić pole Uruchom jako, wykonaj następujące czynności:
- Na pasku bocznym kliknij pozycję Przepływy pracy.
- W kolumnie Nazwa kliknij nazwę zadania.
- W panelu bocznym Szczegóły zadania kliknij ikonę ołówka obok pola Uruchom jako .
- Wyszukaj i wybierz jednostkę usługi.
- Kliknij przycisk Zapisz.
Możesz również wyświetlić listę jednostek usługi, na których znajduje się rola Użytkownik , przy użyciu interfejsu API jednostki usługi obszaru roboczego. Aby uzyskać więcej informacji, zobacz Wyświetlanie listy jednostek usługi, których można użyć.
Uruchamianie zadania zgodnie z harmonogramem
Harmonogram umożliwia automatyczne uruchamianie zadania usługi Azure Databricks w określonych godzinach i okresach. Zobacz Dodawanie harmonogramu zadań.
Uruchamianie zadania ciągłego
Możesz mieć pewność, że zawsze istnieje aktywny przebieg zadania. Zobacz Uruchamianie zadania ciągłego.
Uruchamianie zadania po nadejściu nowych plików
Aby wyzwolić uruchomienie zadania po nadejściu nowych plików w lokalizacji zewnętrznej lub woluminie wykazu aparatu Unity, użyj wyzwalacza nadejścia pliku.
Wyświetlanie i uruchamianie zadania utworzonego za pomocą pakietu zasobów usługi Databricks
Interfejs użytkownika zadań usługi Azure Databricks umożliwia wyświetlanie i uruchamianie zadań wdrożonych przez pakiet zasobów usługi Databricks. Domyślnie te zadania są tylko do odczytu w interfejsie użytkownika zadań. Aby edytować zadanie wdrożone przez pakiet, zmień plik konfiguracji pakietu i ponownie wdróż zadanie. Zastosowanie zmian tylko do konfiguracji pakietu gwarantuje, że pliki źródłowe pakietu zawsze przechwytują bieżącą konfigurację zadania.
Jeśli jednak musisz wprowadzić natychmiastowe zmiany w zadaniu, możesz odłączyć zadanie od konfiguracji pakietu, aby włączyć edytowanie ustawień zadania w interfejsie użytkownika. Aby odłączyć zadanie, kliknij pozycję Odłącz od źródła. W oknie dialogowym Odłącz od źródła kliknij przycisk Rozłącz, aby potwierdzić.
Wszelkie zmiany wprowadzone w zadaniu w interfejsie użytkownika nie są stosowane do konfiguracji pakietu. Aby zastosować zmiany wprowadzone w interfejsie użytkownika do pakietu, należy ręcznie zaktualizować konfigurację pakietu. Aby ponownie połączyć zadanie z konfiguracją pakietu, ponownie wdróż zadanie przy użyciu pakietu.
Co zrobić, jeśli nie można uruchomić zadania z powodu limitów współbieżności?
Uwaga
Kolejkowanie jest domyślnie włączone, gdy zadania są tworzone w interfejsie użytkownika.
Aby zapobiec pomijaniu przebiegów zadania z powodu limitów współbieżności, możesz włączyć kolejkowanie zadania. Jeśli kolejkowanie jest włączone, jeśli zasoby są niedostępne dla uruchomienia zadania, przebieg jest kolejkowany przez maksymalnie 48 godzin. Gdy pojemność jest dostępna, uruchomienie zadania jest odsyłane i uruchamiane. Uruchomienia w kolejce są wyświetlane na liście przebiegów dla zadania i listy ostatnich uruchomień zadania.
Przebieg jest kolejkowany po osiągnięciu jednego z następujących limitów:
- Maksymalna liczba współbieżnych aktywnych przebiegów w obszarze roboczym.
- Maksymalne współbieżne zadania są uruchamiane
Run Jobw obszarze roboczym. - Maksymalna liczba współbieżnych uruchomień zadania.
Kolejkowanie to właściwość na poziomie zadania, która kolejki są uruchamiane tylko dla tego zadania.
Aby włączyć lub wyłączyć kolejkowanie, kliknij pozycję Ustawienia zaawansowane i kliknij przycisk przełączania kolejki w panelu bocznym Szczegóły zadania.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla