Co to jest zdefiniowany programowo magazyn systemu Windows Server?
Magazyn zdefiniowany programowo to jeden z fundamentów technologii Azure Stack HCI. Jednak w przeciwieństwie do funkcji Hyper-V lub klastra trybu failover magazyn zdefiniowany programowo nie jest pojedynczą rolą serwera ani funkcją. Zamiast tego składa się z różnych technologii, które często uzupełniają się wzajemnie. Możesz połączyć te technologie, aby zaimplementować różne scenariusze wirtualizacji magazynu, takie jak klastry gości lub HCI. Te technologie obejmują miejsca do magazynowania, udostępnione woluminy klastra (CSV), blok komunikatów serwera (SMB), SMB Multichannel, SMB Direct, serwer plików skalowalny w poziomie (SOFS), bezpośrednie miejsca do magazynowania (S2D) oraz replikę magazynu. Aby użyć technologii Azure Stack HCI w środowisku do weryfikacji koncepcji, będziesz korzystać z większości z nich.
Uwaga
Nie jest to wyczerpująca lista, ale wystarczy do uzyskania podstawowej wiedzy na temat najważniejszych funkcji zdefiniowanego programowo magazynu w Azure Stack HCI.
Co to jest magazyn zdefiniowany programowo?
Magazyn zdefiniowany programowo używa wirtualizacji magazynu do oddzielenia zarządzania magazynem i prezentowania go od sprzętu fizycznego, na jakim się znajduje. Jedną z głównych zalet tego podejścia jest uproszczenie aprowizacji i uzyskiwania dostępu do zasobów magazynu.
Po co używać magazynu zdefiniowanego programowo
W przypadku magazynu zdefiniowanego programowo implementacja zwirtualizowanych obciążeń nie wymaga konfiguracji numerów jednostek logicznych (LUN) ani przełączników sieci magazynowania (SAN) zgodnie ze specyfikacjami innych dostawców. Zamiast tego można zarządzać magazynem w taki sam, spójny sposób, niezależnie od sprzętu, na jakim się znajduje. Ponadto istnieje możliwość zastąpienia kosztownych, zastrzeżonych technologii elastycznymi i ekonomicznymi rozwiązaniami sprzętowymi. Zamiast polegać na dedykowanych sieciach SAN w przypadku magazynów o wysokiej wydajności i dostępności, można użyć dysków lokalnych, korzystając z ulepszeń w protokołach zdalnego udostępniania plików oraz sieci o wysokiej przepustowości i niskich opóźnieniach.
Miejsca do magazynowania to najprostszy przykład magazynu zdefiniowanego programowo w scenariuszach nieklasterowanych.
Miejsca do magazynowania
Miejsca do magazynowania to funkcja wirtualizacji magazynu, którą firma Microsoft wbudowała w usługę Azure Stack HCI oraz systemy Windows Server i Windows 10. Funkcja miejsc do magazynowania składa się z dwóch składników:
- Pule magazynów to kolekcja dysków fizycznych zagregowanych w dysk logiczny, którym można zarządzać jako pojedyncza jednostka. Pula magazynów może zawierać dyski fizyczne dowolnego typu i rozmiaru.
- Miejsca do magazynowania to dyski wirtualne, które można utworzyć na podstawie wolnego miejsca w puli magazynów. Dyski wirtualne są równoważnikami jednostek LUN w sieci SAN.
Po co używać funkcji miejsc do magazynowania
Poniżej przedstawiono najczęstsze przyczyny używania funkcji miejsc do magazynowania:
- Zwiększenie poziomu odporności magazynu, na przykład poprzez dublowanie i parzystość. Odporność dysków wirtualnych przypomina technologie nadmiarowej macierzy niezależnych dysków (RAID).
- Zwiększenie wydajności magazynu przy użyciu warstw magazynowania. Warstwy magazynowania umożliwiają optymalizowanie użycia różnych typów dysków w miejscu do magazynowania. Można na przykład używać szybkich dysków SSD o małych pojemnościach oraz wolniejszych dysków twardych o dużej pojemności. Jeśli używasz tej kombinacji dysków, Miejsca do magazynowania automatycznie przenosi dane, do których często uzyskuje się dostęp do szybszych dysków. następnie przenosi dane, do których dostęp jest rzadziej uzyskiwany do wolniejszych dysków.
- Zwiększenie wydajności magazynu poprzez buforowanie zapisu. Celem buforowania zapisu jest zoptymalizowanie zapisywania danych na dyskach w miejscu do magazynowania. Buforowanie zapisu działa z warstwami magazynowania. Jeśli serwer, na którym działa miejsce do magazynowania, wykryje szczytową aktywność zapisywania na dysku, automatycznie zacznie zapisywać dane na szybszych dyskach.
- Zwiększenie wydajności magazynu przy użyciu alokowania elastycznego. Alokowanie elastyczne umożliwia przydzielanie magazynu odpowiednio do potrzeb. W tradycyjnej metodzie alokacji magazynu stałego duże części pojemności magazynu są wstępnie przydzielane, ale mogą pozostać nieużywane. Alokowanie elastyczne optymalizuje wszystkie dostępne magazyny, odzyskując magazyn, który nie jest już potrzebny w procesie nazywanym przycinaniem.
Najprostszym przykładem magazynu zdefiniowanego programowo w scenariuszach nieklastrowanych są udostępnione woluminy klastra (CSV).
Udostępnione woluminy klastra
Udostępniony wolumin klastra to klastrowany system plików, który umożliwia wielu węzłom klastra trybu failover jednoczesne odczytywanie i zapisywanie plików w tym samym zestawie woluminów magazynu. Udostępnione woluminy klastra są mapowane na podkatalogi w katalogu C:\ClusterStorage\ w każdym węźle klastra. To mapowanie umożliwia węzłom klastra dostęp do tej samej zawartości za pośrednictwem tej samej ścieżki systemu plików. Chociaż każdy węzeł może niezależnie odczytywać i zapisywać poszczególne pliki w danym woluminie, jeden węzeł klastra pełni specjalną rolę właściciela (lub koordynatora) tego udostępnionego woluminu klastra. Istnieje możliwość przypisywania poszczególnych woluminów do określonego właściciela, jednak klaster trybu failover automatycznie rozpowszechnia własność udostępnionych woluminów klastra między węzłami klastra.
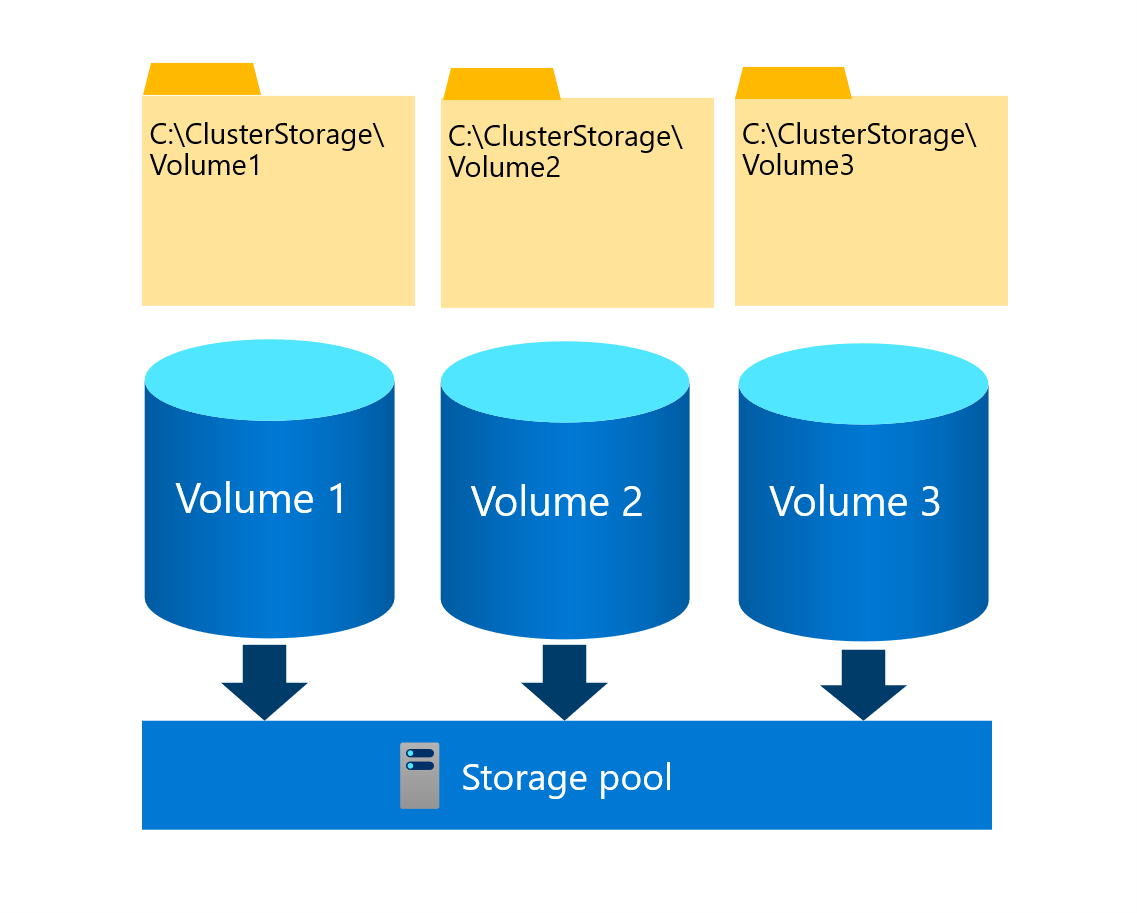
Gdy w udostępnionym woluminie klastra zachodzą zmiany w metadanych systemu plików, właściciel odpowiada za ich implementację, zarządzanie ich orkiestracją oraz zsynchronizowanie ich we wszystkich węzłach klastra z dostępem do tego woluminu. Takie zmiany obejmują utworzenie lub usunięcie pliku. Jednak standardowe operacje zapisu i odczytu otwierające pliki na udostępnionym woluminie klastra nie wpływają na metadane. W efekcie tego każdy węzeł klastra z bezpośrednim połączeniem z magazynem bazowym może wykonywać je niezależnie, bez polegania na właścicielu udostępnionego woluminu klastra.
Po co korzystać z udostępnionych woluminów klastra
Najczęściej używane są następujące zastosowania udostępnionych woluminów klastra:
- Klastrowane maszyny wirtualne funkcji Hyper-V.
- Zwiększanie w poziomie skali udziałów plików hostujących dane aplikacji dostępne za pośrednictwem protokołu SMB 3.x.
Blok komunikatów serwera 3.x
Protokół SMB to sieciowy protokół udostępniania plików, który zapewnia dostęp do plików za pośrednictwem tradycyjnej sieci Ethernet za pomocą protokołu transportowego TCP/IP. Protokół SMB służy jako jeden z podstawowych składników technologii magazynu zdefiniowanego programowo. Firma Microsoft wprowadziła protokół SMB w wersji 3.0 w systemie Windows Server 2012 i stopniowo ulepszała go w kolejnych wersjach.
Po co korzystać z protokołu SMB
Najczęściej używane są następujące zastosowania protokołu SMB:
- Magazyn dla plików dysków maszyn wirtualnych (funkcja Hyper-V przez protokół SMB). Funkcja Hyper-V może za pośrednictwem protokołu SMB 3.x. przechowywać w udziałach plików pliki maszyn wirtualnych, na przykład pliki konfiguracyjne, pliki dysków maszyn wirtualnych czy punkty kontrolne. Tych plików maszyn wirtualnych można używać zarówno w przypadku autonomicznych serwerów plików, jak i klastrowanych serwerów plików używających funkcji Hyper-V razem z udostępnionym magazynem plików dla klastra.
- Program Microsoft SQL Server przy użyciu protokołu SMB. W programie SQL Server mogą być przechowywane pliki bazy danych użytkowników w udziałach plików SMB.
- Tradycyjny magazyn danych użytkowników końcowych. Protokół SMB 3.x obsługuje tradycyjne obciążenia dla pracowników przetwarzających informacje.
Protokół SMB 3.x zapewnia obsługę funkcji SMB Multichannel oraz SMB Direct.
SMB Multichannel
Funkcja SMB Multichannel jest częścią implementacji protokołu SMB 3.x, która znacznie zwiększa wydajność i dostępność sieci dla urządzeń z systemem Windows Server oraz węzłów klastra Azure Stack HCI działających jako serwery plików. Funkcja SMB Multichannel umożliwia takim serwerom korzystanie z wielu połączeń sieciowych w celu zapewnienia następujących możliwości:
- Zwiększona przepływność. Serwer plików może jednocześnie przesyłać więcej danych przy użyciu wielu połączeń. Funkcja SMB Multichannel jest przydatna w przypadku korzystania z serwerów z wieloma, szybkimi kartami sieciowymi.
- Konfiguracja automatyczna. Funkcja SMB Multichannel automatycznie odnajduje wiele dostępnych ścieżek sieciowych i dynamicznie dodaje połączenia zgodnie z potrzebami.
- Odporność na uszkodzenia sieci. Jeśli istniejące połączenie zostanie przerwane z powodu problemu wzdłuż jednej ze ścieżek sieciowych do serwera SMB 3.x. Klienci SMB 3.x mają wbudowaną możliwość automatycznego przełączania w tryb failover do innego.
SMB Direct
Funkcja SMB Direct optymalizuje korzystanie z kart sieciowych zdalnego bezpośredniego dostępu do pamięci (RDMA) w przypadku ruchu SMB, co pozwala im działać z pełną szybkością, małym opóźnieniem i niskim użyciem procesora. Funkcja SMB Direct jest odpowiednia w scenariuszach, w których obciążenia, takie jak hyper-V lub Microsoft SQL Server, korzystają ze zdalnych serwerów plików SMB 3.x w celu emulowania magazynu lokalnego. Funkcja SMB Direct jest dostępna i domyślnie włączona we wszystkich aktualnie obsługiwanych wersjach systemu Windows Server i Azure Stack HCI.
Funkcja SMB Multichannel odpowiada za wykrywanie możliwości RDMA kart sieciowych niezbędnych do włączenia funkcji SMB Direct. Automatycznie tworzy dwa połączenia RDMA na interfejs. Klienty protokołu SMB automatycznie wykrywają dostępność wielu połączeń sieciowych i używają ich, jeśli zidentyfikują odpowiednią konfigurację.
Technologie SMB 3.x i udostępnione woluminy klastra stanowią podstawę funkcji SOFS.
Serwery plików skalowalne w poziomie
SOFS to funkcja klastra trybu failover działającego na podstawie udostępnionych woluminów klastra. Podczas konfigurowania roli serwera usług plików jako klastra można skonfigurować go jako serwer plików do użytku ogólnego lub jako serwer plików skalowalny w poziomie dla danych aplikacji. Pierwsza opcja implementuje foldery udostępnione wysokiej dostępności, do których dostęp uzyskać można za pomocą jednego z węzłów klastra. Jeśli ten węzeł ulegnie awarii, inny węzeł przejmuje własność roli i jej zasobów, zachowując dostępność folderów udostępnionych. Jednak klienty zawsze uzyskują dostęp do nich za pomocą jednego węzła. Funkcja SOFS implementuje inne podejście, w którym foldery udostępnione znajdują się na udostępnionym woluminie klastra.
Po co korzystać z funkcji SOFS
Rozwiązanie SOFS ma następujące zalety:
- Ulepszone skalowanie. Ponieważ klienci uzyskują dostęp do folderów udostępnionych za pośrednictwem wielu węzłów, jeśli liczba żądań dostępu wzrośnie, możesz dodać kolejny węzeł do serwera SOFS.
- Wykorzystanie ze zrównoważonym obciążeniem. Wszystkie węzły klastra trybu failover mogą akceptować i przetwarzać żądania odczytu i zapisu klienta na jednym serwerze SOFS lub większej ich liczbie. Łącząc ich przepustowość i moc procesora, można zwiększyć wykorzystanie w porównaniu do rozwiązania z pojedynczym węzłem. Pojedynczy węzeł klastra nie jest już potencjalnym wąskim gardłem, ponieważ serwer SOFS może obsługiwać taką liczbę klientów, na jaką pozwalają zbiorcze możliwości wszystkich węzłów klastra.
- Niezakłócone konserwacje, aktualizacje i awarie węzłów. Rozwiązywanie problemów z uszkodzeniem dysku, konserwacja, aktualizowanie lub ponowne uruchamianie węzła klastra trybu failover nie ma wpływu na dostępność serwera SOFS. SOFS umożliwia również przezroczyste przejście w tryb failover wyzwalane przez awarię węzła.
Funkcji SOFS można też użyć do zaimplementowania klastrowania gościa.
Klastrowanie gościa
Klaster gościa trybu failover jest konfigurowany podobnie jak klaster trybu failover serwera fizycznego, z tą różnicą, że węzły klastra są maszynami wirtualnymi. W tym scenariuszu tworzy się co najmniej dwie maszyny wirtualne i w systemach operacyjnych gościa implementuje klaster trybu failover. Aplikacja lub usługa może następnie korzystać z wysokiej dostępności między maszynami wirtualnymi. Mimo że maszyny wirtualne można umieścić na pojedynczym hoście, w scenariuszach produkcyjnych należy używać oddzielnych komputerów hosta funkcji Hyper-V z włączoną obsługą klastrów trybu failover. Po zaimplementowaniu klastra trybu failover na poziomie hosta i maszyny wirtualnej można ponownie uruchomić zasób, niezależnie od tego, czy maszyna wirtualna, czy węzeł hosta ulegnie awarii.
Maszyny wirtualne funkcji Hyper-V mogą używać magazynu udostępnionego, z którym mogą nawiązywać połączenie za pomocą protokołu Fibre Channel lub Internet SCSI (iSCSI). Można też skonfigurować magazyn udostępniony na klastrowanych hostach funkcji Hyper-V za pomocą funkcji udostępnionego wirtualnego dysku twardego, a następnie dołączyć dyski udostępnione do klastrowanych maszyn wirtualnych.
Udostępniony wirtualny dysk twardy można zastosować w następujących scenariuszach:
- Udostępniony wolumin klastra w klastrze hosta funkcji Hyper-V. W tym scenariuszu wszystkie pliki maszyn wirtualnych, w tym pliki wirtualnych dysków twardych, są przechowywane w udostępnionym woluminie klastra skonfigurowanym jako magazyn udostępniony klastrowanych maszyn wirtualnych.
- Serwer SOFS w osobnym klastrze magazynu. W tym scenariuszu jako lokalizacja udostępnionych plików wirtualnych dysków twardych używany jest magazyn oparty na plikach protokołu SMB.
W obu scenariuszach można zaimplementować magazyn przy użyciu funkcji bezpośrednich miejsc do magazynowania.
Bezpośrednie miejsca do magazynowania
Funkcja bezpośrednich miejsc do magazynowania reprezentuje ewolucję miejsc do magazynowania. Stosuje miejsca do magazynowania, klastry trybu failover, woluminy CSV i protokół SMB 3.x w celu zaimplementowania zwirtualizowanego, klastrowanego magazynu o wysokiej dostępności przy użyciu dysków lokalnych na każdym z węzłów klastra Miejsca do magazynowania Direct. Nadaje się do hostowania obciążeń o wysokiej dostępności, w tym maszyn wirtualnych i baz danych programu SQL Server. Miejsca do magazynowania Direct eliminuje konieczność dołączania urządzeń magazynujących do wielu węzłów klastra w scenariuszach klastra trybu failover.
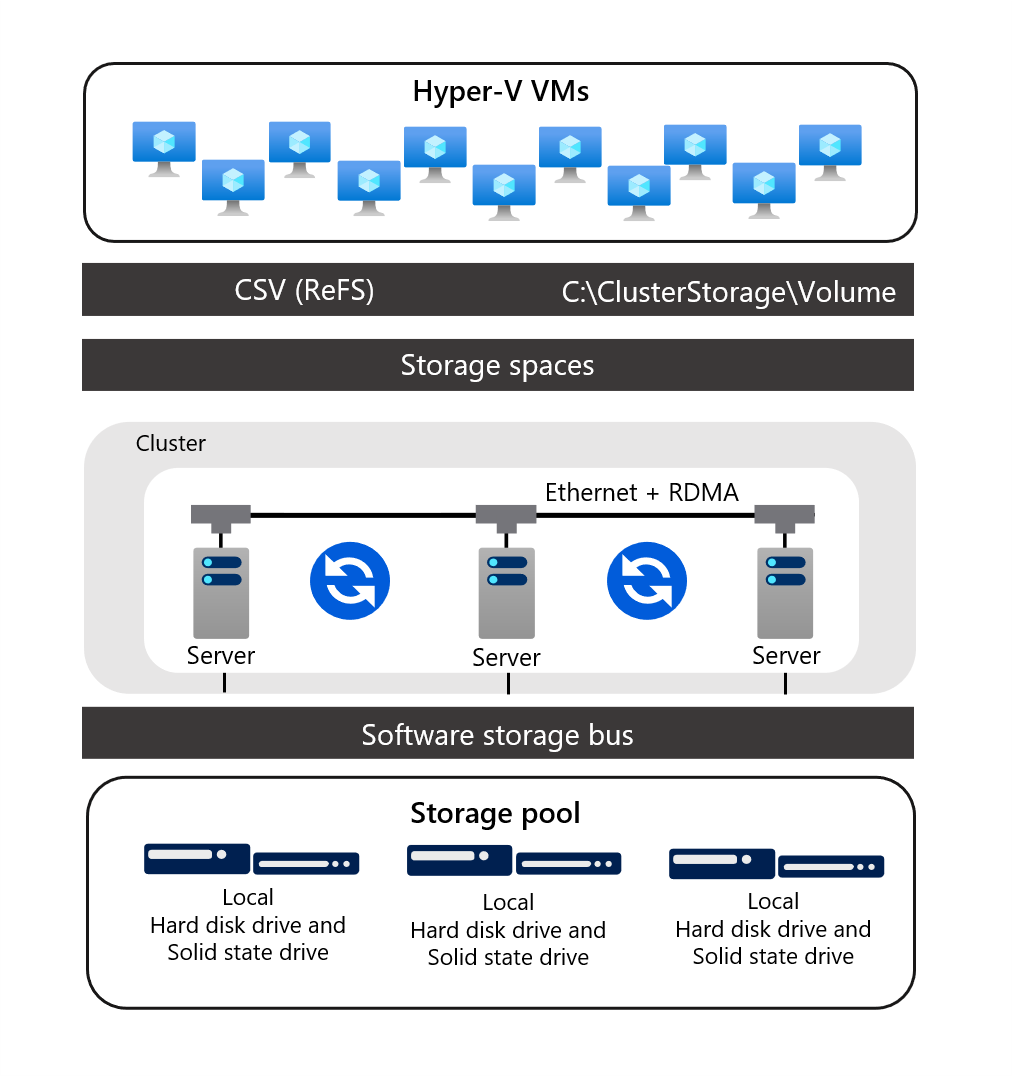
Korzystanie z dysków lokalnych w ten sposób wymaga sieci o dużej przepustowości i małych opóźnieniach między węzłami. Aby spełnić to wymaganie, należy wdrożyć nadmiarowe połączenia sieciowe w połączeniu z wysokiej klasy kartami sieciowymi RDMA. Ta architektura umożliwia korzystanie z technologii takich jak SMB 3.x, SMB Direct i SMB Multichannel w celu zapewnienia szybkiego, małego opóźnienia, wydajnego dla procesora CPU dostępu do magazynu.
Modele obciążeń bezpośrednich miejsc do magazynowania funkcji Hyper-V
Istnieją dwa modele wdrażania obciążeń funkcji Hyper-V za pomocą bezpośrednich miejsc do magazynowania:
- Dzielony. W modelu dzielonym hosty funkcji Hyper-V (obliczenia) znajdują się w oddzielnym klastrze od hostów funkcji bezpośrednich miejsc do magazynowania (magazyn). Maszyny wirtualne funkcji Hyper-V można skonfigurować do przechowywania plików w klastrze magazynu, korzystając z serwera SOFS, co umożliwia niezależne skalowanie klastra funkcji Hyper-V (obliczeń) i klastra opartego na protokole S2D (magazynu).
- Hiperkonwergentny. W modelu hiperkonwergentnym węzły klastra działają zarówno jako hosty funkcji Hyper-V (obliczenia), jak i hosty bezpośrednich miejsc do magazynowania (magazyn). Ten model wdrażania ma kolokowane zasoby obliczeniowe i magazynowe w tym samym zestawie węzłów klastra. Aby skalować klaster w górę, należy zwiększyć liczbę jego węzłów.
Uwaga
Azure Stack HCI to przykład modelu hiperkonwergentnego, który nie korzysta z funkcji SOFS.
Aby zapewnić dodatkową odporność obciążeń funkcji Hyper-V, możesz użyć repliki magazynu.
Replika magazynu
Replika magazynu umożliwia synchroniczną i asynchroniczną replikację na poziomie bloku niezależną od magazynu między serwerami lub klastrami w różnych lokalizacjach fizycznych.
Po co używać repliki magazynu
Za pomocą repliki magazynu można tworzyć rozproszone klastry trybu failover obejmujące dwa odrębne lokacje fizyczne, a wszystkie węzły pozostają zsynchronizowane. Replikacja synchroniczna replikuje woluminy między lokacjami w względnej odległości od siebie. Replikacja jest spójna na poziomie awarii, co pomaga zapobiec utracie danych na poziomie systemu plików podczas pracy w trybie failover. Replikacja asynchroniczna umożliwia replikację na dłuższych dystansach w przypadkach, gdy opóźnienie rundy sieci przekracza 5 milisekund (ms), ale podlega utracie danych. Zakres utraty danych zależy od opóźnienia replikacji między woluminem źródłowym i docelowym.
Uwaga
W przypadku klastrów rozciągniętych w Azure Stack HCI używana jest replika magazynu.