Pipelines e atividades no Azure Data Factory e no Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Importante
O suporte para o Azure Machine Learning Studio (clássico) terminará em 31 de agosto de 2024. Recomendamos que você faça a transição para o Azure Machine Learning até essa data.
Desde 1º de dezembro de 2021, não é possível criar recursos (workspace e plano do serviço Web) do Azure Machine Learning Studio (clássico). Até 31 de agosto de 2024, você poderá continuar usando os experimentos e os serviços Web existentes do Machine Learning Studio (clássico). Para saber mais, veja:
- Migrar para Azure Machine Learning do Machine Learning Studio (clássico)
- O que é Azure Machine Learning?
A documentação do Machine Learning Studio (clássico) está sendo descontinuada e pode não ser atualizada no futuro.
Este artigo o ajuda a compreender pipelines e atividades no Azure Data Factory e no Azure Synapse Analytics e a usá-los para construir fluxos de trabalho orientados a dados de ponta a ponta para seus cenários de movimentação e processamento de dados.
Visão geral
Um espaço de trabalho Data Factory ou Synapse pode ter um ou mais pipelines. Um pipeline é um agrupamento lógico de atividades que juntas executam uma tarefa. Por exemplo, um pipeline pode conter um conjunto de atividades que ingerem e limpam os dados de log e disparam um fluxo de dados de mapeamento para analisar os dados de log. O pipeline permite que você gerencie as atividades como um conjunto, em vez de cada uma individualmente. Você implanta e agenda o pipeline em vez das atividades de maneira independente.
As atividades de um pipeline definem as ações a serem executadas nos seus dados. Por exemplo, você pode usar uma atividade Copy para copiar dados do SQL Server para um Armazenamento de Blobs do Azure. Em seguida, use uma atividade de fluxo de dados ou uma atividade do Databricks Notebook para processar e transformar dados do armazenamento de blobs em um pool do Azure Synapse Analytics, que será usado para criar soluções de relatórios de business intelligence.
O Azure Data Factory e o Azure Synapse Analytics têm três grupos de atividades: atividades de movimentação de dados, atividades de transformação de dados e atividades de controle. Uma atividade pode não usar ou usar vários conjuntos de dados de entrada e gerar um ou mais conjuntos de dados de saída. O seguinte diagrama mostra a relação entre pipeline, atividade e conjunto de dados:

Um conjunto de dados de entrada representa a entrada de uma atividade no pipeline e um conjunto de dados de saída representa a saída da atividade. Conjuntos de dados identificam dados em armazenamentos de dados diferentes, como tabelas, arquivos, pastas e documentos. Depois de criar um conjunto de dados, você pode usá-lo com atividades no pipeline. Por exemplo, um conjunto de dados pode ser o conjunto de dados de entrada/saída de uma atividade de Cópia ou uma atividade do HDInsightHive. Para saber mais sobre conjuntos de dados, confira o artigo Conjuntos de dados no Azure Data Factory.
Atividades de movimentação de dados
A Atividade de Cópia no Data Factory copia os dados de um repositório de dados de origem para um repositório de dados de coletor. O Data Factory dá suporte aos armazenamentos de dados listados na tabela nesta seção. Os dados de qualquer origem podem ser gravados em qualquer coletor.
Para obter mais informações, consulte Atividade de Cópia – Visão Geral.
Clique em um repositório de dados para saber como copiar dados dentro e fora do repositório.
Observação
Se um conector for marcado como versão prévia, você poderá experimentá-lo e nos enviar comentários. Se você quiser uma dependência de conectores em versão prévia em sua solução, entre em contato com o Suporte do Azure.
Atividades de transformação de dados
O Azure Data Factory e o Azure Synapse Analytics dão suporte às seguintes atividades de transformação, que podem ser adicionadas individualmente ou encadeadas a outra atividade.
Para obter mais informações, confira o artigo Atividades de transformação de dados.
| Atividades de transformação de dados | Ambiente de computação |
|---|---|
| Fluxo de Dados | Clusters Apache Spark gerenciados pelo Azure Data Factory |
| Azure Function | Funções do Azure |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Streaming do Hadoop | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Atividades do ML Studio (clássico): Execução do lote e Atualização de recurso | VM do Azure |
| Procedimento armazenado | SQL do Azure, Azure Synapse Analytics ou SQL Server |
| U-SQL | Análise Azure Data Lake |
| Atividade personalizada | Lote do Azure |
| Databricks Notebook | Azure Databricks |
| Atividade do Databricks Jar | Azure Databricks |
| Atividade do Databricks Python | Azure Databricks |
Atividades de fluxo de controle
Há suporte para as seguintes atividades de fluxo de controle:
| Atividade de controle | Descrição |
|---|---|
| Append Variable | Adicionar um valor a uma variável de matriz. |
| Execute Pipeline | A atividade Execute Pipeline permite que um pipeline do Data Factory ou do Synapse invoque outro pipeline. |
| Filter | Aplicar uma expressão de filtro a uma matriz de entrada |
| For Each | A atividade ForEach define um fluxo de controle repetitivo no seu pipeline. Essa atividade é usada para iterar em uma coleção e executa atividades especificadas em um loop. A implementação dessa atividade em loop é semelhante à estrutura em loop Foreach nas linguagens de programação. |
| Obter Metadados | A atividade GetMetadata pode ser usada para recuperar metadados de todos os dados em um pipeline do Data Factory ou do Synapse. |
| Atividade Condição Se | A Condição If pode ser usada para ramificar com base em condições que são avaliadas como true ou false. A atividade If Condition fornece a mesma funcionalidade que uma instrução if fornece em linguagens de programação. Ela avalia um conjunto de atividades quando a condição é avaliada como true e outro conjunto de atividades quando a condição é avaliada como false. |
| Atividade de pesquisa | A atividade de pesquisa pode ser usada para ler ou procurar um registro/nome de tabela/valor de qualquer fonte externa. Essa saída pode referenciada pelas atividades com êxito. |
| Definir variável | Definir o valor de uma variável que já existe. |
| Atividade Until | Implementa o loop Do-Until, que é semelhante à estrutura de looping Do-Until em linguagens de programação. Ela executa um conjunto de atividades em um loop até que a condição associada à atividade seja avaliada como verdadeira. Você pode especificar um valor de tempo limite para a atividade Until. |
| Validation Activity | Apenas continuará a execução do pipeline se houver um conjunto de dados de referência, se ele cumprir critérios especificados ou se alcançar o tempo limite. |
| Atividade Wait | Quando você usa uma atividade de espera em um pipeline, o pipeline aguarda o tempo especificado antes de continuar com a execução de atividades subsequentes. |
| Atividade da Web | A atividade da Web pode ser usada para chamar um ponto de extremidade REST personalizado de um pipeline. Você pode passar conjuntos de dados e serviços vinculados a serem consumidos e acessados pela atividade. |
| Webhook Activity | Usando a atividade de webhook, chame um ponto de extremidade e passe uma URL de retorno de chamada. A execução do pipeline aguarda a chamada do retorno de chamada para prosseguir com a próxima atividade. |
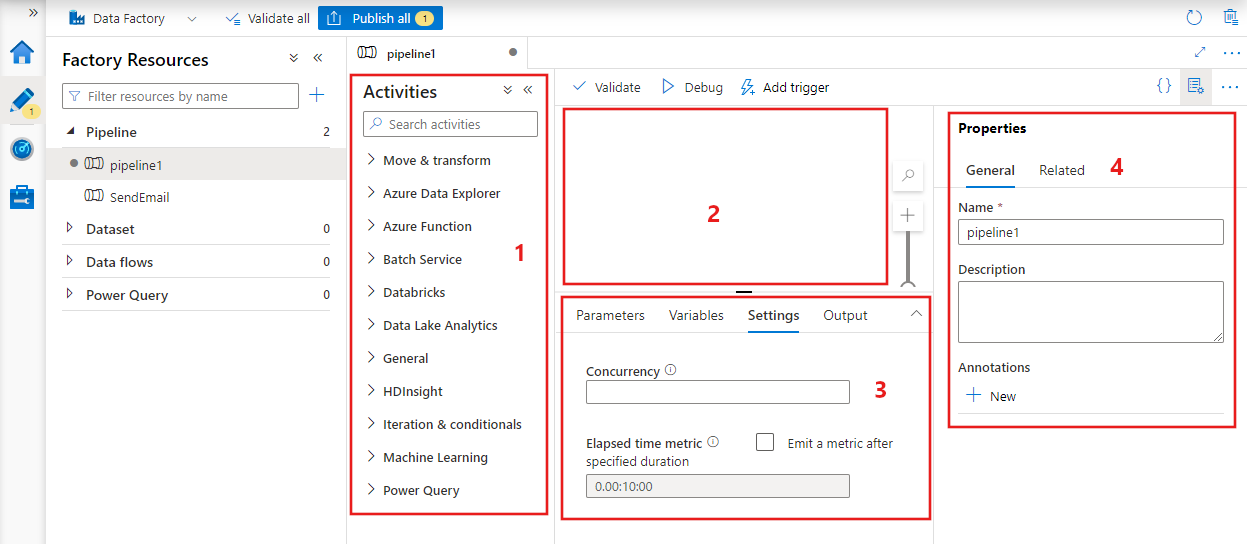
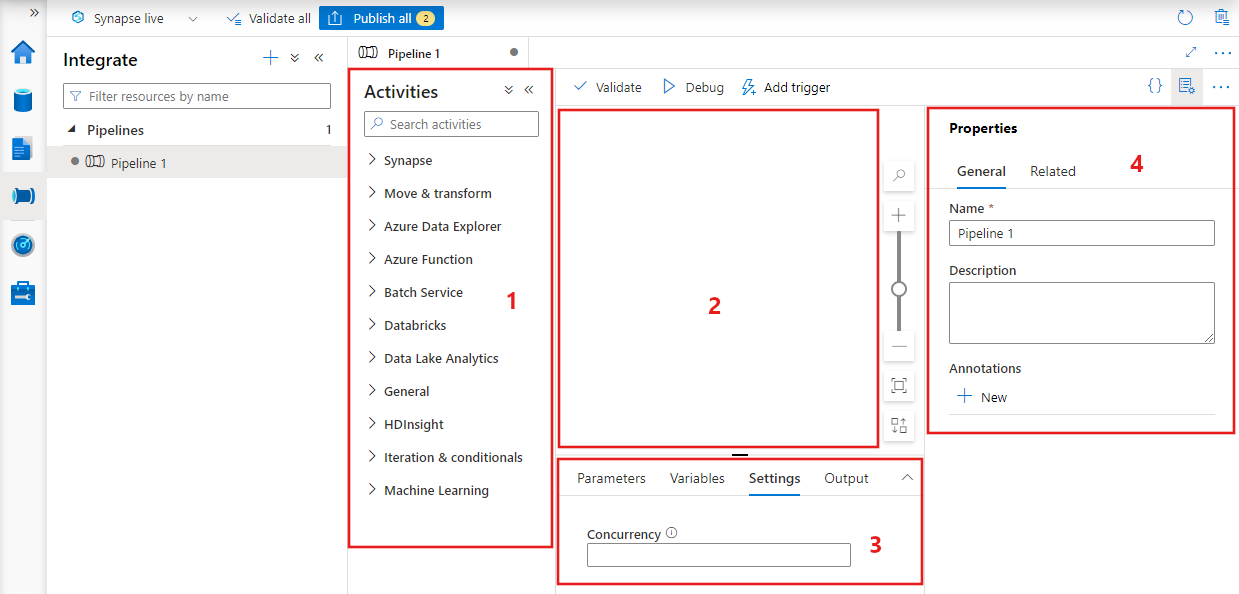
Criando um pipeline com interface do usuário
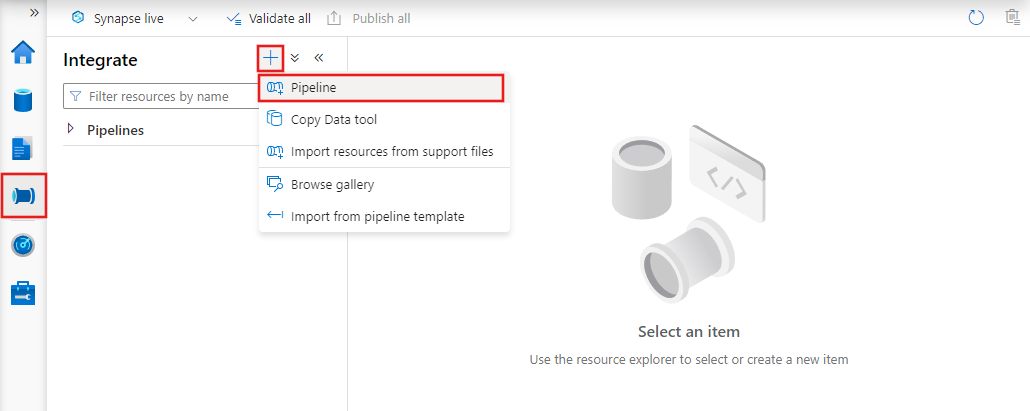
Para criar um pipeline, navegue até a guia Criar no Data Factory Studio (representada pelo ícone de lápis), clique no sinal de mais e escolha Pipeline no menu e Pipeline novamente no submenu.

O Data Factory exibirá o editor de pipeline, no qual você poderá encontrar:
- Todas as atividades que podem ser usadas dentro do pipeline.
- A tela do editor de pipeline, em que as atividades serão exibidas quando adicionadas ao pipeline.
- O painel de configurações de pipeline, incluindo parâmetros, variáveis, configurações gerais e saída.
- O painel de propriedades do pipeline, em que o nome do pipeline, a descrição opcional e as anotações podem ser configurados. Esse painel também mostrará todos os itens relacionados ao pipeline dentro do data factory.
Pipeline de JSON
Veja como um pipeline é definido no formato JSON:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Marca | Descrição | Type | Obrigatório |
|---|---|---|---|
| name | Nome do pipeline. Especifique um nome que represente a ação executada pelo pipeline.
|
String | Sim |
| descrição | Especifique o texto descrevendo para que o pipeline é usado. | String | Não |
| atividades | A seção Atividades pode ter uma ou mais atividades definidas dentro dela. Confira a seção Atividade JSON para obter detalhes sobre o elemento das atividades JSON. | Array | Sim |
| parameters | A seção parâmetros pode ter um ou mais parâmetros definidos no pipeline, tornando seu pipeline flexível para reutilização. | Lista | Não |
| simultaneidade | O número máximo de execuções simultâneas que o pipeline pode ter. Por padrão, não há valor máximo. Se o limite de simultaneidade for atingido, as execuções de pipeline adicionais serão enfileiradas até que as anteriores sejam concluídas | Número | Não |
| annotations | Uma lista de marcas associadas ao pipeline | Array | Não |
Atividade JSON
A seção Atividades pode ter uma ou mais atividades definidas dentro dela. Há dois tipos principais de atividades: atividades de execução e de controle.
Atividades de execução
As atividades de execução incluem atividades de movimentação de dados e de transformação de dados. Elas têm a seguinte estrutura de nível superior:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
A seguinte tabela descreve as propriedades na definição de JSON da atividade:
| Marca | Descrição | Obrigatório |
|---|---|---|
| name | Nome da atividade. Especifique um nome que represente a ação executada pela atividade.
|
Sim |
| descrição | Texto que descreve para que a atividade é usada | Sim |
| type | Tipo da atividade. Confira as seções Atividades de movimentação de dados, Atividades de transformação de dados e Atividades de controle para diferentes tipos de atividade. | Sim |
| linkedServiceName | Nome do serviço vinculado usado pela atividade. Uma atividade pode exigir que você especifique o serviço vinculado que se vincula ao ambiente de computação necessário. |
Sim para Atividade de HDInsight, Atividade de Pontuação de Lote do ML Studio (clássico) e Atividade de Procedimento Armazenado. Não para todas as outros |
| typeProperties | As propriedades na seção typeProperties dependem de cada tipo de atividade. Para ver as propriedades de tipo para uma atividade, clique em links para a atividade na seção anterior. | Não |
| policy | Políticas que afetam o comportamento de tempo de execução da atividade. Essa propriedade inclui o comportamento de tempo limite e de repetição. Se não forem especificados, os valores padrão serão usados. Para obter mais informações, consulte a seção Política de atividade. | Não |
| dependsOn | Esta propriedade é usada para definir as dependências de atividade e o modo como as atividades subsequentes dependem de atividades anteriores. Para obter mais informações, consulte a seção Dependência de atividade | Não |
Política de atividade
As políticas afetam o comportamento em tempo de execução de uma atividade, oferecendo opções de configurabilidade. Políticas de atividade só estão disponíveis para atividades de execução.
Definição JSON de política de atividade
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| Nome JSON | Descrição | Valores Permitidos | Obrigatório |
|---|---|---|---|
| tempo limite | Especifica o tempo limite para a atividade ser executada. | Timespan | Não. O tempo limite padrão é de 12 horas e, no mínimo, dez minutos. |
| tentar novamente | Número máximo de novas tentativas | Integer | Não. O padrão é 0 |
| retryIntervalInSeconds | O intervalo entre tentativas de repetição em segundos | Integer | Não. O padrão é de 30 segundos |
| secureOutput | Quando definido como true, a saída da atividade é considerada segura e não é registrada em log para monitoramento. | Boolean | Não. O padrão é false. |
Atividade de controle
As atividades de controle têm a seguinte estrutura de nível superior:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Marca | Descrição | Obrigatório |
|---|---|---|
| name | Nome da atividade. Especifique um nome que represente a ação executada pela atividade.
|
Sim |
| descrição | Texto que descreve para que a atividade é usada | Sim |
| type | Tipo da atividade. Confira as seções atividades de movimentação de dados, atividades de transformação de dados e atividades de controle para diferentes tipos de atividade. | Sim |
| typeProperties | As propriedades na seção typeProperties dependem de cada tipo de atividade. Para ver as propriedades de tipo para uma atividade, clique em links para a atividade na seção anterior. | Não |
| dependsOn | Essa propriedade é usada para definir a dependência de atividade e o modo como as atividades subsequentes dependem de atividades anteriores. Para obter mais informações, consulte dependência de atividade. | Não |
Dependência de atividade
A dependência de atividade define o modo como atividades subsequentes dependem de atividades anteriores, determinando a condição para que a execução continue ou não para a próxima tarefa. Uma atividade pode depender de uma ou várias atividades anteriores com condições de dependência diferentes.
As diferentes condições de dependência são: Êxito, Falha, Ignorada, Concluída.
Por exemplo, se um pipeline tem atividade A -> atividade B, os diferentes cenários que podem acontecer são:
- A atividade B tem uma condição de dependência de atividade A com o resultado êxito: a atividade B só é executada se a atividade A tem um status final de êxito
- A atividade B tem uma condição de dependência de atividade A com o resultado falha: a atividade B só é executada se a atividade A tem um status final de falha
- A atividade B tem uma condição de dependência de atividade A com o resultado concluída: a atividade B só é executada se a atividade A tem um status final de êxito ou falha
- A atividade B tem uma condição de dependência de atividade A com o resultado ignorada: a atividade B só é executada se a atividade A tem um status final de ignorada. Ignorada ocorre no cenário de Atividade X -> Atividade Y -> Atividade Z, em que cada atividade é executada somente se a atividade anterior tem êxito. Se a Atividade X falhar, a Atividade Y terá o status "Ignorada" porque nunca será executada. Da mesma forma, a Atividade Z também terá o status "Ignorada".
Exemplo: a Atividade 2 depende do êxito da Atividade 1
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Pipeline de cópia de exemplo
No pipeline de exemplo a seguir, há uma atividade do tipo Cópia in the atividades . Neste exemplo, a atividade Copy copia dados de um Armazenamento de Blobs do Azure para um banco de dados no Banco de Dados SQL do Azure.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Observe os seguintes pontos:
- Na seção de atividades, há apenas uma atividade cujo tipo é definido como Copy.
- A entrada da atividade é definida como InputDataset e a saída da atividade é definida como OutputDataset. Confira o artigo Conjuntos de dados para definir conjuntos de dados em JSON.
- Na seção typeProperties, BlobSource é especificado como o tipo de origem e SqlSink é especificado como o tipo de coletor. Na seção atividades de movimentação de dados, clique no armazenamento de dados que você quer usar como uma fonte ou um coletor para aprender mais sobre como mover dados bidirecionalmente nesse armazenamento de dados.
Para um passo a passo completo sobre como criar esse pipeline, consulte Guia de início rápido: criar um data factory.
Pipeline de transformação de exemplo
No pipeline de exemplo a seguir, há uma atividade do tipo HDInsightHive in the atividades . Neste exemplo, a atividade de Hive do HDInsight transforma os dados de um Armazenamento de Blobs do Azure executando um arquivo de script do Hive em um cluster Hadoop do HDInsight do Azure.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Observe os seguintes pontos:
- Na seção de atividades, há apenas uma atividade cujo tipo é definido como HDInsightHive.
- O arquivo de script do Hive, partitionweblogs.hql, é armazenado na conta do Armazenamento do Microsoft Azure (especificada pelo scriptLinkedService chamado AzureStorageLinkedService) e na pasta script no contêiner
adfgetstarted. - A seção
definesé usada para especificar as configurações de runtime passadas para o script do hive como valores de configuração de Hive (por exemplo, ${hiveconf:inputtable},${hiveconf:partitionedtable}).
A seção typeProperties é diferente para cada atividade de transformação. Para saber mais sobre as propriedades de tipo com suporte para uma atividade de transformação, clique na atividade de transformação nas Atividades de transformação de dados.
Para obter uma explicação completa da criação desse pipeline, confira Tutorial: transformar dados usando o Spark.
Várias atividades em um pipeline
Os dois pipelines de exemplo anteriores têm apenas uma atividade neles. Você pode ter mais de uma atividade em um pipeline. Se você tiver várias atividades em um pipeline e as atividades subsequentes não forem dependentes das atividades anteriores, as atividades poderão ser executadas em paralelo.
Você pode encadear duas atividades usando a dependência de atividade, que define o modo como atividades subsequentes dependem de atividades anteriores, determinando a condição para que a execução continue ou não para a próxima tarefa. Uma atividade pode depender de uma ou mais atividades anteriores com condições de dependência diferentes.
Agendando pipelines
Pipelines são agendados por gatilhos. Há diferentes tipos de gatilhos (gatilho de agendamento, que permite que pipelines sejam disparados em um agendamento de relógio, bem como o gatilho manual, que dispara os pipelines sob demanda). Para obter mais informações sobre gatilhos, consulte o artigo gatilhos e execução de pipeline.
Para que o gatilho dispare uma execução de pipeline, você deve incluir uma referência de pipeline do pipeline específico na definição do gatilho. Os pipelines e os gatilhos têm uma relação n-m. Vários gatilhos podem disparar um único pipeline, e o mesmo gatilho pode disparar vários pipelines. Uma vez definido o gatilho, você deve iniciar o gatilho para que ele comece a disparar o pipeline. Para obter mais informações sobre gatilhos, consulte o artigo gatilhos e execução de pipeline.
Por exemplo, digamos que você tenha um gatilho de Agendador, "disparar um", que eu queira iniciar meu pipeline, "MyCopyPipeline". Você define o gatilho, conforme mostrado no exemplo a seguir:
Definição do gatilho A
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}
Conteúdo relacionado
Confira os tutoriais a seguir para obter instruções passo a passo para criar pipelines com atividades:
- Criar um pipeline com uma atividade de cópia
- Crie um pipeline com uma atividade de transformação de dados
Como obter CI/CD (integração e entrega contínuas) usando o Azure Data Factory