Samouczek języka C#: generowanie zawartości z możliwością wyszukiwania w usłudze Azure AI Search przy użyciu zestawów umiejętności
Z tego samouczka dowiesz się, jak używać zestawu Azure SDK dla platformy .NET do tworzenia potoku wzbogacania sztucznej inteligencji na potrzeby wyodrębniania i przekształcania zawartości podczas indeksowania.
Zestawy umiejętności dodają przetwarzanie sztucznej inteligencji do nieprzetworzonej zawartości, dzięki czemu zawartość będzie bardziej jednolita i będzie można wyszukiwać. Gdy już wiesz, jak działają zestawy umiejętności, możesz obsługiwać szeroką gamę przekształceń: od analizy obrazów po przetwarzanie języka naturalnego w celu dostosowania przetwarzania, które udostępniasz zewnętrznie.
Ten samouczek ułatwia zapoznanie się z następującymi instrukcjami:
- Zdefiniuj obiekty w potoku wzbogacania.
- Tworzenie zestawu umiejętności. Wywołaj rozpoznawanie znaków OCR, wykrywanie języka, rozpoznawanie jednostek i wyodrębnianie kluczowych fraz.
- Wykonaj potok. Tworzenie i ładowanie indeksu wyszukiwania.
- Sprawdź wyniki przy użyciu wyszukiwania pełnotekstowego.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem otwórz bezpłatne konto .
Omówienie
W tym samouczku użyto języka C# i biblioteki klienta Azure.Search.Documents do utworzenia źródła danych, indeksu, indeksatora i zestawu umiejętności.
Indeksator napędza każdy krok w potoku, począwszy od wyodrębniania zawartości przykładowych danych (tekstu bez struktury i obrazów) w kontenerze obiektów blob w usłudze Azure Storage.
Po wyodrębnieniu zawartości zestaw umiejętności wykonuje wbudowane umiejętności od firmy Microsoft, aby znaleźć i wyodrębnić informacje. Te umiejętności obejmują optyczne rozpoznawanie znaków (OCR) na obrazach, wykrywanie języka tekstu, wyodrębnianie kluczowych fraz i rozpoznawanie jednostek (organizacje). Nowe informacje utworzone przez zestaw umiejętności są wysyłane do pól w indeksie. Po wypełnieniu indeksu można użyć pól w zapytaniach, aspektach i filtrach.
Wymagania wstępne
Uwaga
W tym samouczku możesz użyć bezpłatnej usługi wyszukiwania. Warstwa Bezpłatna ogranicza do trzech indeksów, trzech indeksatorów i trzech źródeł danych. W ramach tego samouczka tworzony jest jeden element każdego z tych typów. Przed rozpoczęciem upewnij się, że masz pokój w usłudze, aby zaakceptować nowe zasoby.
Pobieranie plików
Pobierz plik zip z przykładowego repozytorium danych i wyodrębnij zawartość. Dowiedz się, jak to zrobić.
Przekazywanie przykładowych danych do usługi Azure Storage
W usłudze Azure Storage utwórz nowy kontener i nadaj mu nazwę cog-search-demo.
Przekaż przykładowe pliki danych.
Uzyskaj parametry połączenia magazynu, aby można było sformułować połączenie w usłudze Azure AI Search.
Po lewej stronie wybierz pozycję Klucze dostępu.
Skopiuj parametry połączenia dla jednego lub drugiego klucza. Parametry połączenia jest podobny do następującego przykładu:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Usługi platformy Azure AI
Wbudowane wzbogacanie sztucznej inteligencji jest wspierane przez usługi Azure AI, w tym usługę językową i usługę Azure AI Vision na potrzeby przetwarzania języka naturalnego i obrazów. W przypadku małych obciążeń, takich jak w tym samouczku, możesz użyć bezpłatnej alokacji 20 transakcji na indeksator. W przypadku większych obciążeń dołącz zasób usługi Azure AI Services w wielu regionach do zestawu umiejętności dla cennika z płatnością zgodnie z rzeczywistym użyciem.
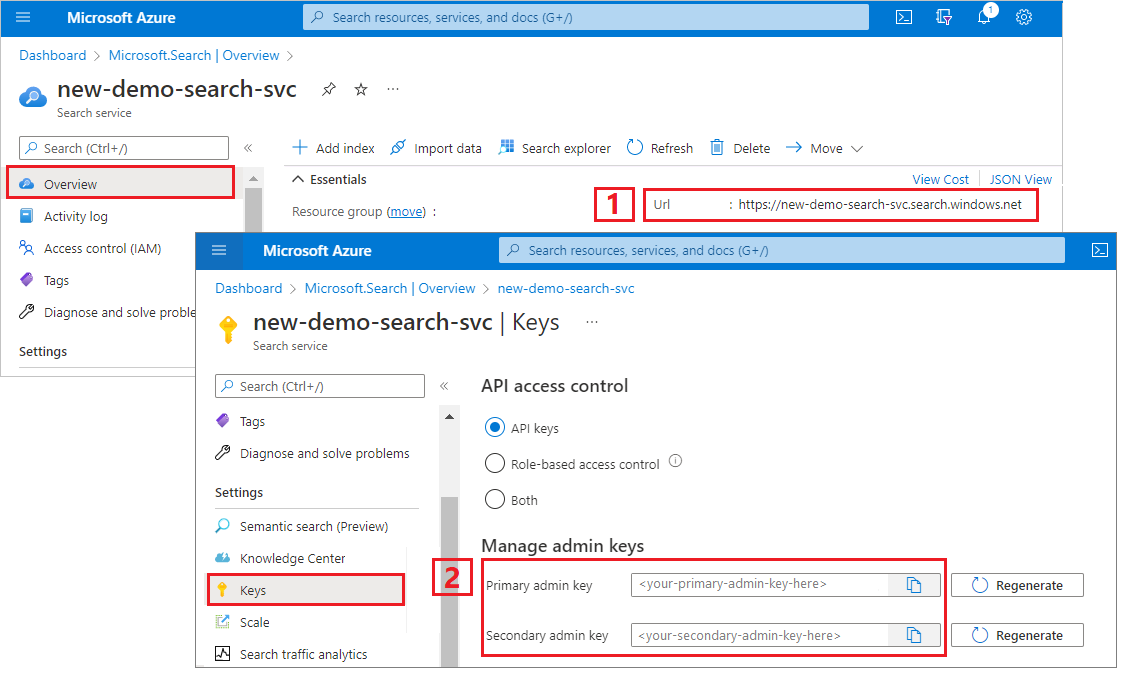
Kopiowanie adresu URL usługi wyszukiwania i klucza interfejsu API
Na potrzeby tego samouczka połączenia z usługą Azure AI Search wymagają punktu końcowego i klucza interfejsu API. Te wartości można uzyskać w witrynie Azure Portal.
Zaloguj się do witryny Azure Portal, przejdź do strony Przegląd usługi wyszukiwania i skopiuj adres URL. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Ustawienia> Keys skopiuj klucz administratora. Administracja klucze służą do dodawania, modyfikowania i usuwania obiektów. Istnieją dwa zamienne klucze administratora. Skopiuj jedną z nich.
Konfigurowanie środowiska
Zacznij od otwarcia programu Visual Studio i utworzenia nowego projektu aplikacji konsolowej, który można uruchomić na platformie .NET Core.
Instalowanie pliku Azure.Search.Documents
Zestaw .NET SDK usługi Azure AI Search składa się z biblioteki klienta, która umożliwia zarządzanie indeksami, źródłami danych, indeksatorami i zestawami umiejętności, a także przekazywanie dokumentów i wykonywanie zapytań oraz zarządzanie nimi bez konieczności obsługi szczegółów protokołu HTTP i JSON. Ta biblioteka klienta jest dystrybuowana jako pakiet NuGet.
W tym projekcie zainstaluj wersję 11 lub nowszą Azure.Search.Documents i najnowszą wersję programu Microsoft.Extensions.Configuration.
W programie Visual Studio wybierz pozycję Narzędzia>NuGet Menedżer pakietów> Zarządzaj pakietami NuGet dla rozwiązania...
Wyszukaj ciąg Azure.Search.Document.
Wybierz najnowszą wersję, a następnie wybierz pozycję Zainstaluj.
Powtórz poprzednie kroki, aby zainstalować plik Microsoft.Extensions.Configuration i Microsoft.Extensions.Configuration.Json.
Dodawanie informacji o połączeniu z usługą
Kliknij prawym przyciskiem myszy projekt w Eksplorator rozwiązań i wybierz polecenie Dodaj>nowy element... .
Nadaj plikowi
appsettings.jsonnazwę i wybierz pozycję Dodaj.Dołącz ten plik do katalogu wyjściowego.
- Kliknij prawym przyciskiem myszy
appsettings.jsoni wybierz polecenie Właściwości. - Zmień wartość Copy to Output Directory (Kopiuj do katalogu wyjściowego), aby skopiować wartość , jeśli jest nowsza.
- Kliknij prawym przyciskiem myszy
Skopiuj poniższy kod JSON do nowego pliku JSON.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Dodaj informacje o usłudze wyszukiwania i koncie magazynu obiektów blob. Pamiętaj, że te informacje można uzyskać z kroków aprowizacji usług wskazanych w poprzedniej sekcji.
W polu SearchServiceUri wprowadź pełny adres URL.
Dodawanie przestrzeni nazw
W Program.cspliku dodaj następujące przestrzenie nazw.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Tworzenie klienta
Utwórz wystąpienie obiektu SearchIndexClient i w SearchIndexerClient obszarze Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Uwaga
Klienci łączą się z usługą wyszukiwania. Aby uniknąć otwierania zbyt wielu połączeń, należy spróbować udostępnić pojedyncze wystąpienie w aplikacji, jeśli to możliwe. Metody są bezpieczne wątkowo, aby umożliwić takie udostępnianie.
Dodawanie funkcji w celu zakończenia programu podczas awarii
Ten samouczek ułatwia zrozumienie każdego kroku potoku indeksowania. Jeśli występuje krytyczny problem uniemożliwiający programowi utworzenie źródła danych, zestawu umiejętności, indeksu lub indeksatora, program wyświetli komunikat o błędzie i zakończy działanie, aby można było zrozumieć i rozwiązać problem.
Dodaj ExitProgram element do obsługi Main scenariuszy, które wymagają zakończenia działania programu.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Tworzenie potoku
W usłudze Azure AI Search przetwarzanie sztucznej inteligencji odbywa się podczas indeksowania (lub pozyskiwania danych). Ta część przewodnika tworzy cztery obiekty: źródło danych, definicję indeksu, zestaw umiejętności, indeksator.
Krok 1. Tworzenie źródła danych
SearchIndexerClientDataSourceName ma właściwość, którą można ustawić na SearchIndexerDataSourceConnection obiekt. Ten obiekt udostępnia wszystkie metody, które należy utworzyć, wyświetlić, zaktualizować lub usunąć źródła danych usługi Azure AI Search.
Utwórz nowe SearchIndexerDataSourceConnection wystąpienie, wywołując polecenie indexerClient.CreateOrUpdateDataSourceConnection(dataSource). Poniższy kod tworzy źródło danych typu AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
W przypadku pomyślnego żądania metoda zwraca utworzone źródło danych. Jeśli występuje problem z żądaniem, taki jak nieprawidłowy parametr, metoda zgłasza wyjątek.
Teraz dodaj wiersz , Main aby wywołać CreateOrUpdateDataSource właśnie dodaną funkcję.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Skompiluj i uruchom rozwiązanie. Ponieważ jest to pierwsze żądanie, sprawdź witrynę Azure Portal, aby potwierdzić, że źródło danych zostało utworzone w usłudze Azure AI Search. Na stronie przeglądu usługi wyszukiwania sprawdź, czy lista Źródła danych zawiera nowy element. Może trzeba będzie zaczekać kilka minut na odświeżenie strony portalu.

Krok 2. Tworzenie zestawu umiejętności
W tej sekcji zdefiniujesz zestaw kroków wzbogacania, które chcesz zastosować do danych. Każdy krok wzbogacania jest nazywany umiejętnością i zestawem kroków wzbogacania, zestawu umiejętności. W tym samouczku są używane wbudowane umiejętności dla zestawu umiejętności :
Optyczne rozpoznawanie znaków w celu rozpoznawania tekstu drukowanego i odręcznego w plikach obrazów.
Połączenie tekstu w celu skonsolidowania tekstu z kolekcji pól w jedno pole "scalonej zawartości".
Wykrywanie języka — identyfikowanie języka zawartości.
Rozpoznawanie jednostek do wyodrębniania nazw organizacji z zawartości w kontenerze obiektów blob.
Podział tekstu w celu podzielenia dużej zawartości na mniejsze fragmenty przed wywołaniem umiejętności wyodrębniania kluczowych fraz i umiejętności rozpoznawania jednostek. Wyodrębnianie kluczowych fraz i rozpoznawanie jednostek akceptuje dane wejściowe o 50 000 znaków lub mniej. Kilka przykładowych plików należy podzielić, aby zmieścić się w tym limicie.
Wyodrębnianie kluczowych fraz — określanie najczęściej występujących fraz kluczowych.
Podczas początkowego przetwarzania usługa Azure AI Search pęka w każdym dokumencie w celu wyodrębnienia zawartości z różnych formatów plików. Tekst pochodzący z pliku źródłowego jest umieszczany w wygenerowanym content polu , po jednym dla każdego dokumentu. W związku z tym ustaw dane wejściowe tak "/document/content" , aby używały tego tekstu. Zawartość obrazu jest umieszczana w wygenerowanym normalized_images polu określonym w zestawie umiejętności jako /document/normalized_images/*.
Dane wyjściowe można mapować na indeks i/lub używać ich jako danych wejściowych umiejętności podrzędnej — jak w przypadku kodu języka. W indeksie kod języka jest przydatny do filtrowania. Kod języka jest używany jako dane wejściowe przez umiejętności analizy tekstu w celu określenia zasad podziału wyrazów przez reguły językowe.
Aby uzyskać więcej podstawowych informacji na temat zestawów umiejętności, zobacz Jak zdefiniować zestaw umiejętności.
Umiejętność OCR
Element OcrSkill wyodrębnia tekst z obrazów. Ta umiejętność zakłada, że istnieje pole normalized_images. Aby wygenerować to pole, w dalszej części samouczka ustawiliśmy konfigurację "imageAction" w definicji indeksatora na "generateNormalizedImages"wartość .
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Umiejętność scalania
W tej sekcji utworzysz MergeSkill element, który scala pole zawartości dokumentu z tekstem utworzonym przez umiejętności OCR.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Umiejętność wykrywania języka
Funkcja LanguageDetectionSkill wykrywa język tekstu wejściowego i zgłasza pojedynczy kod języka dla każdego dokumentu przesłanego na żądanie. Używamy danych wyjściowych umiejętności wykrywania języka jako części danych wejściowych umiejętności dzielenia tekstu.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Umiejętność dzielenia tekstu
Poniższy SplitSkill tekst dzieli tekst według stron i ogranicza długość strony do 4000 znaków mierzonych przez String.Lengthwartość . Algorytm próbuje podzielić tekst na fragmenty, które mają największy maximumPageLength rozmiar. W tym przypadku algorytm robi wszystko, co w jego mocy, aby przerwać zdanie na granicy zdania, więc rozmiar fragmentu może być nieco mniejszy niż maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Umiejętność rozpoznawania jednostek
To EntityRecognitionSkill wystąpienie ma rozpoznawać typ organizationkategorii . Element EntityRecognitionSkill może również rozpoznawać typy person kategorii i location.
Zwróć uwagę, że pole "kontekst" jest ustawione na "/document/pages/*" gwiazdkę, co oznacza, że krok wzbogacania jest wywoływany dla każdej strony w obszarze "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Umiejętność wyodrębniania kluczowych fraz
EntityRecognitionSkill Podobnie jak wystąpienie, które zostało właśnie utworzone, KeyPhraseExtractionSkill element jest wywoływany dla każdej strony dokumentu.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Tworzenie i tworzenie zestawu umiejętności
SearchIndexerSkillset Tworzenie umiejętności utworzonych przez Ciebie.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Dodaj następujące wiersze do Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Krok 3. Tworzenie indeksu
W tej sekcji zdefiniujesz schemat indeksu przez określenie pól do umieszczenia w indeksie z możliwością wyszukiwania oraz atrybutów wyszukiwania dla każdego pola. Pola mogą mieć typ i atrybuty, które określają sposób używania pola (z możliwością wyszukiwania, sortowania itp.). Nazwy pól w indeksie nie są wymagane do identycznego dopasowania nazw pól w źródle. W kolejnym kroku są dodawane mapowania pól w indeksatorze w celu połączenia pól źródłowych z polami docelowymi. W tym kroku zdefiniuj indeks przy użyciu konwencji nazewnictwa pól właściwej dla aplikacji wyszukiwania.
W tym ćwiczeniu są używane następujące pola i typy pól:
| Nazwy pól | Typy pól |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
Wyświetlanie listy<ciągów Edm.String> |
organizations |
Wyświetlanie listy<ciągów Edm.String> |
Tworzenie klasy DemoIndex
Pola dla tego indeksu są definiowane przy użyciu klasy modelu. Każda właściwość klasy modelu ma atrybuty, które określają zachowania związane z wyszukiwaniem odpowiedniego pola indeksu.
Dodamy klasę modelu do nowego pliku C#. Wybierz prawym przyciskiem myszy projekt i wybierz pozycję Dodaj>nowy element..., wybierz pozycję "Klasa" i nadaj plikowi DemoIndex.csnazwę , a następnie wybierz pozycję Dodaj.
Upewnij się, że chcesz używać typów z Azure.Search.Documents.Indexes przestrzeni nazw i System.Text.Json.Serialization .
Dodaj poniższą definicję klasy modelu i DemoIndex.cs dołącz ją do tej samej przestrzeni nazw, w której tworzysz indeks.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Teraz, po zdefiniowaniu klasy modelu, Program.cs możesz łatwo utworzyć definicję indeksu. Nazwa tego indeksu to demoindex. Jeśli indeks już istnieje o tej nazwie, zostanie usunięty.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Podczas testowania może się okazać, że próbujesz utworzyć indeks więcej niż raz. W związku z tym sprawdź, czy indeks, który chcesz utworzyć, już istnieje przed próbą jego utworzenia.
Dodaj następujące wiersze do Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Dodaj następującą instrukcję using, aby rozwiązać niejednoznaczne odwołanie.
using Index = Azure.Search.Documents.Indexes.Models;
Aby dowiedzieć się więcej na temat pojęć dotyczących indeksu, zobacz Tworzenie indeksu (interfejs API REST).
Krok 4. Tworzenie i uruchamianie indeksatora
Do tej pory utworzono źródło danych, zestaw umiejętności i indeks. Te trzy składniki staną się częścią indeksatora, który łączy wszystkie części w pojedynczą operację obejmującą wiele faz. Aby powiązać je razem w indeksatorze, należy zdefiniować mapowania pól.
PolaMappings są przetwarzane przed zestawem umiejętności mapowanie pól źródłowych ze źródła danych na pola docelowe w indeksie. Jeśli nazwy pól i typy są takie same na obu końcach, żadne mapowanie nie jest wymagane.
Dane wyjścioweFieldMappings są przetwarzane po zestawie umiejętności, odwołując się do parametrów sourceFieldName, które nie istnieją, dopóki nie zostaną utworzone pęknięcie dokumentu lub wzbogacanie. TargetFieldName jest polem w indeksie.
Oprócz podłączania danych wejściowych do danych wyjściowych można również używać mapowań pól do spłaszczania struktur danych. Aby uzyskać więcej informacji, zobacz Jak mapować wzbogacone pola na indeks z możliwością wyszukiwania.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Dodaj następujące wiersze do Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Spodziewaj się, że przetwarzanie indeksatora zajmie trochę czasu. Mimo że zestaw danych jest mały, umiejętności analityczne wykorzystują znaczną moc obliczeniową. Wykonywanie niektórych umiejętności, takich jak analiza obrazu, jest długotrwałe.
Napiwek
Utworzenie indeksatora powoduje wywołanie potoku. Jeśli występują problemy z dostępem do danych, mapowaniem danych wejściowych i wyjściowych lub kolejnością operacji, pojawią się one na tym etapie.
Eksplorowanie tworzenia indeksatora
Kod ustawia "maxFailedItems" wartość -1, co instruuje aparat indeksowania, aby ignorował błędy podczas importowania danych. Jest to przydatne, ponieważ pokazowe źródło danych zawiera tak mało dokumentów. W przypadku większego źródła danych należy ustawić wartość większą od 0.
Zwróć również uwagę, że "dataToExtract" parametr jest ustawiony na "contentAndMetadata"wartość . Ta instrukcja nakazuje indeksatorowi automatyczne wyodrębnianie zawartości z plików w różnych formatach, a także metadanych związanych z każdym plikiem.
Gdy zawartość zostanie wyodrębniona, możesz ustawić element imageAction, aby wyodrębnić tekst z obrazów znalezionych w źródle danych. Zestaw "imageAction" do "generateNormalizedImages" konfiguracji w połączeniu z umiejętnością OCR i umiejętnością scalania tekstu informuje indeksatora o wyodrębnieniu tekstu z obrazów (na przykład słowa "stop" z znaku zatrzymania ruchu) i osadzić go w ramach pola zawartości. To zachowanie dotyczy zarówno obrazów osadzonych w dokumentach (np. w pliku PDF), jak i znalezionych w źródle danych (np. pliku JPG).
Monitorowanie indeksowania
Po zdefiniowaniu indeksatora jest on uruchamiany automatycznie przy przesyłaniu żądania. W zależności od zdefiniowanych umiejętności indeksowanie może trwać dłużej niż oczekiwano. Aby dowiedzieć się, czy indeksator jest nadal uruchomiony, użyj GetStatus metody .
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo reprezentuje bieżący stan i historię wykonywania indeksatora.
Ostrzeżenia są typowe w przypadku niektórych kombinacji plików źródłowych i umiejętności i nie zawsze wskazują problem. W tym samouczku ostrzeżenia są niegroźne (np. brak tekstowych danych wejściowych dla plików JPEG).
Dodaj następujące wiersze do Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Search
W aplikacjach konsoli usługi Azure AI Search zwykle dodajemy 2-sekundowe opóźnienie przed uruchomieniem zapytań, które zwracają wyniki, ale wzbogacanie trwa kilka minut, zamkniemy aplikację konsolową i użyjemy innego podejścia.
Najprostszą opcją jest Eksplorator wyszukiwania w portalu. Najpierw można uruchomić puste zapytanie zwracające wszystkie dokumenty lub bardziej ukierunkowane wyszukiwanie zwracające nową zawartość pola utworzoną przez potok.
W witrynie Azure Portal na stronie Przegląd wyszukiwania wybierz pozycję Indeksy.
Znajdź
demoindexna liście. Powinien zawierać 14 dokumentów. Jeśli liczba dokumentów wynosi zero, indeksator jest nadal uruchomiony lub strona nie została jeszcze odświeżona.Wybierz opcję
demoindex. Eksplorator wyszukiwania to pierwsza karta.Zawartość można przeszukiwać zaraz po załadowaniu pierwszego dokumentu. Aby sprawdzić, czy zawartość istnieje, uruchom nieokreślone zapytanie, klikając pozycję Wyszukaj. To zapytanie zwraca wszystkie aktualnie indeksowane dokumenty, co daje wyobrażenie o tym, co zawiera indeks.
Następnie wklej następujący ciąg, aby uzyskać bardziej możliwe do zarządzania wyniki:
search=*&$select=id, languageCode, organizations
Resetowanie i ponowne uruchamianie
Na wczesnym etapie eksperymentalnym programowania najbardziej praktycznym podejściem do iteracji projektowej jest usunięcie obiektów z usługi Azure AI Search i umożliwienie ponownego kompilowania kodu. Nazwy zasobów są unikatowe. Usunięcie obiektu umożliwia jego ponowne utworzenie przy użyciu tej samej nazwy.
Przykładowy kod tego samouczka sprawdza istniejące obiekty i usuwa je, aby można było ponownie uruchomić kod. Portal umożliwia również usuwanie indeksów, indeksatorów, źródeł danych i zestawów umiejętności.
Wnioski
W tym samouczku przedstawiono podstawowe kroki tworzenia wzbogaconego potoku indeksowania poprzez tworzenie części składników: źródła danych, zestawu umiejętności, indeksu i indeksatora.
Wprowadzono wbudowane umiejętności wraz z definicją zestawu umiejętności i mechaniką łączenia umiejętności za pośrednictwem danych wejściowych i wyjściowych. Wiesz również, że outputFieldMappings w definicji indeksatora jest wymagany routing wzbogaconych wartości z potoku do indeksu z możliwością wyszukiwania w usługa wyszukiwania usługi Azure AI.
Ponadto przedstawiono sposób testowania wyników i resetowania systemu na potrzeby przyszłych iteracji. Omówiono proces, w ramach którego odpytanie indeksu powoduje zwrócenie danych wyjściowych utworzonych przez wzbogacony potok indeksowania. Zaprezentowano procedurę sprawdzania stanu indeksatora i usuwania obiektów przed ponownym uruchomieniem potoku.
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, na końcu projektu warto usunąć zasoby, których już nie potrzebujesz. Uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w portalu i zarządzać nimi, korzystając z linku Wszystkie zasoby lub Grupy zasobów w okienku nawigacji po lewej stronie.
Następne kroki
Teraz, gdy znasz już wszystkie obiekty w potoku wzbogacania sztucznej inteligencji, przyjrzyjmy się bliżej definicjom zestawu umiejętności i indywidualnym umiejętnościom.