Fazer fail over de um link - Instância Gerenciada de SQL do Azure
Aplica-se a: ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Este artigo ensina como fazer fail over de um banco de dados vinculado entre o SQL Server e a Instância Gerenciada de SQL do Azure usando o SQL Server Management Studio (SSMS) ou o PowerShell para fins de recuperação de desastres ou migração.
Pré-requisitos
Para fazer failover de bancos de dados para a réplica secundária por meio do link, é necessário ter os seguintes pré-requisitos:
- Uma assinatura ativa do Azure. Se você não tiver uma, crie uma conta gratuita.
- Versão com suporte do SQL Server com a atualização de serviço necessária instalada.
- Link configurado entre a réplica primária e secundária.
- É possível fazer failover do link ao usar Transact-SQL (atualmente em pré-visualização), começando com a atualização cumulativa 13 do SQL Server 2022 (KB5036432).
Parar carga de trabalho
Caso esteja pronto para fazer failover do seu banco de dados para a réplica secundária, primeiro interrompa todas as cargas de trabalho de aplicativos na réplica primária durante suas horas de manutenção. Isso permite que a replicação de banco de dados alcance a réplica secundária para que você possa fazer failover para ela sem perda de dados. É necessário garantir que os aplicativos não estejam realizando transações na réplica primária antes do failover.
Fazer failover de um banco de dados
É possível fazer failover de um banco de dados vinculado ao usar Transact-SQL (T-SQL), SQL Server Management Studio ou PowerShell.
É possível fazer failover do link ao usar Transact-SQL (atualmente em pré-visualização), começando com a atualização cumulativa 13 do SQL Server 2022 (KB5036432).
Para executar um failover planejado para um link, use o comando T-SQL apresentado a seguir na réplica primária:
ALTER AVAILABILITY GROUP [<DAGname>] FAILOVER
Para executar um failover forçado, use o comando T-SQL apresentado a seguir na réplica secundária:
ALTER AVAILABILITY GROUP [<DAGname>] FORCE_FAILOVER_ALLOW_DATA_LOSS
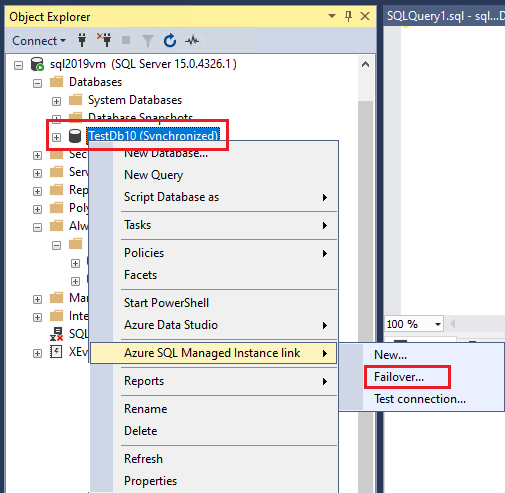
Ver banco de dados após failover
Para o SQL Server 2022, se você optar por manter o link, poderá verificar se o grupo de disponibilidade distribuída existe em Grupos de Disponibilidade no Pesquisador de Objetos no SQL Server Management Studio.
Se você descartou o link durante o failover, poderá usar o Pesquisador de Objetos para confirmar que o grupo de disponibilidade distribuída não existe mais. Se você optar por manter o grupo de disponibilidade, o banco de dados ainda será Sincronizado.
Limpar após o failover
A menos que a opção Remover link após failover bem-sucedido seja selecionada, o failover com SQL Server 2022 não quebra o link. Você pode manter o link após o failover, o que mantém o grupo de disponibilidade e o grupo de disponibilidade distribuído ativos. Nenhuma outra ação é necessária.
Descartar o link apenas descarta o grupo de disponibilidade distribuído e deixa o grupo de disponibilidade ativo. Você pode decidir manter o grupo de disponibilidade ou descartá-lo.
Se você decidir descartar seu grupo de disponibilidade, substitua o seguinte valor e execute o código de T-SQL de exemplo:
<AGName>com o nome do grupo de disponibilidade no SQL Server (usado para criar o link).
-- Run on SQL Server
USE MASTER
GO
DROP AVAILABILITY GROUP <AGName>
GO
Estado inconsistente após failover forçado
Após um failover forçado, você pode encontrar um cenário de cérebro dividido em que ambas as réplicas estão na função principal, deixando o link em um estado inconsistente. Isso poderá acontecer se você fizer failover para a réplica secundária durante um desastre e, em seguida, a réplica primária voltar a ficar online.
Primeiro, confirme se você está em um cenário de cérebro dividido. É possível fazer isso usando o SSMS (SQL Server Management Studio) ou Transact-SQL (T-SQL).
Conecte-se ao SQL Server e à instância gerenciada de SQL no SSMS e, em seguida, no Pesquisador de Objetos, expanda Réplicas de disponibilidade no nó Grupo de disponibilidade em Alta Disponibilidade sempre ativada. Se duas réplicas diferentes estiverem listadas como (Primárias), você estará em um cenário de cérebro dividido.
Como alternativa, você pode executar o seguinte script T-SQL no SQL Server e na Instância Gerenciada de SQL para verificar a função das réplicas:
-- Execute on SQL Server and SQL Managed Instance
declare @link_name varchar(max) = '<DAGName>'
USE MASTER
GO
SELECT
ag.name [Link name],
rs.role_desc [Link role]
FROM
sys.availability_groups ag
join sys.dm_hadr_availability_replica_states rs
on ag.group_id = rs.group_id
WHERE
rs.is_local = 1 and ag.name = @link_name
GO
Se ambas as instâncias listarem uma Primária diferente na coluna Função do link, você estará em um cenário de cérebro dividido.
Para resolver o estado de cérebro dividido, primeiro faça um backup da réplica que era a primária original. Se a primária original era SQL Server, faça um backup da parte final do log. Se a primária original era Instância Gerenciada de SQL, faça um backup completo somente cópia. Após a conclusão do backup, defina o grupo de disponibilidade distribuído como a função secundária para a réplica que costumava ser a primária original, mas que agora será a nova secundária.
Por exemplo, no caso de um desastre real, supondo que você tenha forçado um failover da carga de trabalho do SQL Server para a Instância Gerenciada de SQL do Azure e pretenda continuar executando sua carga de trabalho na Instância Gerenciada de SQL, faça um backup da parte final do log no SQL Server e defina o grupo de disponibilidade distribuído para a função secundária no SQL Server, como no exemplo a seguir:
--Execute on SQL Server
USE MASTER
ALTER availability group [<DAGName>]
SET (role = secondary)
GO
Em seguida, execute um failover manual planejado da Instância Gerenciada de SQL para o SQL Server usando o link, como no exemplo a seguir:
--Execute on SQL Managed Instance
USE MASTER
ALTER availability group [<DAGName>] FAILOVER
GO
Conteúdo relacionado
Para obter mais informações sobre o recurso de link, veja os seguintes artigos: