Gravações aceleradas do Azure HDInsight para Apache HBase
Este artigo fornece informações sobre o recurso Gravações Aceleradas para Apache HBase no Azure HDInsight e como ele pode ser usado com eficiência para melhorar o desempenho de gravação. O recurso Gravações Aceleradas usa discos gerenciados SSD premium do Azure para melhorar o desempenho do Write Ahead Log (WAL) do Apache HBase. Para saber mais sobre o Apache HBase, veja O que é Apache HBase no HDInsight.
Visão geral da arquitetura do HBase
No HBase, uma linha consiste em uma ou mais colunas e é identificada por uma chave de linha. Várias linhas compõem uma tabela. As colunas contêm células, que são versões com carimbo de data/hora do valor nessa coluna. As colunas são agrupadas em famílias de colunas e todas as colunas em uma família de colunas são armazenadas juntas em arquivos de armazenamento chamados HFiles.
As regiões no HBase são usadas para balancear a carga de processamento de dados. O HBase armazena primeiro as linhas de uma tabela em uma única região. As linhas são distribuídas entre várias regiões à medida que a quantidade de dados na tabela aumenta. Os Servidores de Região podem lidar com solicitações para várias regiões.
Write Ahead Log para Apache HBase
O HBase primeiro grava as atualizações de dados em um tipo de log de confirmação chamado Write Ahead Log (WAL). Depois que a atualização é armazenada no WAL, ela é gravada no MemStore na memória. Quando atingem sua capacidade máxima, os dados na memória são gravados em disco como um HFile.
Se um RegionServer falhar ou ficar indisponível antes de o MemStore ser liberado, o Write Ahead Log poderá ser usado para reproduzir atualizações. Sem o WAL, se um RegionServer falhar antes de liberar as atualizações para um HFile todas essas atualizações serão perdidas.
Recurso Gravações Aceleradas no Azure HDInsight para Apache HBase
O recurso Gravações Aceleradas resolve o problema de latências de gravação mais altas causadas pelo uso do Write Ahead Logs que estão no armazenamento em nuvem. O recurso Gravações Aceleradas para clusters Apache HBase do HDInsight anexa discos gerenciados SSD premium a cada RegionServer (nó de trabalho). Os Write Ahead Logs são gravados no Hadoop File System (HDFS) montado nesses discos gerenciados premium em vez de no armazenamento em nuvem. Os discos gerenciados premium usam SSDs (Solid-State Disks) e oferecem excelente desempenho de E/S com tolerância a falhas. Ao contrário dos discos não gerenciados, se uma unidade de armazenamento falhar, isso não afetará outras unidades de armazenamento no mesmo conjunto de disponibilidade. Como resultado, os discos gerenciados fornecem baixa latência de gravação e maior resiliência para seus aplicativos. Para saber mais sobre os discos gerenciados do Azure, veja Introdução aos discos gerenciados do Azure.
Como habilitar o recurso Gravações Aceleradas para HBase no HDInsight
Para criar um novo cluster HBase com o recurso Gravações Aceleradas, siga as etapas em Configurar clusters no HDInsight. Na guia Noções básicas, selecione o tipo de cluster como HBase, especifique uma versão de componente e clique na caixa de seleção ao lado de Habilitar gravações aceleradas do HBase. Em seguida, continue com as etapas restantes para a criação do cluster.
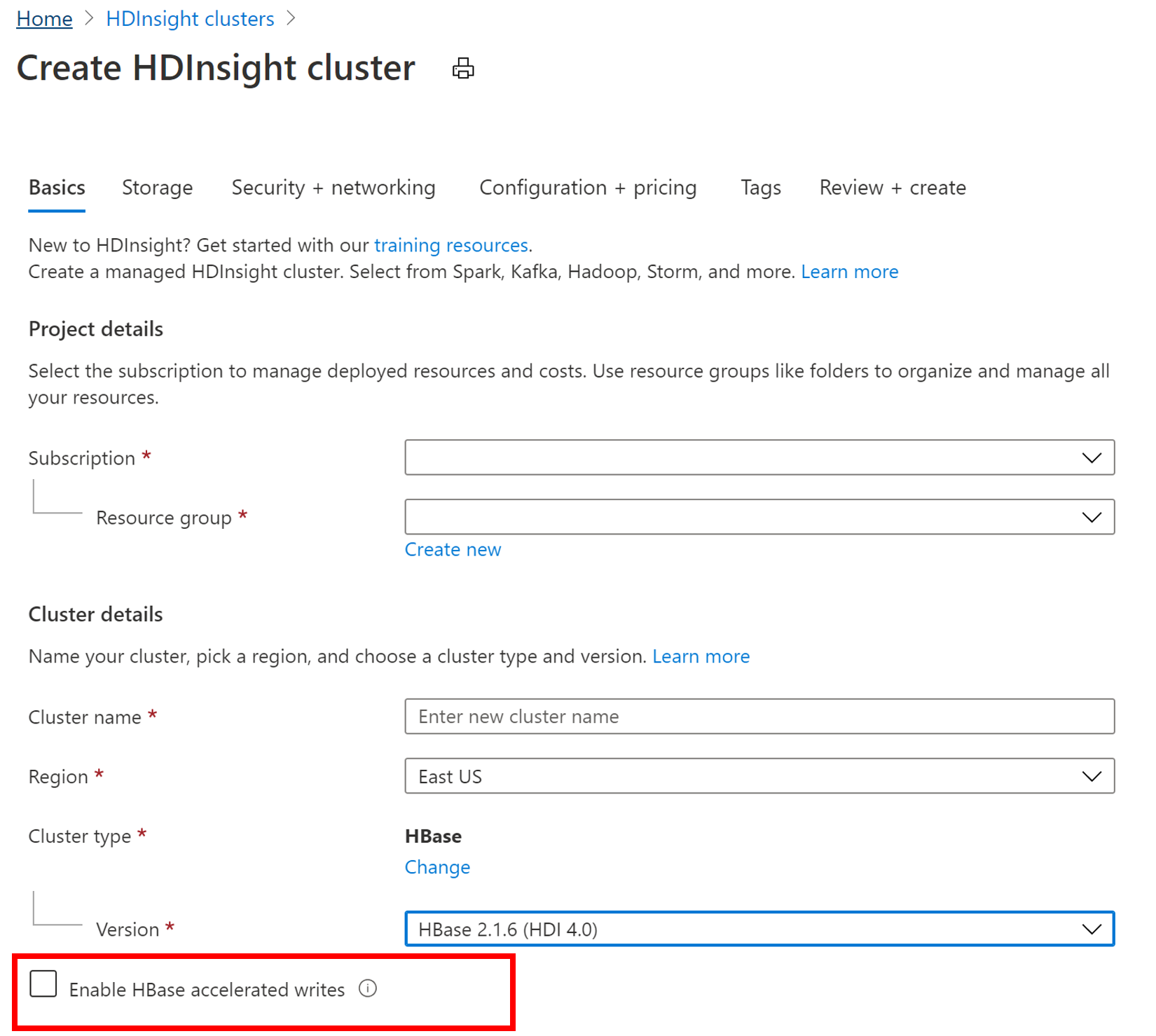
Verificar se o recurso de Gravações Aceleradas estava habilitado
Você pode usar o portal do Azure para verificar se o recurso Gravações Aceleradas está habilitado em um cluster do HBASE.
- Pesquise seu cluster do HBASE no portal do Azure.
- Selecione a folha Tamanho do Cluster.
- Os discos Premium por nó de trabalho serão exibidos.
Como ajustar o tamanho dos clusters do HBASE
Para preservar a durabilidade dos dados, crie um cluster com um mínimo de três nós de trabalho. Depois de criado, você não pode reduzir o cluster para menos de três nós de trabalho.
Libere ou desabilite as tabelas do HBase antes de excluir o cluster, para que você não perca os dados do Write Ahead Log.
flush 'mytable'
disable 'mytable'
Siga etapas semelhantes ao reduzir verticalmente o cluster: libere as tabelas e desative-as para interromper a entrada de dados. Não é possível reduzir verticalmente o cluster para menos de três nós.
Seguir essas etapas garantirá uma redução vertical bem-sucedida e evitará a possibilidade de um namenode entrar no modo de segurança devido a arquivos temporários ou replicados.
Se o namenode entrar em modo de segurança após uma redução vertical, use os comandos do hdfs para replicar novamente os blocos sub-replicados e tirar o hdfs do modo de segurança. Essa nova replicação permitirá que você reinicie o HBase com êxito.
Próximas etapas
- Documentação oficial do Apache HBase no recurso Write Ahead Log
- Para atualizar o cluster do Apache HBase do HDInsight para usar Gravações Aceleradas, veja Migrar um cluster do Apache HBase para uma nova versão.