O que é a fala personalizada?
Com a fala personalizada, é possível avaliar e aprimorar a precisão do reconhecimento de fala dos aplicativos e produtos. Um modelo de fala personalizado pode ser usado para conversão de fala em texto em tempo real, tradução de fala e transcrição em lote.
Pronto para uso, o reconhecimento de fala utiliza um Modelo de Linguagem Universal como um modelo base treinado com dados de propriedade da Microsoft e reflete a linguagem falada comumente usada. O modelo base é pré-treinado com dialetos e fonéticas que representam uma variedade de domínios comuns. Quando você faz uma solicitação de reconhecimento de fala, o modelo base mais recente de cada linguagem com suporte é usado por padrão. O modelo base funciona bem na maioria dos cenários de reconhecimento de fala.
Um modelo personalizado pode ser usado para aumentar o modelo base para melhorar o reconhecimento do vocabulário específico do domínio específico ao aplicativo, fornecendo dados de texto para treinar o modelo. Ele também pode ser usado para melhorar o reconhecimento com base nas condições de áudio específicas do aplicativo, fornecendo dados de áudio com transcrições de referência.
Você também pode treinar um modelo com texto estruturado, quando os dados seguirem um padrão, para especificar pronúncias personalizadas e personalizar a formatação de texto de exibição com normalização de texto inversa personalizada, reescrita personalizada e filtragem personalizada de conteúdo ofensivo.
Como ele funciona?
Com a fala personalizada, você pode carregar seus próprios dados, testar e treinar um modelo personalizado, comparar a precisão entre modelos e implantar um modelo em um ponto de extremidade personalizado.
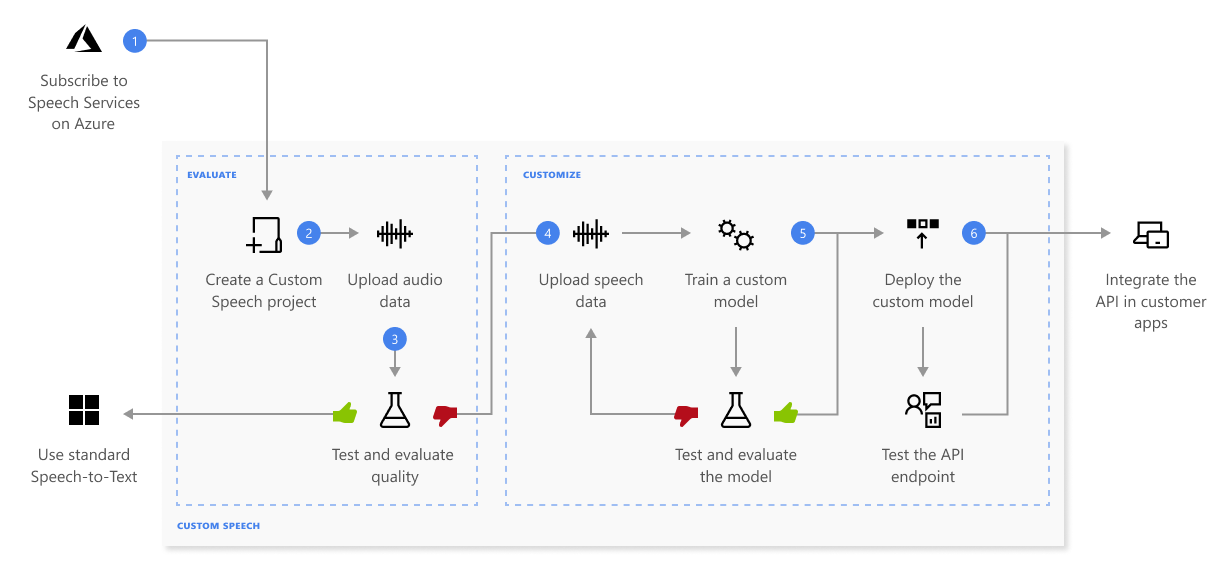
Veja mais informações sobre a sequência de etapas mostradas no diagrama anterior:
- Criar um projeto e escolher um modelo. Use recurso de Fala criado no portal do Azure. Se você treinar um modelo personalizado com dados de áudio, escolha uma região de recursos de fala com hardware dedicado para treinar os dados de áudio. Para obter mais informações, confira as notas de rodapé na tabela regiões.
- Carregar dados de teste. Carregue dados de teste para avaliar a oferta de conversão de fala em texto para seus aplicativos, ferramentas e produtos.
- Testar qualidade do reconhecimento. Use o Speech Studio para reproduzir áudio carregado e inspecionar a qualidade do reconhecimento de fala de seus dados de teste.
- Testar modelo quantitativamente. Avalie e aprimore a precisão do modelo de reconhecimento de fala. O serviço de Fala fornece uma WER (taxa de erros de palavras) quantitativa, que você pode usar para determinar se treinamento adicional é necessário.
- Treinar um modelo. Forneça transcrições escritas e texto relacionado, juntamente com os dados de áudio correspondentes. Testar um modelo antes e depois do treinamento é opcional, mas recomendado.
Observação
Você paga pelo uso personalizado do modelo de fala e pela hospedagem do ponto de extremidade. Você também será cobrado pelo treinamento do modelo de fala personalizada se o modelo base tiver sido criado em 1º de outubro de 2023 e posteriormente. Você não será cobrado pelo treinamento se o modelo base tiver sido criado antes de outubro de 2023. Para obter mais informações, consulte Preços de Fala de IA do Azure e a seção Cobrança pela adaptação no guia de migração de conversão de fala em texto 3.2.
- Implantar um modelo. Depois de estar satisfeito com os resultados do teste, implante o modelo em um ponto de extremidade personalizado. Com exceção da transcrição em lote, você deve implantar um ponto de extremidade personalizado para usar um modelo de fala personalizada.
Dica
Um ponto de extremidade de implantação hospedado não é necessário para usar a fala personalizada com a API de transcrição em lote. Você poderá conservar recursos se o modelo de fala personalizado só for usado para transcrição em lote. Para obter mais informações, confira Preços do serviço de Fala.
IA responsável
Um sistema de IA inclui não apenas a tecnologia, mas também as pessoas que a usam, que serão afetadas por ela e o ambiente em que ela foi implantada. Leia as notas de transparência para saber mais sobre o uso e implantação de IA responsável em seus sistemas.
- Nota de transparência e casos de uso
- Características e limitações
- Integração e uso responsável
- Dados, privacidade e segurança