Carregar dados no Azure Synapse Analytics usando um pipeline do Azure Data Factory ou do Synapse
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
O Azure Synapse Analytics é um banco de dados com base na nuvem e expansível com capacidade de processar volumes imensos de dados, relacionais e não relacionais. O Azure Synapse Analytics foi desenvolvido com base na arquitetura MPP (processamento paralelo maciço) otimizada para cargas de trabalho de Data Warehouse corporativo. Ele oferece a elasticidade da nuvem com a flexibilidade de dimensionar o armazenamento e a computação de modo independente.
Agora está mais fácil do que nunca começar a usar o Azure Synapse Analytics. O Azure Data Factory e seu recurso de pipelines equivalentes no Azure Synapse fornecem um serviço de integração de dados totalmente gerenciado baseado em nuvem. Você pode usar o serviço para preencher o Azure Synapse Analytics com dados do sistema existente e poupar tempo ao criar suas soluções analíticas.
Os pipelines do Azure Data Factory ou do Synapse oferecem os seguintes benefícios para carregar dados no Azure Synapse Analytics:
- Fácil de configurar: um assistente intuitivo de cinco etapas sem necessidade de script.
- Suporte avançado de armazenamento de dados: suporte interno para um conjunto avançado de armazenamentos de dados locais e baseados em nuvem. Para obter uma lista detalhada, consulte a tabela de Suporte para repositórios de dados.
- Seguro e em conformidade: os dados são transferidos via HTTPS ou ExpressRoute. A presença do serviço global garante que os dados nunca saiam do limite geográfico.
- Desempenho incomparável usando o PolyBase: o uso do PolyBase é a maneira mais eficiente de mover dados para o Azure Synapse Analytics. Use o recurso de objeto binário em etapas para obter velocidades de alta carga de todos os tipos de armazenamentos de dados, incluindo armazenamento Azure Blob e Data Lake Store. O Polybase dá suporte ao Armazenamento de blobs do Azure e ao Azure Data Lake Store por padrão. Para saber os detalhes, veja Desempenho da atividade Copy.
Este artigo mostra como usar a ferramenta Copiar Dados para carregar dados do Banco de Dados SQL do Azure no Azure Synapse Analytics. Você pode seguir as etapas semelhantes para copiar dados de outros tipos de armazenamentos de dados.
Observação
Para obter mais informações, confira Copiar dados para ou do Azure Synapse Analytics.
Pré-requisitos
- Assinatura do Azure: Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Azure Synapse Analytics: o data warehouse contém os dados copiados do banco de dados SQL. Se você não tiver um Azure Synapse Analytics, veja as instruções em Criar um Azure Synapse Analytics.
- Banco de Dados SQL do Azure: Este tutorial copia os dados do conjunto de dados de amostra do Adventure Works LT no Banco de Dados SQL do Azure. Você pode criar um banco de dados de exemplo no Banco de Dados SQL seguindo as instruções em Criar um banco de dados de exemplo no Banco de Dados SQL do Azure.
- Conta de armazenamento do Azure: armazenamento do Azure é usado como blob de processo de reparo na operação de cópia em massa. Se você não tiver uma conta de armazenamento do Azure, confira as instruções em Criar uma conta de armazenamento.
Criar uma data factory
Se você ainda não criou o data factory, siga as etapas no Início Rápido: crie um data factory usando o portal do Azure e o Estúdio do Azure Data Factory para criar um. Depois de criá-lo, navegue até o data factory no portal do Azure.
Selecione Abrir no bloco Abrir Estúdio do Azure Data Factory para iniciar o aplicativo Data Integration em uma guia separada.
Carregar dados no Azure Synapse Analytics
Na home page do workspace do Azure Data Factory ou do Azure Synapse, selecione o bloco Ingerir para a inicialização da ferramenta Copiar Dados. Em seguida, escolha a tarefa de cópia interna.
Na página Propriedades, escolha a Tarefa de cópia interna em Tipo de tarefa e selecione Avançar.
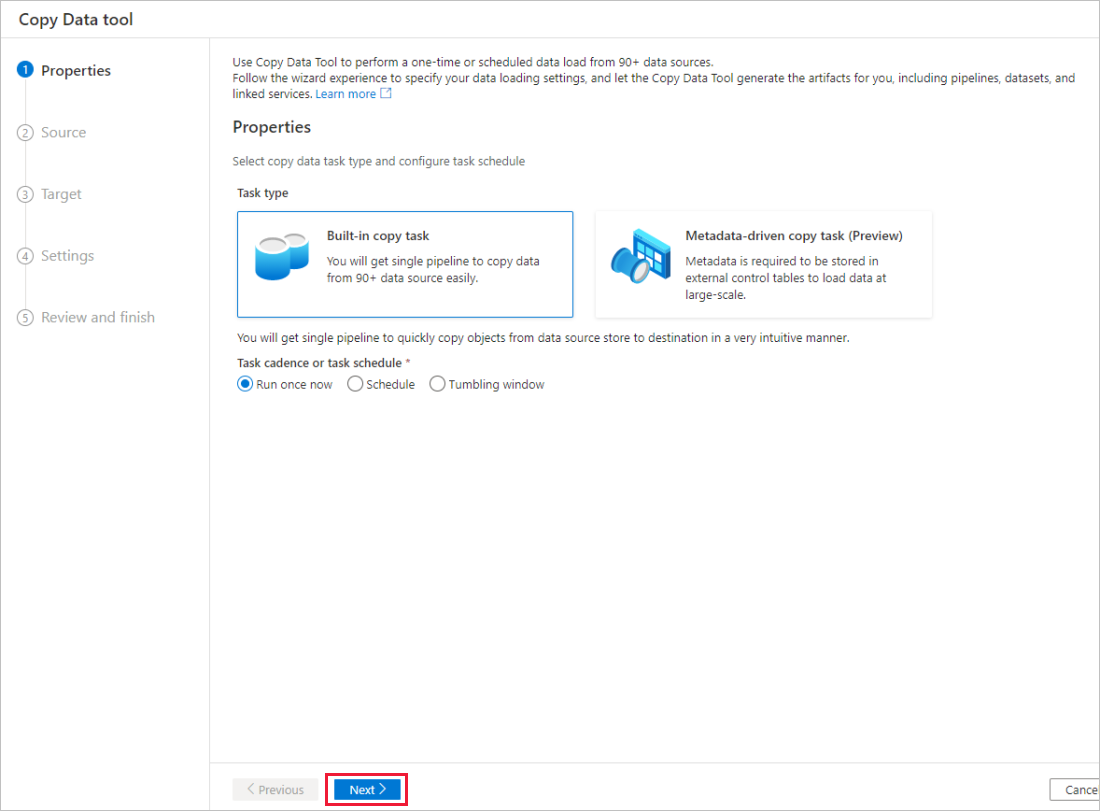
Na página Armazenamento de dados de origem, conclua as etapas a seguir:
Dica
Neste tutorial, você usa a Autenticação de SQL como o tipo de autenticação para o armazenamento de dados de origem, mas pode escolher outros métodos de autenticação compatíveis: Entidade de Serviço e Identidade Gerenciada, se necessário. Veja as seções correspondentes neste artigo para obter detalhes. Para armazenar segredos de armazenamentos de dados com segurança, também é recomendável usar um Azure Key Vault. Veja este artigo para obter ilustrações detalhadas.
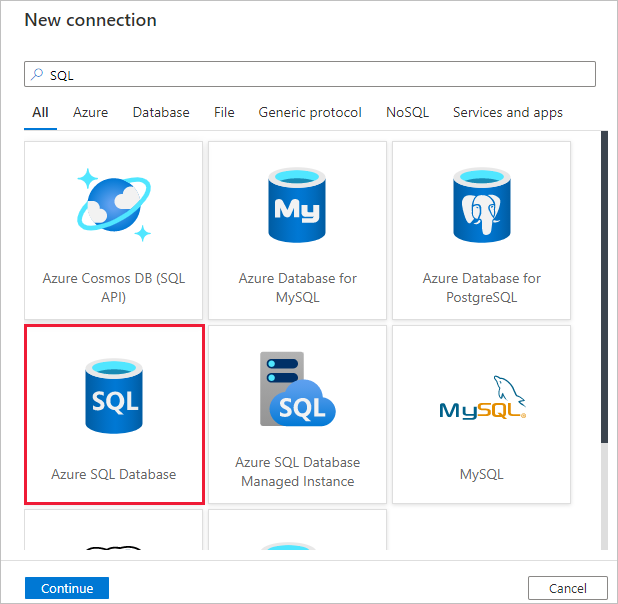
Selecione + Nova conexão.
Selecione Banco de Dados SQL do Azure da galeria e selecione Continuar. Você pode digitar "SQL" na caixa de pesquisa para filtrar os conectores.
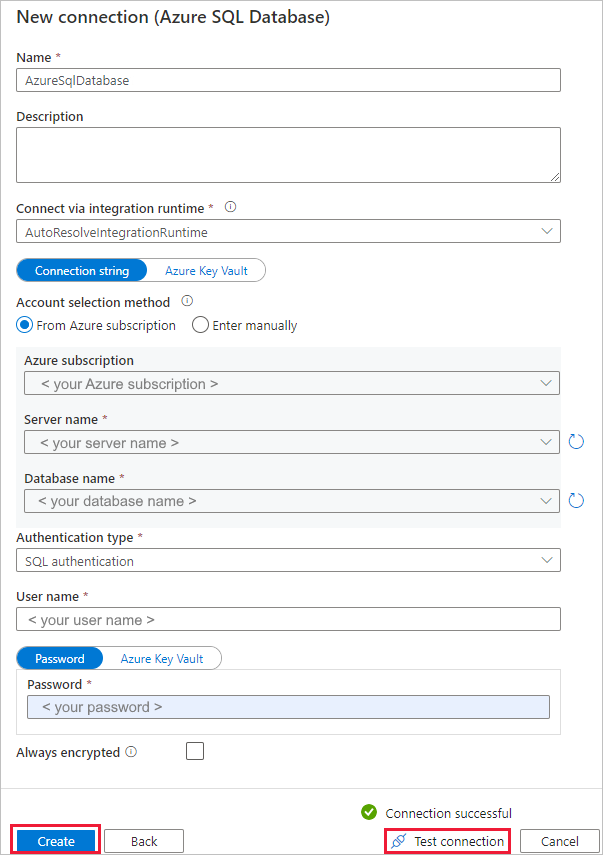
Na página Novo conexão (Banco de dados SQL do Azure) , selecione o nome do servidor e nome da BD na lista suspensa e especifique o nome de usuário e a senha. Selecione Testar conectividade para validar as configurações e selecione Criar.
Na página Armazenamento de dados de origem, selecione a conexão criada recentemente como fonte na seção Conexão.
Na seção tabelas fonte, insira salesLT para filtrar as tabelas. Marque a caixa (Selecionar tudo) para usar todas as tabelas para a cópia e, em seguida, selecione Avançar.
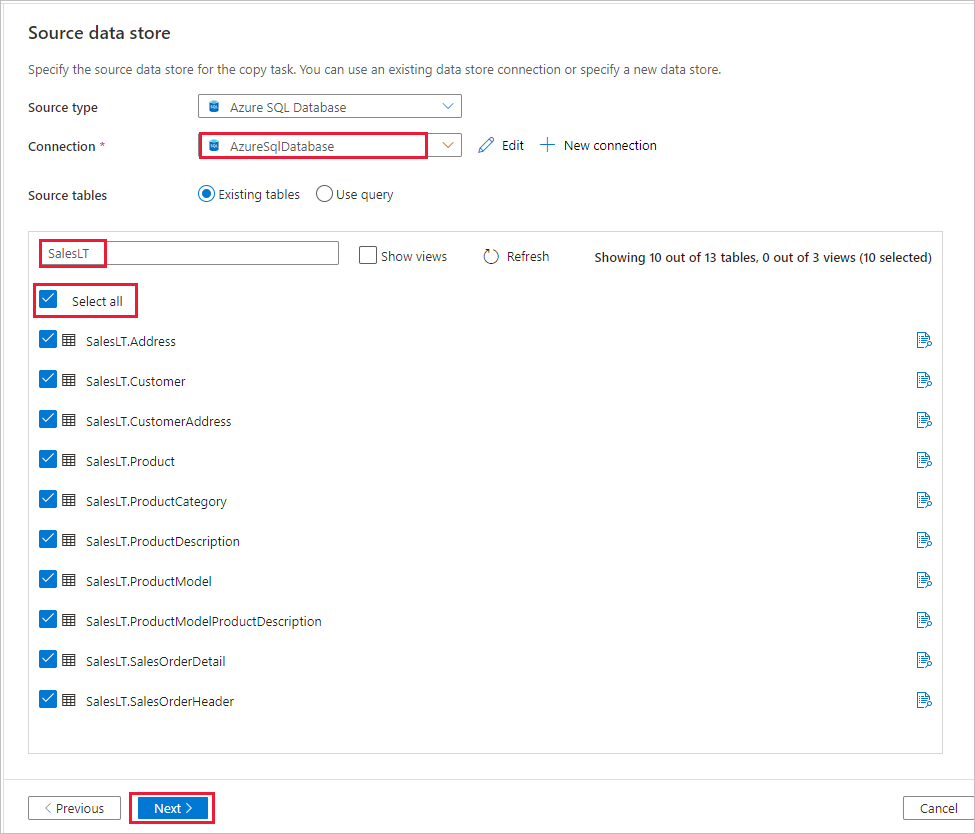
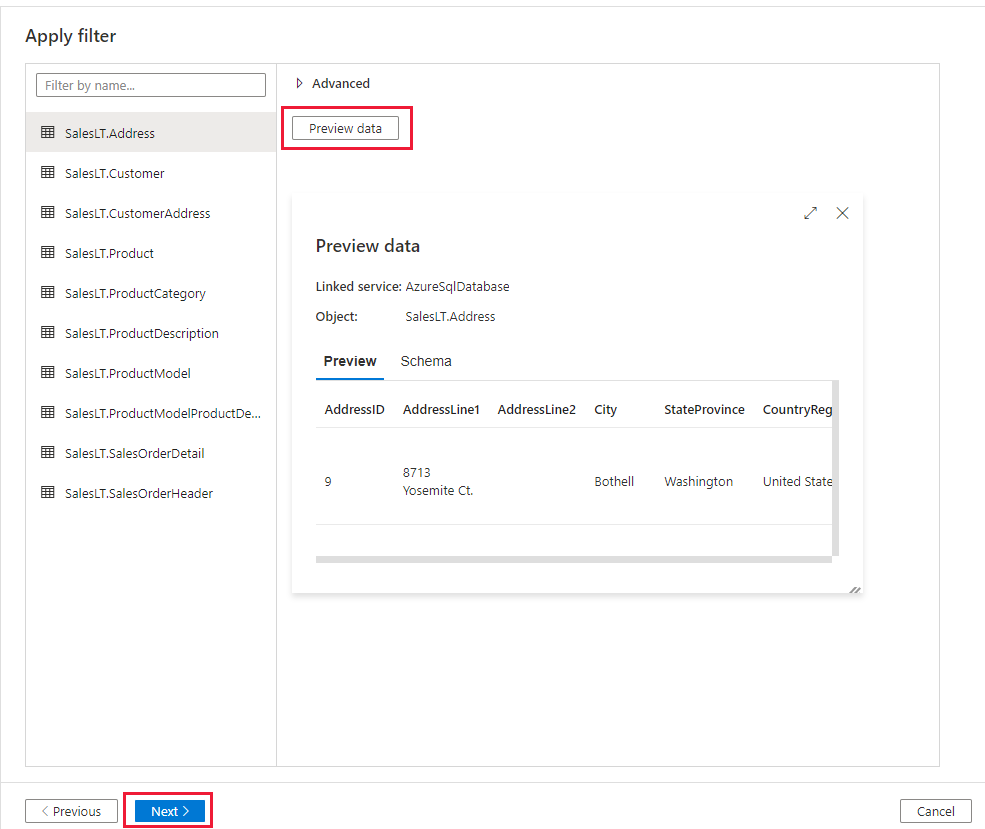
Na página Aplicar filtro, especifique as configurações ou selecione Avançar. Você pode pré-visualizar os dados e exibir o esquema dos dados de entrada selecionando o botão Pré-visualização de dados nesta página.
Na página Armazenamento de dados de destino, conclua as etapas a seguir:
Dica
Neste tutorial, você usa Autenticação SQL como o tipo de autenticação para o armazenamento de dados de destino, mas você pode escolher outros métodos de autenticação compatíveis: Entidade de Serviço e Identidade Gerenciada, se necessário. Veja as seções correspondentes neste artigo para obter detalhes. Para armazenar segredos de armazenamentos de dados com segurança, também é recomendável usar um Azure Key Vault. Veja este artigo para obter ilustrações detalhadas.
Selecione + Nova conexão para adicionar uma conexão.
Selecione Azure Synapse Analytics na galeria e, em seguida, Continuar.
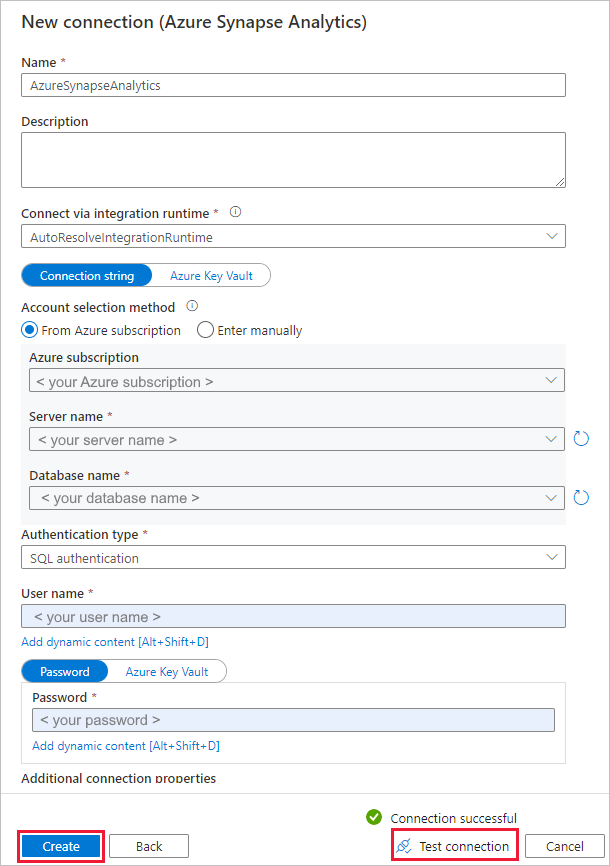
Na página Nova conexão (Azure Synapse Analytics) , selecione o nome do servidor e nome da BD na lista suspensa e especifique o nome de usuário e a senha. Selecione Testar conectividade para validar as configurações e selecione Criar.
Na página Armazenamento de dados de destino, selecione a conexão criada recentemente como coletor na seção Conexão.
Na seção Mapeamento de tabela, revise o conteúdo e selecione Avançar. Um mapeamento de tabela inteligente é exibido. As tabelas de origem são mapeadas para as tabelas de destino com base nos nomes de tabela. Se a tabela de origem não existir no destino, por padrão o serviço cria uma tabela de destino com o mesmo nome por padrão. Você também pode mapear uma tabela de origem para uma tabela de destino existente.
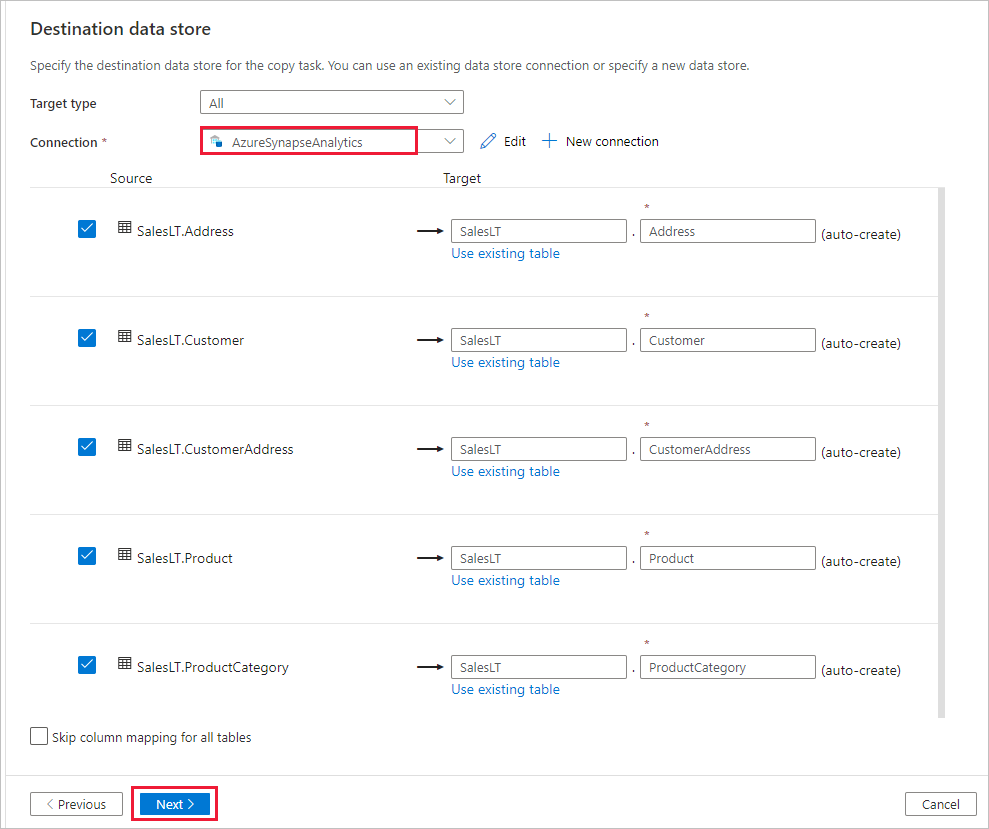
Na página Mapeamento de coluna, examine o conteúdo e selecione Avançar. O mapeamento de tabela inteligente é baseado no nome da coluna. Se você deixar o serviço criar automaticamente as tabelas, a conversão do tipo de dados pode ocorrer quando houver incompatibilidades entre a origem e os armazenamentos de destino. Se houver uma conversão de tipo de dados sem suporte entre a coluna de origem e de destino, você verá uma mensagem de erro próximo à tabela correspondente.
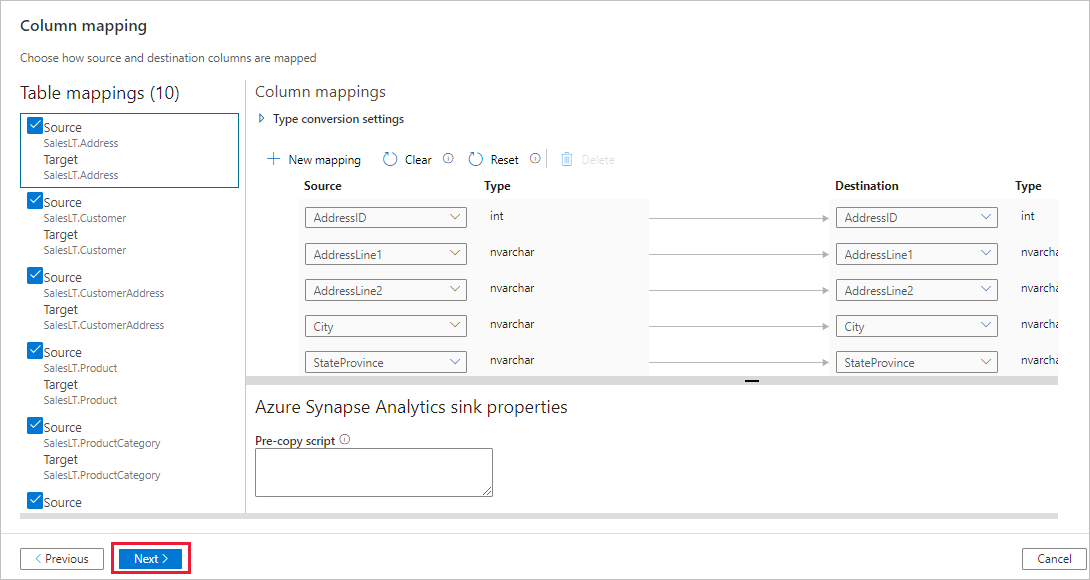
Na página Configurações, execute as seguintes etapas:
Especifique CopyFromSQLToSQLDW para o campo Nome da tarefa.
Na seção Configurações de preparo, selecione + Novo para criar um novo armazenamento de preparo. O armazenamento é usado para preparar os dados antes de serem carregados no Azure Synapse Analytics usando o PolyBase. Quando a cópia terminar, os dados provisórios no Armazenamento de Blobs do Azure serão limpos automaticamente.
Na página Novo serviço vinculado, selecione a conta de armazenamento e, em seguida, Criar para implantar o serviço vinculado.
Desmarque a opção Usar tipo padrão e, em seguida, selecione Avançar.
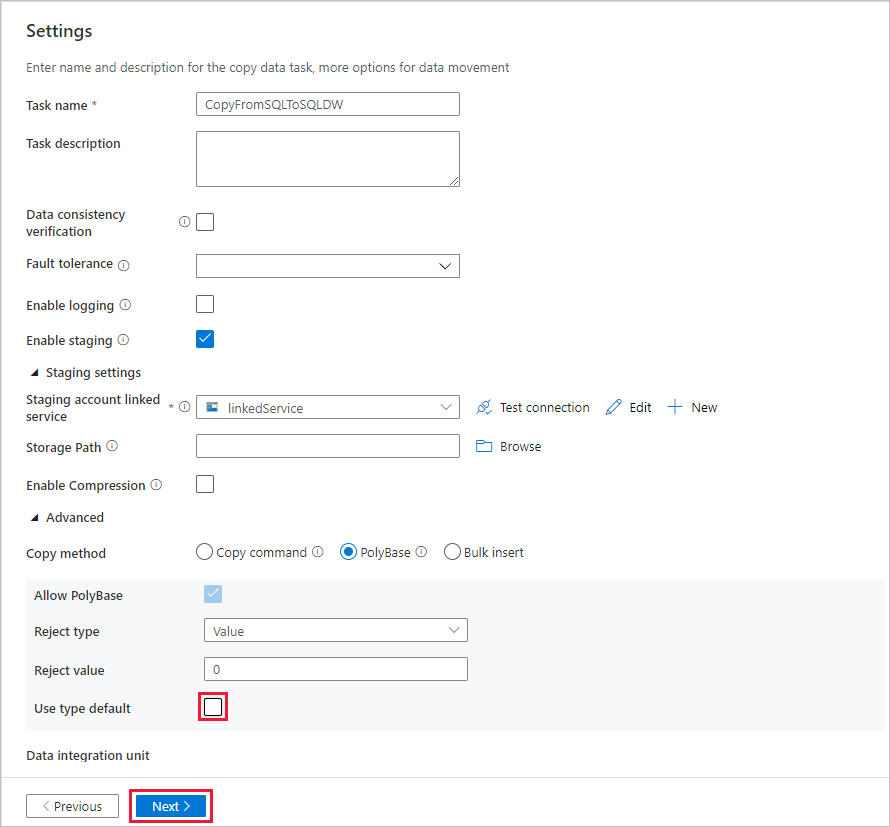
Na página Resumo, examine as configurações e selecione Avançar.
Na página Implantação, selecione Monitorar para monitorar o pipeline (tarefa).
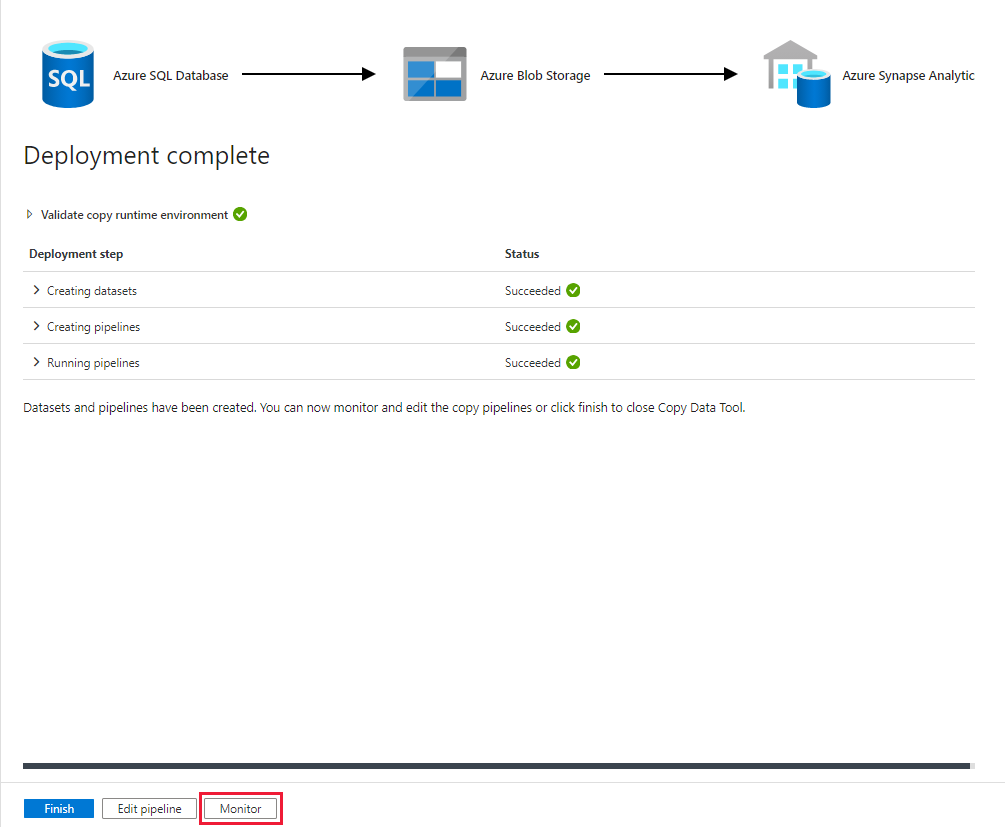
Observe que a guia Monitor à esquerda é selecionada automaticamente. Quando a execução do pipeline for concluída com êxito, selecione o link CopyFromSQLToSQLDW na coluna Nome do pipeline para exibir os detalhes da execução da atividade ou para executar novamente o pipeline.
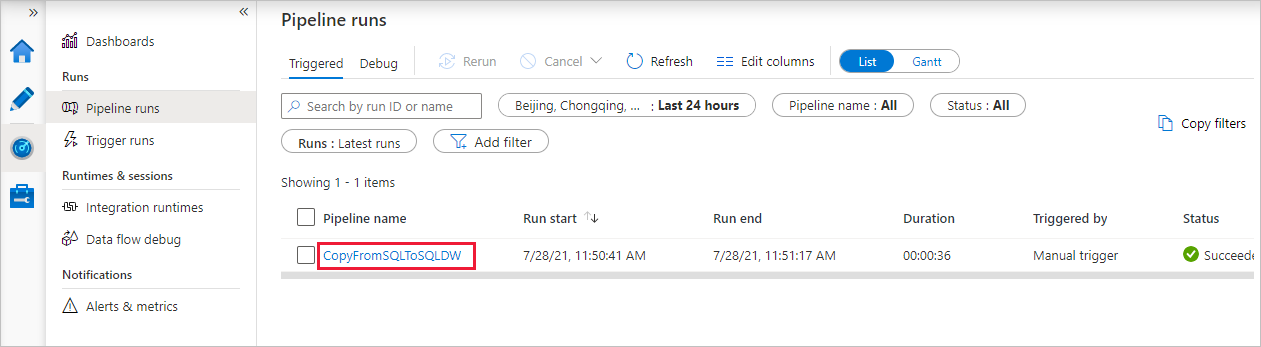
Para voltar à exibição de execuções de pipeline, selecione o link Todos os pipelines são executados na parte superior. Selecione Atualizar para atualizar a lista.
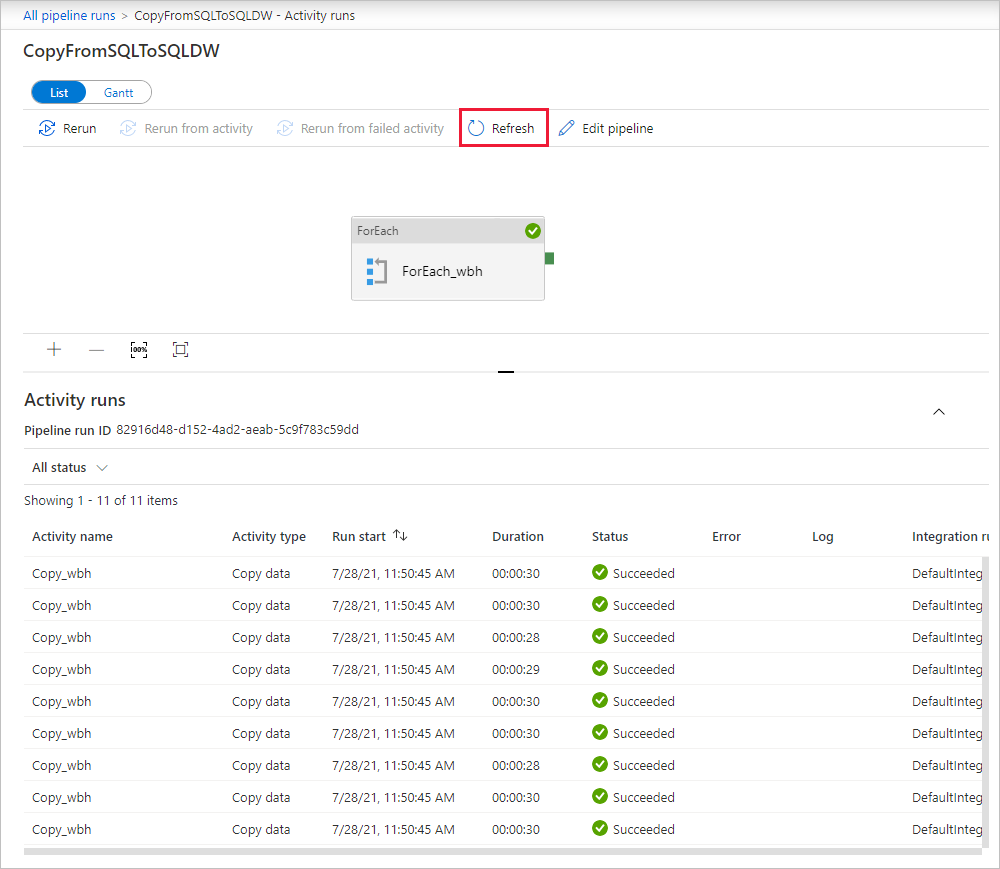
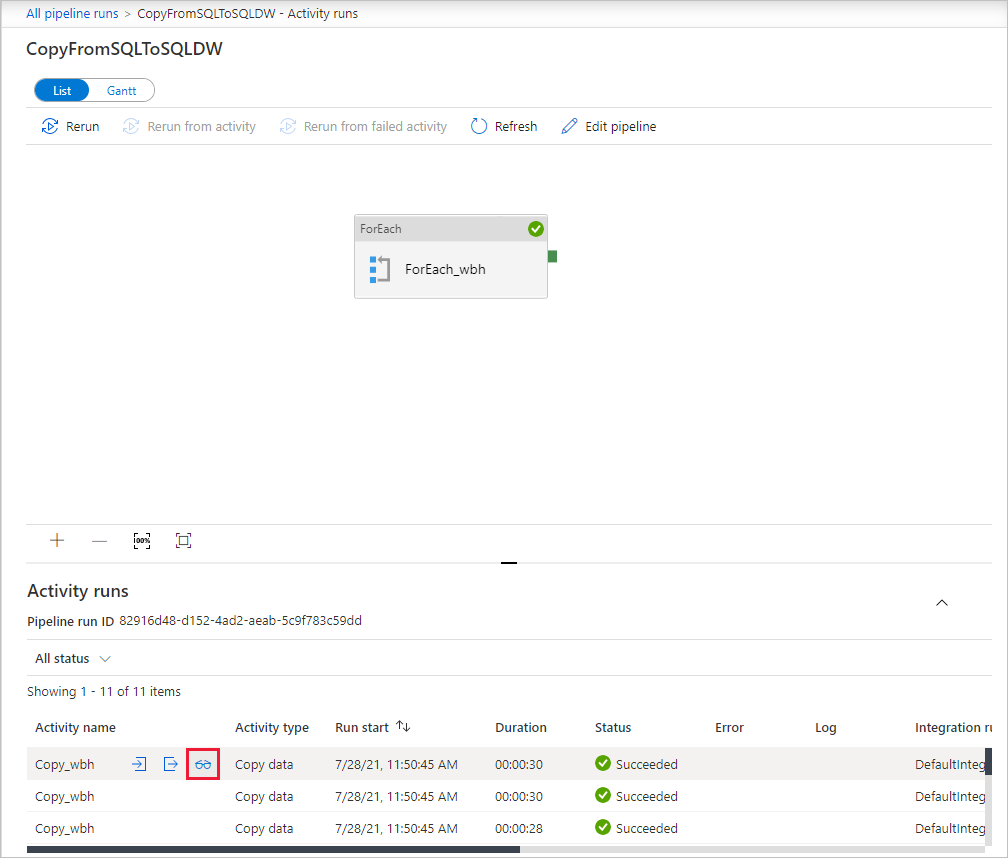
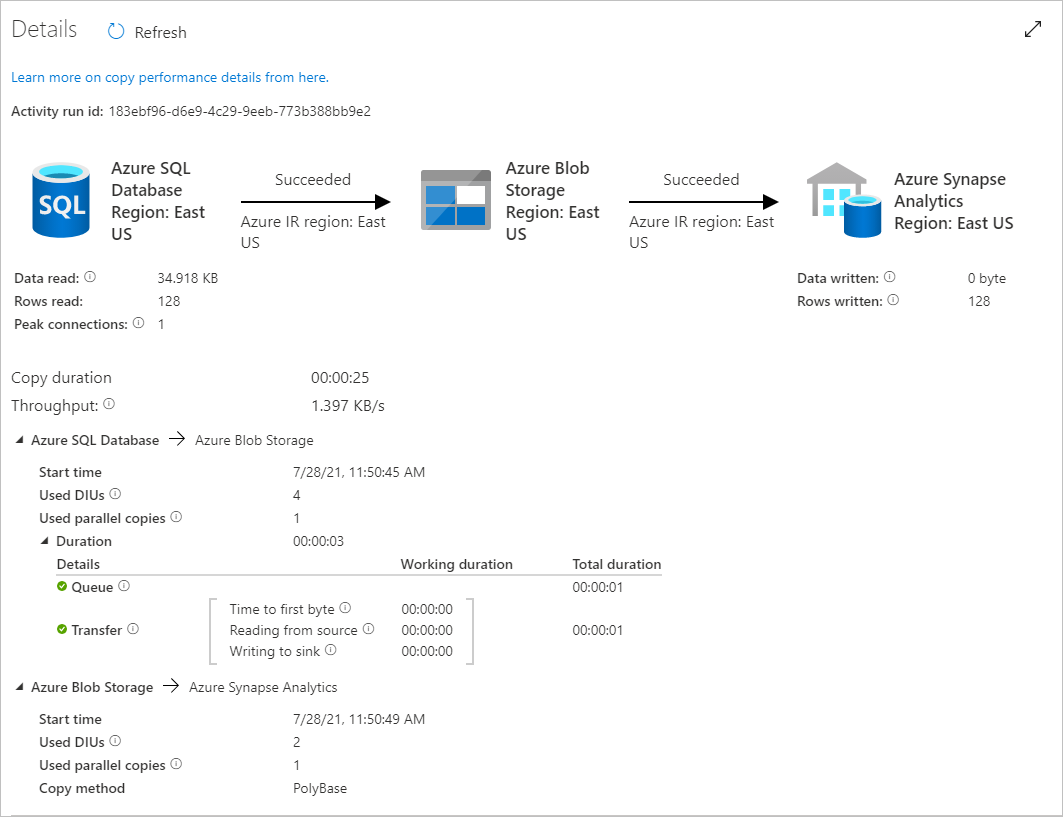
Para monitorar os detalhes de execução de cada atividade de cópia, selecione o link Detalhes (imagem de óculos) em Nome da atividade na exibição de execução de atividade. Você pode monitorar detalhes como o volume de dados copiados da fonte para o coletor, taxa de transferência de dados, etapas de execução com duração correspondente e configurações usadas.
Conteúdo relacionado
Vá para o seguinte artigo para saber mais sobre o suporte do Azure Synapse Analytics: