Coleta e agregação de eventos utilizando o Diagnóstico do Windows Azure
Quando você estiver executando um cluster de Service Fabric do Azure, é uma boa ideia coletar os logs de todos os nós em um local central. Ter os logs em um local central ajuda a analisar e solucionar problemas no cluster ou nos aplicativos e serviços em execução nesse cluster.
Uma maneira de fazer upload e coletar logs é utilizar a extensão WAD (Diagnóstico do Windows Azure) que faz upload dos logs no Armazenamento do Azure e, além disso, possui a opção de enviar os logs para o Azure Application Insights ou Hubs de Evento. Também é possível utilizar um processo externo para ler os eventos do armazenamento e colocá-los em um produto da plataforma de análise, como os logs do Azure Monitor ou outra solução de análise de log.
Observação
Recomendamos que você use o módulo Az PowerShell do Azure para interagir com o Azure. Confira Instalar o Azure PowerShell para começar. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Pré-requisitos
As ferramentas a seguir são usadas neste artigo:
Eventos de plataforma do Service Fabric
O Service Fabric configura alguns canais de log prontos, dos quais os canais a seguir são pré-configurados com a extensão para enviar dados de monitoramento e diagnósticos para uma tabela de armazenamento ou em outro lugar:
- Eventos operacionais: operações de nível superior que a plataforma do Service Fabric executa. Os exemplos incluem criação de aplicativos e serviços, alterações de estado do nó e informações de atualização. Eles são emitidos como eventos de logs do Rastreamento de Eventos para Windows (ETW)
- Eventos do modelo de programação Reliable Actors
- Eventos do modelo de programação Reliable Services
Implantar a extensão de Diagnóstico através do portal
A primeira etapa na coleta de logs é implantar a extensão de Diagnóstico nos nós do conjunto de dimensionamento de máquinas virtuais no cluster do Service Fabric. A extensão de Diagnóstico coleta logs em cada VM e os carrega para a conta de armazenamento especificada. As etapas a seguir descrevem como fazer isso para clusters novos e existentes por meio do Portal do Azure e modelos do Azure Resource Manager.
Implantar a extensão de Diagnóstico como parte da criação de cluster por meio do portal do Azure
Ao criar o cluster, na etapa de configuração do cluster, expanda as configurações opcionais e verifique se o Diagnóstico está definido como On (a configuração padrão).
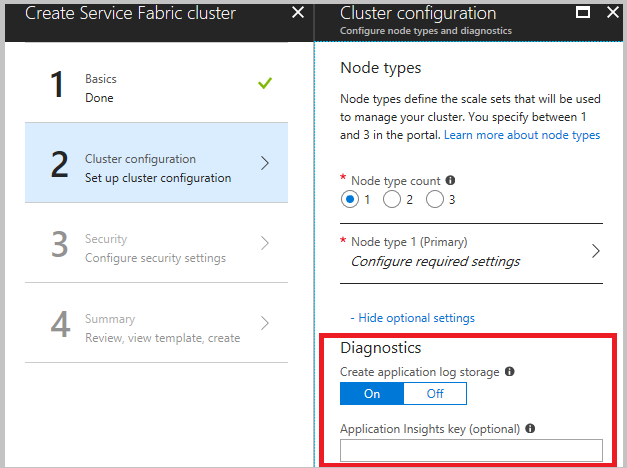
É altamente recomendável que você baixe o modelo antes de clicar em Criar na etapa final. Para obter detalhes, confira Setup a Service Fabric cluster by using an Azure Resource Manager template (Configurar um cluster do Service Fabric usando um modelo do Azure Resource Manager). Você precisa do modelo para fazer alterações nos canais (listados acima) para coletar dados.
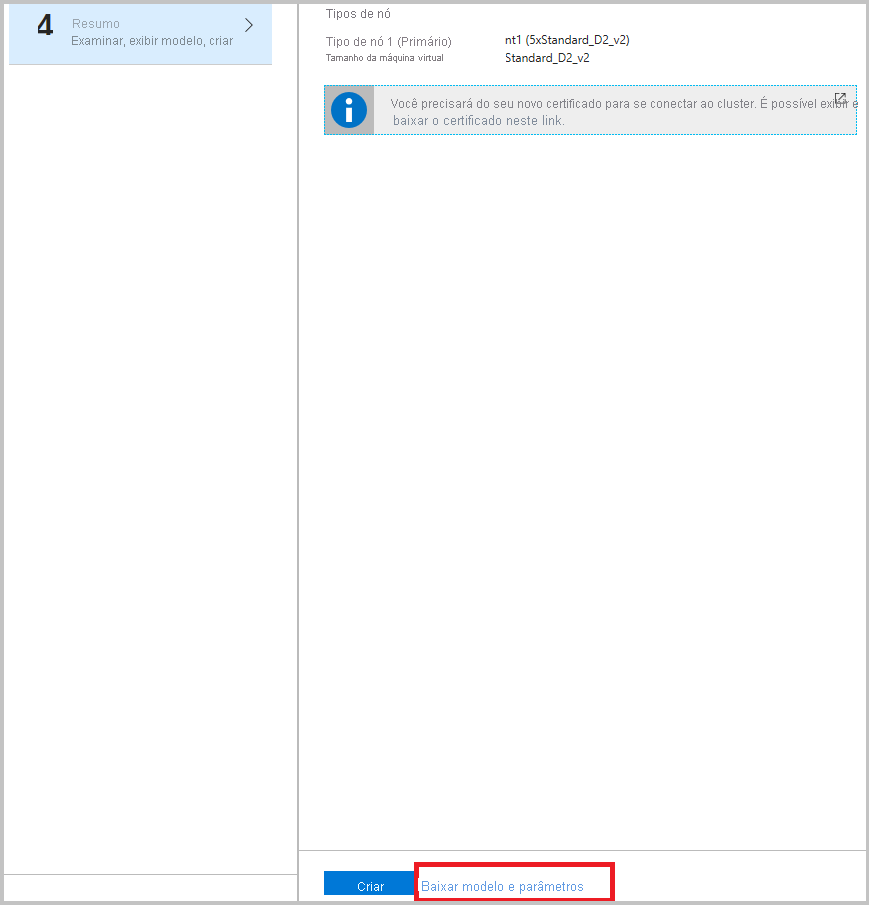
Agora que você está agregando eventos no Armazenamento do Azure, configure os logs do Azure Monitor para obter insights e consultá-los no Portal de logs do Azure Monitor
Observação
Atualmente, não há como filtrar ou preparar os eventos que são enviados para as tabelas. Se você não implementar um processo para remover eventos da tabela, a tabela continuará crescendo (o limite padrão é 50 GB). Instruções sobre como mudar isso estão descritas mais adiante neste artigo. Além disso, há um exemplo de um serviço de limpeza de dados em execução no exemplo Watchdog, e é recomendável que você grave um para você mesmo, a menos que haja uma boa razão para armazenar logs além de um período de 30 ou 90 dias.
Implantar a extensão de Diagnóstico por meio do Azure Resource Manager
Criar um cluster com a extensão de diagnóstico
Para criar um cluster usando o Resource Manager, você precisa adicionar a configuração de Diagnóstico JSON ao modelo do Resource Manager completo. Fornecemos um exemplo de modelo de Gerenciador de Recursos de cluster de cinco VMs com configuração de Diagnóstico adicionada a ele como parte dos exemplos do modelo de Gerenciador de Recursos. Você pode vê-lo nesse local na Galeria de exemplos do Azure: cluster cinco nós com exemplo de modelo do Gerenciador de Recursos de Diagnóstico.
Para ver a configuração do Diagnóstico no modelo do Resource Manager, abra o arquivo azuredeploy.json e pesquise IaaSDiagnostics. Para criar um cluster usando este modelo, selecione o botão Implantar no Azure disponível no link anterior.
Como alternativa você pode baixar o exemplo de Gerenciador de Recursos, fazer suas alterações e criar um cluster com o modelo modificado usando o comando New-AzResourceGroupDeployment em uma janela do Azure PowerShell. Consulte no código a seguir para ver os parâmetros que você passa para o comando. Para obter informações detalhadas sobre como implantar um grupo de recursos usando o PowerShell, consulte o artigo Deploy a resource group with the Azure Resource Manager template (Implantar o grupo de recursos com o modelo do Azure Resource Manager).
Adicionar a extensão de diagnóstico a um cluster existente
Se você tiver um cluster existente que não tenha o Diagnóstico implantado, poderá adicioná-lo ou atualizá-lo por meio do modelo de cluster. Modifique o modelo do Resource Manager usado para criar o cluster existente ou baixe o modelo do portal, conforme descrito anteriormente. Modifique o arquivo template.json executando as tarefas a seguir:
Adicione um novo recurso de armazenamento ao modelo, adicionando à seção de recursos.
{
"apiVersion": "2018-07-01",
"type": "Microsoft.Storage/storageAccounts",
"name": "[parameters('applicationDiagnosticsStorageAccountName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "[parameters('applicationDiagnosticsStorageAccountType')]"
"tier": "standard"
},
"tags": {
"resourceType": "Service Fabric",
"clusterName": "[parameters('clusterName')]"
}
},
Em seguida, adicione à seção de parâmetros logo após as definições da conta de armazenamento, entre supportLogStorageAccountName. Substitua o texto do espaço reservado nome da conta de armazenamento aqui pelo nome da conta de armazenamento que você deseja.
"applicationDiagnosticsStorageAccountType": {
"type": "string",
"allowedValues": [
"Standard_LRS",
"Standard_GRS"
],
"defaultValue": "Standard_LRS",
"metadata": {
"description": "Replication option for the application diagnostics storage account"
}
},
"applicationDiagnosticsStorageAccountName": {
"type": "string",
"defaultValue": "**STORAGE ACCOUNT NAME GOES HERE**",
"metadata": {
"description": "Name for the storage account that contains application diagnostics data from the cluster"
}
},
Em seguida, atualize a seção VirtualMachineProfile do arquivo template.json adicionando o conteúdo a seguir dentro da matriz extensions. Adicione uma vírgula no início ou no fim, dependendo de onde será inserido.
{
"name": "[concat(parameters('vmNodeType0Name'),'_Microsoft.Insights.VMDiagnosticsSettings')]",
"properties": {
"type": "IaaSDiagnostics",
"autoUpgradeMinorVersion": true,
"protectedSettings": {
"storageAccountName": "[parameters('applicationDiagnosticsStorageAccountName')]",
"storageAccountKey": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', parameters('applicationDiagnosticsStorageAccountName')),'2015-05-01-preview').key1]",
"storageAccountEndPoint": "https://core.windows.net/"
},
"publisher": "Microsoft.Azure.Diagnostics",
"settings": {
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
"StorageAccount": "[parameters('applicationDiagnosticsStorageAccountName')]"
},
"typeHandlerVersion": "1.5"
}
}
Após modificar o arquivo template.json conforme descrito, republique o modelo do Resource Manager. Se o modelo tiver sido exportado, a execução do arquivo deploy.ps1 republicará o modelo. Após implantar, verifique se o status de ProvisioningState é Com êxito.
Dica
Se você pretende implantar contêineres para seu cluster, habilite o WAD para acompanhar as estatísticas do docker adicionando eles à sua seção WadCfg > DiagnosticMonitorConfiguration.
"DockerSources": {
"Stats": {
"enabled": true,
"sampleRate": "PT1M"
}
},
Atualizar cota de armazenamento
Como as tabelas preenchidas pela extensão aumentam até que a cota seja atingida, convém considerar a redução do tamanho da cota. O valor padrão é 50 GB e é configurável no modelo no overallQuotaInMB campo em DiagnosticMonitorConfiguration
"overallQuotaInMB": "50000",
Configurações de coleção de log
Logs de canais adicionais também estão disponíveis para coleção, aqui estão algumas das configurações mais comuns que você pode fazer no modelo para clusters em execução no Azure.
Canal operacional-base: habilitada por padrão, operações de alto nível executadas por Service Fabric e o cluster, incluindo eventos para um nó surgindo, um novo aplicativo sendo implantado ou uma reversão de atualização, etc. Para obter uma lista de eventos, consulte Eventos de canal operacional.
"scheduledTransferKeywordFilter": "4611686018427387904"Canal operacional - Detalhado: Inclui relatórios de integridade e balanceamento de cargo, além de tudo no canal operacional de base. Esses eventos são gerados pelo sistema ou seu código usando a integridade ou APIs de relatórios de carga como ReportPartitionHealth ou ReportLoad. Para exibir esses eventos no Visualizador de Eventos de Diagnóstico do Visual Studio, adicione "Microsoft-ServiceFabric:4:0x4000000000000008" à lista de provedores de ETW.
"scheduledTransferKeywordFilter": "4611686018427387912"Canal de Dados e Mensagens- Base: logs e eventos críticos gerados no sistema de mensagens (atualmente, apenas o ReverseProxy) e o caminho de dados, além dos logs do canal operacional detalhado. Esses eventos são falhas de processamento de solicitações e outros problemas críticos no ReverseProxy, bem como solicitações processadas. Essa é a nossa recomendação para o registro em log abrangente. Para exibir esses eventos no Visualizador de Eventos de Diagnóstico do Visual Studio, adicione "Microsoft-ServiceFabric:4:0x4000000000000010" à lista de provedores de ETW.
"scheduledTransferKeywordFilter": "4611686018427387928"Canal de Dados e Mensagens – Detalhado: canal detalhado que contém todos os logs não críticos dos dados e das mensagens no cluster e o canal operacional detalhado. Para obter a solução de problemas de todos eventos de proxy reverso, veja o guia de diagnóstico de proxy reverso. Para exibir esses eventos no Visualizador de Eventos de Diagnóstico do Visual Studio, adicione "Microsoft-ServiceFabric:4:0x4000000000000020" à lista de provedores de ETW.
"scheduledTransferKeywordFilter": "4611686018427387944"
Observação
Este canal tem um volume muito alto de eventos, habilitando a coleção de eventos neste canal detalhado resulta na rápida geração de uma grande quantidade de rastreamentos e pode consumir a capacidade de armazenamento. Ative esta opção somente quando absolutamente necessário.
Para habilitar o Canal Operacional de Base nossa recomendação para o log abrangente com a menor quantidade de ruído, o EtwManifestProviderConfiguration no WadCfg do seu modelo seria semelhante ao seguinte:
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
Coletar a partir de novos canais EventSource
Para atualizar o Diagnóstico para coletar logs a partir de novos canais EventSource que representam um novo aplicativo que você está prestes a implantar, execute as mesmas etapas anteriores para configurar o Diagnóstico para um cluster existente.
Atualize a seção EtwEventSourceProviderConfiguration no arquivo template.json para adicionar entradas para novos canais de EventSource antes de aplicar a atualização de configuração usando o comando New-AzResourceGroupDeployment do PowerShell. O nome da origem do evento é definido como parte do seu código no arquivo Visual Studio-generated ServiceEventSource.cs.
Por exemplo, se a origem do evento for denominada My-Eventsource, adicione o seguinte código para colocar os eventos de My-Eventsource em uma tabela chamada MyDestinationTableName.
{
"provider": "My-Eventsource",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "MyDestinationTableName"
}
}
Para coletar contadores de desempenho ou logs de eventos, modifique o modelo do Resource Manager usando os exemplos fornecidos em Criar uma máquina virtual do Windows com monitoramento e diagnóstico usando um modelo do Azure Resource Manager. Em seguira, republique o modelo do Resource Manager.
Coletar contadores de desempenho
Para coletar métricas de desempenho do seu cluster, adicione os contadores de desempenho para o "WadCfg > DiagnosticMonitorConfiguration" no modelo do Resource Manager para o cluster. Consulte Monitoramento do desempenho com WAD para obter etapas sobre como modificar seu WadCfg para coletar contadores de desempenho específicos. Consulte Contadores de desempenho do Service Fabric para uma lista dos contadores de desempenho que recomendamos coletar.
Se você estiver usando um coletor do Application Insights, conforme descrito na seção abaixo e deseja que essas métricas sejam exibidas no Application Insights, certifique-se de adicionar o nome do coletor na seção "coletores", como mostrado acima. Isso enviará automaticamente os contadores de desempenho que são configurados individualmente para o recurso do Application Insights.
Enviar logs para o Application Insights
Configurar o Application Insights com WAD
Observação
No momento, isso só é aplicável a clusters do Windows.
Há duas maneiras principais de enviar dados do WAD para o Aplicativo Azure insights, que é obtido adicionando um coletor de Application Insights à configuração do WAD, por meio do portal do Azure ou por meio de um modelo de Azure Resource Manager.
Adicionar uma chave de instrumentação do Application Insights ao criar um cluster no portal do Azure
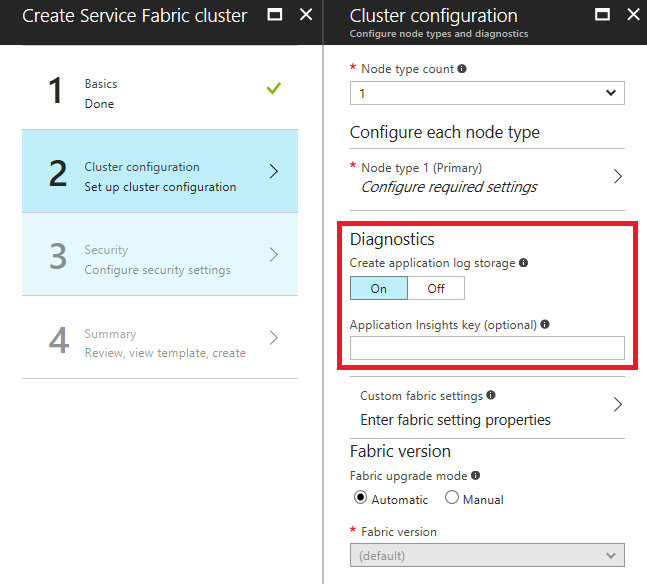
Ao criar um cluster, se o Diagnóstico estiver ativado em "On", um campo opcional para inserir uma chave de Instrumentação do Application Insights será exibido. Se você colar sua chave do Application Insights aqui, o coletor do Application Insights será configurado automaticamente no modelo do Resource Manager usado para implantar o cluster.
Adicionar o coletor do Application Insights para o modelo do Resource Manager
No "WadCfg" do modelo do Resource Manager, adicione um "Coletor", incluindo as duas alterações a seguir:
Adicione a configuração do coletor diretamente após a conclusão da declaração de
DiagnosticMonitorConfiguration:"SinksConfig": { "Sink": [ { "name": "applicationInsights", "ApplicationInsights": "***ADD INSTRUMENTATION KEY HERE***" } ] }Inclua o Coletor no
DiagnosticMonitorConfigurationao adicionar a linha a seguir noDiagnosticMonitorConfigurationdoWadCfg(antes da declaração deEtwProviders):"sinks": "applicationInsights"
Nos dois snippets de código anteriores, o nome "applicationInsights" era usado para descrever o coletor. Isso não é um requisito e, enquanto o nome do coletor estiver incluído em "coletores", você poderá definir o nome para qualquer cadeia de caracteres.
Atualmente, os logs do cluster aparecem como rastreios no visualizador de log do Application Insights. Como a maioria dos rastreamentos originados da plataforma é de nível "Informativo", você também pode considerar alterar a configuração do coletor para enviar apenas logs do tipo "Aviso" ou "Erro". Isso pode ser feito adicionando "Canais" ao seu coletor, conforme demonstrado neste artigo.
Observação
Se você usar uma chave do Application Insights incorreta no portal ou no modelo do Resource Manager, será necessário alterar manualmente a chave e atualizá-la / reimplementá-la.
Próximas etapas
Depois de configurar corretamente o diagnóstico do Azure, você verá os dados nas Tabelas de armazenamento dos logs do ETW e EventSource. Se você optar por usar os logs do Azure Monitor, Kibana ou qualquer outra plataforma de análise e visualização de dados que não foi configurada diretamente no modelo do Resource Manager, certifique-se de configurar a plataforma de sua escolha para ler os dados dessas tabelas de armazenamento. Fazer isso para logs do Azure Monitor é relativamente simples e é explicado em Análise de eventos e logs. O Application Insights é um pouco diferente nesse sentido, pois ele pode ser configurado como parte da configuração da extensão de diagnóstico, então consulte o artigo apropriado se optar por usar o AI.
Observação
Atualmente, não há nenhuma maneira de filtrar ou limpar os eventos que são enviados para a tabela. Se você não implantar um processo para remover eventos da tabela, a tabela continuará crescendo. Atualmente, há um exemplo de um serviço de limpeza de dados em execução no exemplo Watchdog, e é recomendável que você grave um para você mesmo, a menos que haja uma boa razão para armazenar logs além de um período de 30 ou 90 dias.
- Aprenda a coletar contadores de desempenho ou logs usando a extensão de Diagnóstico
- Visualização e Análise de Eventos com o Application Insights
- Análise e visualização de eventos com logs do Azure Monitor
- Visualização e Análise de Eventos com o Application Insights
- Análise e visualização de eventos com logs do Azure Monitor