Melhores práticas de configuração de HADR (SQL Server em VMs do Azure)
Aplicável a:![]() SQL Server na VM do Azure
SQL Server na VM do Azure
Um Cluster de failover do Windows Server é usado para HADR (alta disponibilidade e recuperação de desastre) com o SQL Server em VMs (Máquinas Virtuais) do Azure.
Este artigo fornece as melhores práticas de configuração do cluster para FCIs (instâncias de cluster de failover) e grupos de disponibilidade quando você as usa com o SQL Server em VMs do Azure.
Para saber mais, confira os outros artigos desta série: Lista de verificação, Tamanho da VM, Armazenamento, Segurança, Configuração de HADR e Coletar linha de base.
Lista de verificação
Examine a lista de verificação a seguir para ter uma breve visão geral das melhores práticas de HADR abordadas mais detalhadamente no restante do artigo.
Os recursos de HADR (alta disponibilidade e recuperação de desastre), como o Grupos de Disponibilidade AlwaysOn e a instância de cluster de failover, dependem da tecnologia subjacente de cluster de failover do Windows Server. Examine as melhores práticas para modificar as configurações do HADR para dar melhor suporte ao ambiente de nuvem.
Para o seu cluster do Windows, considere estas práticas recomendadas:
- Implante suas VMs do SQL Server em várias sub-redes sempre que possível para evitar a dependência de um Azure Load Balancer ou um DNN (nome de rede distribuída) para rotear o tráfego para a solução de HADR.
- Altere o cluster para parâmetros menos agressivos para evitar interrupções inesperadas devido a falhas de rede transitórias ou manutenção da plataforma do Azure. Para saber mais, confira configurações de pulsação e limite. Para o Windows Server 2012 e versões posteriores, use os seguintes valores recomendados:
- SameSubnetDelay: 1 segundo
- SameSubnetThreshold: 40 pulsações
- CrossSubnetDelay: 1 segundo
- CrossSubnetThreshold: 40 pulsações
- Coloque suas VMs em um conjunto de disponibilidade ou em zonas de disponibilidade diferentes. Para saber mais, confira configurações de disponibilidade da VM.
- Use uma única NIC por nó de cluster.
- Configure a votação de quorum do cluster para usar um número ímpar de três votos ou mais. Não atribua votos a regiões de DR.
- Monitore cuidadosamente os limites de recursos para evitar reinicializações ou failovers inesperados devido a restrições de recursos.
- Verifique se o sistema operacional, drivers de SO e SQL Server estão nos builds mais recentes.
- Otimize o desempenho para SQL Server em VMs do Azure. Examine as outras seções deste artigo para saber mais.
- Reduza ou distribua a carga de trabalho para evitar limites de recursos.
- Mova para uma VM ou disco com limites mais altos para evitar restrições.
Para seu grupo de disponibilidade SQL Server ou instância de cluster de failover, considere estas melhores práticas:
- Se você estiver enfrentando falhas inesperadas frequentes, siga as melhores práticas de desempenho descritas no restante deste artigo.
- Se a otimização do desempenho da VM do SQL Server não resolver os failovers inesperados, considere reduzir o monitoramento do grupo de disponibilidade ou da instância de cluster de failover. No entanto, isso pode não tratar da origem subjacente do problema e pode mascarar os sintomas ao reduzir a probabilidade de falha. Talvez você ainda precise investigar e resolver a causa raiz subjacente. Para o Windows Server 2012 ou superior, use os seguintes valores recomendados:
- Tempo limite de concessão: use essa equação para calcular o valor máximo de tempo limite de concessão:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Comece com 40 segundos. Se você estiver usando os valoresSameSubnetThresholdeSameSubnetDelayreduzidos recomendados anteriormente, não exceda 80 segundos no valor de tempo limite de concessão. - Máximo de falhas em um período especificado: defina esse valor como 6.
- Tempo limite de concessão: use essa equação para calcular o valor máximo de tempo limite de concessão:
- Ao usar o VNN (nome da rede virtual) e um Azure Load Balancer para se conectar à solução de HADR, especifique
MultiSubnetFailover = truena cadeia de conexão, mesmo que o cluster abranja apenas uma sub-rede.- Se o cliente não der suporte a
MultiSubnetFailover = True, poderá ser necessário definirRegisterAllProvidersIP = 0eHostRecordTTL = 300para armazenar as credenciais do cliente em cache em caso de durações mais curtas. No entanto, isso pode causar consultas adicionais ao servidor DNS.
- Se o cliente não der suporte a
- Para se conectar à sua solução de HADR usando o nome de rede distribuída (DNN), considere o seguinte:
- Você deve usar um driver de cliente que dê suporte ao
MultiSubnetFailover = Truee esse parâmetro deve estar na cadeia de conexão. - Use uma porta DNN exclusiva na cadeia de conexão ao conectar-se ao ouvinte DNN para um grupo de disponibilidade.
- Você deve usar um driver de cliente que dê suporte ao
- Use uma cadeia de conexão de espelhamento de banco de dados para um grupo de disponibilidade básico para ignorar a necessidade de um balanceador de carga ou DNN.
- Valide o tamanho do setor de seus VHDs antes de implantar sua solução de alta disponibilidade para evitar ter E/Ss desalinhadas. Confira KB3009974 para saber mais.
- Se o mecanismo de banco de dados do SQL Server, o ouvinte do grupo de disponibilidade Always On ou a investigação de integridade da instância de cluster de failover estiver configurado para usar uma porta entre 49.152 e 65.536 (o intervalo de portas dinâmicas padrão para TCP/IP), adicione uma exclusão para cada porta. Isso impedirá que outros sistemas sejam atribuídos dinamicamente à mesma porta. O exemplo a seguir cria uma exclusão para a porta 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Para comparar a lista de verificação de HADR com as outras melhores práticas, confira a Lista de verificação de melhores práticas de desempenho completa.
Configurações de disponibilidade da VM
Para reduzir o efeito do tempo de inatividade, considere as seguintes configurações de melhor disponibilidade da VM:
- Use grupos de posicionamento por proximidade com a rede acelerada para ter a menor latência.
- Coloque nós de cluster da máquina virtual em zonas de disponibilidade separadas para proteger contra falhas no nível do datacenter ou em um só conjunto de disponibilidade para ter redundância de menor latência no mesmo datacenter.
- Use um sistema operacional gerenciado premium e discos de dados para VMs em um conjunto de disponibilidade.
- Configure cada camada de aplicativo em conjuntos de disponibilidade separados.
Quorum
Embora um cluster de dois nós funcione sem um recurso de quorum, é estritamente necessário que os clientes usem um recurso de quórum para ter suporte de produção. A validação do cluster não passa por nenhum cluster sem um recurso de quorum.
Tecnicamente, um cluster de três nós pode sobreviver a uma única perda de nó (até dois nós) sem um recurso de quorum, mas depois que o cluster for reduzido a dois nós, se houver outra perda de nó ou falha de comunicação, haverá o risco de que os recursos clusterizados fiquem offline para evitar um cenário de dupla personalidade. A configuração de um recurso de quorum permite que o cluster continue online com apenas um nó on-line.
A testemunha de disco é a opção de quorum mais resiliente. Porém, para usar uma testemunha de disco em um SQL Server na VM do Azure, você deve usar um disco compartilhado do Azure, o que impõe algumas limitações à solução de alta disponibilidade. Dessa forma, use uma testemunha de disco quando estiver configurando a instância de cluster de failover com os discos compartilhados do Azure. Caso contrário, use uma testemunha de nuvem sempre que possível.
A seguinte tabela lista as opções de quorum disponíveis para o SQL Server em VMs do Azure:
| Testemunha da nuvem | Testemunha de disco | Testemunha de compartilhamento de arquivos | |
|---|---|---|---|
| SO com suporte | Windows Server 2016 e posterior | Tudo | Todos |
- Uma testemunha de nuvem é ideal para implantações em vários sites, várias zonas e várias regiões. Use uma testemunha de nuvem sempre que possível, a menos que esteja usando uma solução de cluster com armazenamento compartilhado.
- A testemunha de disco é a opção de quorum mais resiliente e é preferencial para qualquer cluster que usa discos compartilhados do Azure (ou qualquer solução de disco compartilhado, como SCSI compartilhado, iSCSI ou SAN de canal de fibra). Um volume compartilhado em cluster não pode ser usado como testemunha de disco.
- A testemunha de compartilhamento de arquivos é adequada para quando a testemunha de disco e a testemunha de nuvem não estão disponíveis.
Para começar, confira Configurar o quorum do cluster.
Votação de quorum
É possível alterar o voto de quorum de um nó que participa de um Cluster de Failover do Windows Server.
Ao modificar as configurações de voto do nó, siga estas diretrizes:
| Diretrizes de votação por quorum |
|---|
| Comece com cada nó sem nenhum voto por padrão. Cada nó deve ter apenas um voto com justificativa explícita. |
| Habilita votos para nós de cluster que hospedam a réplica primária de um grupo de disponibilidade ou os proprietários preferenciais de uma instância de cluster de failover. |
| Habilitar votos para proprietários de failover automático. Cada nó que pode hospedar uma réplica primária ou FCI como resultado de um failover automático deve ter um voto. |
| Se um grupo de disponibilidade tiver mais de uma réplica secundária, habilite votos apenas para as réplicas que têm failover automático. |
| Desabilite votos para nós que estão em sites secundários de recuperação de desastre. Nós em sites secundários não devem contribuir para a decisão de colocar um cluster offline se não houver nada de errado com o site primário. |
| Tenha um número ímpar de votos, com no mínimo três votos de quorum. Adicione uma testemunha de quorum para um voto extra, se necessário, em um cluster de dois nós. |
| Reavalie as atribuições de voto após o failover. Você não deseja fazer failover em uma configuração de cluster que não é compatível com um quorum íntegro. |
Conectividade
Para corresponder à experiência local de conexão à instância de cluster de failover ou ao ouvinte do grupo de disponibilidade, implante as VMs do SQL Server em várias sub-redes na mesma rede virtual. Com várias sub-redes, não é preciso ter dependência extra em um Azure Load Balancer ou um nome de rede distribuída para rotear o tráfego para o ouvinte.
Para simplificar a solução de HADR, implante as VMs do SQL Server em várias sub-redes sempre que possível. Para saber mais, confira AG de várias sub-redes e FCI de várias sub-redes.
Se as VMs do SQL Server estiverem em uma única sub-rede, será possível configurar um VNN (nome de rede virtual) e um Azure Load Balancer ou um DNN (nome de rede distribuída) para as instâncias de cluster de failover e os ouvintes do grupo de disponibilidade.
O nome da rede distribuída é a opção de conectividade recomendada quando disponível:
- A solução de ponta a ponta é mais robusta, pois você não precisa mais manter o recurso de balanceador de carga.
- A eliminação das investigações do balanceador de carga minimiza a duração do failover.
- O DNN simplifica o provisionamento e o gerenciamento da instância de cluster de failover ou do ouvinte do grupo de disponibilidade com o SQL Server em VMs do Azure.
Considere as seguintes limitações:
- O driver do cliente deve dar suporte ao parâmetro
MultiSubnetFailover=True. - O recurso de DNN está disponível a partir do SQL Server 2016 SP3, do SQL Server 2017 CU25 e do SQL Server 2019 CU8 no Windows Server 2016 e posterior.
Para saber mais, confira a Visão geral do Cluster de Failover do Windows Server.
Para configurar a conectividade, confira os seguintes artigos:
- Grupo de disponibilidade: Configurar a DNN, Configurar a VNN
- Instância de cluster de failover: Configurar a DNN, Configurar a VNN.
A maioria dos recursos do SQL Server funciona de maneira transparente com a FCI e os grupos de disponibilidade quando o DNN é usado, mas há alguns recursos que podem exigir consideração especial. Confira Interoperabilidade da FCI e do DNN e Interoperabilidade do AG e do DNN para saber mais.
Dica
Defina o parâmetro MultiSubnetFailover = true na cadeia de conexão, mesmo em soluções de HADR que abranjam uma única sub-rede, para dar suporte a futuras continuações de sub-redes sem precisar atualizar as cadeias de conexão.
Pulsação e limite
Altere as configurações de pulsação e limite do cluster para ter configurações relaxadas. As configurações padrão do cluster de pulsação e limite são projetadas para redes locais altamente ajustadas e não consideram a possibilidade de aumento da latência em um ambiente de nuvem. A rede de pulsação é mantida com o UDP 3343, que tradicionalmente é muito menos confiável do que o TCP e mais propenso a conversas incompletas.
Portanto, ao executar nós de cluster para o SQL Server em soluções de alta disponibilidade de VM do Azure, altere as configurações do cluster para um estado de monitoramento mais relaxado para evitar falhas transitórias devido à maior possibilidade de falha ou latência de rede, manutenção do Azure ou surgimento de gargalos de recursos.
As configurações de atraso e limite têm efeito cumulativo para a detecção da integridade total. Por exemplo, definir CrossSubnetDelay para enviar uma pulsação a cada 2 segundos e definir CrossSubnetThreshold como 10 pulsações perdidas antes de fazer a recuperação significa que o cluster pode ter uma tolerância de rede total de 20 segundos antes que uma ação de recuperação seja executada. Em geral, é preferível continuar enviado pulsações frequentes, mas ter limites maiores.
Para garantir a recuperação durante interrupções legítimas enquanto fornece maior tolerância para problemas transitórios, relaxe suas configurações de atraso e limite para os valores recomendados detalhados na seguinte tabela:
| Configuração | Windows Server 2012 ou posterior | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 segundo | 2 segundos |
| SameSubnetThreshold | 40 pulsações | 10 pulsações (máx.) |
| CrossSubnetDelay | 1 segundo | 2 segundos |
| CrossSubnetThreshold | 40 pulsações | 20 pulsações (máx.) |
Use o PowerShell para alterar os parâmetros do cluster:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Use o PowerShell para verificar suas alterações:
get-cluster | fl *subnet*
Considere o seguinte:
- Essa alteração é imediata, não é necessário reiniciar o cluster ou qualquer recurso.
- Os mesmos valores da sub-rede não devem ser maiores que valores da sub-rede cruzada.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Escolha valores relaxados com base em quanto tempo de inatividade é tolerável e quanto tempo antes que uma ação corretiva deva ocorrer dependendo de seu aplicativo, das necessidades empresariais e de seu ambiente. Se não for possível ultrapassar os valores padrão do Windows Server 2019, pelo menos tente igualá-los, se possível:
Para referência, a seguinte tabela detalha os valores padrão:
| Configuração | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 segundo | 1 segundo | 1 segundo |
| SameSubnetThreshold | 20 pulsações | 10 pulsações | 5 pulsações |
| CrossSubnetDelay | 1 segundo | 1 segundo | 1 segundo |
| CrossSubnetThreshold | 20 pulsações | 10 pulsações | 5 pulsações |
Para saber mais, confira Ajustando Limites de Rede do Cluster de Failover.
Monitoramento relaxado
Se o ajuste das configurações de pulsação e limite do cluster conforme recomendado proporcionar tolerância insuficiente e você ainda tiver failovers devido a problemas transitórios em vez de interrupções reais, será possível configurar seu monitoramento de AG ou FCI para ser mais ameno. Em alguns cenários, pode ser benéfico relaxar temporariamente o monitoramento por um determinado período dado o nível de atividade. Por exemplo, talvez você queira relaxar o monitoramento quando estiver trabalhando com cargas de trabalho com uso intensivo de E/S, como backups do banco de dados, manutenção de índice, DBCC CHECKDB etc. Quando a atividade for concluída, configure o monitoramento com valores menos relaxados.
Aviso
A alteração dessas configurações pode mascarar um problema subjacente e deve ser usada como uma solução temporária para reduzir, e não eliminar, a probabilidade de falha. Problemas subjacentes ainda devem ser investigados e resolvidos.
Comece aumentando os seguintes parâmetros de seus valores padrão para ter um monitoramento relaxado e ajuste conforme necessário:
| Parâmetro | Valor padrão | Valor relaxado | Descrição |
|---|---|---|---|
| Tempo limite de HealthCheck | 30000 | 60000 | Determina a integridade do nó ou da réplica primária. A DLL de recurso de cluster sp_server_diagnostics retorna resultados em um intervalo igual a 1/3 do limite de tempo limite da verificação de integridade. Se sp_server_diagnostics estiver lento ou não estiver retornando informações, a DLL de recurso aguardará todo o intervalo do limite de tempo limite da verificação de integridade antes de determinar que o recurso não está respondendo e iniciar um failover automático, se configurado para isso. |
| Nível da condição de falha | 3 | 2 | Condições que disparam um failover automático. Há cinco níveis da condição de falha, que variam do menos restritivo (nível um) até o mais restritivo (nível cinco) |
Use Transact-SQL (T-SQL) para modificar a verificação de integridade e as condições de falha para AGs e FCIs.
Para grupos de disponibilidade:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Para instâncias de cluster de failover:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Específico para os grupos de disponibilidade, comece com os seguintes parâmetros recomendados e ajuste conforme necessário:
| Parâmetro | Valor padrão | Valor relaxado | Descrição |
|---|---|---|---|
| Tempo limite de concessão | 20000 | 40000 | Impede dupla personalidade. |
| Tempo limite da sessão | 10000 | 20000 | Verifica problemas de comunicação entre as réplicas. O período de tempo limite da sessão é uma propriedade de réplica que controla quanto tempo (em segundos) uma réplica de disponibilidade espera por uma resposta de ping de uma réplica conectada antes de considerar que ocorreu uma falha na conexão. Por padrão, uma réplica espera 10 segundos por uma resposta de ping. Essa propriedade de réplica aplica-se apenas à conexão entre uma determinada réplica secundária e a réplica primária do grupo de disponibilidade. |
| Máximo de falhas no período especificado | 2 | 6 | Usado para evitar a movimentação indefinida de um recurso clusterizado dentro de falhas de vários nós. Um valor muito baixo pode fazer com que o grupo de disponibilidade entre em estado de falha. Aumente o valor para evitar pequenas interrupções causadas por problemas de desempenho, uma vez que um valor muito baixo pode fazer com que o AG entre em estado de falha. |
Antes de fazer qualquer alteração, considere o seguinte:
- Não reduza nenhum valor de tempo limite abaixo dos valores padrão.
- Use essa equação para calcular o valor máximo do tempo limite de concessão:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Comece com 40 segundos. Se você estiver usando os valoresSameSubnetThresholdeSameSubnetDelayreduzidos recomendados anteriormente, não exceda 80 segundos no valor de tempo limite de concessão. - Para réplicas com confirmação síncrona, alterar o tempo limite da sessão para um valor alto pode aumentar espera de HADR_sync_commit.
Tempo limite de concessão
Use o Gerenciador de Cluster de Failover para modificar as configurações de tempo limite de concessão para seu grupo de disponibilidade. Confira a documentação da verificação de integridade da concessão do grupo de disponibilidade do SQL Server para conhecer as etapas detalhadas.
Tempo limite da sessão
Use Transact-SQL (T-SQL) para modificar o tempo limite da sessão para um grupo de disponibilidade:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Máximo de falhas no período especificado
Use o Gerenciador de Cluster de Failover para modificar o valor de Máximo de falhas no período especificado:
- Selecione Funções no painel de navegação.
- Em Funções, clique com o botão direito do mouse no recurso clusterizado e escolha Propriedades.
- Selecione a guia Failover e aumente valor de Máximo de falhas no período especificado conforme desejado.
Limites de recursos
Os limites de VM ou disco podem levar a um gargalo de recursos que afeta a integridade do cluster e impede a verificação de integridade. Se você estiver enfrentando problemas com limites de recursos, considere o seguinte:
- Verifique se o sistema operacional, drivers de SO e SQL Server estão nos builds mais recentes.
- Otimize o SQL Server no ambiente de VM do Azure conforme descrito nas diretrizes de desempenho para o SQL Server em Máquinas Virtuais do Azure
- Reduza ou distribua a carga de trabalho para reduzir a utilização sem exceder os limites de recursos
- Ajuste a carga de trabalho do SQL Server se houver alguma oportunidade, como
- Adicionar/otimizar índices
- Atualizar estatísticas, se necessário e se possível, com uma verificação completa
- Usar recursos como o Resource Governor (começando com o SQL Server 2014, somente Enterprise) para limitar a utilização de recursos durante cargas de trabalho específicas, como backups ou manutenção de índice.
- Mova para uma VM ou disco que tenha limites mais altos para atender ou ultrapassar as demandas de sua carga de trabalho.
Rede
Implante suas VMs do SQL Server em várias sub-redes sempre que possível para evitar a dependência de um Azure Load Balancer ou um DNN (nome de rede distribuída) para rotear o tráfego para a solução de HADR.
Use uma única NIC por servidor (nó de cluster). A Rede do Azure tem redundância física, o que torna desnecessárias as NICs adicionais em um cluster convidado de uma máquina virtual do Azure. O relatório de validação de cluster avisa que os nós podem ser acessados apenas em uma rede. Você pode ignorar esse aviso em clusters de failover convidados de uma máquina virtual do Azure.
Os limites de largura de banda para uma VM específica são compartilhados entre NICs, e adicionar uma NIC adicional não melhora o desempenho do grupo de disponibilidade para SQL Server em VMs do Azure. Assim, não é necessário adicionar uma segunda NIC.
O serviço DHCP não compatível com RFC no Azure pode fazer com que a criação de determinadas configurações de cluster de failover falhe. Essa falha ocorre porque o nome de rede do cluster recebe um endereço IP duplicado, como o mesmo endereço IP de um dos nós do cluster. Isso é um problema quando você usa grupos de disponibilidade, que dependem do recurso de cluster de failover do Windows.
Considere o cenário onde um cluster de dois nós é criado e colocado online:
- O cluster fica online e o NODE1 solicita um endereço IP atribuído dinamicamente ao nome de rede de cluster.
- O serviço DHCP não dá nenhum endereço IP que não seja o próprio endereço IP do NODE1, porque o serviço DHCP reconhece a solicitação vem do próprio NODE1.
- O Windows detecta que um endereço duplicado é atribuído ao NODE1 e ao nome da rede de cluster de failover, e o grupo de clusters padrão não fica online.
- O grupo de clusters padrão é movido para o NODE2. O NODE2 trata o endereço IP do NODE1 como o endereço IP do cluster e coloca o grupo de clusters padrão online.
- Quando o NODE2 tenta estabelecer conectividade com o NODE1, pacotes direcionados ao NODE1 nunca deixam o NODE2, pois ele resolve o endereço IP do NODE1 para si mesmo. O NODE2 não pode estabelecer conectividade com o NODE1 e por isso perde quorum e fecha o cluster.
- O NODE1 pode enviar pacotes para o NODE2, mas o NODE2 não pode responder. O NODE1 perde quorum e fecha o cluster.
Você pode evitar esse cenário atribuindo um endereço IP estático não usado ao nome da rede de cluster para colocar o nome da rede de cluster online e adicionar o endereço IP ao Azure Load Balancer.
Se o mecanismo de banco de dados do SQL Server, o ouvinte do grupo de disponibilidade Always On, a investigação de integridade da instância de cluster de failover, o ponto de extremidade do espelhamento de banco de dados, o principal recurso de IP do cluster ou qualquer outro recurso do SQL estiver configurado para usar uma porta entre 49.152 e 65.536 (o intervalo de portas dinâmicas padrão para TCP/IP), adicione uma exclusão para cada porta. Isso evita que outros processos do sistema sejam atribuídos dinamicamente à mesma porta. O exemplo a seguir cria uma exclusão para a porta 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
É importante configurar a exclusão de portas quando a porta não está em uso. Caso contrário, o comando falhará com uma mensagem como "O processo não pode acessar o arquivo porque ele está sendo usado por outro processo".
Para confirmar se as exclusões foram configuradas corretamente, use o seguinte comando: netsh int ipv4 show excludedportrange tcp.
Definir essa exclusão para a porta de investigação de IP da função do grupo de disponibilidade deve impedir eventos como o Evento ID: 1069 com status 10048. Esse evento pode ser visto nos eventos do cluster de failover do Windows com a seguinte mensagem:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Isso pode ser causado por um processo interno que usa a mesma porta definida como porta de investigação. Lembre-se de que a porta de investigação é usada para verificar o status de uma instância do pool de back-end do Azure Load Balancer.
Se a investigação de integridade falhar ao obter uma resposta de uma instância de back-end, nenhuma conexão nova será enviada para essa instância de back-end até que a investigação de integridade seja bem-sucedida novamente.
Problemas conhecidos
Examine as resoluções de alguns problemas e erros mais conhecidos.
A contenção de recursos (E/S em particular) causa failover
Esgotar a capacidade de E/S ou da CPU na VM pode fazer com que o grupo de disponibilidade faça failover. Identificar a contenção que ocorre logo antes do failover é a maneira mais confiável de identificar o que está causando o failover automático. Monitore as Máquinas Virtuais do Azure para examinar as métricas de Utilização de E/S de Armazenamento para entender a latência de nível de disco ou da VM.
Siga estas etapas para examinar o evento Esgotamento Geral de E/S da VM do Azure:
Navegue até sua Máquina Virtual no portal do Azure, e não até Máquinas virtuais do SQL.
Selecione Métricas em Monitoramento para abrir a página Métricas.
Selecione Hora local para especificar o intervalo de tempo no qual você está interessado e o fuso horário, local para a VM ou UTC/GMT.
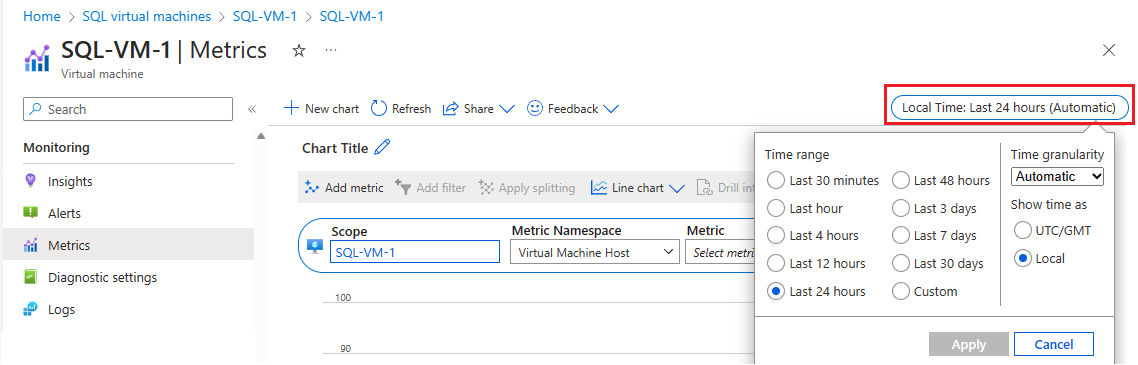
Selecione Adicionar métrica para adicionar as duas métricas a seguir para ver o grafo:
- Percentual Consumido de Largura de Banda Armazenada em Cache da VM
- Percentual Consumido de Largura de Banda Não Armazenada em Cache da VM
HostEvents da VM do Azure causam failover
É possível que um HostEvent da VM do Azure cause o failover do grupo de disponibilidade. Se você acredita que um HostEvent da VM do Azure causou o failover, verifique o log de atividades do Azure Monitor e a visão geral do Resource Health da VM do Azure.
O log de atividades do Azure Monitor é um log de plataforma no Azure que fornece informações sobre eventos em nível de assinatura. O log de atividades inclui informações como quando um recurso é modificado ou quando uma máquina virtual é iniciada. Você pode visualizar o log de atividades no portal do Azure ou recuperar entradas com o PowerShell e a CLI do Azure.
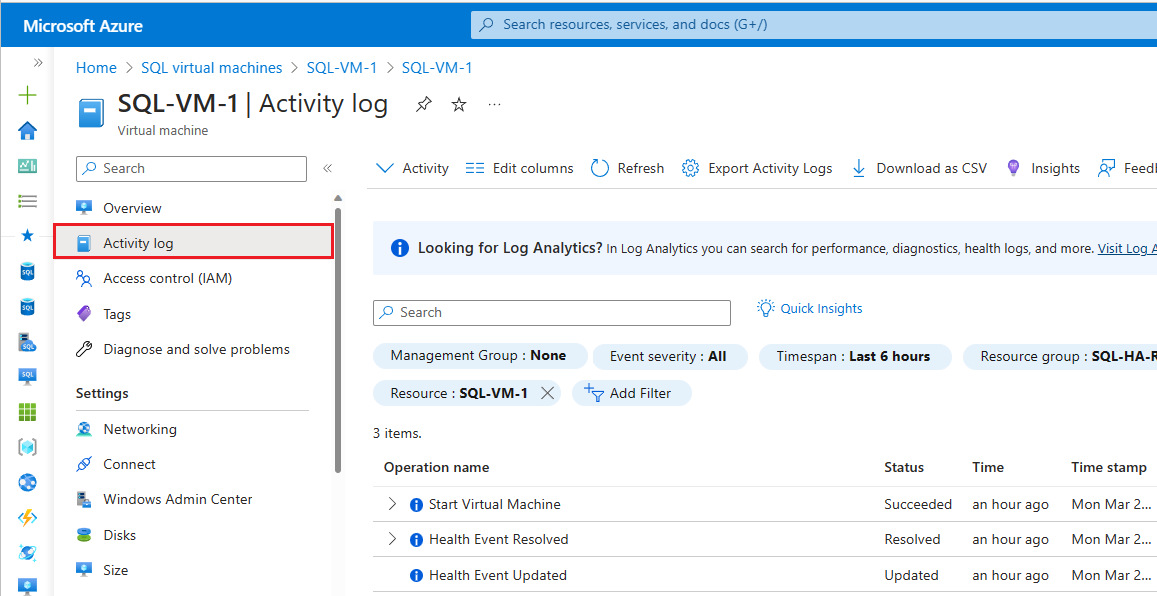
Para verificar o log de atividades do Azure Monitor, siga estas etapas:
Navegue até a Máquina Virtual no portal do Azure
Selecione Log de Atividades no painel Máquina virtual
Selecione Intervalo de tempo e escolha o período em que o grupo de disponibilidade fez failover. Escolha Aplicar.
Se o Azure tiver mais informações sobre a causa raiz de uma indisponibilidade iniciada pela plataforma, essas informações poderão ser postadas na página de visão geral VM do Azure – Resource Health até 72 horas após a indisponibilidade inicial. Essas informações estão disponíveis somente para máquinas virtuais no momento.
- Navegue até a Máquina Virtual no portal do Azure
- Selecione Resource Health no painel Integridade.
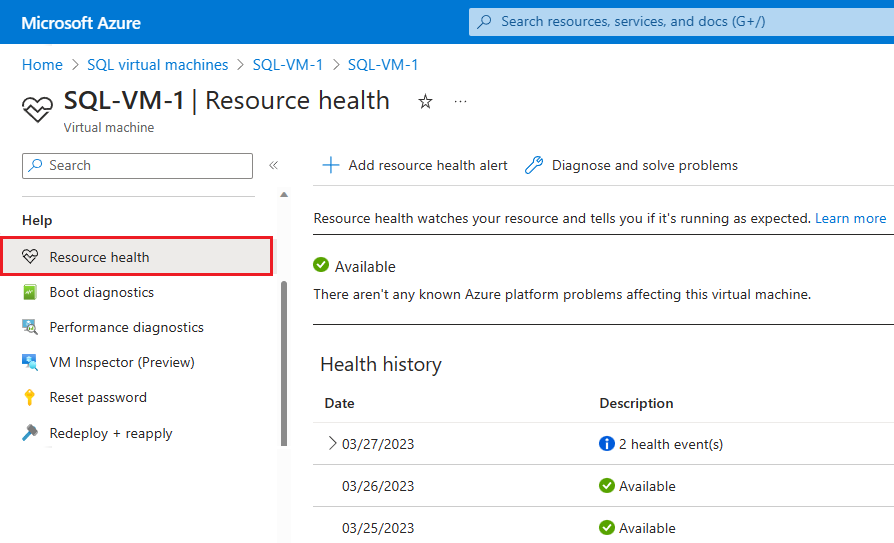
Você também pode configurar alertas com base em eventos de integridade nesta página.
Nó de cluster removido da associação
Se as configurações de pulsação e limite do Cluster Windows forem muito agressivas para seu ambiente, você poderá ver a mensagem a seguir no log de eventos do sistema com frequência.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Para obter mais informações, confira Solucionar problema de cluster com a ID de Evento 1135.
Concessão expirada / A concessão não é mais válida
Se o monitoramento for muito agressivo para seu ambiente, você poderá ver reinicializações, falhas ou failovers frequentes do grupo de disponibilidade ou FCI. Além disso, para grupos de disponibilidade, você poderá ver as seguintes mensagens no log de erros do SQL Server:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Tempo limite da conexão
Se o tempo limite da sessão for muito agressivo para seu ambiente de grupo de disponibilidade, você poderá ver as seguintes mensagens com frequência:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
O grupo não está fazendo failover
Se o valor de Máximo de Falhas no Período Especificado for muito baixo e você estiver enfrentando falhas intermitentes devido a problemas transitórios, seu grupo de disponibilidade poderá terminar em um estado de falha. Aumente esse valor para tolerar mais falhas transitórias.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Evento 1196 – O recurso de nome de rede não registrou o nome DNS associado
- Verifique as configurações da NIC para cada um dos nós de cluster a fim de assegurar que não haja registros DNS externos
- Verifique se o registro A do cluster existe nos servidores DNS internos. Caso contrário, crie um novo manual de registro A no servidor DNS para o objeto de controle de acesso de cluster e marque Permitir que qualquer usuário autenticado atualize registros DNS com o mesmo nome de proprietário.
- Use o "nome de cluster" do recurso com o recurso IP offline e corrija-o.
Evento 157 – O disco foi removido de surpresa.
Isso pode acontecer se a propriedade Espaços de Armazenamento AutomaticClusteringEnabled foi definida como True para um ambiente AG. Altere-o para False. Além disso, executar um relatório de validação com a opção de armazenamento pode disparar a reinicialização do disco ou o evento de remoção de surpresa. A limitação do sistema de armazenamento também pode disparar o evento de remoção de surpresa do disco.
Evento 1206 - O recurso de nome de rede do cluster não pode ser colocado online.
O objeto de computador associado ao recurso não pôde ser atualizado no domínio. Verifique se você tem as permissões apropriadas no domínio
Erros de clustering do Windows
Você poderá encontrar problemas quando configurar um cluster de failover do Windows ou sua conectividade se não tiver portas de serviço de cluster abertas para comunicação.
Se você estiver no Windows Server 2019 e não vir um IP de cluster do Windows, significa que você configurou o Nome da Rede Distribuída, que só tem suporte no SQL Server 2019. Se você tiver as versões anteriores do SQL Server, poderá remover e recriar o cluster usando o nome de rede.
Examine outros erros de eventos de clustering de failover do Windows e suas soluções aqui
Próximas etapas
Para obter mais informações, consulte:
- Configurações de HADR para o SQL Server em VMs do Azure
- Cluster de Failover do Windows Server com o SQL Server em VMs do Azure
- Grupos de disponibilidade Always On com o SQL Server nas VMs do Azure
- Cluster de Failover do Windows Server com o SQL Server em VMs do Azure
- Instâncias de cluster de failover com o SQL Server em VMs do Azure
- Visão geral da instância de cluster de failover
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de