Guia de Início Rápido: Introdução ao Azure Machine Learning
APLICA-SE A:  SDK do Python azure-ai-ml v2 (atual)
SDK do Python azure-ai-ml v2 (atual)
Este tutorial é uma introdução a algumas dos recursos mais utilizados do serviço do Azure Machine Learning. Nele, você criará, registrará e implantará um modelo. Este tutorial ajudará você a se familiarizar com os principais conceitos do Azure Machine Learning e o uso mais comum deles.
Você aprenderá a executar um trabalho de treinamento em um recurso de computação escalonável, implantá-lo e, por fim, testar a implantação.
Você criará um script de treinamento para lidar com a preparação de dados, treinar e registrar um modelo. Depois de treinar o modelo, implemente-o como um ponto de extremidade que será chamado para inferência.
As seguintes etapas são necessárias:
- Configurar um identificador para seu workspace do Azure Machine Learning
- Criar seu script de treinamento
- Criar um recurso de computação escalonável, um cluster de computação
- Criar e executar o trabalho de comando que irá executar o script de treinamento no cluster de computação, configurado com o ambiente de trabalho apropriado
- Exibir a saída do script de treinamento
- Implantar o modelo recém-treinado como um ponto de extremidade
- Chamar o ponto de extremidade do Azure Machine Learning para inferência
Assista a esse vídeo para obter uma visão geral das etapas nesse guia de início rápido.
Pré-requisitos
-
Para usar o Azure Machine Learning, primeiro você precisará de um workspace. Se você não tiver um, conclua Criar recursos necessários para começar para criar um workspace e saber mais sobre como usá-lo.
-
Entre no estúdio e selecione seu workspace, se ele ainda não estiver aberto.
-
Abra ou crie um notebook em seu workspace:
- Crie um novo notebook, se você quiser copiar/colar código em células.
- Ou abra tutoriais/get-started-notebooks/quickstart.ipynb na seção Exemplos do estúdio. Em seguida, selecione Clonar para adicionar o notebook aos seus Arquivos. (Veja onde encontrar Exemplos.)
Definir o kernel
Na barra superior acima do notebook aberto, crie uma instância de computação se você ainda não tiver uma.

Se a instância de computação for interrompida, selecione Iniciar computação e aguarde até que ela esteja em execução.

Verifique se o kernel, encontrado no canto superior direito, é
Python 3.10 - SDK v2. Caso contrário, use a lista suspensa para selecionar esse kernel.
Se você vir uma barra de notificação dizendo que você precisa de autenticação, selecione Autenticar.



Importante
O restante deste tutorial contém células do notebook do tutorial. Copie-as/cole-as no novo notebook ou, no caso de um notebook clonado, mude para ele.
Criar identificador para o workspace
Antes de nos aprofundarmos no código, você precisa de uma maneira de referenciar seu workspace. O workspace é o recurso de nível superior para o Azure Machine Learning. Ele fornece um local centralizado para trabalhar com todos os artefatos que você cria ao usar o Azure Machine Learning.
Você criará um ml_client para um identificador do workspace. Em seguida, você usará ml_client para gerenciar recursos e trabalhos.
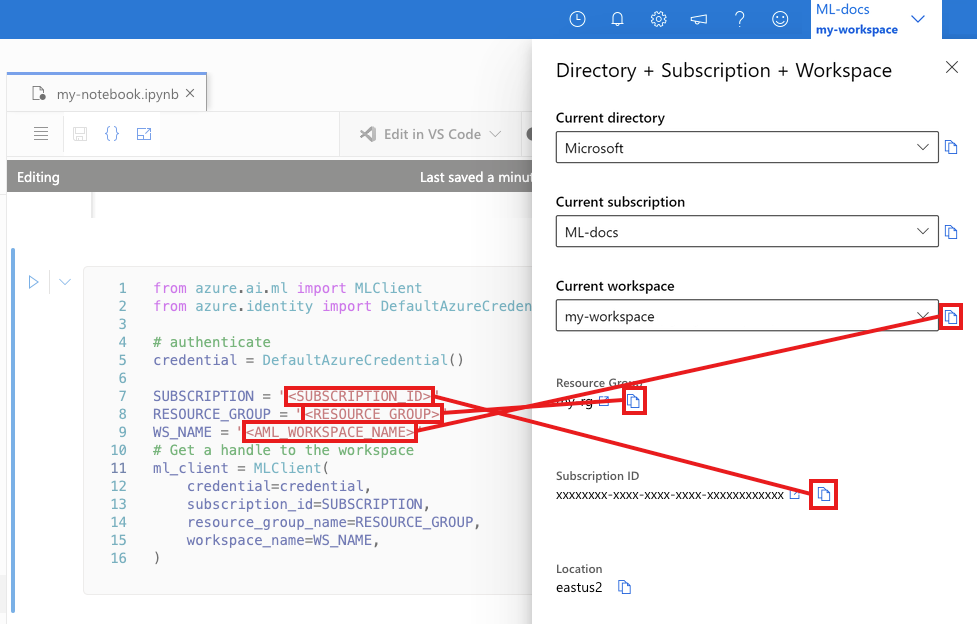
Na próxima célula, insira a ID da Assinatura, o nome do Grupo de Recursos e o nome do Espaço de trabalho. Para encontrar esses valores:
- Na barra de ferramentas do Estúdio do Azure Machine Learning superior direito, selecione o nome do espaço de trabalho.
- Copie o valor do workspace, do grupo de recursos e da ID da assinatura no código.
- Será necessário copiar um valor, fechar a área e colar, em seguida, voltar para o próximo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Observação
A criação do MLClient não se conectará ao espaço de trabalho. A inicialização do cliente é lenta, e ele aguarda a primeira vez que precisa fazer uma chamada (isso acontecerá na próxima célula de código).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Criar o script de treinamento
Para começar, você criará o script de treinamento: o arquivo Python main.py.
Primeiro crie uma pasta de origem para o script:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Esse script lida com o pré-processamento dos dados, dividindo-os em dados de teste e de treinamento. Em seguida, ele os consome para treinar um modelo baseado em árvore e retornar o modelo de saída.
O MLFlow será usado para registrar os parâmetros e as métricas durante a execução do pipeline.
A célula abaixo usa a mágica IPython para gravar o script de treinamento no diretório que você acabou de criar.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Como é possível ver neste script, uma vez que o modelo é treinado, o arquivo de modelo é salvo e registrado no workspace. Agora você pode usar o modelo registrado em pontos de extremidade de inferência.
Talvez seja necessário selecionar Atualizar para ver a nova pasta e o script em seus Arquivos.
Configurar o comando
Com esse script que pode executar as tarefas desejadas, e um cluster de computação para executar o script, use um comando de uso geral para executar ações de linha de comando. Essa ação de linha de comando pode chamar diretamente comandos do sistema ou executar um script.
Aqui, você criará as variáveis de entrada para especificar os dados de entrada, a taxa de divisão, a taxa de aprendizado e o nome do modelo registrado. O script de comando será usado para o seguinte:
- Use um ambiente que defina bibliotecas de software e runtime necessárias para o script de treinamento. O Azure Machine Learning fornece muitos ambientes coletados ou prontos para uso, que são úteis para cenários comuns de treinamento e inferência. Você usará um desses ambientes aqui. No Tutorial: treinar um modelo no Azure Machine Learning, você aprenderá a criar um ambiente personalizado.
- Configurar a própria ação da linha de comando (
python main.pyneste caso). As entradas/saídas são acessíveis no comando por meio da notação${{ ... }}. - Neste exemplo, acessamos os dados de um arquivo na Internet.
- Já que um recurso de computação não foi especificado, o script será executado em um cluster de computação sem servidor que será criado automaticamente.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="credit_default_prediction",
)
Enviar o trabalho
Agora é hora de enviar o trabalho a ser executado no Azure Machine Learning. Desta vez, você usará create_or_update em ml_client.
ml_client.create_or_update(job)
Exiba a saída do trabalho e aguarde a conclusão dele
Veja o trabalho no Estúdio do Azure Machine Learning selecionando o link na saída da célula anterior.
A saída desse trabalho será parecido com este no Estúdio do Azure Machine Learning. Explore as guias para obter diversos detalhes, como métricas, saídas etc. Depois de concluído, o trabalho registrará um modelo no workspace como resultado do treinamento.
Importante
Aguarde até que o status do trabalho seja “Concluído” para retornar a este notebook e continuar. O trabalho levará de dois a três minutos para ser executado. Pode levar mais tempo (até 10 minutos) caso o cluster de computação tenha sido reduzido verticalmente para zero nós e o ambiente personalizado ainda esteja sendo criado.
Implantar o modelo como um ponto de extremidade online
Agora, implante o modelo de machine learning como um serviço Web na nuvem do Azure, um online endpoint.
Para implantar um serviço de machine learning, você usará o modelo registrado.
Criar um ponto de extremidade online
Agora que você tem um modelo registrado, é hora de criar seu ponto de extremidade online. O nome do ponto de extremidade deve ser exclusivo em toda a região do Azure. Para este tutorial, você criará um nome exclusivo usando UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Criar o ponto de extremidade:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Observação
Espere que a criação do ponto de extremidade leve alguns minutos.
Depois que o ponto de extremidade tiver sido criado, você poderá recuperá-lo conforme mostrado abaixo:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Implantar o modelo ao ponto de extremidade
Depois que o ponto de extremidade for criado, implante o modelo com o script de entrada. Cada ponto de extremidade pode ter diversas implantações. O tráfego direto para essas implantações pode ser especificado usando regras. Aqui você criará uma única implantação que manipula 100% do tráfego de entrada. Escolhemos um nome de cor para a implantação, por exemplo, implantações azuis, verdes e vermelhas, o que é arbitrário.
Confira a página Modelos no Estúdio do Azure Machine Learning para identificar a última versão do modelo registrado. Como alternativa, o código a seguir recuperará o número de versão mais recente para você usar.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Implante a versão mais recente do modelo.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Observação
Espere que essa implantação leve aproximadamente de 6 a 8 minutos.
Quando a implantação for concluída, você estará pronto para testá-la.
Teste com uma consulta de amostra
Agora que o modelo está implantado no ponto de extremidade, você pode executar a inferência com ele.
Crie um arquivo de solicitação de exemplo seguindo o design esperado no método de execução no script de pontuação.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Limpar os recursos
Se você não usar o ponto de extremidade, exclua-o para parar de usar o recurso. Verifique se nenhuma outra implantação está usando um ponto de extremidade antes de excluí-lo.
Observação
Espere que a exclusão completa leve aproximadamente 20 minutos.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Parar a instância de computação
Se não for usá-la agora, pare a instância de computação:
- No estúdio, na área de navegação à esquerda, selecione Computação.
- Nas guias superiores, selecione Instâncias de computação
- Selecione a instância de computação na lista.
- Na barra de ferramentas superior, selecione Parar.
Excluir todos os recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos em outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não pretende usar nenhum dos recursos criados, exclua-os para não gerar custos:
No portal do Azure, selecione Grupos de recursos no canto esquerdo.
Selecione o grupo de recursos que você criou por meio da lista.
Selecione Excluir grupo de recursos.
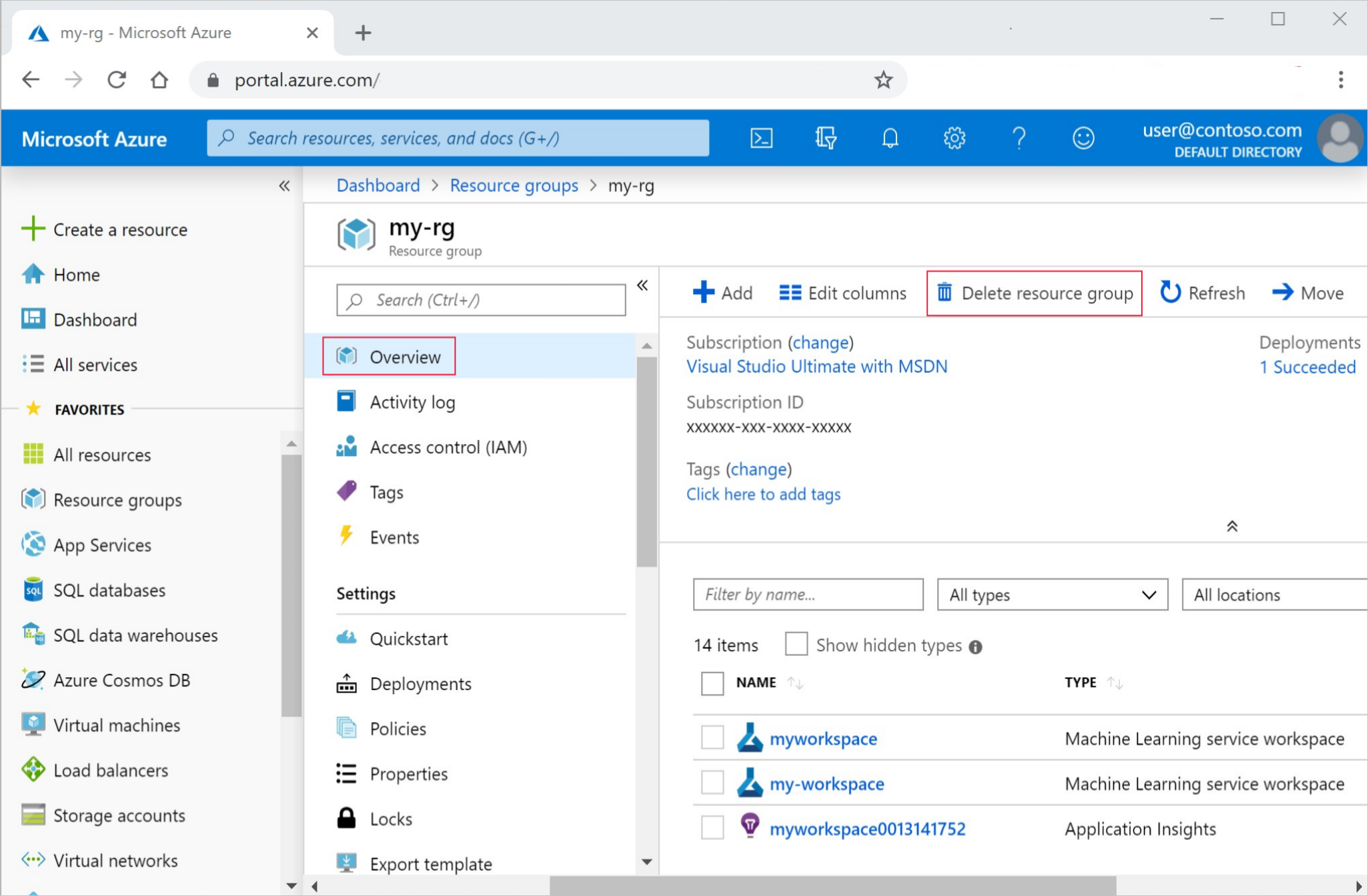
Insira o nome do grupo de recursos. Em seguida, selecione Excluir.
Próximas etapas
Agora que você tem uma ideia do que está envolvido no treinamento e na implantação de um modelo, saiba mais sobre o processo nestes tutoriais:
| Tutorial | Descrição |
|---|---|
| Carregar, acessar e explorar seus dados no Azure Machine Learning | Armazenar dados grandes na nuvem e recuperá-los de notebooks e scripts |
| Modelar o desenvolvimento em uma estação de trabalho de nuvem | Começar a criar protótipos e desenvolver modelos de machine learning |
| Treinar um modelo no Azure Machine Learning | Aprofunde-se nos detalhes do treinamento de um modelo |
| Implantar um modelo como um ponto de extremidade online | Aprofunde-se nos detalhes da implantação de um modelo |
| Criar pipelines de machine learning de produção | Divida uma tarefa completa de machine learning em um fluxo de trabalho de várias etapas. |