Ciclos de lançamento mais rápidos são uma das principais vantagens das arquiteturas de microsserviços. No entanto, sem um bom processo de CI/CD, você não obterá a agilidade que os microsserviços prometem. Este artigo descreve os desafios e recomenda algumas abordagens para o problema.
O que é CI/CD?
Quando falamos sobre CI/CD, realmente falamos sobre vários processos relacionados: integração contínua, entrega contínua e implantação contínua.
Integração contínua. As alterações de código são frequentemente mescladas na ramificação principal. Os processos de compilação e teste automatizados garantem que o código da ramificação principal tenha sempre a qualidade de produção.
Entrega contínua. Qualquer alteração de código transmitida no processo de CI são publicadas automaticamente em um ambiente semelhante à produção. A implantação no ambiente de produção dinâmico pode exigir aprovação manual, mas caso contrário, é automatizada. A meta é que o seu código esteja sempre pronto para implantação na produção.
Implantação contínua. As alterações de código que passam pelas duas etapas anteriores são implantadas automaticamente na produção.
Aqui estão algumas metas de um processo de CI/CD robusto para uma arquitetura de microsserviços:
Cada equipe pode criar e implantar os serviços que ela possui independentemente, sem afetar ou interromper outras equipes.
Antes de uma nova versão de um serviço ser implantada na produção, ela é implantada em ambientes de desenvolvimento/teste/garantia de qualidade para validação. Há restrições de qualidade impostas em cada estágio.
Uma nova versão de um serviço pode ser implantada lado a lado com a versão anterior.
Há políticas de controle de acesso suficientes em vigor.
Para cargas de trabalho conteinerizadas, você pode confiar nas imagens de contêiner que estão implantadas na produção.
Por que um pipeline robusto de CI/CD é importante
Em um aplicativo monolítico tradicional, há um único pipeline de compilação cuja saída é o executável do aplicativo. Todo o trabalho de desenvolvimento alimenta este pipeline. Se for encontrado um bug de alta prioridade, uma correção deverá ser integrada, testada e publicada, o que poderá atrasar o lançamento dos novos recursos. Você pode atenuar esses problemas com módulos bem fatorados e usando ramificações de recursos para minimizar o impacto de alterações de código. Mas conforme o aplicativo se torna mais complexo e mais recursos são adicionados, o processo de liberação para um monolito tende a se tornar mais frágil e suscetível a interrupção.
Seguindo a filosofia de microsserviços, nunca deverá haver uma versão de treinamento longa em que todas as equipes precisam se mobilizar. A equipe que cria o serviço "A" pode lançar uma atualização a qualquer momento, sem esperar que as alterações no serviço "B" sejam mescladas, testadas e implantadas.
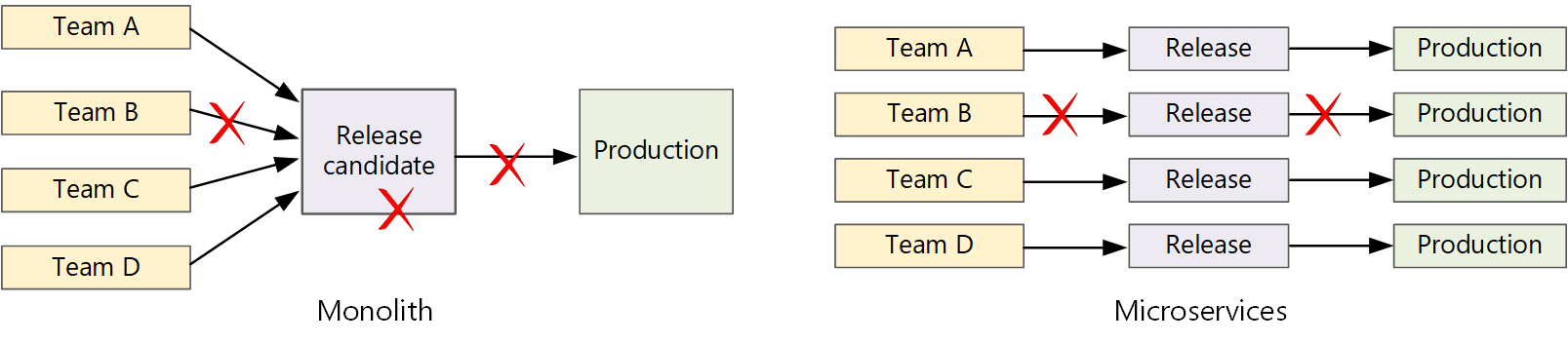
Para atingir uma alta velocidade de liberação, seu pipeline de liberação deve ser automatizado e ser altamente confiável para minimizar os riscos. Se você lançar para produção uma ou mais vezes ao dia, as regressões ou as interrupções de serviço deverão ser raras. Ao mesmo tempo, se uma atualização inválida é implantada, você deve ter uma maneira confiável de reverter ou efetuar roll forward rapidamente para uma versão anterior de um serviço.
Desafios
Várias bases de código pequenas independentes. Cada equipe é responsável por criar seu próprio serviço, com seu próprio pipeline de build. Em algumas organizações, as equipes podem usar repositórios de código separados. Repositórios separados podem levar a uma situação em que o conhecimento de como compilar o sistema é disseminado entre as equipes e ninguém na organização sabe como implantar o aplicativo inteiro. Por exemplo, o que acontecerá em um cenário de recuperação de desastre, se você precisar implantar rapidamente para um novo cluster?
Mitigação: tenha um pipeline unificado e automatizado para criar e implantar serviços para que esse conhecimento não fique "escondido" dentro de cada equipe.
Múltiplas linguagens de programação e estruturas. Com cada equipe usando seu próprio conjunto de tecnologias, pode ser difícil criar um processo de build único que funcione em toda a organização. O processo de build deve ser flexível o suficiente para que cada equipe possa adaptá-lo para sua linguagem de programação ou estrutura de preferência.
Mitigação: conteinerize o processo de compilação para cada serviço. Dessa forma, o sistema de compilação só precisa ser capaz de executar os contêineres.
Integração e teste de carga. Com as equipes de liberação de atualizações em seu próprio ritmo, pode ser difícil projetar testes de ponta a ponta robustos, especialmente quando os serviços têm dependências em outros serviços. Além disso, o processo de execução de um cluster de produção completo pode ser cara, portanto, é improvável que cada equipe execute seu próprio cluster completo em escalas de produção, apenas para teste.
Gerenciamento de versão. Cada equipe deve ter poder implantar uma atualização em produção. Isso não significa que cada membro da equipe tem permissões para fazer isso. Mas ter uma função de Gerenciador de Versão centralizada pode reduzir a velocidade das implantações.
Mitigação: quanto mais o processo de CI/CD for automatizado e confiável, menos deverá haver necessidade de uma autoridade central. Dito isso, você pode ter diferentes políticas para liberar atualizações dos principais recursos e correções de bugs secundários. Ser descentralizado não significa governança zero.
Atualizações de serviço. Quando você atualizar um serviço para uma nova versão, ele não deverá interromper outros serviços que dependem dele.
Mitigação: use técnicas de implantação, como liberação azul-verde ou canária, para alterações ininterruptas. Para quebrar as alterações da API, implante a nova versão lado a lado com a versão anterior. Dessa forma, os serviços que consomem a API anterior podem ser atualizados e testados para a nova API. Consulte Atualização de serviços, abaixo.
Repositório único versus vários repositórios
Antes de criar um fluxo de trabalho de CI/CD, você precisa saber como a base de código será estruturada e gerenciada.
- As equipes funcionam em repositórios separados ou em um repositório único?
- Qual é sua estratégia de ramificação?
- Quem pode efetuar push do código para a produção? Existe uma função de gerente de versão?
A abordagem de repositório único tem tido mais aceitação, mas há vantagens e desvantagens em ambas.
| Repositório único | Vários repositórios | |
|---|---|---|
| Vantagens | Compartilhamento de código Maior facilidade em padronizar o código e as ferramentas Maior facilidade em refatorar o código Detectabilidade – modo de exibição único do código |
Propriedade clara por equipe Possivelmente menos conflitos de mesclagem Ajuda a impor o desacoplamento de microsserviços |
| Desafios | As alterações no código compartilhado podem afetar vários microsserviços Maior potencial de conflitos de mesclagem As ferramentas devem ser dimensionadas para uma base de código grande Controle de acesso Processo de implantação mais complexo |
Mais difícil de compartilhar o código Mais difícil de impor padrões de codificação Gerenciamento de dependência Base de código difusa, baixa detectabilidade Falta de infraestrutura compartilhada |
Atualizando serviços
Há várias estratégias para atualizar um serviço que já está em produção. Aqui, abordamos três opções comuns: atualização sem interrupção, implantação "blue-green" e versão canário.
Atualizações sem interrupção
Em uma atualização sem interrupção, você implanta novas instâncias de um serviço e as novas instâncias começam a receber solicitações imediatamente. À medida que as novas instâncias chegam, as anteriores são removidas.
Exemplo. No Kubernetes, atualizações são o comportamento padrão quando você atualiza a especificação de pod para uma implantação. O controlador de implantação cria um novo ReplicaSet para os pods atualizados. Em seguida, ele expande o novo ReplicaSet e reduz simultaneamente o antigo, para manter a contagem de réplicas desejada. Ela não exclui os pods antigos até que os novos estejam prontos. O Kubernetes mantém um histórico da atualização, de modo que você possa reverter uma atualização se necessário.
Exemplo. O Azure Service Fabric usa a estratégia de atualização contínua por padrão. Essa estratégia é mais adequada para implantar uma versão de um serviço com novos recursos sem alterar as APIs existentes. O Service Fabric inicia uma implantação de atualização atualizando o tipo de aplicativo para um subconjunto dos nós ou um domínio de atualização. Em seguida, ele avança para o próximo domínio de atualização até que todos os domínios sejam atualizados. Se um domínio de atualização falhar ao atualizar, o tipo de aplicativo será revertido para a versão anterior em todos os domínios. Lembre-se de que um tipo de aplicativo com vários serviços (e se todos os serviços forem atualizados como parte de uma implantação de atualização) está propenso a falhas. Se um serviço não puder ser atualizado, o aplicativo inteiro será revertido para a versão anterior, e os outros serviços não serão atualizados.
Um desafio de reverter atualizações é que durante o processo de atualização uma mistura das versões antiga e nova estão em execução e recebendo tráfego. Durante esse período, qualquer solicitação poderia ser roteada para qualquer uma das duas versões.
Para quebrar alterações de API, uma boa prática é oferecer suporte a ambas as versões lado a lado, até que todos os clientes da versão anterior sejam atualizados. Consulte Controle de versão da API.
Implantação "blue-green"
Em uma implantação "blue-green", você deve implantar a nova versão juntamente com a versão anterior. Depois de validar a nova versão, você pode mudar todo o tráfego da versão anterior para a nova versão, de uma só vez. Após a troca, você deve monitorar o aplicativo para quaisquer problemas. Se algo der errado, você poderá retornar à versão antiga. Se nenhum problema ocorrer, você poderá excluir a versão antiga.
Com um aplicativo monolítico ou de N camadas mais tradicional, a implantação "blue-green" geralmente significa provisionar dois ambientes idênticos. Você implantaria a nova versão em um ambiente de preparo e então redirecionaria o tráfego de cliente para o ambiente de preparo, por exemplo, alternando VIPs. Em uma arquitetura de microsserviços, as atualizações ocorrem no nível de microsserviço, portanto, você normalmente implantaria a atualização no mesmo ambiente e usaria um mecanismo de descoberta de serviço para trocar.
Exemplo. No Kubernetes, você não precisa provisionar um cluster separado para fazer implantações "blue-green". Em vez disso, você pode tirar proveito de seletores. Crie um recurso de implantação com uma nova especificação de pod e um conjunto diferente de rótulos. Crie essa implantação sem excluir a implantação anterior nem modificar o serviço que aponta para ela. Quando os novo pods estiverem em execução, você poderá atualizar o seletor do serviço para corresponder à nova implantação.
Uma desvantagem da implantação azul-verde é que durante a atualização você executa o dobro de pods para o serviço (os atuais e os próximos). Se os pods exigirem muitos recursos de CPU ou de memória, talvez você precisará escalar horizontalmente o cluster temporariamente para dar conta do consumo de recursos.
Versão canário
Em uma versão canário, você distribui uma versão atualizada para um número pequeno de clientes. Em seguida, você monitora o comportamento do novo serviço antes de implantá-lo em todos os clientes. Isso lhe permite fazer uma distribuição lenta de forma controlada, observar dados reais e identificar problemas antes que todos os clientes sejam afetados.
Uma versão canário é mais complexa de gerenciar do que a atualização sem interrupção ou "blue-green", porque você deve rotear solicitações dinamicamente para diferentes versões do serviço.
Exemplo. No Kubernetes, você pode configurar um serviço para abranger dois conjuntos de réplicas (um para cada versão) e ajustar as contagens de réplicas manualmente. No entanto, essa abordagem tem uma granularidade bastante alta devido ao modo como o Kubernetes balanceia a carga entre os pods. Por exemplo, se você tiver um total de 10 réplicas, só poderá realizar deslocamentos de tráfego em incrementos de 10%. Se você estiver usando uma malha de serviço, poderá usar as regras de roteamento de malha do serviço para implementar uma estratégia de versão canário mais sofisticada.
Próximas etapas
- Roteiro de aprendizagem: definir e implementar a integração contínua
- Treinamento: introdução à entrega contínua
- Arquitetura de microsserviços
- Por que usar uma abordagem de microsserviços para criar aplicativos