Uruchamianie przewidywań wsadowych przy użyciu projektanta usługi Azure Machine Learning
Z tego artykułu dowiesz się, jak utworzyć potok przewidywania wsadowego za pomocą projektanta. Przewidywanie wsadowe umożliwia ciągłe ocenianie dużych zestawów danych na żądanie przy użyciu usługi internetowej, która może być wyzwalana z dowolnej biblioteki HTTP.
Z tego przewodnika dowiesz się, jak wykonywać następujące zadania:
- Tworzenie i publikowanie potoku wnioskowania wsadowego
- Korzystanie z punktu końcowego potoku
- Zarządzanie wersjami punktów końcowych
Aby dowiedzieć się, jak skonfigurować usługi oceniania wsadowego przy użyciu zestawu SDK, zobacz towarzyszący samouczek dotyczący oceniania wsadowego potoku.
Wymagania wstępne
W ten sposób założono, że masz już potok trenowania. Aby zapoznać się z wprowadzeniem z przewodnikiem do projektanta, ukończ jedną z części samouczka projektanta.
Ważne
Jeśli nie widzisz elementów graficznych wymienionych w tym dokumencie, takich jak przyciski w studio lub projektancie, być może nie masz odpowiedniego poziomu uprawnień do obszaru roboczego. Skontaktuj się z administratorem subskrypcji platformy Azure, aby sprawdzić, czy udzielono Ci poprawnego poziomu dostępu. Aby uzyskać więcej informacji, zobacz Zarządzanie użytkownikami i rolami.
Tworzenie potoku wnioskowania wsadowego
Potok trenowania musi być uruchamiany co najmniej raz, aby można było utworzyć potok wnioskowania.
Przejdź do karty Projektant w obszarze roboczym.
Wybierz potok trenowania, który trenuje model, którego chcesz użyć do przewidywania.
Prześlij potok.


Po lewej stronie kanwy zostanie wyświetlona lista przesyłania. Możesz wybrać link szczegółów zadania, aby przejść do strony szczegółów zadania, a po zakończeniu zadania potoku trenowania możesz utworzyć potok wnioskowania wsadowego.

Na stronie szczegółów zadania nad kanwą wybierz listę rozwijaną Utwórz potok wnioskowania. Wybierz pozycję Potok wnioskowania wsadowego.
Uwaga
Obecnie potok wnioskowania automatycznego działa tylko w przypadku potoku trenowania utworzonego wyłącznie przez wbudowane składniki projektanta.

Spowoduje to utworzenie wersji roboczej potoku wnioskowania wsadowego. Wersja robocza potoku wnioskowania wsadowego używa wytrenowanego modelu jako węzła MD- i przekształcenia jako węzła TD- z zadania potoku trenowania.
Możesz również zmodyfikować tę wersję roboczą potoku wnioskowania, aby lepiej obsługiwać dane wejściowe na potrzeby wnioskowania wsadowego.



Dodawanie parametru potoku
Aby utworzyć przewidywania dotyczące nowych danych, możesz ręcznie połączyć inny zestaw danych w tym widoku roboczym potoku lub utworzyć parametr dla zestawu danych. Parametry umożliwiają zmianę zachowania procesu wnioskowania wsadowego w czasie wykonywania.
W tej sekcji utworzysz parametr zestawu danych, aby określić inny zestaw danych do przewidywania.
Wybierz składnik zestawu danych.
Po prawej stronie kanwy zostanie wyświetlone okienko. W dolnej części okienka wybierz pozycję Ustaw jako parametr potoku.
Wprowadź nazwę parametru lub zaakceptuj wartość domyślną.

Prześlij potok wnioskowania wsadowego i przejdź do strony szczegółów zadania, wybierając link zadania w okienku po lewej stronie.

Publikowanie potoku wnioskowania wsadowego
Teraz możesz przystąpić do wdrażania potoku wnioskowania. Spowoduje to wdrożenie potoku i udostępnienie go innym osobom.
Wybierz przycisk Publikuj.
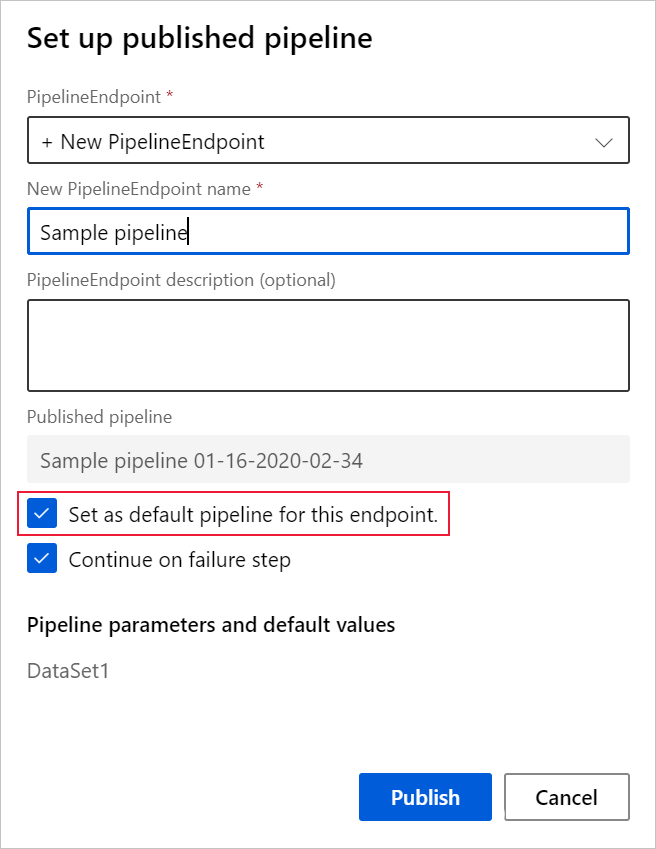
W wyświetlonym oknie dialogowym rozwiń listę rozwijaną PipelineEndpoint i wybierz pozycję Nowy potokEndpoint.
Podaj nazwę punktu końcowego i opcjonalny opis.
W dolnej części okna dialogowego można zobaczyć parametr skonfigurowany z wartością domyślną identyfikatora zestawu danych używanego podczas trenowania.
Wybierz Publikuj.

Korzystanie z punktu końcowego
Teraz masz opublikowany potok z parametrem zestawu danych. Potok będzie używać wytrenowanego modelu utworzonego w potoku trenowania w celu oceny zestawu danych podanego jako parametru.
Przesyłanie zadania potoku
W tej sekcji skonfigurujesz zadanie potoku ręcznego i zmienisz parametr potoku, aby ocenić nowe dane.
Po zakończeniu wdrażania przejdź do sekcji Punkty końcowe .
Wybierz pozycję Punkty końcowe potoku.
Wybierz nazwę utworzonego punktu końcowego.
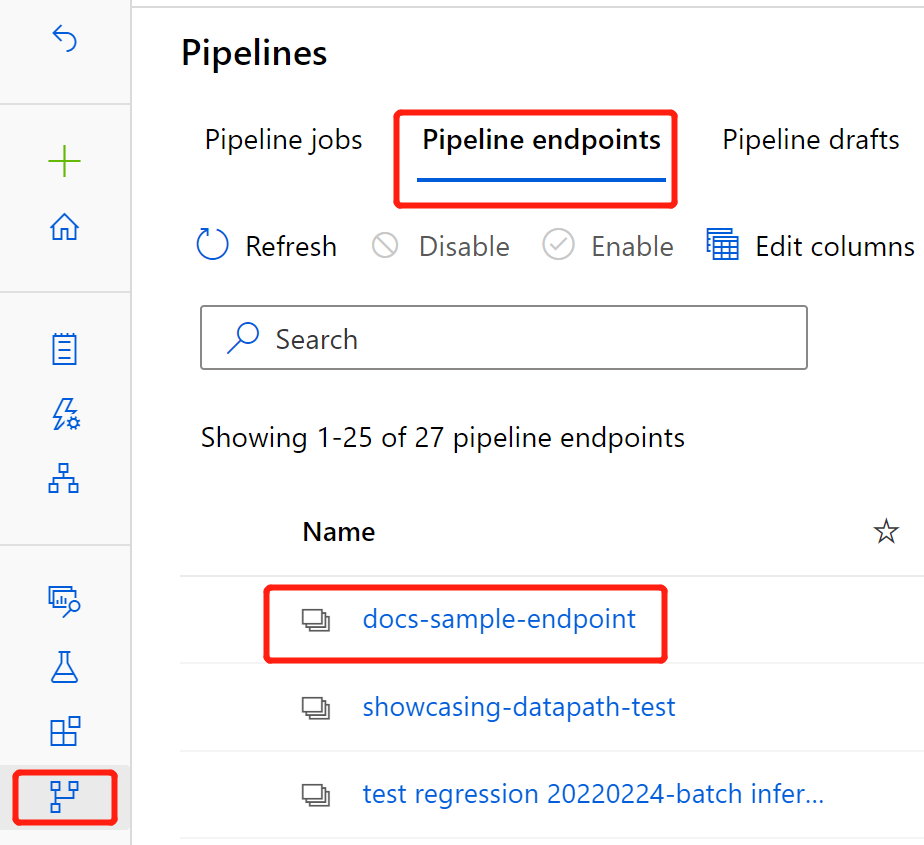
Wybierz pozycję Opublikowane potoki.
Ten ekran przedstawia wszystkie opublikowane potoki opublikowane w tym punkcie końcowym.
Wybierz opublikowany potok.
Na stronie szczegółów potoku przedstawiono szczegółową historię zadań i parametry połączenia informacje dotyczące potoku.
Wybierz pozycję Prześlij , aby utworzyć ręczne uruchomienie potoku.

Zmień parametr tak, aby używał innego zestawu danych.
Wybierz pozycję Prześlij , aby uruchomić potok.

Korzystanie z punktu końcowego REST
Informacje na temat korzystania z punktów końcowych potoku i opublikowanego potoku można znaleźć w sekcji Punkty końcowe .
Punkt końcowy REST punktu końcowego potoku można znaleźć w panelu przeglądu zadania. Wywołując punkt końcowy, korzystasz z domyślnego opublikowanego potoku.
Możesz również użyć opublikowanego potoku na stronie Opublikowane potoki . Wybierz opublikowany potok i możesz znaleźć punkt końcowy REST w panelu przeglądu opublikowanego potoku po prawej stronie grafu.
Aby wykonać wywołanie REST, potrzebny będzie nagłówek uwierzytelniania elementu nośnego OAuth 2.0. Zobacz następującą sekcję samouczka, aby uzyskać więcej informacji na temat konfigurowania uwierzytelniania w obszarze roboczym i wykonywania sparametryzowanego wywołania REST.
Punkty końcowe przechowywania wersji
Projektant przypisuje wersję do każdego kolejnego potoku publikowanego w punkcie końcowym. Możesz określić wersję potoku, którą chcesz wykonać jako parametr w wywołaniu REST. Jeśli nie określisz numeru wersji, projektant użyje potoku domyślnego.
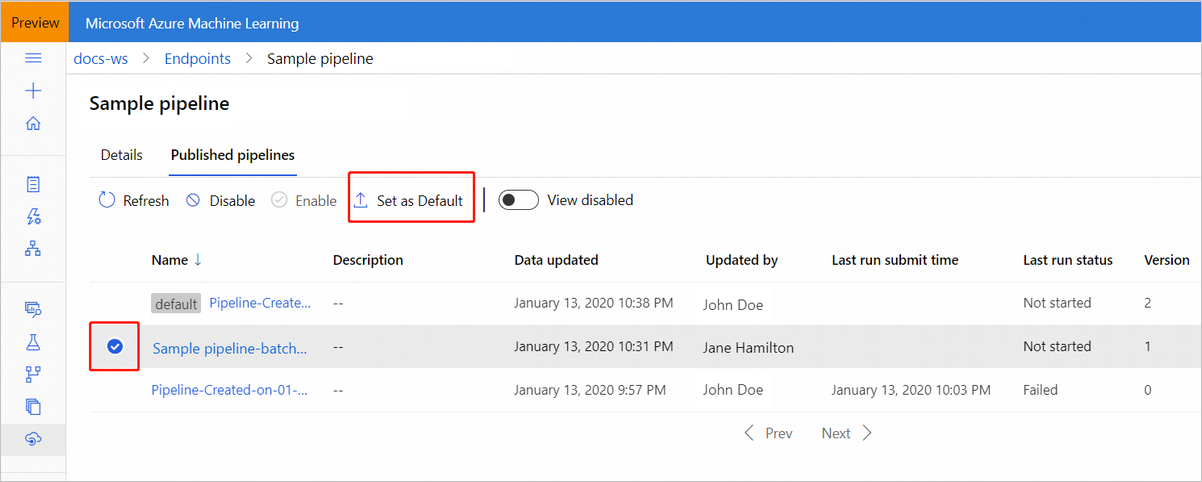
Podczas publikowania potoku możesz ustawić go jako nowy domyślny potok dla tego punktu końcowego.
Możesz również ustawić nowy potok domyślny na karcie Opublikowane potoki punktu końcowego.
Aktualizowanie punktu końcowego potoku
Jeśli wprowadzisz pewne modyfikacje w potoku trenowania, możesz zaktualizować nowo wytrenowany model do punktu końcowego potoku.
Po pomyślnym zakończeniu zmodyfikowanego potoku trenowania przejdź do strony szczegółów zadania.
Kliknij prawym przyciskiem myszy pozycję Train Model component (Trenowanie składnika modelu) i wybierz polecenie Register data (Zarejestruj dane)
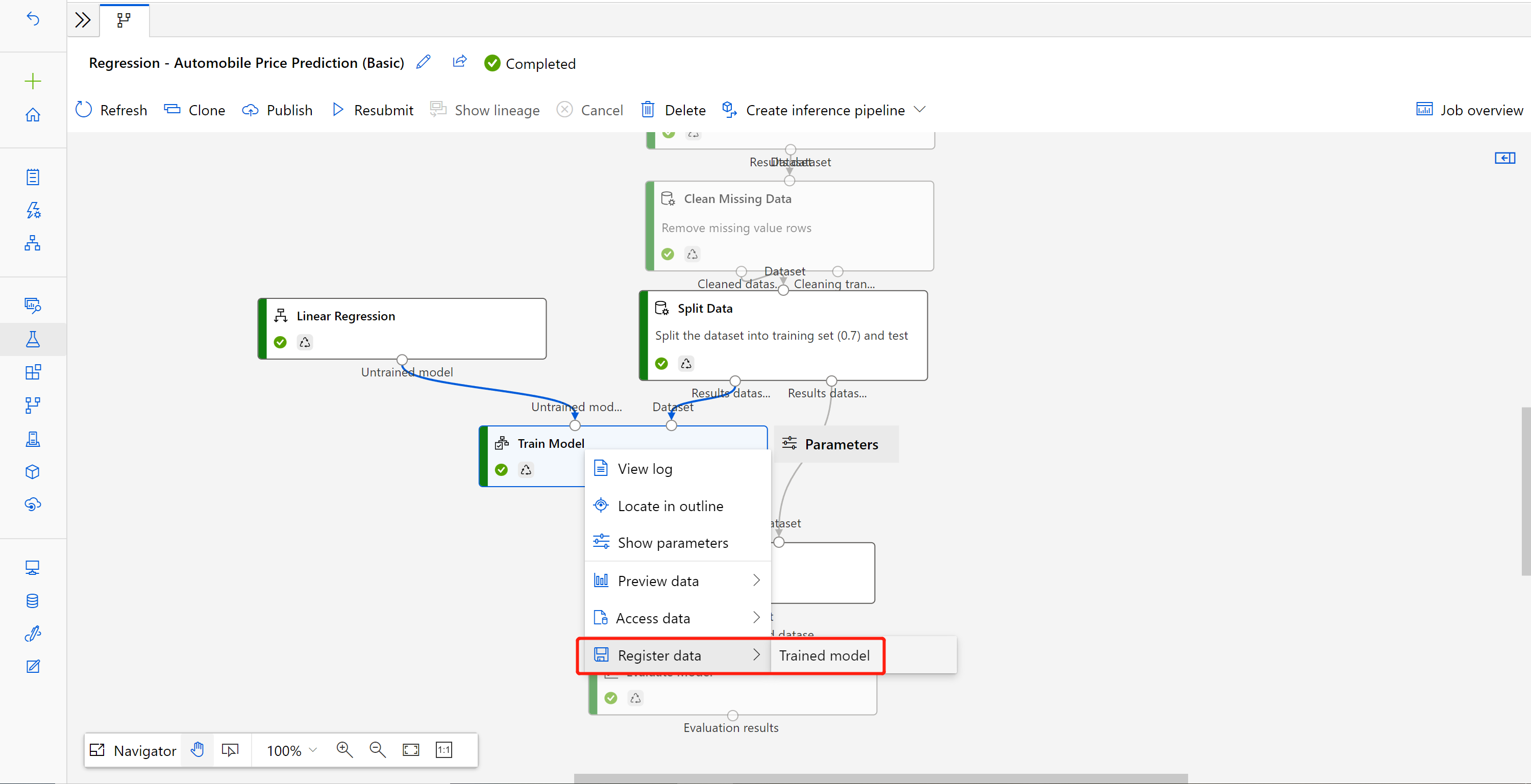
Nazwa danych wejściowych i wybierz pozycję Typ pliku .
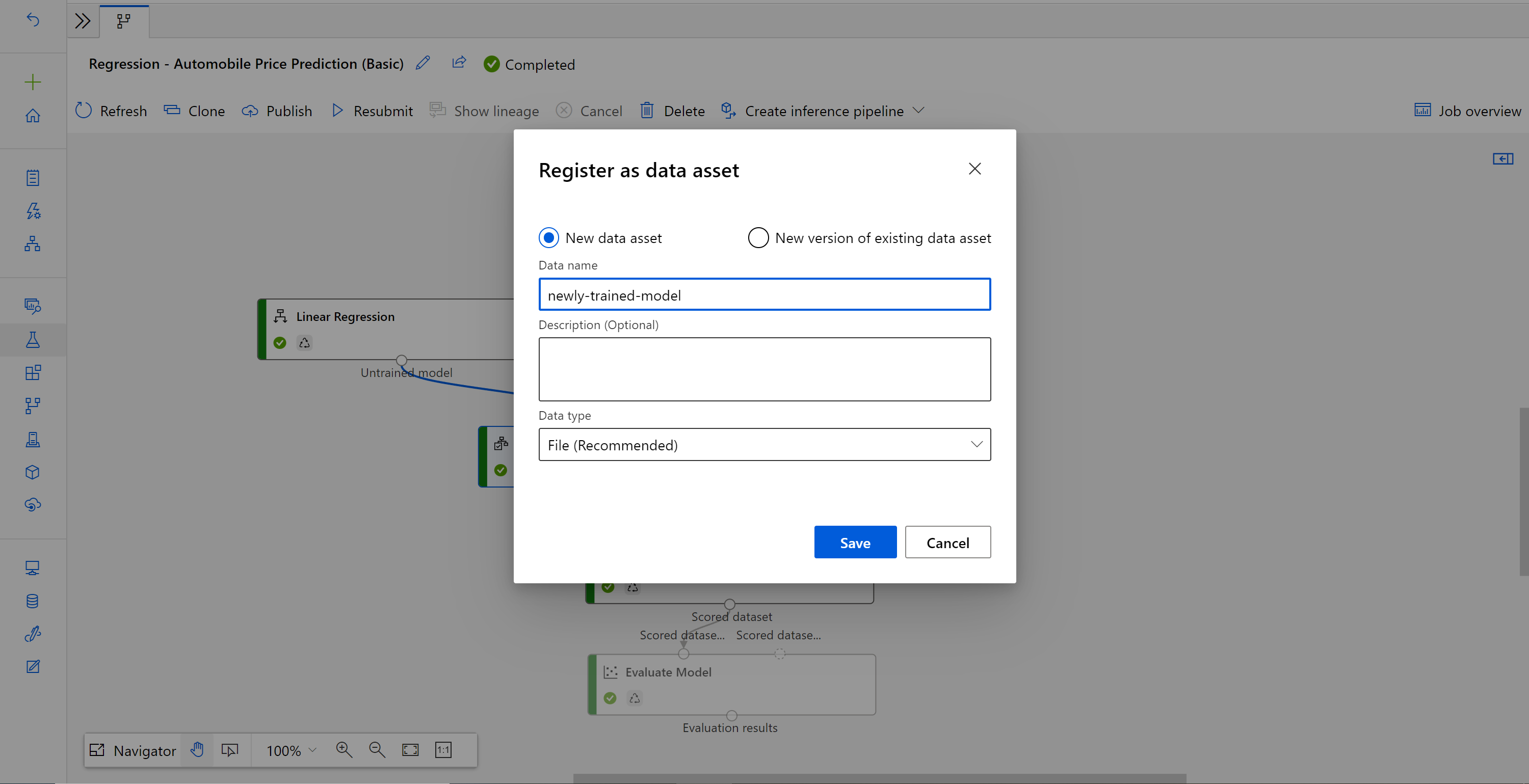
Znajdź poprzednią wersję roboczą potoku wnioskowania wsadowego lub możesz po prostu sklonować opublikowany potok do nowej wersji roboczej.
Zastąp węzeł MD- w wersji roboczej potoku wnioskowania zarejestrowanymi danymi w powyższym kroku.
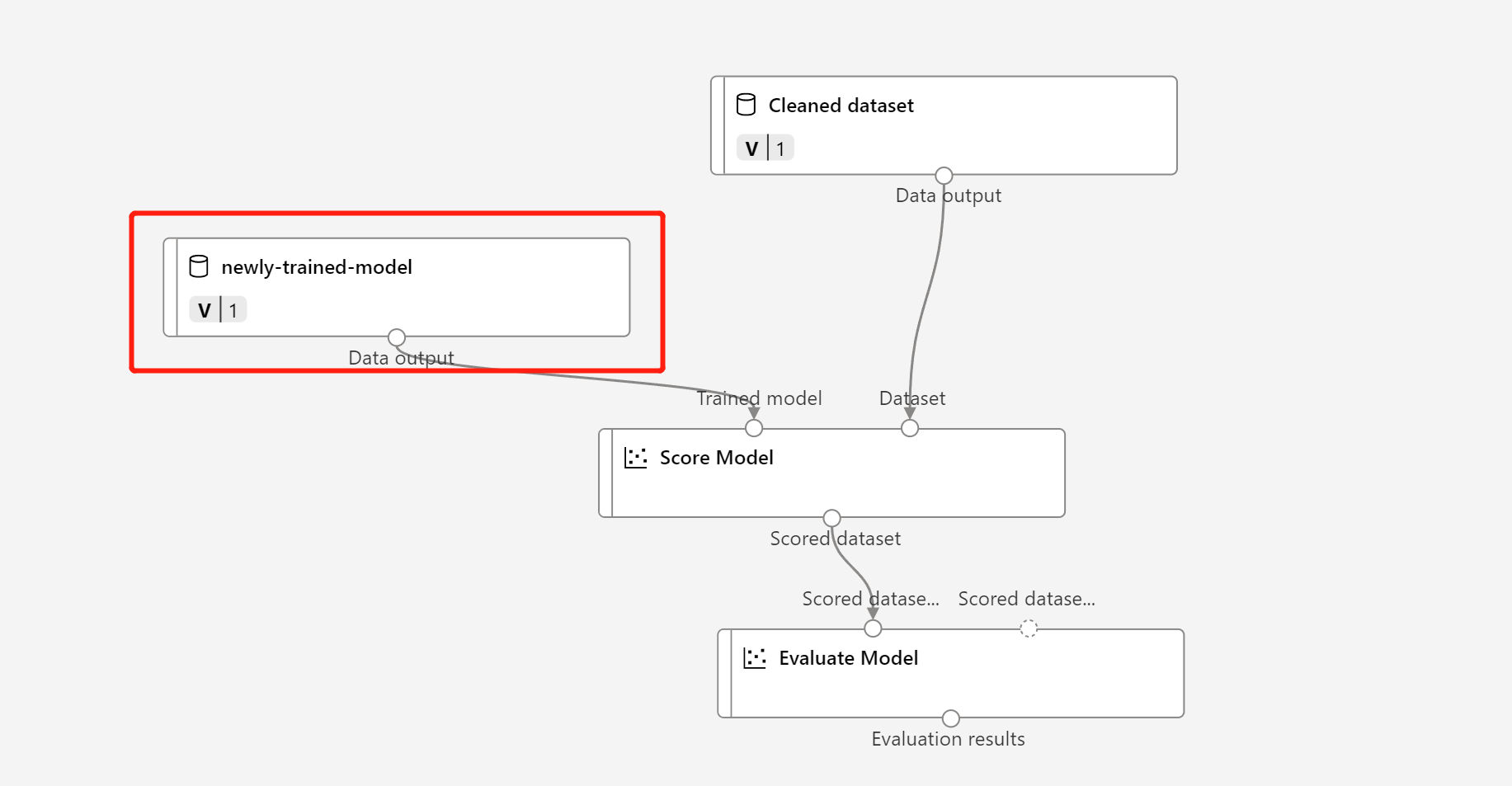
Aktualizowanie węzła przekształcania danych TD — jest takie samo jak wytrenowany model.
Następnie możesz przesłać potok wnioskowania ze zaktualizowanym modelem i przekształceniem, a następnie opublikować go ponownie.


Następne kroki
- Postępuj zgodnie z samouczkiem dotyczącym projektanta, aby wytrenować i wdrożyć model regresji.
- Aby uzyskać informacje na temat publikowania i uruchamiania opublikowanego potoku przy użyciu zestawu SDK w wersji 1, zobacz artykuł How to deploy pipelines (Jak wdrażać potoki ).