Architektury przesyłania strumieniowego: Analiza przypadku
Po omówieniu rozwoju architektur przesyłania strumieniowego możemy przyjrzeć się jednej konkretnej platformie, Apache Samza.
Apache Samza
Projekt Samza został opracowany przez firmę LinkedIn jako platforma rozproszonego przetwarzania strumieniowego. Służy ona do przekształcania strumienia wejściowego komunikatów w zmodyfikowany strumień wyjściowy w oparciu o przetwarzanie stanowe lub bezstanowe. Projekt Samza został opracowany wraz z platformą Kafka (opisaną wcześniej), która była rozproszonym systemem obsługi komunikatów o małym opóźnieniu. Projekt Samza umożliwia przetwarzanie w czasie rzeczywistym tych komunikatów platformy Kafka.
Projekt Samza składa się z następujących trzech warstw:
- Warstwa przesyłania strumieniowego, która zapewnia partycjonowane, replikowane i trwałe strumienie
- Warstwa wykonywania, która planuje i koordynuje podzadania w klastrze
- Warstwa przetwarzania, która przekształca strumień wejściowy i generuje nowy strumień wyjściowy, zmienia bazy danych, wyzwala zdarzenia i ogólnie rzecz biorąc reaguje na komunikaty wejściowe
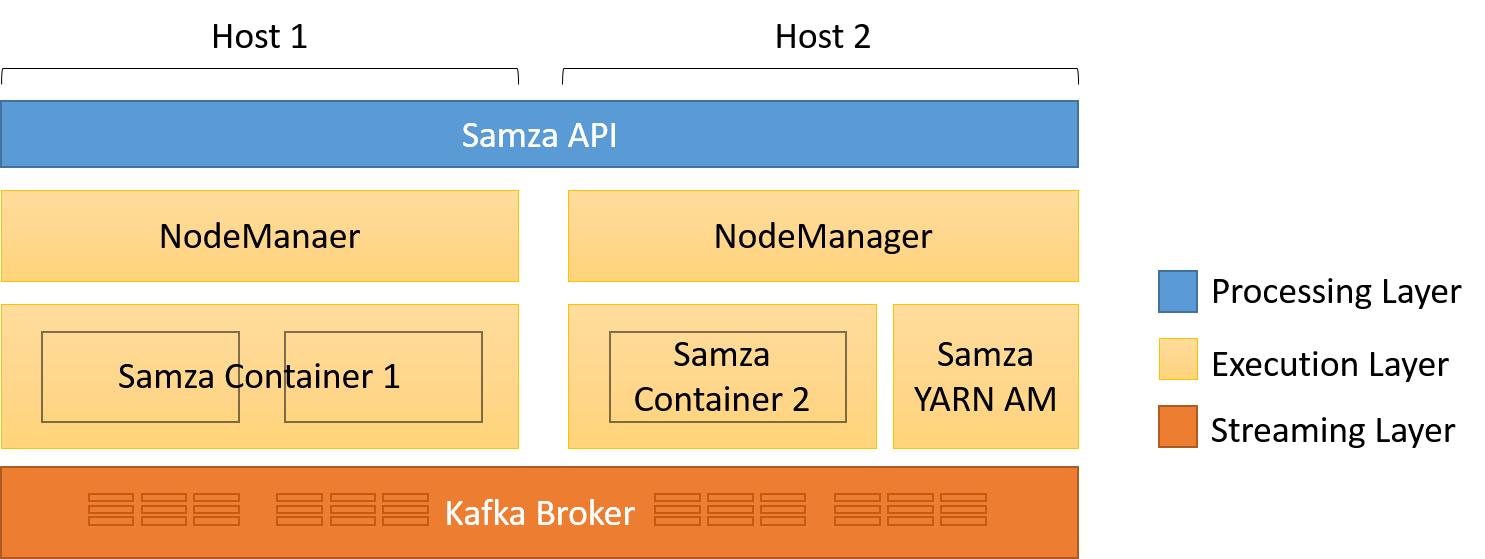
Rysunek 9. Trzy warstwy aplikacji Samza
Warstwy przesyłania strumieniowego i wykonywania są podłączane. Podczas implementacji domyślnej platforma Kafka jest wykorzystywana jako broker do przesyłania strumieniowego komunikatów. Strumienie wejściowe i wyjściowe są niezmienialnymi sekwencjami komunikatów, które można dzielić na partycje dla poszczególnych węzłów. W ramach partycji komunikaty są porządkowane globalnie i jednoznacznie identyfikowane na podstawie przesunięcia w ramach strumienia. Domyślna warstwa wykonywania korzysta z platformy YARN, chociaż można też użyć innego popularnego menedżera zasobów — Mesos. Użycie platformy YARN ułatwia aplikacji Samza zapewnienie odporności na uszkodzenia, uproszczenie wdrażania oraz korzystanie z wbudowanych funkcji rejestrowania i izolacji zasobów. Korzystanie z platformy YARN wraz z HDFS umożliwia również aplikacji Samza korzystanie z lokalności danych.
Samza używa również kontenerów cgroups do przetwarzania jednordzeniowych kontenerów, które uruchamiają wirtualną maszynę Java w celu wykonywania jednego lub wielu podzadań w ramach jednego zadania. Cgroups to funkcja jądra systemu Linux, która umożliwia utworzenie kolekcji procesów i określenie dla nich zbiorczego ograniczenia w zakresie dostępu do procesora, pamięci i systemu plików. W aplikacji Samza każdy kontener podczas przetwarzania komunikatu jest logicznie wykonywany jako jeden wątek, czyli w dowolnym momencie w kontenerze jest wykonywane tylko jedno podzadanie. Przetwarzanie odbywa się przy użyciu niestandardowego kodu napisanego przy użyciu interfejsu API Samza.
Aby zwiększyć równoległość, aplikacja Samza po prostu duplikuje więcej kontenerów. Z tego powodu nie zaleca się, aby deweloperzy stosowali wielowątkowość w kodzie zadania. Środowisko Samza do komunikacji i przetwarzania używa wielu wątków wewnętrznie; jednak jeden wątek działa jako pętla zdarzeń, która obsługuje operacje wejścia/wyjścia komunikatów, ustalanie punktu kontrolnego, obsługę okien oraz opróżnianie metryk.
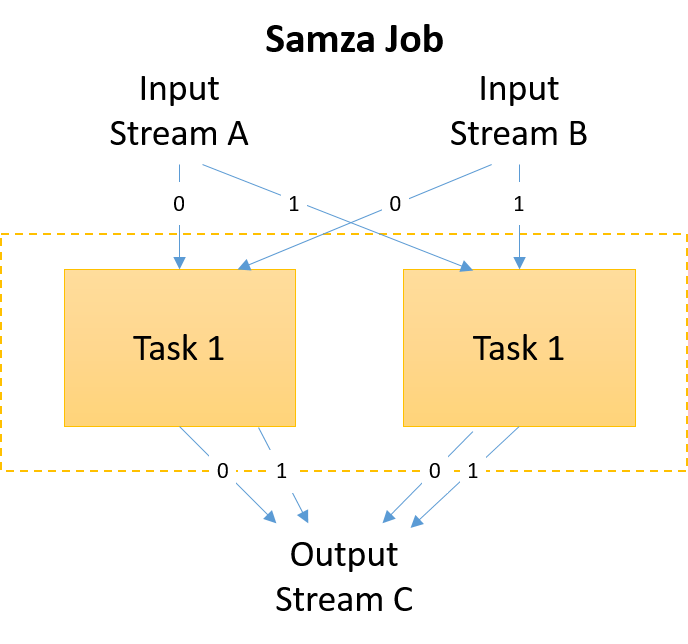
Rysunek 10. Strumienie wejściowe i wyjściowe w zadaniu Samza
Klienci platformy Samza inicjują zadania Samza w ramach platformy YARN. Środowisko Samza ma własny program Application Master, który negocjuje przydział zasobów za pomocą programu YARN Resource Manager (RM). Program YARN RM komunikuje się z różnymi menedżerami węzłów, aby przydzielić zasoby do aplikacji Samza. Platforma YARN duplikuje kontenery SamzaContainers (moduły uruchamiające podzadania), które uruchamiają kod niestandardowy wdrażający interfejs API Samza StreamTask. Są one często kolokowane z kontenerami dla brokerów platformy Kafka, aby zmaksymalizować lokalność danych.
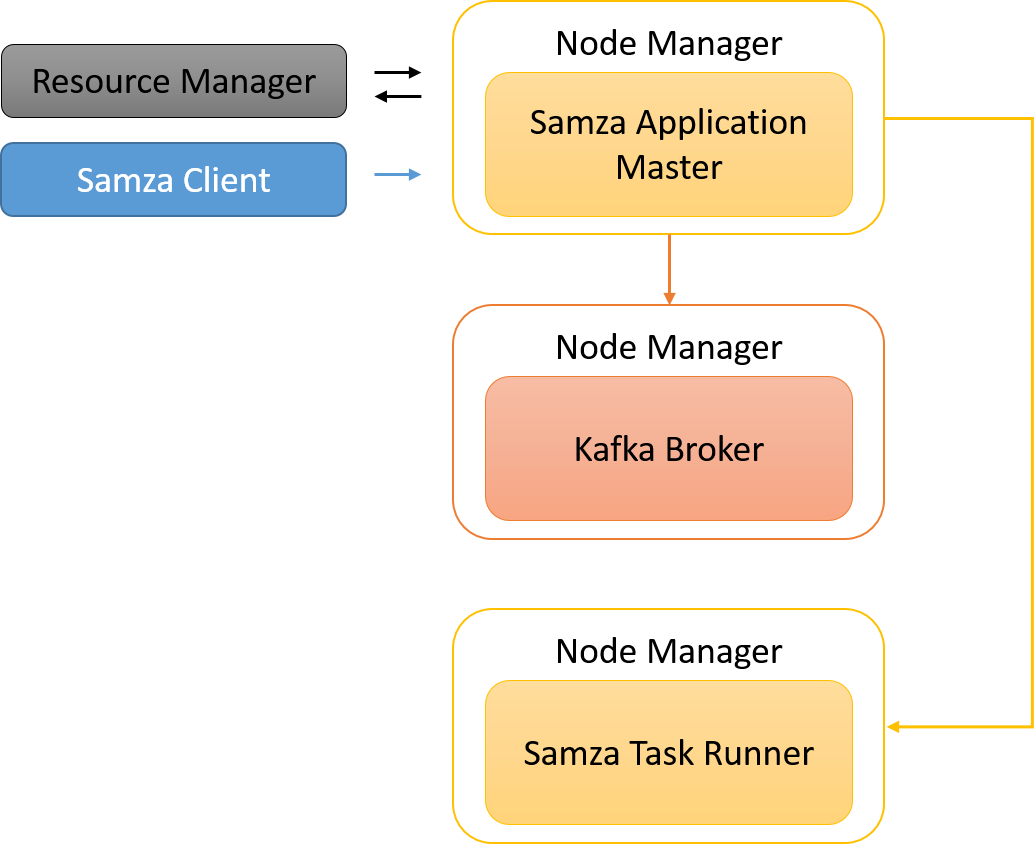
Rysunek 11. Zadanie Samza jest podzielone na zadania, które można zgrupować w kontenerze. Ponieważ istnieje tylko jeden wątek na kontener, w danym momencie może być aktywne tylko jedno podzadanie.
W środowisku Samza poprawa wydajności jest uzyskiwana przez skalowanie w poziomie. Odbywa się to przez zwiększenie liczby podzadań w ramach zadania. Każde podzadanie działa na pojedynczej partycji ze strumieni danych wejściowych zadania. Zatem aby istniała możliwość uruchamiania większej liczby równoległych podzadań, strumień musi zostać podzielony na większą liczbę partycji. Zostało to opisane we wcześniejszym temacie dotyczącym platformy Kafka. W przypadku każdego tematu wejściowego istnieje co najmniej jedno wystąpienie StreamTask zainicjowane dla każdej partycji. Każde zadanie strumienia niezależnie przetwarza jedną partycję.

Rysunek 12. Aplikacje Samza działają na platformie YARN w izolowanych kontenerach
Oczywiście przedstawiony powyżej przykład przesyłania strumieniowego po prostu przekształca strumień przychodzący w dane wyjściowe. Istnieje wiele aplikacji do przetwarzania strumieniowego, w których obliczenia wykonywane na dowolnym komunikacie wejściowym są niezależne od pozostałych komunikatów. Przykłady obejmują filtrowanie danych na podstawie reguł lub proste modyfikacje na podstawie czasu.
Jednak bardziej interesujące przypadki użycia związane z przetwarzaniem strumieniowym wymagają połączenia wielu strumieni, wykonywania agregacji komunikatów lub podejmowania decyzji na podstawie okna danych. Wszystkie te scenariusze wymagają przechowywania informacji o stanie. Środowisko Samza implementuje trwałość przy użyciu abstrakcji KeyValueStore. Każde wystąpienie StreamTask przechowuje stan w oddzielnym osadzonym magazynie danych na tej samej maszynie. Domyślnie środowisko Samza używa bazy danych RocksDB, która zapewnia małe opóźnienie, wysoką przepływność i jest zoptymalizowana pod kątem zapisu. Użycie osadzonej bazy danych zmniejsza obciążenie związane z zależnością od kosztownych wywołań sieciowych do wykonywania zapytań o dane.
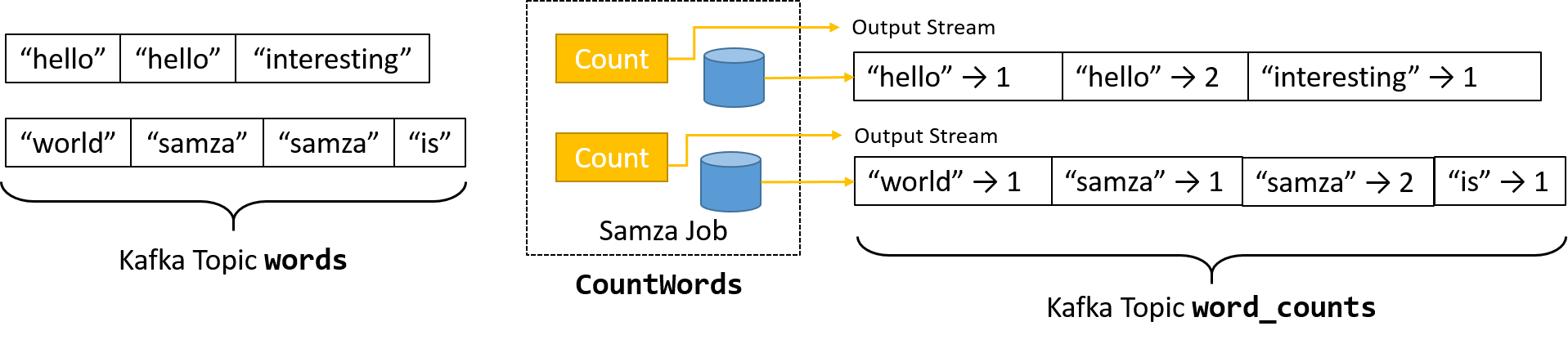
Rysunek 13. Zapewnianie trwałości stanu lokalnego zadania przy użyciu osadzonego magazynu danych
Ta implementacja polega na podzieleniu zdalnej bazy danych na fragmenty i kolokowaniu każdego fragmentu z unikatową partycją danych. Aby zagwarantować, że awarie nie będą prowadzić do utraty stanu, wszelkie modyfikacje lokalnej bazy danych będą emitowane przy użyciu oddzielnego strumienia dziennika zmian, który jest osobnym tematem na platformie Kafka. Oddzielny proces w tle uruchamia kompaktowanie dzienników w celu zmniejszenia ilości danych w dzienniku zmian.
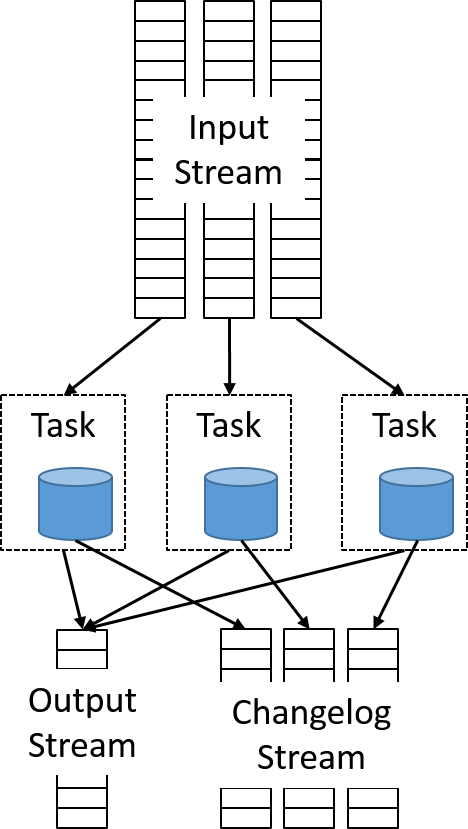
Rysunek 14. Każda lokalna osadzona baza danych zapisuje w strumieniu wyjściowym dziennika zmian
Dzięki temu podzadania można łatwo skalować w poziomie przez uruchomienie nowego kontenera, który ma własną bazę danych i wykonuje zapis do innego równoległego strumienia dziennika zmian. W przypadku wystąpienia jakichkolwiek awarii nowy kontener można uruchomić i przywrócić do stanu spójnego przez pobranie z wyjściowego dziennika zmian partycji, która uległa awarii.
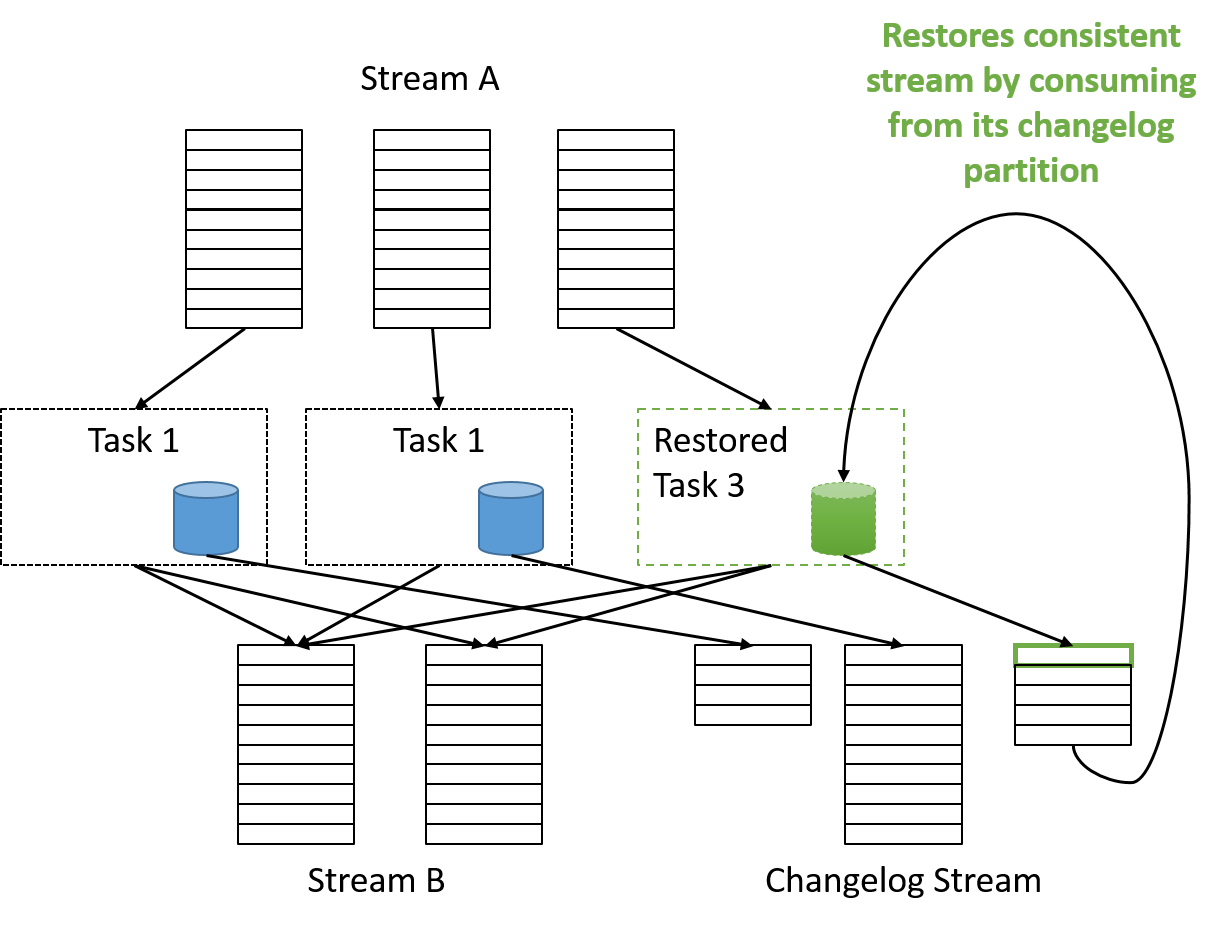
Rysunek 15. Odzyskiwanie po awarii w środowisku Samza