Wdrażanie modeli oceniania w punktach końcowych wsadowych
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Punkty końcowe usługi Batch zapewniają wygodny sposób wdrażania modeli, które uruchamiają wnioskowanie na dużych ilościach danych. Te punkty końcowe upraszczają proces hostowania modeli na potrzeby oceniania wsadowego, dzięki czemu koncentrujesz się na uczeniu maszynowym, a nie na infrastrukturze.
Użyj punktów końcowych wsadowych do wdrażania modelu, gdy:
- Masz kosztowne modele, które wymagają dłuższego czasu na wnioskowanie.
- Należy przeprowadzić wnioskowanie na dużych ilościach danych, które są dystrybuowane w wielu plikach.
- Nie masz wymagań dotyczących małych opóźnień.
- Możesz skorzystać z równoległości.
W tym artykule użyjesz punktu końcowego wsadowego do wdrożenia modelu uczenia maszynowego, który rozwiązuje klasyczny problem rozpoznawania cyfr MNIST (zmodyfikowany Narodowy Instytut Standardów i Technologii). Wdrożony model wykonuje następnie wnioskowanie wsadowe na dużych ilościach danych — w tym przypadku pliki obrazów. Zacznij od utworzenia wdrożenia wsadowego modelu, który został utworzony przy użyciu platformy Torch. To wdrożenie staje się domyślne w punkcie końcowym. Później utworzysz drugie wdrożenie trybu, który został utworzony za pomocą biblioteki TensorFlow (Keras), przetestujesz drugie wdrożenie, a następnie ustawisz je jako domyślne wdrożenie punktu końcowego.
Aby postępować zgodnie z przykładami kodu i plikami wymaganymi do uruchamiania poleceń w tym artykule lokalnie, zobacz sekcję Klonowanie repozytorium przykładów. Przykłady kodu i pliki znajdują się w repozytorium azureml-examples .
Wymagania wstępne
Przed wykonaniem kroków opisanych w tym artykule upewnij się, że masz następujące wymagania wstępne:
Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Edukacja.
Obszar roboczy usługi Azure Machine Learning. Jeśli go nie masz, wykonaj kroki opisane w artykule How to manage workspaces (Jak zarządzać obszarami roboczymi ), aby je utworzyć.
Aby wykonać następujące zadania, upewnij się, że masz te uprawnienia w obszarze roboczym:
Aby utworzyć i zarządzać punktami końcowymi i wdrożeniami wsadowymi: użyj roli właściciela, roli współautora lub roli niestandardowej zezwalającej na
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*usługę .Aby utworzyć wdrożenia usługi ARM w grupie zasobów obszaru roboczego: użyj roli właściciela, roli współautora lub roli niestandardowej zezwalającej
Microsoft.Resources/deployments/writew grupie zasobów, w której wdrożono obszar roboczy.
Aby pracować z usługą Azure Machine Edukacja, należy zainstalować następujące oprogramowanie:
DOTYCZY:
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (bieżąca)Interfejs wiersza polecenia platformy
mlAzure i rozszerzenie usługi Azure Machine Edukacja.az extension add -n ml
Klonowanie repozytorium przykładów
Przykład w tym artykule jest oparty na przykładach kodu zawartych w repozytorium azureml-examples . Aby uruchomić polecenia lokalnie bez konieczności kopiowania/wklejania kodu YAML i innych plików, najpierw sklonuj repozytorium, a następnie zmień katalogi na folder:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Przygotowywanie systemu
Nawiązywanie połączenia z obszarem roboczym
Najpierw połącz się z obszarem roboczym usługi Azure Machine Edukacja, w którym będziesz pracować.
Jeśli nie ustawiono jeszcze ustawień domyślnych dla interfejsu wiersza polecenia platformy Azure, zapisz ustawienia domyślne. Aby uniknąć wielokrotnego przekazywania wartości dla subskrypcji, obszaru roboczego, grupy zasobów i lokalizacji, uruchom następujący kod:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Tworzenie zasobów obliczeniowych
Punkty końcowe usługi Batch działają w klastrach obliczeniowych i obsługują zarówno klastry obliczeniowe usługi Azure Machine Edukacja (AmlCompute) jak i klastry Kubernetes. Klastry są zasobem udostępnionym, dlatego jeden klaster może hostować jedno lub wiele wdrożeń wsadowych (wraz z innymi obciążeniami, jeśli jest to konieczne).
Utwórz obliczenia o nazwie batch-cluster, jak pokazano w poniższym kodzie. Możesz dostosować je zgodnie z potrzebami i odwołać się do zasobów obliczeniowych przy użyciu polecenia azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Uwaga
W tym momencie nie są naliczane opłaty za obliczenia, ponieważ klaster pozostaje w 0 węzłach do momentu wywołania punktu końcowego wsadowego i przesłania zadania oceniania wsadowego. Aby uzyskać więcej informacji na temat kosztów obliczeń, zobacz Zarządzanie kosztami i optymalizowanie kosztów dla usługi AmlCompute.
Tworzenie punktu końcowego wsadowego
Punkt końcowy wsadowy to punkt końcowy HTTPS, który klienci mogą wywoływać w celu wyzwolenia zadania oceniania wsadowego. Zadanie oceniania wsadowego to zadanie , które ocenia wiele danych wejściowych. Wdrożenie wsadowe to zestaw zasobów obliczeniowych hostujących model, który wykonuje rzeczywiste ocenianie wsadowe (lub wnioskowanie wsadowe). Jeden punkt końcowy wsadowy może mieć wiele wdrożeń wsadowych. Aby uzyskać więcej informacji na temat punktów końcowych wsadowych, zobacz Co to są punkty końcowe wsadowe?.
Napiwek
Jedno z wdrożeń wsadowych służy jako domyślne wdrożenie punktu końcowego. Po wywołaniu punktu końcowego domyślne wdrożenie wykonuje rzeczywiste ocenianie wsadowe. Aby uzyskać więcej informacji na temat punktów końcowych i wdrożeń wsadowych, zobacz batch endpoints and batch deployment (Punkty końcowe wsadowe i wdrażanie wsadowe).
Nadaj punktowi końcowego nazwę. Nazwa punktu końcowego musi być unikatowa w regionie świadczenia usługi Azure, ponieważ nazwa jest uwzględniona w identyfikatorze URI punktu końcowego. Na przykład może istnieć tylko jeden punkt końcowy wsadowy o nazwie
mybatchendpointw plikuwestus2.Umieść nazwę punktu końcowego w zmiennej, aby można było łatwo odwoływać się do niej później.
ENDPOINT_NAME="mnist-batch"Konfigurowanie punktu końcowego wsadowego
Poniższy plik YAML definiuje punkt końcowy wsadowy. Tego pliku można użyć z poleceniem interfejsu wiersza polecenia na potrzeby tworzenia punktu końcowego wsadowego.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningW poniższej tabeli opisano kluczowe właściwości punktu końcowego. Aby uzyskać pełny schemat YAML punktu końcowego wsadowego, zobacz Schemat YAML punktu końcowego wsadowego interfejsu wiersza polecenia (wersja 2).
Key opis nameNazwa punktu końcowego partii. Musi być unikatowa na poziomie regionu świadczenia usługi Azure. descriptionOpis punktu końcowego wsadowego. Ta właściwość jest opcjonalna. tagsTagi do uwzględnienia w punkcie końcowym. Ta właściwość jest opcjonalna. Utwórz punkt końcowy:
Uruchom następujący kod, aby utworzyć punkt końcowy wsadowy.
az ml batch-endpoint create --file endpoint.yml --name $ENDPOINT_NAME
Tworzenie wdrożenia wsadowego
Wdrożenie modelu to zestaw zasobów wymaganych do hostowania modelu, który wykonuje rzeczywiste wnioskowanie. Do utworzenia wdrożenia modelu wsadowego potrzebne są następujące elementy:
- Zarejestrowany model w obszarze roboczym
- Kod oceniania modelu
- Środowisko z zainstalowanymi zależnościami modelu
- Wstępnie utworzone ustawienia zasobów i zasobów obliczeniowych
Zacznij od zarejestrowania modelu, który ma zostać wdrożony — modelu Torch dla popularnego problemu z rozpoznawaniem cyfr (MNIST). Wdrożenia usługi Batch mogą wdrażać tylko modele zarejestrowane w obszarze roboczym. Ten krok można pominąć, jeśli model, który chcesz wdrożyć, jest już zarejestrowany.
Napiwek
Modele są skojarzone z wdrożeniem, a nie z punktem końcowym. Oznacza to, że pojedynczy punkt końcowy może obsługiwać różne modele (lub wersje modelu) w ramach tego samego punktu końcowego, pod warunkiem, że różne modele (lub wersje modelu) są wdrażane w różnych wdrożeniach.
MODEL_NAME='mnist-classifier-torch' az ml model create --name $MODEL_NAME --type "custom_model" --path "deployment-torch/model"Teraz nadszedł czas, aby utworzyć skrypt oceniania. Wdrożenia wsadowe wymagają skryptu oceniania wskazującego sposób wykonywania danego modelu i sposób przetwarzania danych wejściowych. Punkty końcowe usługi Batch obsługują skrypty utworzone w języku Python. W tym przypadku wdrożysz model, który odczytuje pliki obrazów reprezentujące cyfry i dane wyjściowe odpowiadającej mu cyfry. Skrypt oceniania wygląda następująco:
Uwaga
W przypadku modeli MLflow usługa Azure Machine Edukacja automatycznie generuje skrypt oceniania, więc nie musisz go podawać. Jeśli model jest modelem MLflow, możesz pominąć ten krok. Aby uzyskać więcej informacji na temat sposobu pracy punktów końcowych wsadowych z modelami MLflow, zobacz artykuł Using MLflow models in batch deployments (Używanie modeli MLflow we wdrożeniach wsadowych).
Ostrzeżenie
Jeśli wdrażasz model zautomatyzowanego uczenia maszynowego (AutoML) w punkcie końcowym wsadowym, pamiętaj, że skrypt oceniania, który zapewnia rozwiązanie AutoML, działa tylko dla punktów końcowych online i nie jest przeznaczony do wykonywania wsadowego. Aby uzyskać informacje na temat tworzenia skryptu oceniania dla wdrożenia wsadowego, zobacz Tworzenie skryptów oceniania dla wdrożeń wsadowych.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Utwórz środowisko, w którym zostanie uruchomione wdrożenie wsadowe. Środowisko powinno zawierać pakiety
azureml-coreiazureml-dataset-runtime[fuse], które są wymagane przez punkty końcowe wsadowe, a także wszelkie zależności wymagane przez kod do uruchomienia. W takim przypadku zależności zostały przechwycone wconda.yamlpliku:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Ważne
Pakiety
azureml-coreiazureml-dataset-runtime[fuse]są wymagane przez wdrożenia wsadowe i powinny być uwzględnione w zależnościach środowiska.Określ środowisko w następujący sposób:
Definicja środowiska zostanie uwzględniona w definicji wdrożenia jako środowisko anonimowe. W ramach wdrożenia zobaczysz następujące wiersze:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlOstrzeżenie
Nadzorowane środowiska nie są obsługiwane we wdrożeniach wsadowych. Musisz określić własne środowisko. W celu uproszczenia procesu zawsze można użyć obrazu podstawowego środowiska wyselekcjonowanego.
Tworzenie definicji wdrożenia
torch/deployment.yml wdrożenia
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoW poniższej tabeli opisano kluczowe właściwości wdrożenia wsadowego. Aby zapoznać się ze schematem YAML pełnego wdrożenia wsadowego, zobacz Schemat YAML wdrożenia wsadowego (CLI, v2).
Key opis nameNazwa wdrożenia. endpoint_nameNazwa punktu końcowego do utworzenia wdrożenia w obszarze. modelModel, który ma być używany do oceniania wsadowego. W przykładzie zdefiniowano wbudowany model przy użyciu polecenia path. Ta definicja umożliwia automatyczne przekazywanie i zarejestrowanie plików modelu przy użyciu automatycznie wygenerowanej nazwy i wersji. Aby uzyskać więcej opcji, zobacz schemat modelu. Najlepszym rozwiązaniem dla scenariuszy produkcyjnych jest utworzenie modelu oddzielnie i odwołanie do niego w tym miejscu. Aby odwołać się do istniejącego modelu, użyjazureml:<model-name>:<model-version>składni .code_configuration.codeKatalog lokalny zawierający cały kod źródłowy języka Python do oceny modelu. code_configuration.scoring_scriptPlik języka Python w code_configuration.codekatalogu . Ten plik musi miećinit()funkcję irun()funkcję.init()Użyj funkcji dla każdego kosztownego lub wspólnego przygotowania (na przykład do załadowania modelu w pamięci).init()zostanie wywołana tylko raz na początku procesu. Służyrun(mini_batch)do oceniania każdego wpisu; wartośćmini_batchjest listą ścieżek plików. Funkcjarun()powinna zwrócić ramkę danych biblioteki pandas lub tablicę. Każdy zwrócony element wskazuje jeden pomyślny przebieg elementu wejściowego w elemeciemini_batch. Aby uzyskać więcej informacji na temat tworzenia skryptu oceniania, zobacz Opis skryptu oceniania.environmentŚrodowisko do oceny modelu. W przykładzie zdefiniowano wbudowane środowisko przy użyciu elementów conda_fileiimage. Zależnościconda_filezostaną zainstalowane na podstawie .imageŚrodowisko zostanie automatycznie zarejestrowane przy użyciu automatycznie wygenerowanej nazwy i wersji. Aby uzyskać więcej opcji, zobacz Schemat środowiska. Najlepszym rozwiązaniem dla scenariuszy produkcyjnych jest utworzenie środowiska oddzielnie i odwołanie do niego w tym miejscu. Aby odwołać się do istniejącego środowiska, użyjazureml:<environment-name>:<environment-version>składni .computeObliczenia do uruchamiania oceniania wsadowego. W przykładzie użyto utworzonego batch-clusterna początku elementu i odwołuje się do niego przy użyciuazureml:<compute-name>składni .resources.instance_countLiczba wystąpień, które mają być używane dla każdego zadania oceniania wsadowego. settings.max_concurrency_per_instance[Opcjonalnie] Maksymalna liczba przebiegów równoległych scoring_scriptna wystąpienie.settings.mini_batch_size[Opcjonalnie] Liczba plików, które scoring_scriptmogą przetwarzać w jednymrun()wywołaniu.settings.output_action[Opcjonalnie] Sposób organizowania danych wyjściowych w pliku wyjściowym. append_rowScali wszystkierun()zwrócone wyniki wyjściowe w jeden plik o nazwieoutput_file_name.summary_onlynie scali wyników wyjściowych i obliczy tylkoerror_thresholdwartość .settings.output_file_name[Opcjonalnie] Nazwa pliku wyjściowego oceniania wsadowego dla . append_rowoutput_actionsettings.retry_settings.max_retries[Opcjonalnie] Liczba prób maksymalnej liczby nieudanych scoring_scriptrun()prób.settings.retry_settings.timeout[Opcjonalnie] Limit czasu w sekundach dla oceny scoring_scriptrun()minisadowej.settings.error_threshold[Opcjonalnie] Liczba błędów oceniania pliku wejściowego, które powinny być ignorowane. Jeśli liczba błędów dla całego danych wejściowych przekroczy tę wartość, zadanie oceniania wsadowego zostanie zakończone. W przykładzie użyto -1metody , która wskazuje, że dowolna liczba niepowodzeń jest dozwolona bez kończenia zadania oceniania wsadowego.settings.logging_level[Opcjonalnie] Czasownik dziennika. Wartości zwiększające szczegółowość to: OSTRZEŻENIE, INFORMACJE i DEBUGOWANIE. settings.environment_variables[Opcjonalnie] Słownik par nazwa-wartość zmiennej środowiskowej do ustawienia dla każdego zadania oceniania wsadowego. Utwórz wdrożenie:
Uruchom następujący kod, aby utworzyć wdrożenie wsadowe w punkcie końcowym wsadowym i ustawić je jako domyślne wdrożenie.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultNapiwek
Parametr
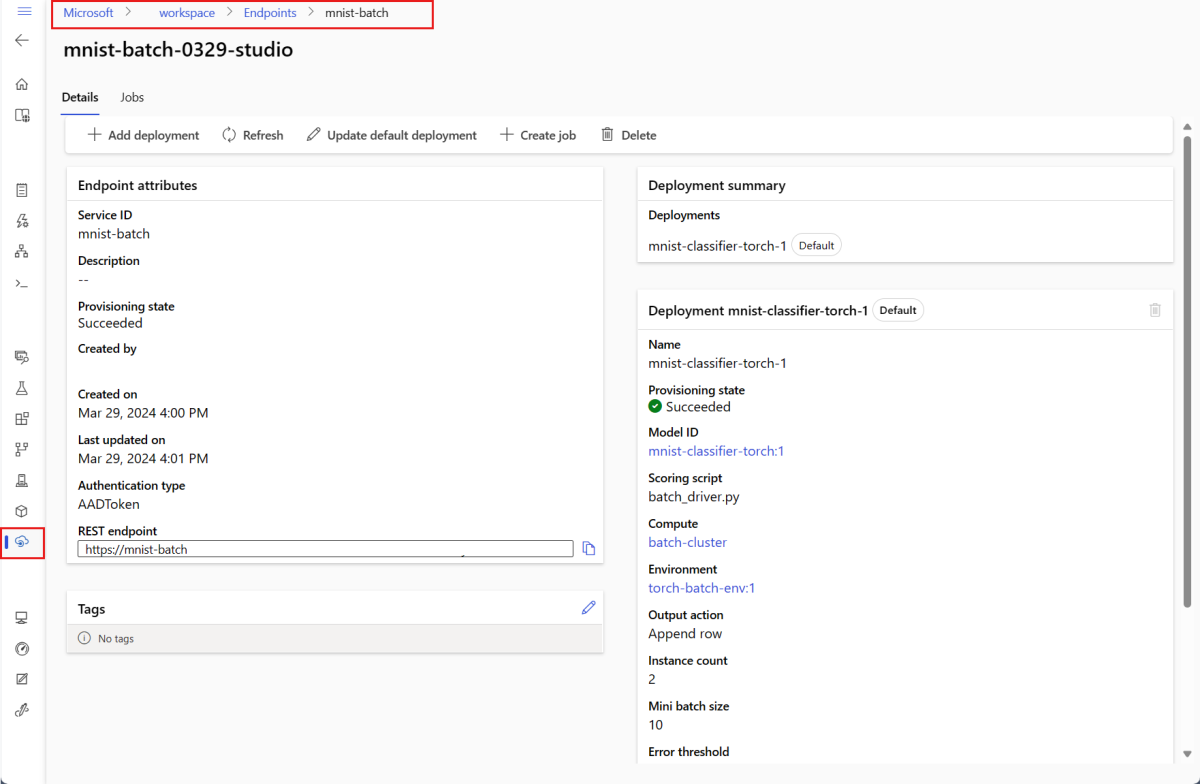
--set-defaultustawia nowo utworzone wdrożenie jako domyślne wdrożenie punktu końcowego. Jest to wygodny sposób tworzenia nowego domyślnego wdrożenia punktu końcowego, szczególnie w przypadku pierwszego utworzenia wdrożenia. Najlepszym rozwiązaniem dla scenariuszy produkcyjnych może być utworzenie nowego wdrożenia bez ustawiania go jako domyślnego. Sprawdź, czy wdrożenie działa zgodnie z oczekiwaniami, a następnie zaktualizuj domyślne wdrożenie później. Aby uzyskać więcej informacji na temat implementowania tego procesu, zobacz sekcję Wdrażanie nowego modelu .Sprawdź szczegóły punktu końcowego i wdrożenia wsadowego.
Użyj polecenia
show, aby sprawdzić szczegóły punktu końcowego i wdrożenia. Aby sprawdzić wdrożenie wsadowe, uruchom następujący kod:DEPLOYMENT_NAME="mnist-torch-dpl" az ml batch-deployment show --name $DEPLOYMENT_NAME --endpoint-name $ENDPOINT_NAME

Uruchamianie punktów końcowych wsadowych i uzyskiwanie dostępu do wyników
Wywoływanie punktu końcowego wsadowego wyzwala zadanie oceniania wsadowego. Zadanie name jest zwracane z odpowiedzi wywołania i może służyć do śledzenia postępu oceniania wsadowego. Podczas uruchamiania modeli oceniania w punktach końcowych wsadowych należy określić ścieżkę do danych wejściowych, aby punkty końcowe mogły znaleźć dane, które chcesz ocenić. W poniższym przykładzie pokazano, jak uruchomić nowe zadanie względem przykładowych danych zestawu danych MNIST przechowywanego na koncie usługi Azure Storage.
Punkt końcowy usługi Batch można uruchomić i wywołać przy użyciu interfejsu wiersza polecenia platformy Azure, zestawu SDK usługi Azure Machine Edukacja lub punktów końcowych REST. Aby uzyskać więcej informacji na temat tych opcji, zobacz Tworzenie zadań i danych wejściowych dla punktów końcowych wsadowych.
Uwaga
Jak działa równoległe przetwarzanie?
Wdrożenia wsadowe dystrybuują pracę na poziomie pliku, co oznacza, że folder zawierający 100 plików z minisadami 10 plików spowoduje wygenerowanie 10 partii 10 plików. Zwróć uwagę, że dzieje się tak niezależnie od rozmiaru zaangażowanych plików. Jeśli pliki są zbyt duże do przetworzenia w dużych minisadach, sugerujemy podzielenie plików na mniejsze pliki w celu osiągnięcia wyższego poziomu równoległości lub zmniejszenie liczby plików na minisadę. Obecnie wdrożenia wsadowe nie mogą uwzględniać niesymetryczności w dystrybucji rozmiaru pliku.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Punkty końcowe usługi Batch obsługują odczytywanie plików lub folderów znajdujących się w różnych lokalizacjach. Aby dowiedzieć się więcej o obsługiwanych typach i sposobach ich określania, zobacz Uzyskiwanie dostępu do danych z zadań punktów końcowych wsadowych.
Monitorowanie postępu wykonywania zadania wsadowego
Zadania oceniania wsadowego zwykle zajmują trochę czasu, aby przetworzyć cały zestaw danych wejściowych.
Poniższy kod sprawdza stan zadania i generuje link do programu Azure Machine Edukacja Studio, aby uzyskać więcej szczegółów.
az ml job show -n $JOB_NAME --web

Sprawdzanie wyników oceniania wsadowego
Dane wyjściowe zadania są przechowywane w magazynie w chmurze w domyślnym magazynie obiektów blob obszaru roboczego lub określonym magazynie. Aby dowiedzieć się, jak zmienić ustawienia domyślne, zobacz Konfigurowanie lokalizacji wyjściowej. Poniższe kroki umożliwiają wyświetlenie wyników oceniania w Eksplorator usługi Azure Storage po zakończeniu zadania:
Uruchom następujący kod, aby otworzyć zadanie oceniania wsadowego w usłudze Azure Machine Edukacja Studio. Link do programu Job Studio jest również uwzględniony w odpowiedzi elementu
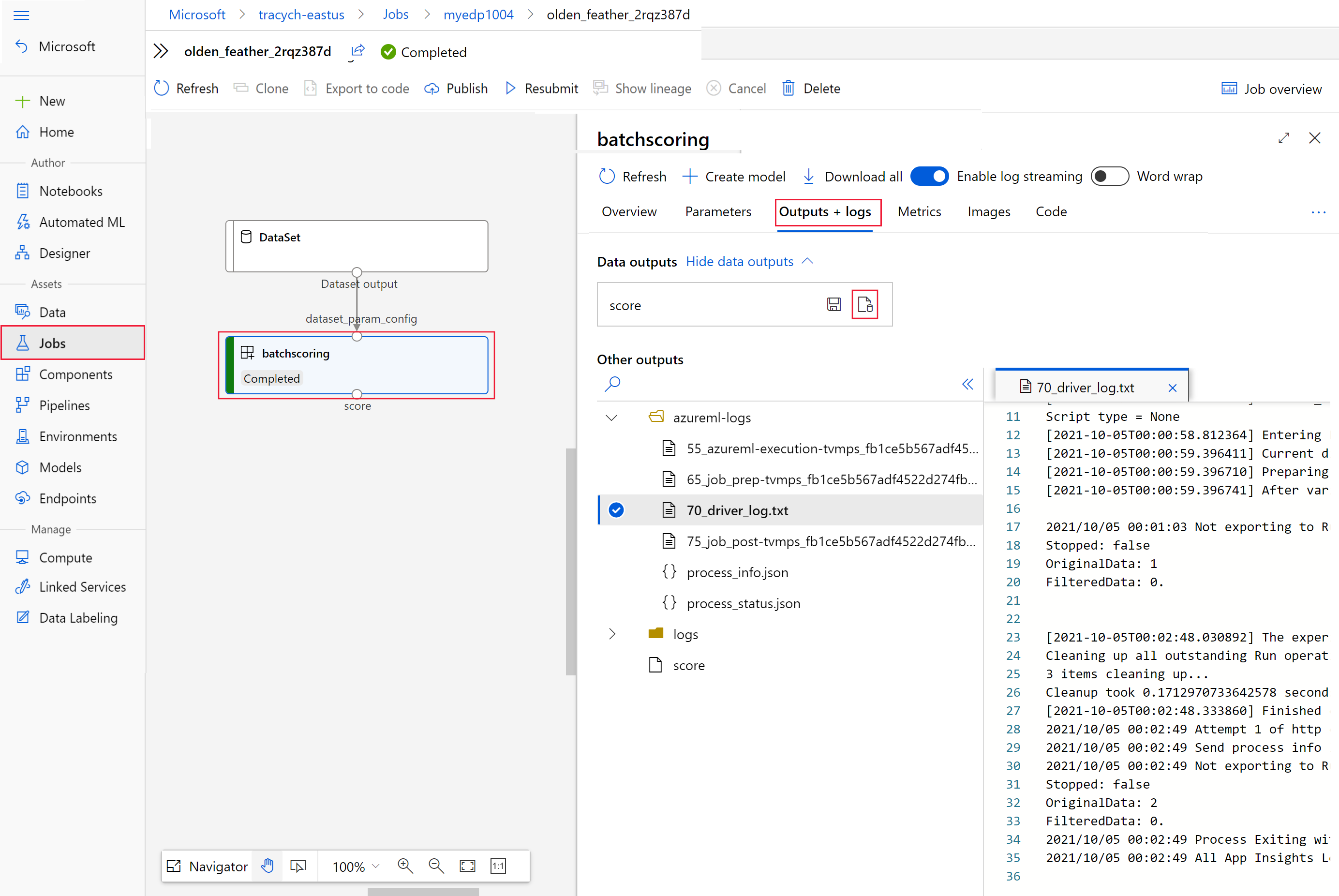
invoke, jako wartośćinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webNa wykresie zadania wybierz
batchscoringkrok.Wybierz kartę Dane wyjściowe i dzienniki , a następnie wybierz pozycję Pokaż dane wyjściowe.
W obszarze Dane wyjściowe wybierz ikonę, aby otworzyć Eksplorator usługi Storage.
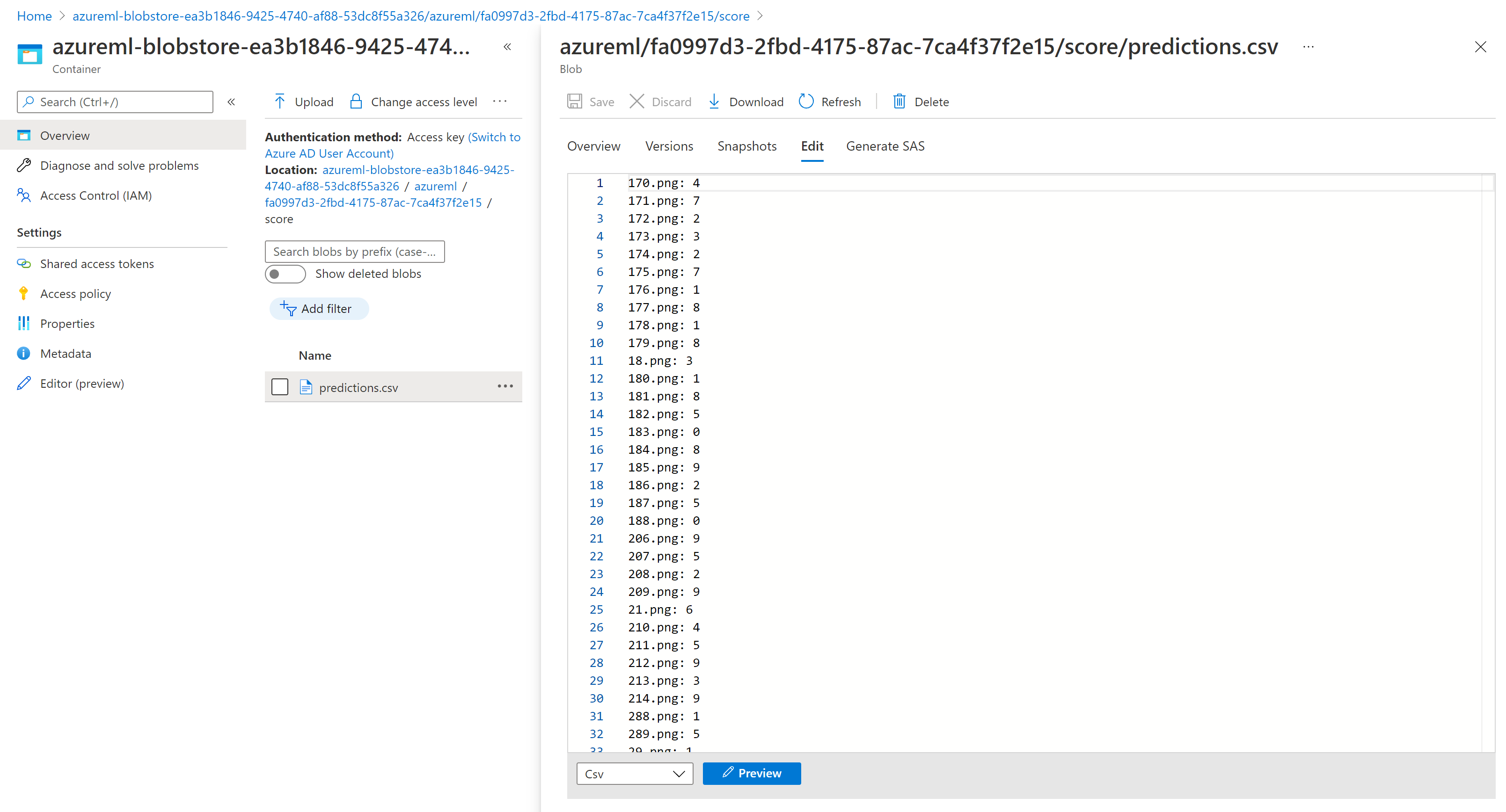
Wyniki oceniania w Eksplorator usługi Storage są podobne do następującej przykładowej strony:


Konfigurowanie lokalizacji wyjściowej
Domyślnie wyniki oceniania wsadowego są przechowywane w domyślnym magazynie obiektów blob obszaru roboczego w folderze o nazwie według nazwy zadania (identyfikator GUID generowany przez system). Możesz skonfigurować miejsce przechowywania danych wyjściowych oceniania podczas wywoływania punktu końcowego wsadowego.
Służy output-path do konfigurowania dowolnego folderu w zarejestrowanym magazynie danych w usłudze Azure Machine Edukacja. Składnia elementu --output-path jest taka sama jak --input w przypadku określania folderu , azureml://datastores/<datastore-name>/paths/<path-on-datastore>/czyli . Użyj --set output_file_name=<your-file-name> polecenia , aby skonfigurować nową nazwę pliku wyjściowego.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Ostrzeżenie
Musisz użyć unikatowej lokalizacji wyjściowej. Jeśli plik wyjściowy istnieje, zadanie oceniania wsadowego zakończy się niepowodzeniem.
Ważne
W przeciwieństwie do danych wejściowych dane wyjściowe mogą być przechowywane tylko w usłudze Azure Machine Edukacja magazynach danych uruchamianych na kontach usługi Blob Storage.
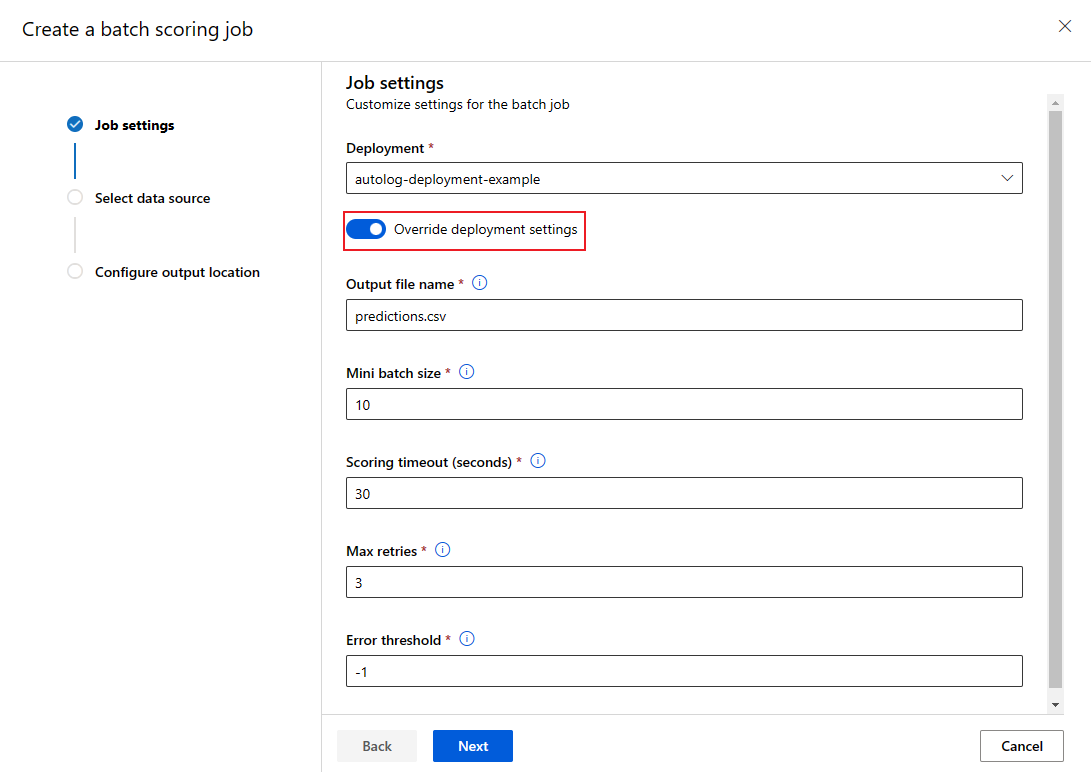
Zastępowanie konfiguracji wdrożenia dla każdego zadania
Podczas wywoływania punktu końcowego wsadowego niektóre ustawienia można zastąpić, aby jak najlepiej wykorzystać zasoby obliczeniowe i zwiększyć wydajność. Następujące ustawienia można skonfigurować dla poszczególnych zadań:
- Liczba wystąpień: użyj tego ustawienia, aby zastąpić liczbę wystąpień do żądania z klastra obliczeniowego. Na przykład w przypadku większej ilości danych wejściowych możesz użyć większej liczby wystąpień, aby przyspieszyć zakończenie oceniania wsadowego.
- Rozmiar minisadów: użyj tego ustawienia, aby zastąpić liczbę plików do uwzględnienia w każdej minisadowej partii. Liczba minisadów jest określana przez łączną liczbę plików wejściowych i rozmiar mini-partii. Mniejszy rozmiar mini-partii generuje więcej minisadów. Minisady mogą być uruchamiane równolegle, ale mogą istnieć dodatkowe obciążenia związane z planowaniem i wywołaniem.
- Inne ustawienia, takie jak maksymalna liczba ponownych prób, przekroczenie limitu czasu i próg błędu, można zastąpić. Te ustawienia mogą mieć wpływ na pełny czas oceniania wsadowego dla różnych obciążeń.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Dodawanie wdrożeń do punktu końcowego
Po utworzeniu punktu końcowego wsadowego z wdrożeniem możesz nadal uściślić model i dodawać nowe wdrożenia. Punkty końcowe usługi Batch będą nadal obsługiwać wdrożenie domyślne podczas tworzenia i wdrażania nowych modeli w ramach tego samego punktu końcowego. Wdrożenia nie mają wpływu na siebie.
W tym przykładzie dodasz drugie wdrożenie korzystające z modelu utworzonego za pomocą interfejsu Keras i TensorFlow w celu rozwiązania tego samego problemu MNIST.
Dodawanie drugiego wdrożenia
Utwórz środowisko, w którym zostanie uruchomione wdrożenie wsadowe. Uwzględnij w środowisku dowolną zależność wymaganą przez kod do uruchomienia. Należy również dodać bibliotekę
azureml-core, ponieważ jest ona wymagana do pracy wdrożeń wsadowych. Poniższa definicja środowiska zawiera biblioteki wymagane do uruchomienia modelu za pomocą bibliotek TensorFlow.Definicja środowiska jest uwzględniana w samej definicji wdrożenia jako środowisko anonimowe.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlUżyty plik conda wygląda następująco:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Utwórz skrypt oceniania dla modelu:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Tworzenie definicji wdrożenia
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvUtwórz wdrożenie:
Uruchom następujący kod, aby utworzyć wdrożenie wsadowe w punkcie końcowym wsadowym i ustawić je jako domyślne wdrożenie.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMENapiwek
Brak parametru
--set-defaultw tym przypadku. Najlepszym rozwiązaniem dla scenariuszy produkcyjnych jest utworzenie nowego wdrożenia bez ustawiania go jako domyślnego. Następnie zweryfikuj je i zaktualizuj wdrożenie domyślne później.
Testowanie wdrożenia wsadowego innego niż domyślne
Aby przetestować nowe wdrożenie inne niż domyślne, musisz znać nazwę wdrożenia, które chcesz uruchomić.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Powiadomienie --deployment-name służy do określania wdrożenia do wykonania. Ten parametr umożliwia invoke wdrożenie inne niż domyślne bez aktualizowania domyślnego wdrożenia punktu końcowego wsadowego.
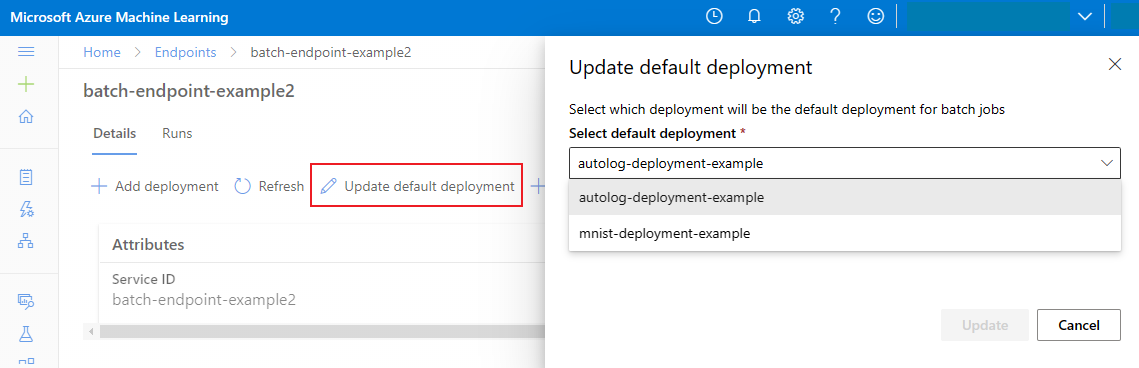
Aktualizowanie domyślnego wdrożenia wsadowego
Chociaż można wywołać określone wdrożenie wewnątrz punktu końcowego, zazwyczaj należy wywołać sam punkt końcowy i pozwolić punktowi końcowemu zdecydować, którego wdrożenia użyć — domyślne wdrożenie. Możesz zmienić domyślne wdrożenie (a w związku z tym zmienić model obsługujący wdrożenie) bez zmiany umowy z użytkownikiem wywołującym punkt końcowy. Użyj następującego kodu, aby zaktualizować wdrożenie domyślne:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Usuwanie punktu końcowego wsadowego i wdrożenia
Jeśli nie będziesz używać starego wdrożenia wsadowego, usuń je, uruchamiając następujący kod. --yes służy do potwierdzania usunięcia.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Uruchom następujący kod, aby usunąć punkt końcowy wsadowy i wszystkie jego podstawowe wdrożenia. Zadania oceniania wsadowego nie zostaną usunięte.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes