Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Ten artykuł zawiera informacje na temat korzystania z zestawu Azure Machine Learning SDK w wersji 1. Zestaw SDK w wersji 1 jest przestarzały od 31 marca 2025 r. Wsparcie dla niego zakończy się 30 czerwca 2026 r. Do tej pory można zainstalować zestaw SDK w wersji 1 i używać go. Istniejące przepływy pracy korzystające z zestawu SDK w wersji 1 będą nadal działać po dacie zakończenia pomocy technicznej. Mogą one jednak być narażone na zagrożenia bezpieczeństwa lub niespójności w przypadku zmian architektury w produkcie.
Zalecamy przejście do zestawu SDK w wersji 2 przed 30 czerwca 2026 r. Aby uzyskać więcej informacji na temat zestawu SDK w wersji 2, zobacz Co to jest interfejs wiersza polecenia usługi Azure Machine Learning i zestaw Python SDK w wersji 2? oraz dokumentacja zestawu SDK w wersji 2.
Jeśli zastanawiasz się, który algorytm uczenia maszynowego ma być używany, odpowiedź zależy przede wszystkim od dwóch aspektów scenariusza nauki o danych:
Co chcesz zrobić z danymi? W szczególności jakie jest pytanie biznesowe, na które chcesz odpowiedzieć, ucząc się z poprzednich danych?
Jakie są wymagania scenariusza nauki o danych? Jakie są funkcje, dokładność, czas trenowania, liniowość i parametry obsługiwane przez rozwiązanie?
Uwaga
Projektant usługi Azure Machine Learning obsługuje dwa typy składników: klasyczne wstępnie utworzone składniki (wersja 1) i składniki niestandardowe (wersja 2). Te dwa typy składników nie są zgodne.
Klasyczne wstępnie utworzone składniki są przeznaczone głównie do przetwarzania danych i tradycyjnych zadań uczenia maszynowego, takich jak regresja i klasyfikacja. Ten typ składników nadal jest obsługiwany, ale nie będą do niego dodawane żadne nowego składniki.
Składniki niestandardowe umożliwiają opakowywanie własnego kodu jako składnika. Obsługują udostępnianie składników między obszarami roboczymi i bezproblemowe tworzenie w interfejsach programu Studio, interfejsu wiersza polecenia w wersji 2 i zestawu SDK w wersji 2.
W przypadku nowych projektów zdecydowanie zalecamy używanie składników niestandardowych, które są zgodne z usługą AzureML w wersji 2 i będą otrzymywać nowe aktualizacje.
Ten artykuł dotyczy klasycznych wstępnie utworzonych składników i nie jest zgodny z interfejsem wiersza polecenia w wersji 2 i zestawem SDK w wersji 2.
Ściągawka dotycząca algorytmów usługi Azure Machine Learning
Ściągawka dotycząca algorytmów usługi Azure Machine Learning pomaga w pierwszej kwestii: Co chcesz zrobić z danymi? W ściągawce poszukaj zadania, które chcesz wykonać, a następnie znajdź algorytm projektanta usługi Azure Machine Learning dla rozwiązania do analizy predykcyjnej.
Uwaga
Możesz pobrać ściągawkę dotycząca algorytmów uczenia maszynowego.
Projektant udostępnia kompleksowe portfolio algorytmów, takich jak wieloklasowy las decyzyjny, systemy rekomendacji, regresja sieci neuronowej, wieloklasowa sieć neuronowa i klastrowanie metodą K-Średnich. Każdy algorytm został zaprojektowany w celu rozwiązania innego typu problemu z uczeniem maszynowym. Zapoznaj się z dokumentacją dotyczącą algorytmu i składnika , aby uzyskać pełną listę wraz z dokumentacją dotyczącą działania poszczególnych algorytmów i dostrajania parametrów w celu optymalizacji algorytmu.
Oprócz tych wskazówek należy pamiętać o innych wymaganiach podczas wybierania algorytmu uczenia maszynowego. Poniżej przedstawiono dodatkowe czynniki, które należy wziąć pod uwagę, takie jak dokładność, czas trenowania, liniowość, liczba parametrów i liczba funkcji.
Porównanie algorytmów uczenia maszynowego
Niektóre algorytmy tworzą konkretne założenia dotyczące struktury danych lub żądanych wyników. Jeśli możesz znaleźć taki, który odpowiada Twoim potrzebom, może dać ci bardziej przydatne wyniki, dokładniejsze przewidywania lub szybsze czasy trenowania.
Poniższa tabela zawiera podsumowanie najważniejszych cech algorytmów klasyfikacji, regresji i rodzin klastrowania:
| Algorytm | Dokładność | Czas trenowania | Liniowości | Parametry | Uwagi |
|---|---|---|---|---|---|
| Rodzina klasyfikacji | |||||
| Regresja logistyczna dwuklasowa | Dobrze | Szybkie przetwarzanie | Tak | 100 | |
| Dwuklasowy las decyzyjny | Doskonałe | Umiarkowane | Nie. | 5 | Pokazuje wolniejsze czasy oceniania. Sugerujemy, że nie współpracujemy z wieloklasą one-vs-all z powodu wolniejszych czasów oceniania spowodowanych blokowaniem wątków w przewidywaniach drzewa gromadzenia |
| Dwuklasowe wzmocnione drzewo decyzyjne | Doskonałe | Umiarkowane | Nie. | 6 | Duże zużycie pamięci |
| Dwuklasowa sieć neuronowa | Dobrze | Umiarkowane | Nie. | 8 | |
| Dwuklasowa średnia perceptron | Dobrze | Umiarkowane | Tak | 100 | |
| Dwuklasowa maszyna wektorowa obsługi | Dobrze | Szybkie przetwarzanie | Tak | 5 | Dobre dla dużych zestawów funkcji |
| Regresja logistyczna wieloklasowa | Dobrze | Szybkie przetwarzanie | Tak | 100 | |
| Wieloklasowy las decyzyjny | Doskonałe | Umiarkowane | Nie. | 5 | Pokazuje wolniejsze czasy oceniania |
| Wieloklasowe wzmocnione drzewo decyzyjne | Doskonałe | Umiarkowane | Nie. | 6 | Ma tendencję do poprawy dokładności z niewielkim ryzykiem mniejszego pokrycia |
| Wieloklasowa sieć neuronowa | Dobrze | Umiarkowane | Nie. | 8 | |
| Jedna i wszystkie wieloklasy | - | - | - | - | Zobacz właściwości wybranej metody dwuklasowej |
| Rodzina regresji | |||||
| Regresja liniowa | Dobrze | Szybkie przetwarzanie | Tak | 100 | |
| Regresja lasu decyzyjnego | Doskonałe | Umiarkowane | Nie. | 5 | |
| Zwiększenie regresji drzewa decyzyjnego | Doskonałe | Umiarkowane | Nie. | 6 | Duże zużycie pamięci |
| Regresja sieci neuronowej | Dobrze | Umiarkowane | Nie. | 8 | |
| Rodzina klastrów | |||||
| Klastrowanie K-średnich | Doskonałe | Umiarkowane | Tak | 8 | Algorytm klastrowania |
Wymagania dotyczące scenariusza nauki o danych
Gdy wiesz, co chcesz zrobić z danymi, musisz określić inne wymagania dotyczące scenariusza nauki o danych.
Dokonaj wyborów i ewentualnie kompromisów dla następujących wymagań:
- Dokładność
- Czas trenowania
- Liniowości
- Liczba parametrów
- Liczba funkcji
Dokładność
Dokładność w uczeniu maszynowym mierzy skuteczność modelu jako proporcję rzeczywistych wyników do łącznej liczby przypadków. W projektancie składnik Evaluate Model oblicza zestaw metryk oceny standardu branżowego. Za pomocą tego składnika można zmierzyć dokładność wytrenowanego modelu.
Uzyskanie najdokładniejszej możliwej odpowiedzi nie zawsze jest konieczne. Czasami przybliżenie jest odpowiednie, w zależności od tego, do czego chcesz go użyć. Jeśli tak jest, możesz znacznie skrócić czas przetwarzania, trzymając się bardziej przybliżonych metod. Przybliżone metody również naturalnie mają tendencję do unikania nadmiernego dopasowania.
Istnieją trzy sposoby używania składnika Evaluate Model( Ocena modelu):
- Wygeneruj wyniki na podstawie danych treningowych, aby ocenić model.
- Wygeneruj wyniki w modelu, ale porównaj te wyniki z wynikami w zestawie testów zarezerwowanych.
- Porównaj wyniki dla dwóch różnych, ale powiązanych modeli przy użyciu tego samego zestawu danych.
Aby uzyskać pełną listę metryk i podejść, których można użyć do oceny dokładności modeli uczenia maszynowego, zobacz Evaluate Model component (Ocena składnika modelu).
Czas trenowania
W uczeniu nadzorowanym trenowanie oznacza używanie danych historycznych do tworzenia modelu uczenia maszynowego, który minimalizuje błędy. Liczba minut lub godzin potrzebnych do wytrenowania modelu różni się znacznie między algorytmami. Czas trenowania jest często ściśle związany z dokładnością; zwykle towarzyszy drugiemu.
Ponadto niektóre algorytmy są bardziej wrażliwe na liczbę punktów danych niż inne. Możesz wybrać określony algorytm, ponieważ masz ograniczenie czasowe, zwłaszcza gdy zestaw danych jest duży.
W projektancie tworzenie i używanie modelu uczenia maszynowego jest zwykle procesem trzyetapowym:
Skonfiguruj model, wybierając określony typ algorytmu, a następnie definiując jego parametry lub hiperparametry.
Podaj zestaw danych oznaczony etykietą i ma dane zgodne z algorytmem. Połącz zarówno dane, jak i model ze składnikiem Train Model (Trenowanie modelu).
Po zakończeniu trenowania użyj wytrenowanego modelu z jednym ze składników oceniania, aby przewidywać nowe dane.
Liniowości
Liniowość statystyk i uczenia maszynowego oznacza, że istnieje relacja liniowa między zmienną a stałą w zestawie danych. Na przykład algorytmy klasyfikacji liniowej zakładają, że klasy mogą być oddzielone linią prostą (lub analogią wyższą).
Wiele algorytmów uczenia maszynowego wykorzystuje liniowość. W projektancie usługi Azure Machine Learning należą do nich:
Algorytmy regresji liniowej zakładają, że trendy danych są zgodne z linią prostą. To założenie nie jest złe dla niektórych problemów, ale dla innych zmniejsza dokładność. Pomimo ich wad algorytmy liniowe są popularne jako pierwsza strategia. Zwykle są one algorytmicznie proste i szybkie do trenowania.
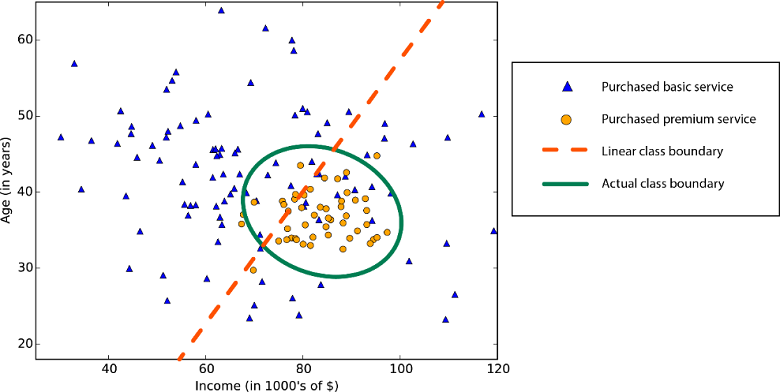
Granica klasy nieliniowej: poleganie na algorytmie klasyfikacji liniowej spowodowałoby niską dokładność.
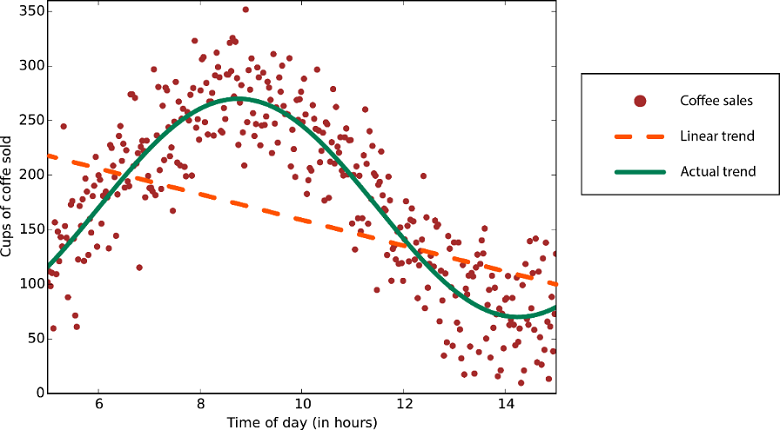
Dane z trendem nieliniowym: użycie metody regresji liniowej spowodowałoby wygenerowanie znacznie większych błędów niż jest to konieczne.
Liczba parametrów
Parametry to pokrętła, które analityk danych może włączyć podczas konfigurowania algorytmu. Są to liczby wpływające na zachowanie algorytmu, takie jak tolerancja błędów lub liczba iteracji, lub opcje między wariantami zachowania algorytmu. Czas trenowania i dokładność algorytmu może czasami być wrażliwa na uzyskanie odpowiednich ustawień. Zazwyczaj algorytmy z dużą liczbą parametrów wymagają największej liczby prób i błędów, aby znaleźć dobrą kombinację.
Alternatywnie w projektancie znajduje się składnik Hiperparametry modelu dostrajania. Celem tego składnika jest określenie optymalnych hiperparametrów dla modelu uczenia maszynowego. Składnik kompiluje i testuje wiele modeli przy użyciu różnych kombinacji ustawień. Porównuje metryki we wszystkich modelach, aby uzyskać kombinacje ustawień.
Chociaż jest to doskonały sposób, aby upewnić się, że zakres przestrzeni parametrów został przekroczony, czas wymagany do wytrenowania modelu zwiększa się wykładniczo wraz z liczbą parametrów. Plusem jest to, że posiadanie wielu parametrów zwykle wskazuje, że algorytm ma większą elastyczność. Często może osiągnąć bardzo dobrą dokładność, pod warunkiem, że można znaleźć odpowiednią kombinację ustawień parametrów.
Liczba funkcji
W uczeniu maszynowym funkcja jest kwantyfikalną zmienną zjawiska, które próbujesz przeanalizować. W przypadku niektórych typów danych liczba funkcji może być bardzo duża w porównaniu z liczbą punktów danych. Jest to często przypadek genetyki lub danych tekstowych.
Duża liczba funkcji może strasić niektóre algorytmy uczenia, co sprawia, że czas trenowania jest niewyobrażająco długi. Maszyny wektorów nośnych są dobrze dopasowane do scenariuszy z dużą liczbą funkcji. Z tego powodu zostały one użyte w wielu aplikacjach z pobierania informacji do klasyfikacji tekstu i obrazów. Maszyny wektorów nośnych mogą służyć zarówno do zadań klasyfikacji, jak i regresji.
Wybór funkcji odnosi się do procesu stosowania testów statystycznych do danych wejściowych, biorąc pod uwagę określone dane wyjściowe. Celem jest określenie, które kolumny są bardziej predykcyjne danych wyjściowych. Składnik Wybór cech opartych na filtrach w projektancie udostępnia wiele algorytmów wyboru funkcji do wyboru. Składnik zawiera metody korelacji, takie jak korelacja Pearson i wartości chi kwadratu.
Możesz również użyć składnika Ważność funkcji permutacji, aby obliczyć zestaw wyników ważności funkcji dla zestawu danych. Następnie możesz użyć tych wyników, aby ułatwić określenie najlepszych funkcji do użycia w modelu.