Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() IoT Edge 1.1
IoT Edge 1.1
Importante
O IoT Edge 1.1 data de término do suporte foi 13 de dezembro de 2022. Confira o Ciclo de Vida do Produto da Microsoft para obter informações sobre o suporte deste produto, serviço, tecnologia ou API. Para obter mais informações sobre como atualizar para a versão mais recente do IoT Edge, consulte Update IoT Edge.
Com frequência, os aplicativos de IoT querem aproveitar a nuvem inteligente e a borda inteligente. Neste tutorial, orientamos você pelo treinamento de um modelo de machine learning com dados coletados de dispositivos IoT na nuvem, implantando esse modelo no IoT Edge e mantendo e refinando o modelo periodicamente.
Observação
Os conceitos neste conjunto de tutoriais se aplicam a todas as versões do IoT Edge, mas o dispositivo de exemplo criado para experimentar o cenário executa o IoT Edge versão 1.1.
O objetivo principal deste tutorial é introduzir o processamento de dados de IoT com aprendizado de máquina, especificamente na computação de borda. Embora toquemos em muitos aspectos de um fluxo de trabalho de machine learning geral, este tutorial não se destina a uma introdução detalhada ao aprendizado de máquina. Como um caso em questão, não tentamos criar um modelo altamente otimizado para o caso de uso - apenas fazemos o suficiente para ilustrar o processo de criação e uso de um modelo viável para processamento de dados IoT.
Esta seção do tutorial discute:
- Os pré-requisitos para concluir as partes subsequentes do tutorial.
- O público-alvo do tutorial.
- O caso de uso que o tutorial simula.
- O processo geral que o tutorial segue para atender ao caso de uso.
Caso você não tenha uma assinatura do Azure, crie uma conta gratuita do Azure antes de começar.
Pré-requisitos
Para concluir o tutorial, você precisa de acesso a uma assinatura do Azure na qual você tem direitos para criar recursos. Vários dos serviços usados neste tutorial incorrerão em encargos do Azure. Se você ainda não tiver uma assinatura do Azure, poderá começar a usar uma Conta Gratuita do Azure.
Você também precisa de um computador com o PowerShell instalado, no qual você pode executar scripts para configurar uma Máquina Virtual do Azure como sua máquina de desenvolvimento.
Neste documento, usamos o seguinte conjunto de ferramentas:
Um hub IoT do Azure para captura de dados
Azure Notebooks como nosso front-end principal para preparação de dados e experimentação de aprendizado de máquina. Executar código Python em um notebook em um subconjunto dos dados de exemplo é uma ótima maneira de obter uma reviravolta rápida iterativa e interativa durante a preparação de dados. Os jupyter notebooks também podem ser usados para preparar scripts para serem executados em escala em um back-end de computação.
O Azure Machine Learning como um back-end para aprendizado de máquina em larga escala e para geração de imagens de aprendizado de máquina. Acionamos o back-end do Azure Machine Learning usando scripts preparados e testados em notebooks Jupyter.
Azure IoT Edge para aplicação fora da nuvem de um modelo de aprendizado de máquina
Obviamente, há outras opções disponíveis. Em determinados cenários, por exemplo, o IoT Central pode ser usado como uma alternativa sem código para capturar dados de treinamento iniciais de dispositivos IoT.
Público-alvo e funções
Esse conjunto de artigos destina-se a desenvolvedores sem experiência anterior em desenvolvimento de IoT ou machine learning. Implantar o aprendizado de máquina na extremidade requer conhecimento de como conectar uma ampla gama de tecnologias. Portanto, este tutorial aborda todo um cenário de ponta a ponta para demonstrar uma maneira de unir essas tecnologias para uma solução de IoT. Em um ambiente real, essas tarefas podem ser distribuídas entre várias pessoas com diferentes especializações. Por exemplo, os desenvolvedores se concentrariam no dispositivo ou no código de nuvem, enquanto os cientistas de dados projetaram os modelos de análise. Para permitir que um desenvolvedor individual conclua este tutorial com êxito, fornecemos diretrizes complementares com insights e links para mais informações que esperamos ser suficientes para entender o que está sendo feito, bem como por quê.
Como alternativa, você pode se unir a colegas de trabalho de diferentes funções para seguir o tutorial juntos, reunindo sua experiência completa e aprendendo como uma equipe como as coisas se encaixam.
Em ambos os casos, para ajudar a orientar os leitores, cada artigo neste tutorial indica a função do usuário. Essas funções incluem:
- Desenvolvimento em nuvem (incluindo um desenvolvedor de nuvem trabalhando em uma capacidade de DevOps)
- Análise de dados
Caso de uso: manutenção preditiva
Baseamos esse cenário em um caso de uso apresentado na Conferência sobre Prognósticos e Gerenciamento de Integridade (PHM08) em 2008. O objetivo é prever a RUL (vida útil) restante de um conjunto de motores de avião turbofan. Esses dados foram gerados usando C-MAPSS, a versão comercial do software MAPSS (Modular Aero-Propulsion System Simulation). Esse software fornece um ambiente de simulação de motor turbofan flexível para simular facilmente as condições, controle e parâmetros do motor.
Os dados usados neste tutorial são obtidos do conjunto de dados de simulação de degradação do mecanismo Turbofan.
No arquivo README:
Cenário experimental
Os conjuntos de dados consistem em várias séries temporais multivariadas. Cada conjunto de dados é dividido ainda mais em subconjuntos de treinamento e teste. Cada série temporal é de um mecanismo diferente, ou seja, os dados podem ser considerados de uma frota de mecanismos do mesmo tipo. Cada mecanismo começa com diferentes graus de desgaste inicial e variação de fabricação que são desconhecidos para o usuário. Esse desgaste e variação é considerado normal, ou seja, não é considerado uma condição de falha. Há três configurações operacionais que têm um efeito substancial no desempenho do mecanismo. Essas configurações também são incluídas nos dados. Os dados estão contaminados com ruído do sensor.
O motor está operando normalmente no início de cada série temporal e desenvolve uma falha em algum momento durante as séries. No conjunto de treinamento, a falha cresce em magnitude até o colapso do sistema. No conjunto de testes, a série temporal termina algum tempo antes da falha do sistema. O objetivo da competição é prever o número de ciclos operacionais restantes antes da falha no conjunto de testes, ou seja, o número de ciclos operacionais após o último ciclo em que o mecanismo continuará operando. Também forneceu um vetor de verdadeiros valores de RUL (Vida Útil Restante) para os dados de teste.
Como os dados foram publicados para uma competição, várias abordagens para derivar modelos de machine learning foram publicadas de forma independente. Descobrimos que estudar exemplos é útil para entender o processo e o raciocínio envolvidos na criação de um modelo de machine learning específico. Veja, por exemplo:
Modelo de previsão de falha do motor da aeronave pelo usuário do GitHub jancervenka.
Degradação do motor turbofan pelo usuário do GitHub hankroark.
Processo
A imagem abaixo ilustra as etapas aproximadas que seguimos neste tutorial:
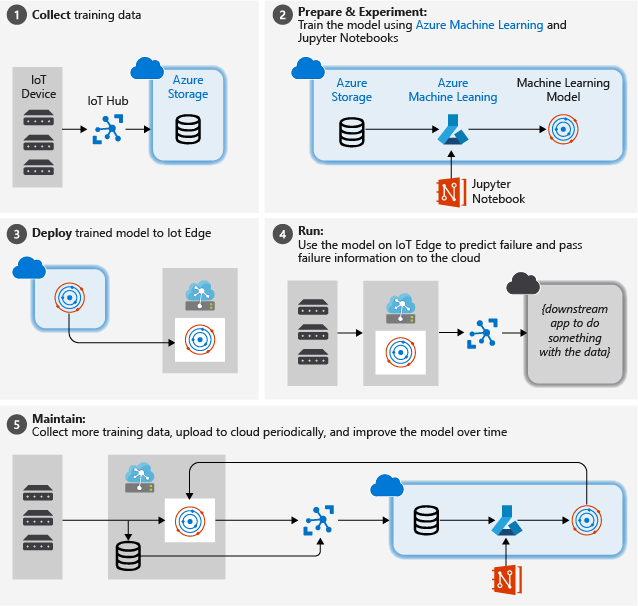
Coletar dados de treinamento: o processo começa coletando dados de treinamento. Em alguns casos, os dados já foram coletados e estão disponíveis em um banco de dados ou em forma de arquivos de dados. Em outros casos, especialmente para cenários de IoT, os dados precisam ser coletados de dispositivos e sensores IoT e armazenados na nuvem.
Presumimos que você não tenha uma coleção de mecanismos turbofan, portanto, os arquivos de projeto incluem um simulador de dispositivo simples que envia os dados do dispositivo da NASA para a nuvem.
Preparar dados. Na maioria dos casos, os dados brutos, conforme coletados de dispositivos e sensores, exigirão preparação para o aprendizado de máquina. Essa etapa pode envolver limpeza de dados, reformatação de dados ou pré-processamento para injetar informações adicionais que o aprendizado de máquina pode utilizar.
Para nossos dados do computador do motor de avião, a preparação de dados envolve o cálculo de tempos de falha explícitos para cada ponto de dados na amostra com base nas observações reais nos dados. Essas informações permitem que o algoritmo de aprendizado de máquina encontre correlações entre padrões de dados reais do sensor e o tempo de vida restante esperado do mecanismo. Esta etapa é altamente específica do domínio.
Crie um modelo de machine learning. Com base nos dados preparados, agora podemos experimentar algoritmos e parametrizações de aprendizado de máquina diferentes para treinar modelos e comparar os resultados uns com os outros.
Nesse caso, para testar, comparamos o resultado previsto calculado pelo modelo com o resultado real observado em um conjunto de mecanismos. No Azure Machine Learning, podemos gerenciar as diferentes iterações de modelos que criamos em um registro de modelo.
Implante o modelo. Depois que tivermos um modelo que atenda aos nossos critérios de êxito, poderemos migrar para a implantação. Isso envolve encapsular o modelo em um aplicativo de serviço Web que pode ser alimentado com dados usando chamadas REST e retornar resultados de análise. Em seguida, o aplicativo de serviço Web é empacotado em um contêiner do Docker, que, por sua vez, pode ser implantado na nuvem ou como um módulo do IoT Edge. Neste exemplo, nos concentramos na implantação no IoT Edge.
Manter e refinar o modelo. Nosso trabalho não é feito depois que o modelo é implantado. Em muitos casos, queremos continuar coletando dados e carregando periodicamente esses dados na nuvem. Em seguida, podemos usar esses dados para treinar novamente e refinar nosso modelo, que podemos reimplantar no IoT Edge.
Limpar os recursos
Este tutorial faz parte de um conjunto em que cada artigo se baseia no trabalho feito nas anteriores. Aguarde para limpar todos os recursos até concluir o tutorial final.
Próximas etapas
Este tutorial é dividido nas seguintes seções:
- Configure o computador de desenvolvimento e os serviços do Azure.
- Gere os dados de treinamento para o módulo de machine learning.
- Treine e implante o módulo de machine learning.
- Configure um dispositivo IoT Edge para atuar como um gateway transparente.
- Criar e implantar módulos do IoT Edge.
- Envie dados para seu dispositivo IoT Edge.
Continue para o próximo artigo para configurar um computador de desenvolvimento e provisionar recursos do Azure.