Debugowanie skryptu oceniania za pomocą usługi Azure Machine Edukacja wnioskowania serwera HTTP
Serwer HTTP wnioskowania usługi Azure Machine Edukacja to pakiet języka Python, który uwidacznia funkcję oceniania jako punkt końcowy HTTP i opakowuje kod serwera Flask i zależności w pojedynczy pakiet. Jest on uwzględniony we wstępnie utworzonych obrazach platformy Docker na potrzeby wnioskowania, które są używane podczas wdrażania modelu za pomocą usługi Azure Machine Edukacja. Korzystając z samego pakietu, możesz wdrożyć model lokalnie na potrzeby środowiska produkcyjnego, a także łatwo zweryfikować skrypt oceniania (wpisu) w lokalnym środowisku deweloperskim. Jeśli wystąpi problem ze skryptem oceniania, serwer zwróci błąd i lokalizację, w której wystąpił błąd.
Serwer może również służyć do tworzenia bram weryfikacji w potoku ciągłej integracji i wdrażania. Na przykład można uruchomić serwer za pomocą skryptu kandydata i uruchomić zestaw testów względem lokalnego punktu końcowego.
Ten artykuł dotyczy głównie użytkowników, którzy chcą używać serwera wnioskowania do debugowania lokalnego, ale pomoże również zrozumieć, jak używać serwera wnioskowania z punktami końcowymi online.
Lokalne debugowanie punktu końcowego w trybie online
Lokalne debugowanie punktów końcowych przed ich wdrożeniem w chmurze może pomóc w przechwyceniu błędów w kodzie i konfiguracji wcześniej. Aby debugować punkty końcowe lokalnie, możesz użyć:
- serwer HTTP wnioskowania usługi Azure Machine Edukacja
- lokalny punkt końcowy
Ten artykuł koncentruje się na serwerze HTTP wnioskowania usługi Azure Machine Edukacja.
Poniższa tabela zawiera omówienie scenariuszy, które pomogą Ci wybrać najlepsze rozwiązania.
| Scenariusz | Wnioskowanie serwera HTTP | Lokalny punkt końcowy |
|---|---|---|
| Aktualizowanie lokalnego środowiska języka Python bez ponownego kompilowanie obrazu platformy Docker | Tak | Nie. |
| Aktualizowanie skryptu oceniania | Tak | Tak |
| Aktualizowanie konfiguracji wdrożenia (wdrożenie, środowisko, kod, model) | Nie. | Tak |
| Integrowanie debugera programu VS Code | Tak | Tak |
Uruchamiając lokalnie serwer HTTP wnioskowania, możesz skoncentrować się na debugowaniu skryptu oceniania bez wpływu na konfiguracje kontenera wdrożenia.
Wymagania wstępne
- Wymaga: Python >=3.8
- Anaconda
Napiwek
Serwer HTTP wnioskowania usługi Azure Machine Edukacja działa w systemach operacyjnych z systemem Windows i Linux.
Instalacja
Uwaga
Aby uniknąć konfliktów pakietów, zainstaluj serwer w środowisku wirtualnym.
Aby zainstalować program , uruchom następujące polecenie w narzędziu azureml-inference-server-http packagecmd/terminalu:
python -m pip install azureml-inference-server-http
Lokalne debugowanie skryptu oceniania
Aby debugować skrypt oceniania lokalnie, możesz przetestować, jak działa serwer za pomocą fikcyjnego skryptu oceniania, użyj programu VS Code do debugowania za pomocą pakietu azureml-inference-server-http lub przetestować serwer za pomocą rzeczywistego skryptu oceniania, pliku modelu i pliku środowiska z naszego repozytorium przykładów.
Testowanie zachowania serwera za pomocą fikcyjnego skryptu oceniania
Utwórz katalog do przechowywania plików:
mkdir server_quickstart cd server_quickstartAby uniknąć konfliktów pakietów, utwórz środowisko wirtualne i aktywuj je:
python -m venv myenv source myenv/bin/activateNapiwek
Po przetestowaniu uruchom polecenie
deactivate, aby dezaktywować środowisko wirtualne języka Python.azureml-inference-server-httpZainstaluj pakiet ze źródła danych pypi:python -m pip install azureml-inference-server-httpUtwórz skrypt wejścia (
score.py). Poniższy przykład tworzy podstawowy skrypt wpisu:echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.pyUruchom serwer (azmlinfsrv) i ustaw
score.pygo jako skrypt wpisu:azmlinfsrv --entry_script score.pyUwaga
Serwer jest hostowany w wersji 0.0.0.0, co oznacza, że będzie nasłuchiwać wszystkich adresów IP maszyny hostingu.
Wyślij żądanie oceniania do serwera przy użyciu polecenia
curl:curl -p 127.0.0.1:5001/scoreSerwer powinien odpowiedzieć w ten sposób.
{"message": "Hello, World!"}
Po przetestowaniu możesz nacisnąć klawisz Ctrl + C , aby zakończyć działanie serwera.
Teraz możesz zmodyfikować skrypt oceniania (score.py) i przetestować zmiany, uruchamiając ponownie serwer (azmlinfsrv --entry_script score.py).
Jak zintegrować z programem Visual Studio Code
Istnieją dwa sposoby używania programu Visual Studio Code (VS Code) i rozszerzenia języka Python do debugowania za pomocą pakietu azureml-inference-server-http (tryby uruchamiania i dołączania).
Tryb uruchamiania: skonfiguruj
launch.jsonprogram VS Code i uruchom usługę Azure Machine Edukacja wnioskowanie serwera HTTP w programie VS Code.Uruchom program VS Code i otwórz folder zawierający skrypt (
score.py).Dodaj następującą konfigurację dla
launch.jsontego obszaru roboczego w programie VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }Rozpocznij sesję debugowania w programie VS Code. Wybierz pozycję "Uruchom" —> "Rozpocznij debugowanie" (lub
F5).
Tryb dołączania: uruchom usługę Azure Machine Edukacja wnioskowanie serwera HTTP w wierszu polecenia i użyj programu VS Code + rozszerzenia języka Python, aby dołączyć do procesu.
Uwaga
Jeśli używasz środowiska systemu Linux, najpierw zainstaluj
gdbpakiet, uruchamiając poleceniesudo apt-get install -y gdb.Dodaj następującą konfigurację dla
launch.jsontego obszaru roboczego w programie VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }Uruchom serwer wnioskowania przy użyciu interfejsu wiersza polecenia (
azmlinfsrv --entry_script score.py).Rozpocznij sesję debugowania w programie VS Code.
- W programie VS Code wybierz pozycję "Uruchom" —> "Rozpocznij debugowanie" (lub
F5). - Wprowadź identyfikator
azmlinfsrvprocesu (a niegunicorn) przy użyciu dzienników (z serwera wnioskowania) wyświetlanego w interfejsie wiersza polecenia.
Uwaga
Jeśli selektor procesu nie jest wyświetlany, ręcznie wprowadź identyfikator procesu w
processIdpolulaunch.json.- W programie VS Code wybierz pozycję "Uruchom" —> "Rozpocznij debugowanie" (lub
W obu przypadkach można ustawić punkt przerwania i debugować krok po kroku.
Przykład kompleksowego
W tej sekcji uruchomimy serwer lokalnie z przykładowymi plikami (skrypt oceniania, plik modelu i środowisko) w naszym przykładowym repozytorium. Przykładowe pliki są również używane w naszym artykule dotyczącym wdrażania i oceniania modelu uczenia maszynowego przy użyciu punktu końcowego online
Sklonuj przykładowe repozytorium.
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/Tworzenie i aktywowanie środowiska wirtualnego za pomocą środowiska conda. W tym przykładzie
azureml-inference-server-httppakiet jest instalowany automatycznie, ponieważ jest dołączony jako zależna bibliotekaazureml-defaultspakietu w następującyconda.ymlsposób.# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-envPrzejrzyj skrypt oceniania.
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()Uruchom serwer wnioskowania z określeniem skryptu oceniania i pliku modelu. Określony katalog modelu (
model_dirparametr) zostanie zdefiniowany jakoAZUREML_MODEL_DIRzmienna i pobrany w skryfcie oceniania. W tym przypadku określamy bieżący katalog (./), ponieważ podkatalog jest określony w skryfcie oceniania jakomodel/sklearn_regression_model.pkl.azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./Przykładowy dziennik uruchamiania zostanie wyświetlony, jeśli serwer został uruchomiony i skrypt oceniania został pomyślnie wywołany. W przeciwnym razie w dzienniku będą wyświetlane komunikaty o błędach.
Przetestuj skrypt oceniania przy użyciu przykładowych danych. Otwórz inny terminal i przejdź do tego samego katalogu roboczego, aby uruchomić polecenie . Użyj polecenia ,
curlaby wysłać przykładowe żądanie do serwera i otrzymać wynik oceniania.curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.jsonWynik oceniania zostanie zwrócony, jeśli nie ma problemu ze skryptem oceniania. Jeśli znajdziesz coś nie tak, możesz spróbować zaktualizować skrypt oceniania i ponownie uruchomić serwer, aby przetestować zaktualizowany skrypt.
Trasy serwera
Serwer nasłuchuje na porcie 5001 (domyślnie) na tych trasach.
| Nazwisko | Marszruta |
|---|---|
| Sonda liveness | 127.0.0.1:5001/ |
| Wynik | 127.0.0.1:5001/wynik |
| OpenAPI (swagger) | 127.0.0.1:5001/swagger.json |
Parametry serwera
Poniższa tabela zawiera parametry akceptowane przez serwer:
| Parametr | Wymagania | Wartość domyślna | opis |
|---|---|---|---|
| entry_script | Prawda | Nie dotyczy | Względna lub bezwzględna ścieżka do skryptu oceniania. |
| model_dir | Fałsz | Nie dotyczy | Względna lub bezwzględna ścieżka do katalogu zawierającego model używany do wnioskowania. |
| port | Fałsz | 5001 | Port obsługujący serwer. |
| worker_count | Fałsz | 1 | Liczba wątków procesu roboczego, które będą przetwarzać żądania współbieżne. |
| appinsights_instrumentation_key | Fałsz | Nie dotyczy | Klucz instrumentacji do usługi Application Insights, w którym zostaną opublikowane dzienniki. |
| access_control_allow_origins | Fałsz | Nie dotyczy | Włącz mechanizm CORS dla określonych źródeł. Oddzielaj wiele źródeł od ",". Przykład: "microsoft.com, bing.com" |
Przepływ żądania
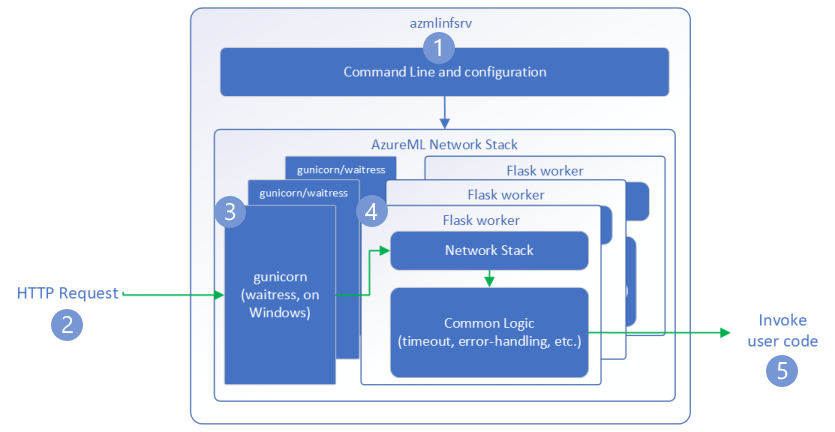
W poniższych krokach wyjaśniono, jak usługa Azure Machine Edukacja wnioskowania serwera HTTP (azmlinfsrv) obsługuje żądania przychodzące:
- Otoka interfejsu wiersza polecenia języka Python znajduje się wokół stosu sieciowego serwera i służy do uruchamiania serwera.
- Klient wysyła żądanie do serwera.
- Po odebraniu żądania przechodzi przez serwer WSGI , a następnie jest wysyłany do jednego z procesów roboczych.
- Żądania są następnie obsługiwane przez aplikację platformy Flask , która ładuje skrypt wejścia i wszelkie zależności.
- Na koniec żądanie jest wysyłane do skryptu wpisu. Następnie skrypt wejścia wykonuje wywołanie wnioskowania do załadowanego modelu i zwraca odpowiedź.
Informacje o dziennikach
W tym miejscu opisano dzienniki serwera HTTP wnioskowania usługi Azure Machine Edukacja. Dziennik można uzyskać po uruchomieniu azureml-inference-server-http lokalnie lub pobrać dzienniki kontenera, jeśli używasz punktów końcowych online.
Uwaga
Format rejestrowania zmienił się od wersji 0.8.0. Jeśli znajdziesz dziennik w innym stylu, zaktualizuj azureml-inference-server-http pakiet do najnowszej wersji.
Napiwek
Jeśli używasz punktów końcowych online, dziennik z serwera wnioskowania rozpoczyna się od Azure Machine Learning Inferencing HTTP server <version>.
Dzienniki uruchamiania
Po uruchomieniu serwera ustawienia serwera są najpierw wyświetlane przez dzienniki w następujący sposób:
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
Na przykład po uruchomieniu serwera następuje pełny przykład:
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
Format dziennika
Dzienniki z serwera wnioskowania są generowane w następującym formacie, z wyjątkiem skryptów uruchamiania, ponieważ nie są częścią pakietu python:
<UTC Time> | <level> [<pid>] <logger name> - <message>
Oto <pid> identyfikator procesu i <level> jest pierwszym znakiem poziomu rejestrowania — E dla BŁĘDU, I dla INFORMACJI itp.
W języku Python istnieje sześć poziomów rejestrowania z liczbami skojarzonymi z ważnością:
| Poziom rejestrowania | Wartość liczbowa |
|---|---|
| KRYTYCZNY | 50 |
| BŁĄD | 40 |
| OSTRZEŻENIE | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
Przewodnik po rozwiązywaniu problemów
W tej sekcji udostępnimy podstawowe porady dotyczące rozwiązywania problemów z serwerem HTTP wnioskowania usługi Azure Machine Edukacja. Jeśli chcesz rozwiązać problemy z punktami końcowymi online, zobacz również Rozwiązywanie problemów z wdrażaniem punktów końcowych online
Podstawowe kroki
Podstawowe kroki rozwiązywania problemów to:
- Zbierz informacje o wersji dla środowiska języka Python.
- Upewnij się, że wersja pakietu azureml-inference-server-http języka Python określona w pliku środowiska jest zgodna z wersją serwera HTTP wnioskowania usługi AzureML wyświetlaną w dzienniku uruchamiania. Czasami narzędzie do rozpoznawania zależności pip prowadzi do nieoczekiwanych wersji zainstalowanych pakietów.
- Jeśli określisz platformę Flask (i jej zależności) w środowisku, usuń je. Zależności obejmują
Flask, ,Jinja2,itsdangerous,Werkzeug,MarkupSafe, iclick. Platforma Flask jest wymieniona jako zależność w pakiecie serwera i najlepiej pozwolić serwerowi go zainstalować. Dzięki temu, gdy serwer obsługuje nowe wersje platformy Flask, otrzymasz je automatycznie.
Wersja serwera
Pakiet azureml-inference-server-http serwera jest publikowany w interfejsie PyPI. Nasz dziennik zmian i wszystkie poprzednie wersje można znaleźć na naszej stronie PyPI. Zaktualizuj do najnowszej wersji, jeśli używasz starszej wersji.
- 0.4.x: wersja dołączona do obrazów szkoleniowych ≤
20220601i w programieazureml-defaults>=1.34,<=1.43.0.4.13jest ostatnią stabilną wersją. Jeśli używasz serwera przed wersją0.4.11, mogą wystąpić problemy z zależnościami platformy Flask, takie jak nie można zaimportować nazwyMarkupz programujinja2. Zalecamy uaktualnienie do0.4.13lub0.8.x(najnowszą wersję), jeśli jest to możliwe. - 0.6.x: wersja wstępnie zainstalowana w wnioskowaniu obrazów ≤ 20220516. Najnowsza stabilna wersja to
0.6.1. - 0.7.x: pierwsza wersja, która obsługuje platformę Flask 2. Najnowsza stabilna wersja to
0.7.7. - 0.8.x: Format dziennika uległ zmianie, a obsługa języka Python 3.6 spadła.
Zależności pakietów
Najbardziej odpowiednie pakiety dla serwera azureml-inference-server-http to następujące pakiety:
- Kolby
- opencensus-ext-azure
- schemat wnioskowania
W przypadku określenia azureml-defaults w środowisku azureml-inference-server-http języka Python pakiet jest zależny i zostanie zainstalowany automatycznie.
Napiwek
Jeśli używasz zestawu Python SDK w wersji 1 i nie określasz azureml-defaults jawnie go w środowisku języka Python, zestaw SDK może dodać pakiet. Jednak zablokuje go do wersji, w ramach których jest włączony zestaw SDK. Jeśli na przykład wersja zestawu SDK to 1.38.0, zostanie dodana azureml-defaults==1.38.0 do wymagań pip środowiska.
Często zadawane pytania
1. Wystąpił następujący błąd podczas uruchamiania serwera:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
Platforma Flask 2 jest zainstalowana w środowisku języka Python, ale jest uruchomiona wersjaazureml-inference-server-http, która nie obsługuje platformy Flask 2. Obsługa platformy Flask 2 jest dodawana w systemie azureml-inference-server-http>=0.7.0, który jest również w systemie azureml-defaults>=1.44.
Jeśli nie używasz tego pakietu w obrazie platformy Docker usługi AzureML, użyj najnowszej
azureml-inference-server-httpwersji programu lubazureml-defaults.Jeśli używasz tego pakietu z obrazem platformy Docker usługi AzureML, upewnij się, że używasz obrazu wbudowanego lub po lipcu 2022 r. Wersja obrazu jest dostępna w dziennikach kontenera. Powinno być możliwe znalezienie dziennika podobnego do następującego:
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |Data kompilacji obrazu jest wyświetlana po "Materialization Build", który w powyższym przykładzie to
20220708, czyli 8 lipca 2022 r. Ten obraz jest zgodny z platformą Flask 2. Jeśli w dzienniku kontenera nie widzisz baneru takiego jak ten, obraz jest nieaktualny i powinien zostać zaktualizowany. Jeśli używasz obrazu CUDA i nie możesz znaleźć nowszego obrazu, sprawdź, czy obraz jest przestarzały w usłudze AzureML-Containers. Jeśli tak jest, powinno być możliwe znalezienie zamienników.Jeśli używasz serwera z punktem końcowym online, możesz również znaleźć dzienniki w obszarze "Dzienniki wdrażania" na stronie punktu końcowego online w usłudze Azure Machine Edukacja Studio. Jeśli wdrożysz za pomocą zestawu SDK w wersji 1 i nie określisz jawnie obrazu w konfiguracji wdrożenia, domyślnie będzie używana wersja
openmpi4.1.0-ubuntu20.04zgodna z lokalnym zestawem narzędzi zestawu SDK, który może nie być najnowszą wersją obrazu. Na przykład zestaw SDK 1.43 będzie domyślnie używaćopenmpi4.1.0-ubuntu20.04:20220616elementu , który jest niezgodny. Upewnij się, że używasz najnowszego zestawu SDK do wdrożenia.Jeśli z jakiegoś powodu nie możesz zaktualizować obrazu, możesz tymczasowo uniknąć problemu przez przypięcie
azureml-defaults==1.43lubazureml-inference-server-http~=0.4.13, co spowoduje zainstalowanie starszego serwera wersji za pomocąFlask 1.0.xpolecenia .
2. Napotkałem moduły ImportError lub ModuleNotFoundError w modułach opencensus, jinja2, MarkupSafelub click podczas uruchamiania, podobnie jak w przypadku następującego komunikatu:
ImportError: cannot import name 'Markup' from 'jinja2'
Starsze wersje (<= 0.4.10) serwera nie przypiąły zależności platformy Flask do zgodnych wersji. Ten problem został rozwiązany w najnowszej wersji serwera.
Następne kroki
- Aby uzyskać więcej informacji na temat tworzenia skryptu wejścia i wdrażania modeli, zobacz How to deploy a model using Azure Machine Edukacja (Jak wdrożyć model przy użyciu usługi Azure Machine Edukacja).
- Dowiedz się więcej o wstępnie utworzonych obrazach platformy Docker na potrzeby wnioskowania