Użyj pakietu do interpretowania języka Python, aby wyjaśnić modele i przewidywania uczenia maszynowego (wersja zapoznawcza)
DOTYCZY: Zestaw SDK języka Python azureml w wersji 1
Zestaw SDK języka Python azureml w wersji 1
W tym przewodniku z instrukcjami dowiesz się, jak używać pakietu możliwości interpretacji zestawu SDK języka Python Edukacja azure Machine do wykonywania następujących zadań:
Wyjaśnij całe zachowanie modelu lub poszczególne przewidywania na komputerze osobistym lokalnie.
Włącz techniki interpretowania dla funkcji zaprojektowanych.
Wyjaśnij zachowanie całego modelu i poszczególnych przewidywań na platformie Azure.
Przekaż wyjaśnienia do usługi Azure Machine Edukacja Historii uruchamiania.
Użyj pulpitu nawigacyjnego wizualizacji, aby wchodzić w interakcje z wyjaśnieniami modelu, zarówno w notesie Jupyter Notebook, jak i w usłudze Azure Machine Edukacja Studio.
Wdróż objaśnienie oceniania obok modelu, aby obserwować wyjaśnienia podczas wnioskowania.
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Aby uzyskać więcej informacji na temat obsługiwanych technik interpretacji i modeli uczenia maszynowego, zobacz Możliwości interpretowania modelu w usłudze Azure Machine Edukacja i przykładowe notesy.
Aby uzyskać wskazówki dotyczące włączania interpretacji modeli wytrenowanych za pomocą zautomatyzowanego uczenia maszynowego, zobacz Interpretowanie: wyjaśnienia modelu dla modeli zautomatyzowanego uczenia maszynowego (wersja zapoznawcza).
Generowanie wartości ważności funkcji na komputerze osobistym
W poniższym przykładzie pokazano, jak używać pakietu do interpretowania na komputerze osobistym bez kontaktowania się z usługami platformy Azure.
Zainstaluj pakiet
azureml-interpret.pip install azureml-interpretTrenowanie przykładowego modelu w lokalnym notesie Jupyter Notebook.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Wywołaj element wyjaśniający lokalnie.
- Aby zainicjować obiekt objaśnienia, przekaż model i niektóre dane szkoleniowe do konstruktora objaśnienia.
- Aby wyjaśnić i wizualizacje bardziej informacyjne, możesz przekazać nazwy funkcji i nazwy klas wyjściowych w przypadku klasyfikacji.
W poniższych blokach kodu pokazano, jak utworzyć wystąpienie obiektu objaśnienia za pomocą
TabularExplainerelementów ,MimicExplaineriPFIExplainerlokalnie.TabularExplainerwywołuje jedną z trzech wyjaśnień SHAP poniżej (TreeExplainer,DeepExplainer, lubKernelExplainer).TabularExplainerAutomatycznie wybiera najbardziej odpowiedni dla twojego przypadku użycia, ale można bezpośrednio wywołać każdy z trzech podstawowych wyjaśnień.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)lub
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)lub
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Wyjaśnienie całego zachowania modelu (wyjaśnienie globalne)
Zapoznaj się z poniższym przykładem, aby uzyskać wartości ważności funkcji agregacji (globalnej).
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Wyjaśnienie indywidualnego przewidywania (wyjaśnienie lokalne)
Pobierz poszczególne wartości ważności funkcji różnych punktów danych, wywołując wyjaśnienia dla pojedynczego wystąpienia lub grupy wystąpień.
Uwaga
PFIExplainer nie obsługuje lokalnych wyjaśnień.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Nieprzetworzone przekształcenia funkcji
Możesz zdecydować się na uzyskanie wyjaśnień dotyczących nieprzetworzonych, nieprzetworzonych funkcji, a nie funkcji zaprojektowanych. W przypadku tej opcji przekażesz potok przekształcania funkcji do objaśnienia w pliku train_explain.py. W przeciwnym razie objaśnienie zawiera wyjaśnienia dotyczące cech inżynierów.
Format obsługiwanych przekształceń jest taki sam, jak opisano w pliku sklearn-pandas. Ogólnie rzecz biorąc, wszystkie przekształcenia są obsługiwane tak długo, jak działają w jednej kolumnie, aby było jasne, że są one jeden do wielu.
Zapoznaj się z wyjaśnieniem pierwotnych cech przy użyciu sklearn.compose.ColumnTransformer elementu lub z listą dopasowanych krotki transformatora. W poniższym przykładzie użyto metody sklearn.compose.ColumnTransformer.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Jeśli chcesz uruchomić przykład z listą dopasowanych krotki transformatora, użyj następującego kodu:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Generowanie wartości ważności funkcji za pośrednictwem przebiegów zdalnych
W poniższym przykładzie pokazano, jak można użyć ExplanationClient klasy , aby umożliwić interpretowanie modelu dla przebiegów zdalnych. Jest ona koncepcyjnie podobna do procesu lokalnego, z wyjątkiem następujących sytuacji:
- Użyj polecenia
ExplanationClientw zdalnym uruchomieniu, aby przekazać kontekst możliwości interpretacji. - Pobierz kontekst później w środowisku lokalnym.
Zainstaluj pakiet
azureml-interpret.pip install azureml-interpretUtwórz skrypt szkoleniowy w lokalnym notesie Jupyter Notebook. Na przykład
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Skonfiguruj usługę Azure Machine Edukacja Compute jako docelowy obiekt obliczeniowy i prześlij przebieg trenowania. Aby uzyskać instrukcje, zobacz Tworzenie klastrów obliczeniowych usługi Azure Machine Edukacja i zarządzanie nimi. Przydatne mogą być również przykładowe notesy .
Pobierz wyjaśnienie w lokalnym notesie Jupyter Notebook.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Wizualizacje
Po pobraniu wyjaśnień w lokalnym notesie Jupyter Notebook możesz użyć wizualizacji na pulpicie nawigacyjnym wyjaśnień, aby zrozumieć i interpretować model. Aby załadować widżet pulpitu nawigacyjnego wyjaśnień w notesie Jupyter Notebook, użyj następującego kodu:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
Wizualizacje obsługują wyjaśnienia dotyczące funkcji zaprojektowanych i nieprzetworzonych. Nieprzetworzone wyjaśnienia są oparte na funkcjach z oryginalnego zestawu danych, a objaśnienia inżynieryjne są oparte na funkcjach z zestawu danych z zastosowaniem inżynierii cech.
Podczas próby zinterpretowania modelu w odniesieniu do oryginalnego zestawu danych zaleca się użycie nieprzetworzonych wyjaśnień, ponieważ każde znaczenie funkcji będzie odpowiadać kolumnie z oryginalnego zestawu danych. Jednym ze scenariuszy, w którym objaśnienia inżynierów mogą być przydatne podczas badania wpływu poszczególnych kategorii z funkcji kategorii. Jeśli kodowanie jednokrotne jest stosowane do funkcji podzielonej na kategorie, wynikowe wyjaśnienia będą zawierać inną wartość ważności na kategorię, jedną na funkcję zaprojektowaną na gorąco. To kodowanie może być przydatne podczas zawężania, która część zestawu danych jest najbardziej informacyjna dla modelu.
Uwaga
Objaśnienia inżynierów i nieprzetworzonych są obliczane sekwencyjnie. Najpierw tworzone jest objaśnienie zaprojektowane na podstawie modelu i potoku cechowania. Następnie pierwotne wyjaśnienie jest tworzone na podstawie tego zaprojektowanego wyjaśnienia przez agregowanie znaczenia cech zaprojektowanych, które pochodzą z tej samej pierwotnej funkcji.
Tworzenie, edytowanie i wyświetlanie kohort zestawów danych
Górna wstążka przedstawia ogólne statystyki dotyczące modelu i danych. Dane można podzielić na kohorty zestawów danych lub podgrupy, aby zbadać lub porównać wydajność i wyjaśnienia modelu w tych zdefiniowanych podgrupach. Porównując statystyki zestawu danych i wyjaśnienia w tych podgrupach, możesz zrozumieć, dlaczego możliwe błędy występują w jednej grupie w porównaniu z drugą.

Omówienie całego zachowania modelu (wyjaśnienie globalne)
Pierwsze trzy karty pulpitu nawigacyjnego wyjaśnienia zawierają ogólną analizę wytrenowanego modelu wraz z jego przewidywaniami i wyjaśnieniami.
Wydajność modelu
Oceń wydajność modelu, eksplorując rozkład wartości przewidywania i wartości metryk wydajności modelu. Możesz dokładniej zbadać model, przeglądając analizę porównawczą jego wydajności w różnych kohortach lub podgrupach zestawu danych. Wybierz filtry wzdłuż wartości y i x-value, aby wyciąć różne wymiary. Wyświetl metryki, takie jak dokładność, precyzja, kompletność, współczynnik fałszywie dodatni (FPR) i fałszywie ujemny współczynnik (FNR).

Eksplorator zestawów danych
Eksploruj statystyki zestawu danych, wybierając różne filtry wzdłuż osi X, Y i kolorów, aby podzielić dane na różne wymiary. Utwórz kohorty zestawów danych powyżej, aby analizować statystyki zestawów danych za pomocą filtrów, takich jak przewidywany wynik, funkcje zestawu danych i grupy błędów. Użyj ikony koła zębatego w prawym górnym rogu grafu, aby zmienić typy wykresów.

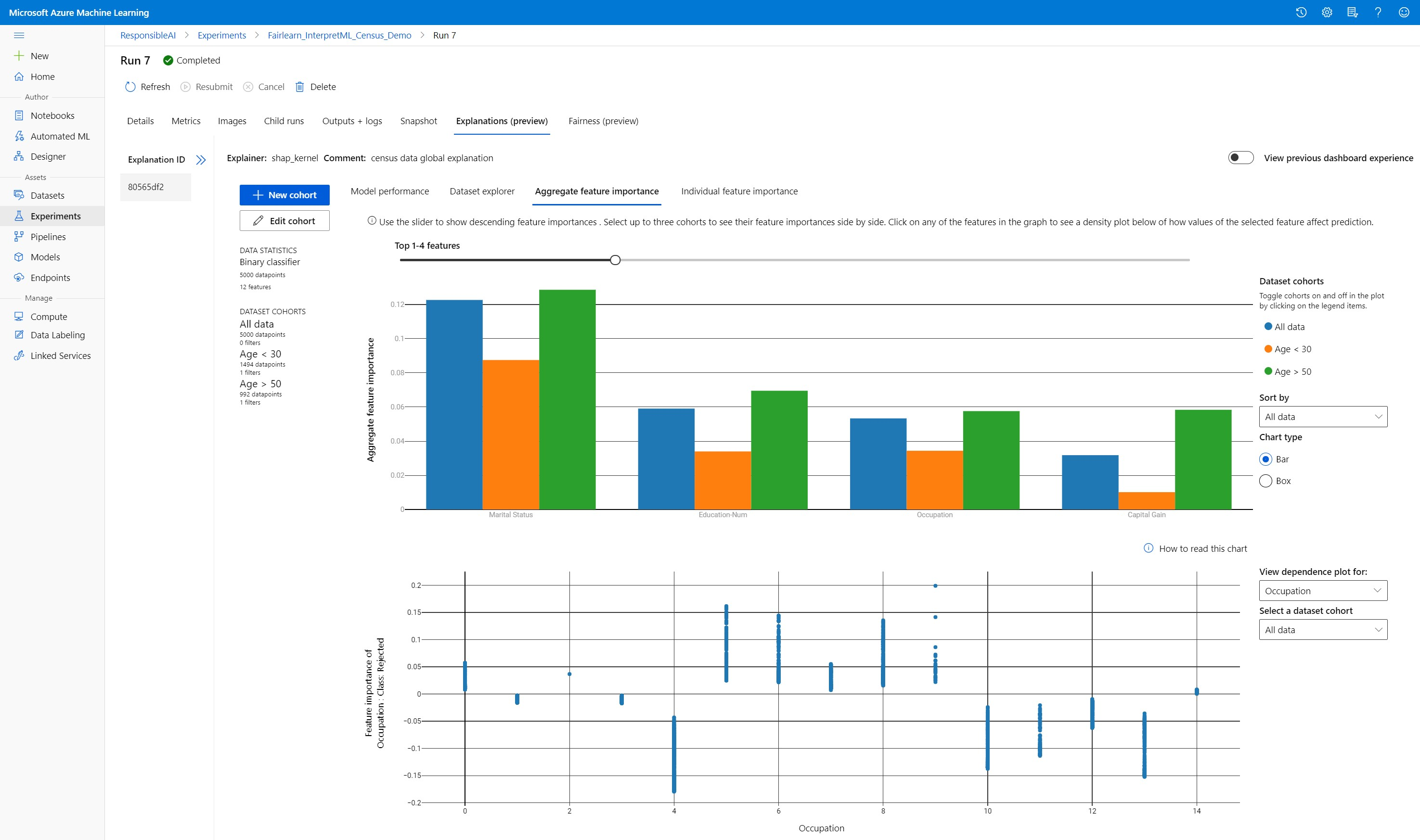
Zagregowane znaczenie funkcji
Zapoznaj się z najważniejszymi funkcjami, które mają wpływ na ogólne przewidywania modelu (nazywane również globalnymi wyjaśnieniami). Użyj suwaka, aby wyświetlić malejące wartości ważności funkcji. Wybierz maksymalnie trzy kohorty, aby zobaczyć obok siebie wartości ważności funkcji. Wybierz dowolny z pasków funkcji na wykresie, aby zobaczyć, jak wartości wybranego modelu wpływu funkcji mają wpływ na model w poniższym wykresie zależności.

Omówienie poszczególnych przewidywań (wyjaśnienie lokalne)
Czwarta karta wyjaśnienia umożliwia przechodzenie do szczegółów poszczególnych punktów danych i ich poszczególnych istotności funkcji. Pojedynczy wykres ważności funkcji można załadować dla dowolnego punktu danych, klikając dowolny z poszczególnych punktów danych na głównym wykresie punktowym lub wybierając konkretny punkt danych w kreatorze panelu po prawej stronie.
| Wykreślić | opis |
|---|---|
| Ważność poszczególnych cech | Przedstawia najważniejsze funkcje dla poszczególnych przewidywań. Pomaga zilustrować lokalne zachowanie bazowego modelu w określonym punkcie danych. |
| Analiza analizy warunkowej | Umożliwia zmianę wartości funkcji wybranego rzeczywistego punktu danych i obserwowanie wynikowych zmian wartości przewidywania przez wygenerowanie hipotetycznego punktu danych przy użyciu nowych wartości funkcji. |
| Indywidualne oczekiwania warunkowe (ICE) | Umożliwia zmianę wartości funkcji z wartości minimalnej na wartość maksymalną. Pomaga zilustrować, w jaki sposób przewidywanie punktu danych zmienia się po zmianie funkcji. |

Uwaga
Są to wyjaśnienia oparte na wielu przybliżeniach i nie są "przyczyną" przewidywań. Bez ścisłej niezawodności matematycznej wnioskowania przyczynowego, nie zalecamy użytkownikom podejmowania rzeczywistych decyzji na podstawie perturbacji funkcji narzędzia Analizy co-jeżeli. To narzędzie służy przede wszystkim do zrozumienia modelu i debugowania.
Wizualizacja w usłudze Azure Machine Edukacja Studio
Jeśli wykonasz kroki zdalnego interpretowania (przekazywanie wygenerowanych wyjaśnień do historii uruchamiania usługi Azure Machine Edukacja), możesz wyświetlić wizualizacje na pulpicie nawigacyjnym objaśnień w usłudze Azure Machine Edukacja Studio. Ten pulpit nawigacyjny jest prostszą wersją widżetu pulpitu nawigacyjnego wygenerowanego w notesie Jupyter Notebook. Generowanie punktów danych what-If i wykresy ICE są wyłączone, ponieważ w usłudze Azure Machine Edukacja studio nie ma aktywnych obliczeń, które mogą wykonywać obliczenia w czasie rzeczywistym.
Jeśli zestaw danych, globalne i lokalne wyjaśnienia są dostępne, dane wypełniają wszystkie karty. Jeśli jednak dostępne jest tylko globalne wyjaśnienie, karta Ważność poszczególnych funkcji zostanie wyłączona.
Wykonaj jedną z tych ścieżek, aby uzyskać dostęp do pulpitu nawigacyjnego wyjaśnień w usłudze Azure Machine Edukacja Studio:
Okienko Eksperymenty (wersja zapoznawcza)
- Wybierz pozycję Eksperymenty w okienku po lewej stronie, aby wyświetlić listę eksperymentów, które zostały uruchomione na maszynie azure Edukacja.
- Wybierz konkretny eksperyment, aby wyświetlić wszystkie przebiegi w tym eksperymencie.
- Wybierz przebieg, a następnie kartę Wyjaśnienia na pulpicie nawigacyjnym wizualizacji wyjaśnienia.
Okienko Modele
- Jeśli zarejestrowano oryginalny model, wykonując kroki opisane w artykule Wdrażanie modeli przy użyciu usługi Azure Machine Edukacja, możesz wybrać pozycję Modele w okienku po lewej stronie, aby go wyświetlić.
- Wybierz model, a następnie kartę Wyjaśnienia , aby wyświetlić pulpit nawigacyjny wyjaśnień.

Możliwość interpretacji w czasie wnioskowania
Możesz wdrożyć objaśnienie wraz z oryginalnym modelem i użyć go w czasie wnioskowania, aby podać poszczególne wartości ważności funkcji (lokalne wyjaśnienie) dla dowolnego nowego punktu danych. Oferujemy również jaśniejsze wyjaśnienia oceniania wagi w celu zwiększenia wydajności interpretowania w czasie wnioskowania, który jest obecnie obsługiwany tylko w zestawie SDK usługi Azure Machine Edukacja. Proces wdrażania wyjaśnień oceniania o lżejszej wadze jest podobny do wdrażania modelu i obejmuje następujące kroki:
Utwórz obiekt wyjaśnienia. Możesz na przykład użyć polecenia
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Utwórz objaśnienie oceniania z obiektem wyjaśnienia.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Skonfiguruj i zarejestruj obraz, który używa modelu objaśnienia oceniania.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Opcjonalnie możesz pobrać objaśnienie oceniania z chmury i przetestować wyjaśnienia.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Wdróż obraz w docelowym obiekcie obliczeniowym, wykonując następujące kroki:
W razie potrzeby zarejestruj oryginalny model przewidywania, wykonując kroki opisane w artykule Wdrażanie modeli przy użyciu usługi Azure Machine Edukacja.
Utwórz plik oceniania.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Zdefiniowanie konfiguracji wdrożenia.
Ta konfiguracja zależy od wymagań modelu. W poniższym przykładzie zdefiniowano konfigurację, która używa jednego rdzenia procesora CPU i jednego GB pamięci.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Utwórz plik z zależnościami środowiska.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Utwórz niestandardowy plik dockerfile z zainstalowanym językiem g++.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Wdróż utworzony obraz.
Ten proces trwa około pięciu minut.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Przetestuj wdrożenie.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Wyczyść.
Aby usunąć wdrożona usługa sieci Web, użyj polecenia
service.delete().
Rozwiązywanie problemów
Dane rozrzedne nie są obsługiwane: pulpit nawigacyjny wyjaśnienia modelu przerywa/spowalnia znacznie z dużą liczbą funkcji, dlatego obecnie nie obsługujemy rozrzednia formatu danych. Ponadto ogólne problemy z pamięcią będą występować w przypadku dużych zestawów danych i dużej liczby funkcji.
Macierz obsługiwanych wyjaśnień
| Karta Obsługiwane wyjaśnienia | Funkcje pierwotne (gęste) | Funkcje pierwotne (rozrzedzone) | Funkcje zaprojektowane (gęste) | Funkcje zaprojektowane (rozrzedzone) |
|---|---|---|---|---|
| Wydajność modelu | Obsługiwane (brak prognozowania) | Obsługiwane (brak prognozowania) | Obsługiwane | Obsługiwane |
| Eksplorator zestawów danych | Obsługiwane (brak prognozowania) | Nieobsługiwane. Ponieważ rozrzedzone dane nie są przekazywane, a interfejs użytkownika ma problemy z renderowaniem rozrzedzone dane. | Obsługiwane | Nieobsługiwane. Ponieważ rozrzedzone dane nie są przekazywane, a interfejs użytkownika ma problemy z renderowaniem rozrzedzone dane. |
| Zagregowane znaczenie funkcji | Obsługiwane | Obsługiwane | Obsługiwane | Obsługiwane |
| Ważność poszczególnych cech | Obsługiwane (brak prognozowania) | Nieobsługiwane. Ponieważ rozrzedzone dane nie są przekazywane, a interfejs użytkownika ma problemy z renderowaniem rozrzedzone dane. | Obsługiwane | Nieobsługiwane. Ponieważ rozrzedzone dane nie są przekazywane, a interfejs użytkownika ma problemy z renderowaniem rozrzedzone dane. |
Modele prognozowania nie są obsługiwane w przypadku wyjaśnień modelu: Interpretacja, najlepsze wyjaśnienie modelu, nie jest dostępna w przypadku eksperymentów prognozowania automatycznego uczenia maszynowego, które zalecają następujące algorytmy jako najlepszy model: TCNForecaster, AutoArima, Prorok, WykładniczySmoothing, Average, Naive, Sezonowa średnia i Sezonowa naiwność. Modele regresji prognozowania automatycznego uczenia maszynowego obsługują wyjaśnienia. Jednak na pulpicie nawigacyjnym objaśnienia karta "Ważność poszczególnych funkcji" nie jest obsługiwana ze względu na złożoność potoków danych.
Lokalne wyjaśnienie indeksu danych: pulpit nawigacyjny wyjaśnienia nie obsługuje wiązania lokalnych wartości ważności z identyfikatorem wiersza z oryginalnego zestawu danych weryfikacji, jeśli ten zestaw danych jest większy niż 5000 punktów danych, ponieważ pulpit nawigacyjny losowo obniża próbkowanie danych. Jednak na pulpicie nawigacyjnym są wyświetlane nieprzetworzone wartości funkcji zestawu danych dla każdego punktu danych przekazanego do pulpitu nawigacyjnego na karcie Ważność poszczególnych funkcji. Użytkownicy mogą mapować lokalne znaczenie z powrotem do oryginalnego zestawu danych, pasując do pierwotnych wartości funkcji zestawu danych. Jeśli rozmiar zestawu danych sprawdzania poprawności jest mniejszy niż 5000 przykładów,
indexfunkcja w usłudze Azure Machine Edukacja Studio będzie odpowiadać indeksowi w zestawie danych weryfikacji.Wykresy warunkowe/ICE nieobsługiwane w studio: wykresy Warunkowe i Oczekiwania warunkowe (ICE) nie są obsługiwane w usłudze Azure Machine Edukacja Studio na karcie Wyjaśnienia, ponieważ przekazane wyjaśnienie wymaga aktywnego obliczenia w celu ponownego obliczenia przewidywań i prawdopodobieństwa zburzonych funkcji. Jest ona obecnie obsługiwana w notesach Jupyter w przypadku uruchamiania jako widżetu przy użyciu zestawu SDK.
Następne kroki
Techniki interpretowania modelu w usłudze Azure Machine Edukacja
Zapoznaj się z przykładowymi notesami usługi Azure Machine Edukacja interpretability