"Ćwiczenie — tworzenie przepływu danych mapowania usługi Azure Data Factory"
Przekształcanie danych za pomocą Przepływ danych mapowania
Możesz natywnie wykonywać przekształcenia danych za pomocą bezpłatnego kodu usługi Azure Data Factory przy użyciu zadania Mapowanie Przepływ danych. Mapowanie Przepływ danych zapewnia w pełni wizualne środowisko bez konieczności kodowania. Przepływy danych będą uruchamiane we własnym klastrze wykonywania na potrzeby skalowalnego w poziomie przetwarzania danych. Działania przepływu danych można zoperacjonalizować za pomocą istniejących funkcji planowania, sterowania, przepływu i monitorowania usługi Data Factory.
Podczas tworzenia przepływów danych można włączyć tryb debugowania, który włącza mały interaktywny klaster Spark. Włącz tryb debugowania, przełączając suwak w górnej części modułu tworzenia. Rozgrzanie klastrów debugowania może potrwać kilka minut, ale może służyć do interaktywnego wyświetlania podglądu danych wyjściowych logiki przekształcania.

Po dodaniu Przepływ danych mapowania i uruchomieniu klastra Spark umożliwi to przeprowadzenie transformacji oraz uruchomienie i wyświetlenie podglądu danych. Nie jest wymagane kodowanie, ponieważ usługa Azure Data Factory obsługuje całe tłumaczenie kodu, optymalizację ścieżki i wykonywanie zadań przepływu danych.
Dodawanie danych źródłowych do Przepływ danych mapowania
Otwórz kanwę mapowania Przepływ danych. Kliknij przycisk Dodaj źródło na kanwie Przepływ danych. Na liście rozwijanej źródłowy zestaw danych wybierz źródło danych, w tym przypadku zestaw danych usługi ADLS Gen2 jest używany w tym przykładzie
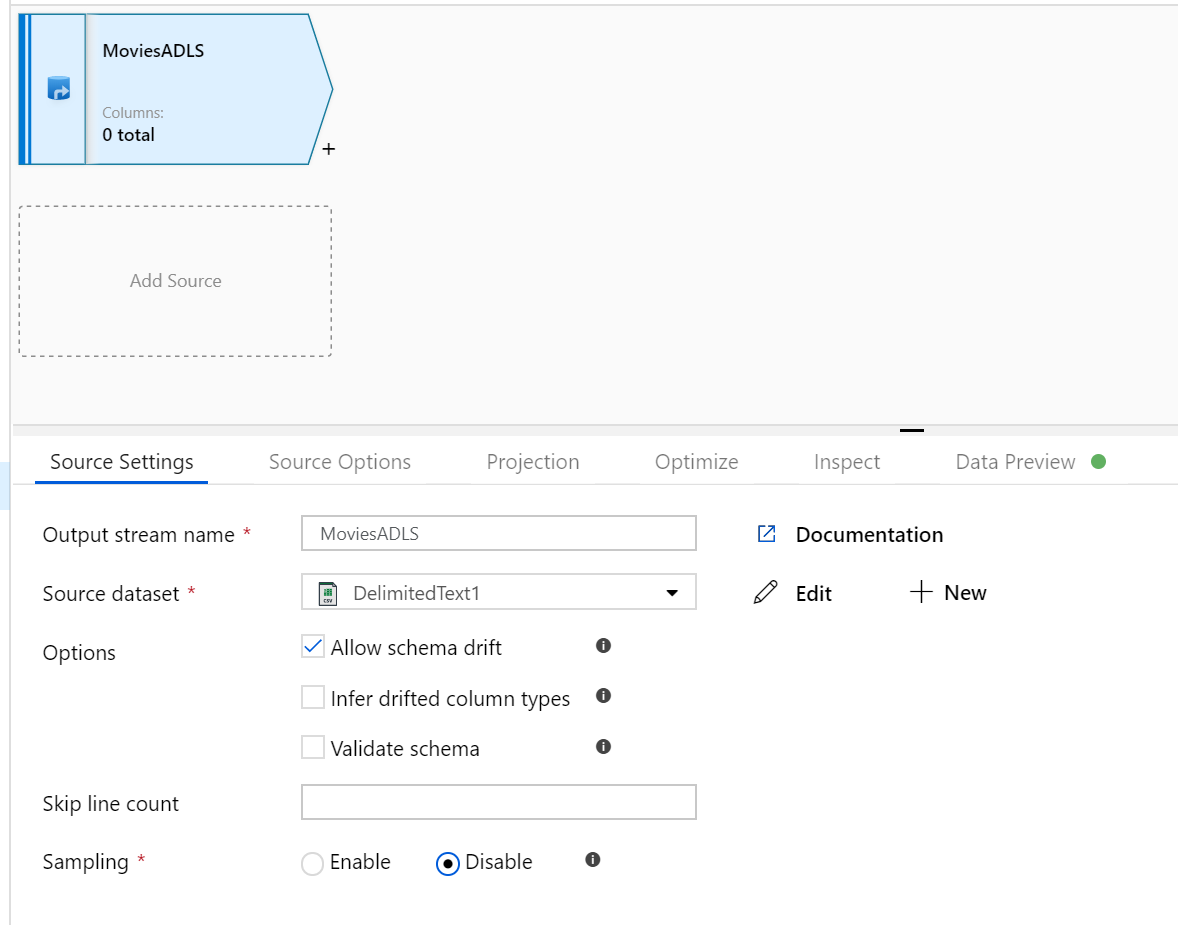
Należy pamiętać o kilku kwestiach:
- Jeśli zestaw danych wskazuje folder z innymi plikami i chcesz użyć tylko jednego pliku, może być konieczne utworzenie innego zestawu danych lub wykorzystanie parametryzacji, aby upewnić się, że tylko określony plik jest odczytywany
- Jeśli schemat nie został zaimportowany do usługi ADLS, ale już pozyskał dane, przejdź do karty "Schemat" zestawu danych i kliknij pozycję "Importuj schemat", aby przepływ danych znał projekcję schematu.
Mapowanie Przepływ danych jest zgodne z podejściem wyodrębniania, ładowania, przekształcania (ELT) i współpracuje z przejściowymi zestawami danych, które znajdują się na platformie Azure. Obecnie w transformacji źródłowej można używać następujących zestawów danych:
- Azure Blob Storage (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Text, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Usługa Azure Data Factory ma dostęp do ponad 80 łączników natywnych. Aby uwzględnić dane z tych innych źródeł w przepływie danych, użyj działania kopiowania, aby załadować te dane do jednego z obsługiwanych obszarów przejściowych.
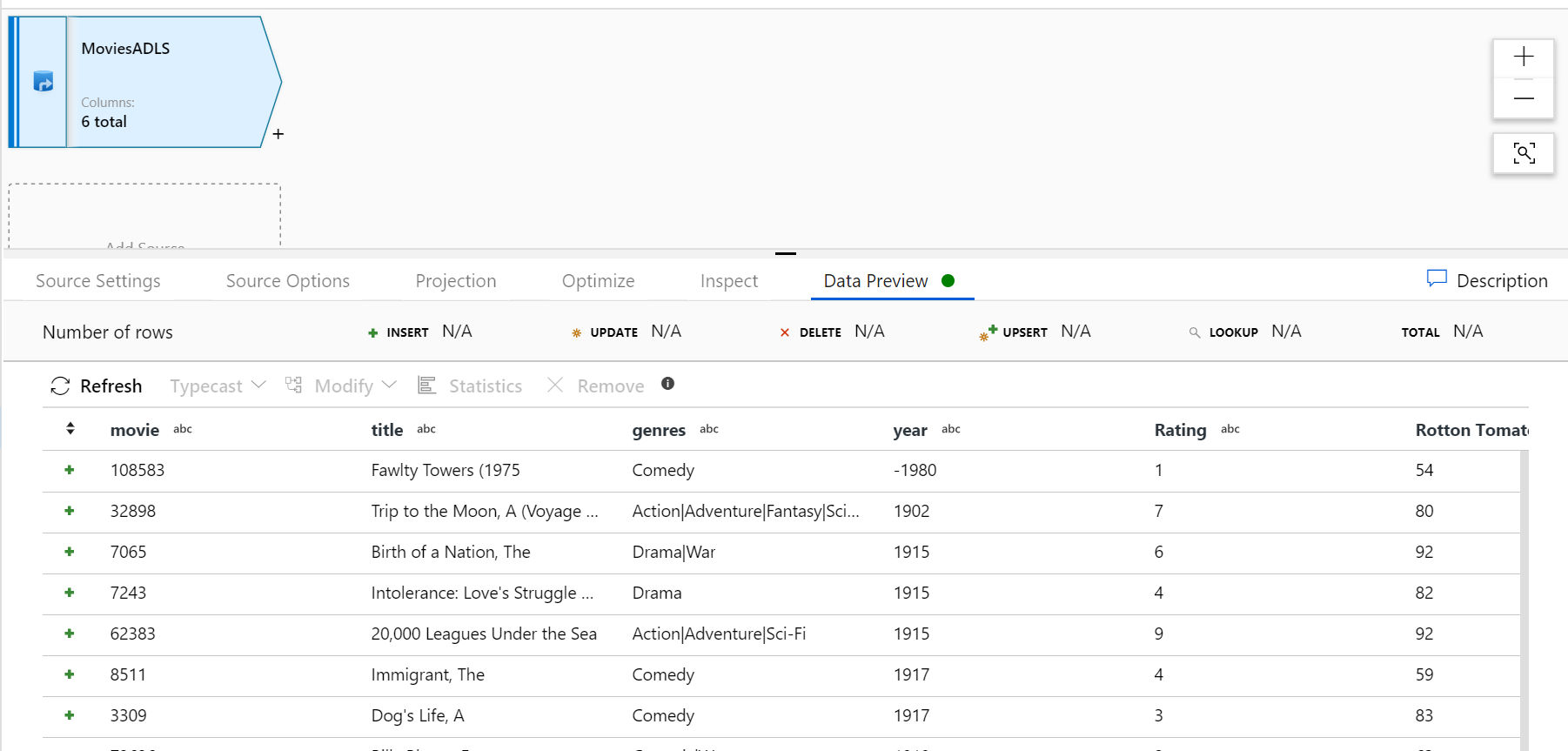
Po rozgrzaniu klastra debugowania sprawdź, czy dane są prawidłowo ładowane za pomocą karty Podgląd danych. Po kliknięciu przycisku odświeżania mapowanie Przepływ danych wyświetli migawkę wyglądu danych podczas każdej transformacji.
Używanie przekształceń w Przepływ danych mapowania
Po przeniesieniu danych do usługi Azure Data Lake Store Gen2 możesz utworzyć Przepływ danych mapowania, które przekształci dane na dużą skalę za pośrednictwem klastra spark, a następnie załaduj je do magazynu danych.
Główne zadania dla tego zadania są następujące:
Przygotowywanie środowiska
Dodawanie źródła danych
Używanie przekształcenia Przepływ danych mapowania
Zapisywanie w ujściu danych
Zadanie 1. Przygotowywanie środowiska
Włącz Przepływ danych Debugowanie Włącz suwak debugowania Przepływ danych znajdujący się w górnej części modułu tworzenia.
Uwaga
Przepływ danych klastry rozgrzewają się przez 5–7 minut.
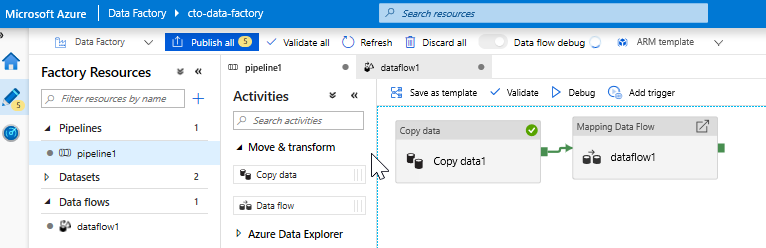
Dodaj działanie Przepływ danych. W okienku Działania otwórz akordeon Przenieś i Przekształć i przeciągnij działanie Przepływ danych na kanwę potoku. W wyświetlonym bloku kliknij pozycję Utwórz nowy Przepływ danych i wybierz pozycję Mapowanie Przepływ danych, a następnie kliknij przycisk OK. Kliknij kartę pipeline1 i przeciągnij zielone pole z działanie Kopiuj do działania Przepływ danych, aby utworzyć warunek powodzenia. Na kanwie zostaną wyświetlone następujące elementy:
Zadanie 2. Dodawanie źródła danych
Dodaj źródło usługi ADLS. Kliknij dwukrotnie obiekt Mapowanie Przepływ danych na kanwie. Kliknij przycisk Dodaj źródło na kanwie Przepływ danych. Z listy rozwijanej Źródłowy zestaw danych wybierz zestaw danych USŁUGI ADLSG2 używany w działanie Kopiuj
- Jeśli zestaw danych wskazuje folder z innymi plikami, może być konieczne utworzenie innego zestawu danych lub użycie parametryzacji, aby upewnić się, że tylko plik moviesDB.csv jest odczytywany
- Jeśli schemat nie został zaimportowany do usługi ADLS, ale już pozyskał dane, przejdź do karty "Schemat" zestawu danych i kliknij pozycję "Importuj schemat", aby przepływ danych znał projekcję schematu.
Po rozgrzaniu klastra debugowania sprawdź, czy dane są prawidłowo ładowane za pomocą karty Podgląd danych. Po kliknięciu przycisku odświeżania mapowanie Przepływ danych wyświetli migawkę wyglądu danych podczas każdej transformacji.
Zadanie 3. Używanie przekształcenia Przepływ danych mapowania
Dodaj przekształcenie Wybierz, aby zmienić nazwę i usunąć kolumnę. W podglądzie danych można zauważyć, że kolumna "Rotton Tomatoes" jest błędnie wyczyszczone. Aby poprawnie go nazwać i usunąć nieużywaną kolumnę Ocena, możesz dodać przekształcenie Wybierz, klikając ikonę + obok węzła źródłowego usługi ADLS i wybierając pozycję Wybierz w obszarze Modyfikator schematu.
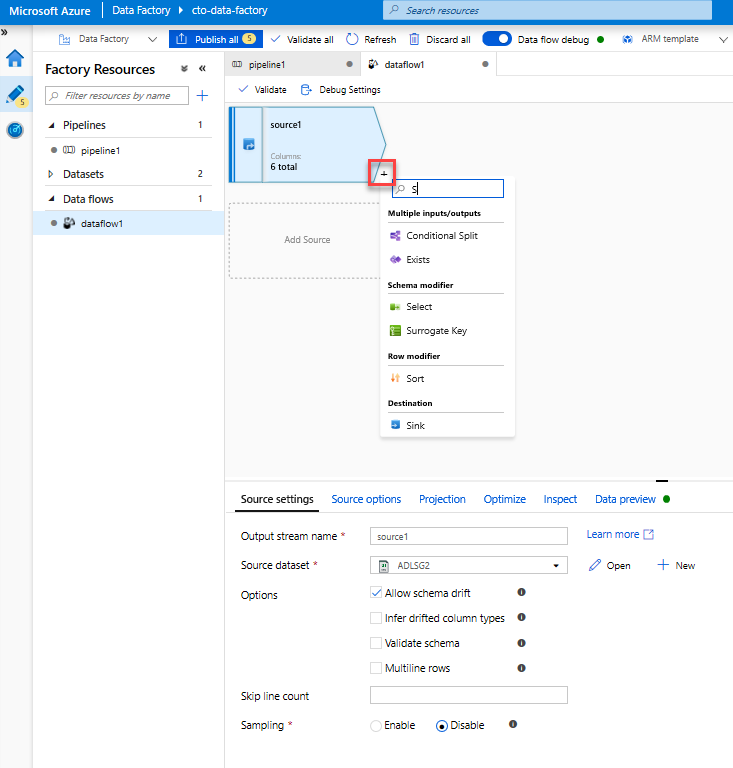
W polu Nazwa jako zmień wartość "Rotton" na "Rotten". Aby usunąć kolumnę Ocena, umieść na niej wskaźnik myszy i kliknij ikonę kosza.
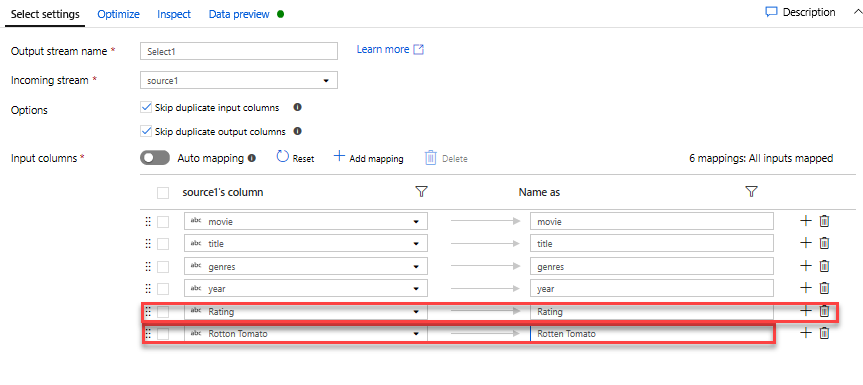
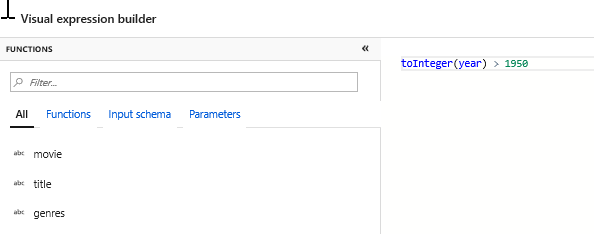
Dodaj transformację filtru, aby odfiltrować niechciane lata. Załóżmy, że interesuje Cię tylko filmy wykonane po 1951 roku. Możesz dodać przekształcenie Filtr, aby określić warunek filtru, klikając ikonę + obok przekształcenia Wybierz i wybierając pozycję Filtr w obszarze Modyfikator wierszy. Kliknij pole wyrażenia, aby otworzyć konstruktora wyrażeń i wprowadzić go w warunku filtru. Używając składni języka wyrażeń mapowania Przepływ danych, wartośćInteger(rok) > 1950 przekonwertuje wartość roku ciągu na liczbę całkowitą i filtruje wiersze, jeśli ta wartość jest wyższa niż 1950.
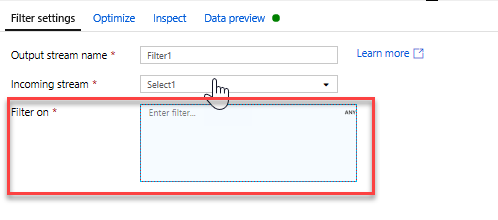
Możesz użyć osadzonego okienka Podgląd danych konstruktora wyrażeń, aby sprawdzić, czy warunek działa prawidłowo
Dodaj transformację pochodną, aby obliczyć gatunek podstawowy. Jak można było zauważyć, kolumna gatunków jest ciągiem rozdzielanym znakiem '|'. Jeśli interesuje Cię tylko pierwszy gatunek w każdej kolumnie, możesz utworzyć nową kolumnę o nazwie PrimaryGenre za pomocą przekształcenia kolumny pochodnej, klikając ikonę + obok przekształcenia Filtr i wybierając pozycję Pochodne w obszarze Modyfikator schematu. Podobnie jak w przypadku przekształcenia filtru, kolumna pochodna używa konstruktora wyrażeń mapowania Przepływ danych w celu określenia wartości nowej kolumny.

W tym scenariuszu próbujesz wyodrębnić pierwszy gatunek z kolumny gatunków, która jest sformatowana jako "gatunek1|gatunek2|...|gatunekN". Użyj funkcji locate, aby uzyskać pierwszy 1-oparty na indeksie '|' w ciągu gatunku. Korzystając z funkcji iif, jeśli ten indeks jest większy niż 1, gatunek podstawowy można obliczyć za pomocą funkcji po lewej stronie, która zwraca wszystkie znaki w ciągu z lewej strony indeksu. W przeciwnym razie wartość PrimaryGenre jest równa polu gatunkom. Dane wyjściowe można zweryfikować za pomocą okienka Podgląd danych konstruktora wyrażeń.
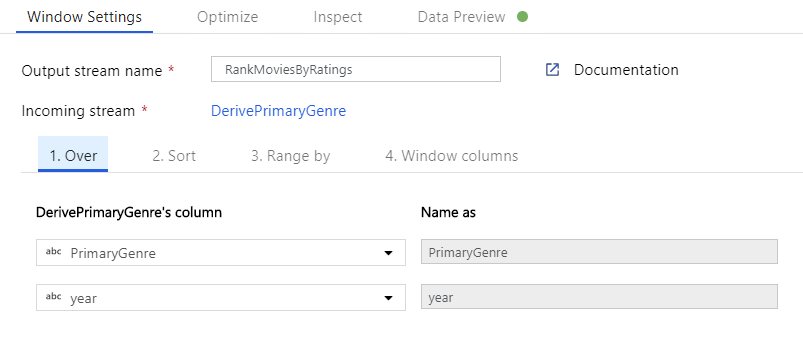
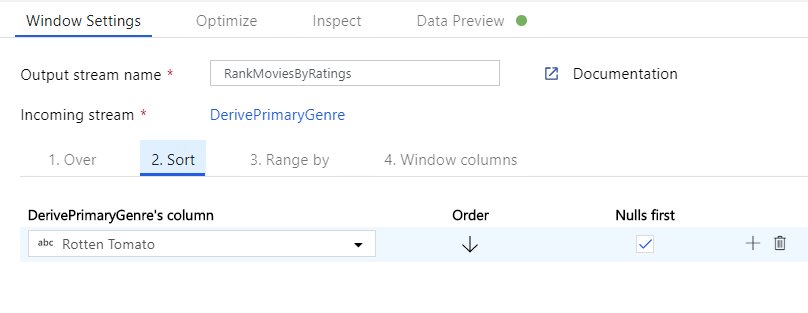
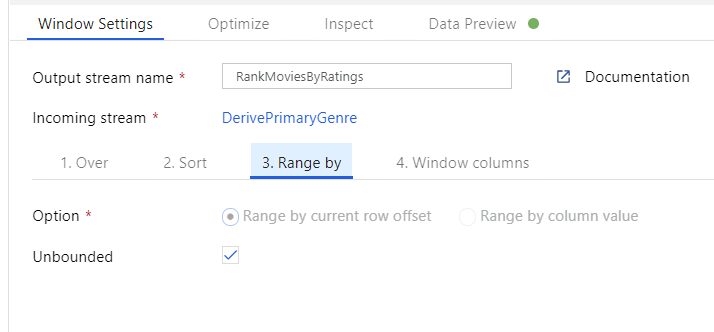
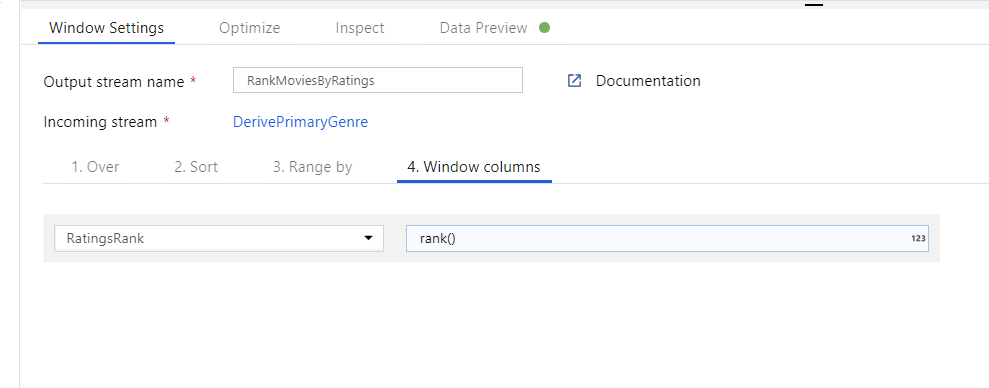
Klasyfikacja filmów za pomocą przekształcenia okna. Załóżmy, że interesuje Cię, jak film plasuje się w ciągu roku dla konkretnego gatunku. Aby zdefiniować agregacje oparte na oknach, możesz dodać przekształcenie okna, klikając ikonę + obok przekształcenia kolumny pochodnej i klikając pozycję Okno w obszarze Modyfikator schematu. Aby to osiągnąć, określ, co jest w oknie, co sortujesz według, jaki jest zakres i jak obliczyć nowe kolumny okien. W tym przykładzie zostanie wyświetlone okno w kolumnie PrimaryGenre i roku z niezwiązanym zakresem, posortujemy według malejącego rotten pomidora i obliczymy nową kolumnę o nazwie RatingsRank, która jest równa rangi każdego filmu w określonym gatunku roku.
Agregowanie klasyfikacji za pomocą przekształcenia agregowanego. Po zebraniu i utworzeniu wszystkich wymaganych danych możemy dodać przekształcenie agregacji w celu obliczenia metryk na podstawie żądanej grupy, klikając ikonę + obok przekształcenia okna i klikając pozycję Agregacja w obszarze Modyfikator schematu. Tak jak w przypadku transformacji okna, umożliwia grupowanie filmów według PrimaryGenre i roku
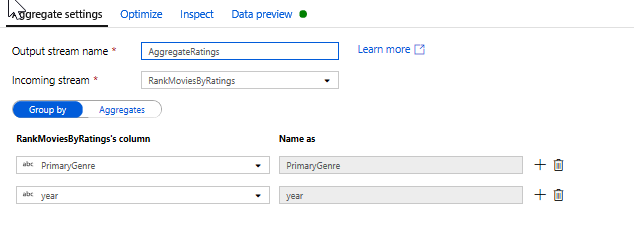
Na karcie Agregacje można tworzyć agregacje obliczane dla określonej grupy według kolumn. Dla każdego gatunku i roku, umożliwia uzyskanie średniej oceny Rotten Tomatoes, najwyższego i najniższego ocenianego filmu (korzystającego z funkcji okien) i liczby filmów, które znajdują się w każdej grupie. Agregacja znacznie zmniejsza liczbę wierszy w strumieniu transformacji i propaguje grupę tylko według i agreguje kolumny określone w transformacji.
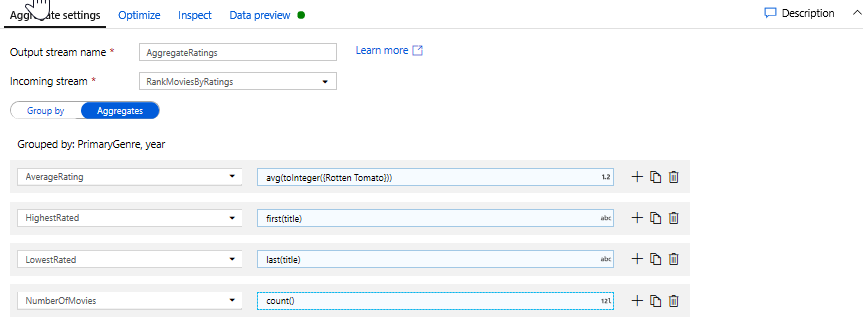
- Aby zobaczyć, jak agregacja zmienia dane, użyj karty Podgląd danych
Określ warunek Upsert za pomocą przekształcenia alter row. Jeśli piszesz do ujścia tabelarycznego, możesz określić zasady wstawiania, usuwania, aktualizowania i upsert wierszy przy użyciu przekształcenia Alter Row, klikając ikonę + obok przekształcenia Agregacja i klikając polecenie Alter Row w obszarze Modyfikator wierszy. Ponieważ zawsze wstawiasz i aktualizujesz, możesz określić, że wszystkie wiersze będą zawsze upserted.

Zadanie 4. Zapisywanie w ujściu danych
- Zapisywanie w ujściu usługi Azure Synapse Analytics. Po zakończeniu całej logiki przekształcania możesz przystąpić do zapisywania w ujściu.
Dodaj ujście, klikając ikonę + obok przekształcenia Upsert i klikając pozycję Ujście w obszarze Miejsce docelowe.
Na karcie Ujście utwórz nowy zestaw danych magazynu danych za pomocą przycisku + Nowy.
Wybierz pozycję Azure Synapse Analytics z listy kafelków.
Wybierz nową połączoną usługę i skonfiguruj połączenie usługi Azure Synapse Analytics w celu nawiązania połączenia z bazą danych DWDB. Kliknij przycisk Utwórz po zakończeniu.
W konfiguracji zestawu danych wybierz pozycję Utwórz nową tabelę i wprowadź w schemacie dboi nazwę tabeli Klasyfikacje. Kliknij przycisk OK po zakończeniu.
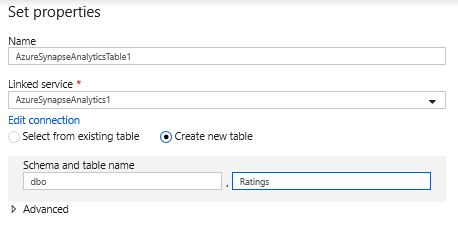
Ponieważ określono warunek upsert, należy przejść do karty Ustawienia i wybrać pozycję "Zezwalaj na upsert" na podstawie kluczowych kolumn PrimaryGenre i year.
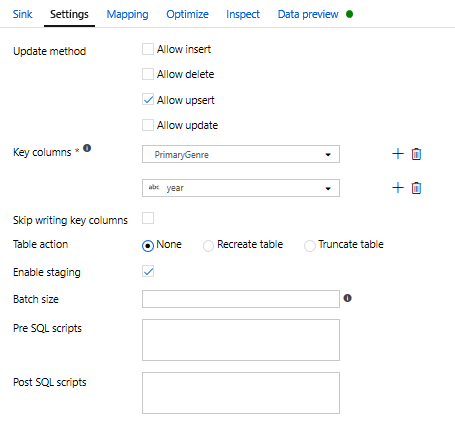
Na tym etapie zakończono tworzenie Przepływ danych mapowania przekształceń 8. Nadszedł czas, aby uruchomić potok i zobaczyć wyniki!

Zadanie 5. Uruchamianie potoku
Przejdź do karty pipeline1 na kanwie. Ponieważ usługa Azure Synapse Analytics w Przepływ danych używa technologii PolyBase, należy określić obiekt blob lub folder przejściowy usługi ADLS. Na karcie Ustawienia działania Wykonaj Przepływ danych otwórz akordeon PolyBase i wybierz połączoną usługę ADLS i określ ścieżkę folderu przejściowego.
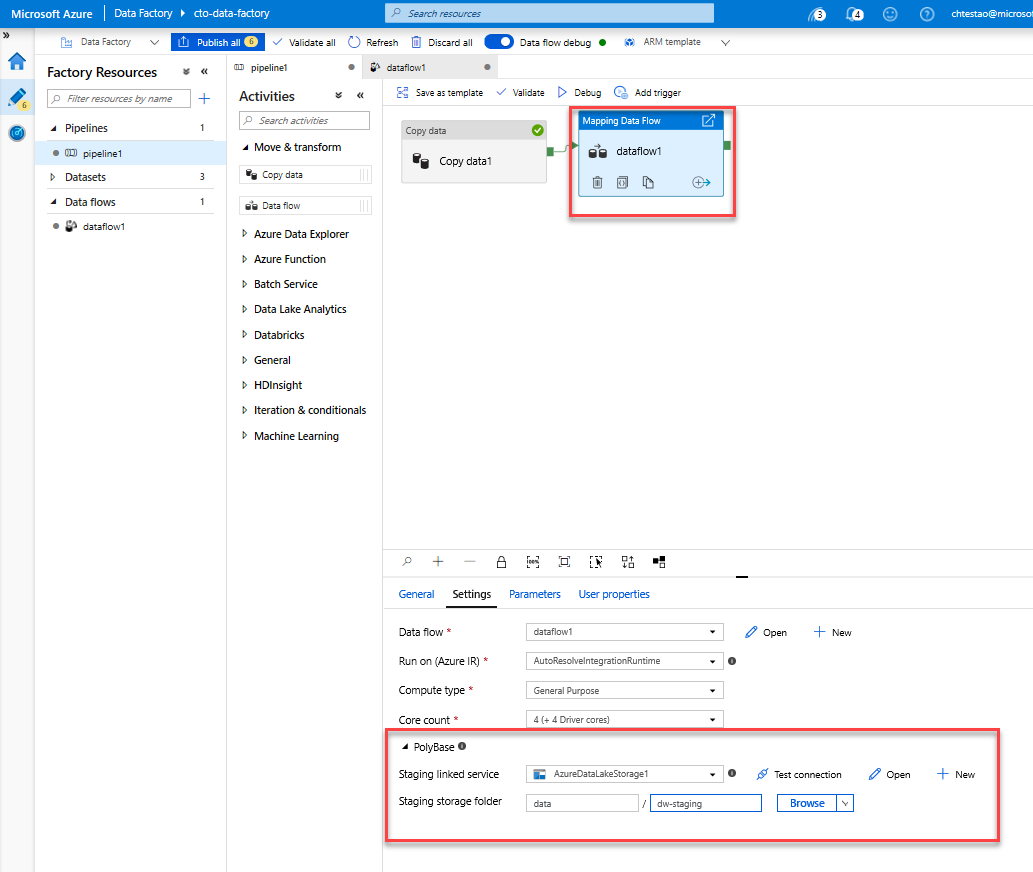
Przed opublikowaniem potoku uruchom kolejne uruchomienie debugowania, aby potwierdzić, że działa zgodnie z oczekiwaniami. Patrząc na kartę Dane wyjściowe, możesz monitorować stan obu działań w miarę ich uruchamiania.
Po pomyślnym zakończeniu obu działań możesz kliknąć ikonę okularów obok działania Przepływ danych, aby uzyskać bardziej szczegółowe spojrzenie na przebieg Przepływ danych.
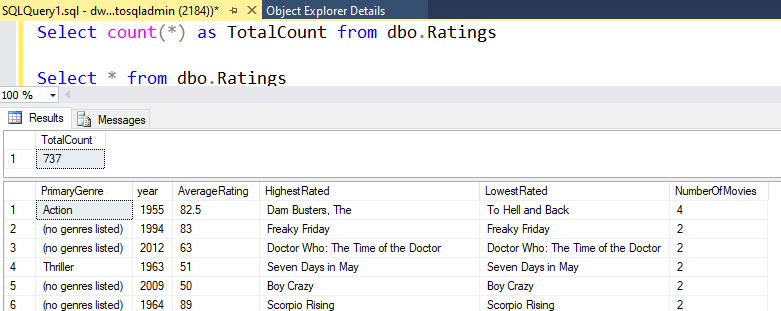
Jeśli w tym laboratorium użyto tej samej logiki, Przepływ danych napisze 737 wierszy do usługi SQL DW. Możesz przejść do programu SQL Server Management Studio , aby sprawdzić, czy potok działa prawidłowo i zobaczyć, co zostało napisane.