Embutimento de UDF escalar
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x) ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Este artigo apresenta o embutimento de UDF escalar, um recurso sob o conjunto de recursos de Processamento de Consulta Inteligente. Esse recurso aprimora o desempenho das consultas que invocam UDFs escalares no SQL Server (começando com o SQL Server 2019 (15.x)).
Funções escalares definidas pelo usuário T-SQL
Funções Definidas pelo Usuário implementadas no Transact-SQL e que retornam um valor de dados único são chamadas de Funções Definidas pelo Usuário Escalares T-SQL. UDFs T-SQL são uma maneira elegante de obter reutilização e modularidade de código em consultas Transact-SQL. Alguns cálculos (como regras de negócios complexas) são mais fáceis de expressar no formulário de UDF imperativa. UDFs ajudam na criação de uma lógica complexa sem exigir experiência em escrever consultas SQL complexas. Para saber mais sobre UDFs, confira Criar funções definidas pelo usuário (Mecanismo de Banco de Dados).
Desempenho de UDFs escalares
Normalmente, UDFs escalares acabam tendo um desempenho ruim devido aos seguintes motivos:
Invocação iterativa. UDFs são invocados de maneira iterativa, uma vez a cada tupla qualificada. Isso resulta em custos adicionais repetido de comutação de contexto repetida devido à invocação de função. Especialmente, UDFs que executam consultas Transact-SQL em sua definição são gravemente afetadas.
Falta de avaliação de custo. Durante a otimização, somente operadores relacionais terão o custo calculado, enquanto os operadores escalares não terão. Antes da introdução de UDFs escalares, outros operadores escalares geralmente eram baratos e não exigiam avaliação de custo. Um pequeno custo de CPU adicionado para uma operação de escalar foi suficiente. Há cenários em que o custo real é significativo e ainda assim permanece sub-representado.
Execução interpretada. UDFs são avaliados como um lote de instruções, executados instrução a instrução. Cada instrução em si é compilada e o plano compilado é armazenado em cache. Embora essa estratégia de armazenamento em cache economize algum tempo, pois evita recompilações, cada instrução é executada em isolamento. Nenhuma otimização entre instruções é executada.
Execução serial. O SQL Server não permite paralelismo dentro da consulta em consultas que invocam UDFs.
Embutimento automático de UDFs escalares
A meta do recurso de embutimento de UDF escalar é melhorar o desempenho de consultas que invocam UDFs escalares do T-SQL, em que a execução da UDF é o principal gargalo.
Com esse novo recurso, os UDFs escalares são automaticamente transformados em expressões escalares ou subconsultas escalares substituídas na consulta responsável pela chamada, em vez do operador UDF. Essas expressões e subconsultas então são otimizadas. Como resultado, o plano de consulta não terá mais um operador de função definido pelo usuário, mas seus efeitos serão observados no plano, como modos de exibição ou TVFs embutidos.
Exemplo 1: UDF estado de instrução única
Considere a consulta a seguir.
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (L_EXTENDEDPRICE *(1 - L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE;
Essa consulta calcula a soma dos preços com desconto para itens de linha e apresenta os resultados agrupados por data de envio e prioridade de envio. A expressão L_EXTENDEDPRICE *(1 - L_DISCOUNT) é a fórmula para o preço com desconto para um determinado item de linha. Essas fórmulas podem ser extraídas em funções para o benefício de modularidade e da reutilização.
CREATE FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2) AS
BEGIN
RETURN @price * (1 - @discount);
END
Agora, a consulta pode ser modificada para invocar essa UDF.
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (dbo.discount_price(L_EXTENDEDPRICE, L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
Devido a motivos descritos anteriormente, a consulta com a UDF tem um mau desempenho. Agora, com o embutimento de UDF escalar, a expressão escalar no corpo da UDF é substituída diretamente na consulta. Os resultados da execução dessa consulta são mostrados na tabela a seguir:
| Consulta: | Consulta sem UDF | Consultar com UDF (sem embutimento) | Consultar com embutimento de UDF escalar |
|---|---|---|---|
| Tempo de execução: | 1,6 segundo | 29 minutos e 11 segundos | 1,6 segundo |
Esses números são baseados em um banco de dados CCI de 10 GB (usando o esquema do TPC-H), em execução em um computador com processador duplo (12 núcleos), 96 GB de RAM, apoiado por SSD. Os números incluem a compilação e o tempo de execução com um pool de buffers e cache de procedimento frio. A configuração padrão foi usada e nenhum outro índice foi criado.
Exemplo 2: UDF escalar de várias instruções
UDFs escalares implementadas usando várias instruções T-SQL, como atribuições de variáveis e ramificação condicional, também podem ser embutidos. Considere a seguinte UDF escalar que, dada uma chave de cliente, determina a categoria de serviço para esse cliente. Ele chega na categoria computando primeiro o preço total de todos os pedidos feitos pelo cliente usando uma consulta SQL. Então, ela usa uma lógica IF (...) ELSE para decidir a categoria com base no preço total.
CREATE OR ALTER FUNCTION dbo.customer_category(@ckey INT)
RETURNS CHAR(10) AS
BEGIN
DECLARE @total_price DECIMAL(18,2);
DECLARE @category CHAR(10);
SELECT @total_price = SUM(O_TOTALPRICE) FROM ORDERS WHERE O_CUSTKEY = @ckey;
IF @total_price < 500000
SET @category = 'REGULAR';
ELSE IF @total_price < 1000000
SET @category = 'GOLD';
ELSE
SET @category = 'PLATINUM';
RETURN @category;
END
Agora, considere uma consulta que invoque essa UDF.
SELECT C_NAME, dbo.customer_category(C_CUSTKEY) FROM CUSTOMER;
O plano de execução para essa consulta no SQL Server 2017 (14.x) (nível de compatibilidade 140 e anterior) é o seguinte

Como mostra o plano, o SQL Server adota uma estratégia simples aqui: para cada tupla na tabela CUSTOMER, invoca a UDF e produz os resultados. Essa estratégia é ingênua e ineficiente. Com embutimento, essas UDFs são transformadas em subconsultas escalares equivalentes, que são substituídas na consulta responsável pela chamada no lugar da UDF.
Para a mesma consulta, o plano com a UDF embutida se parece com o abaixo.
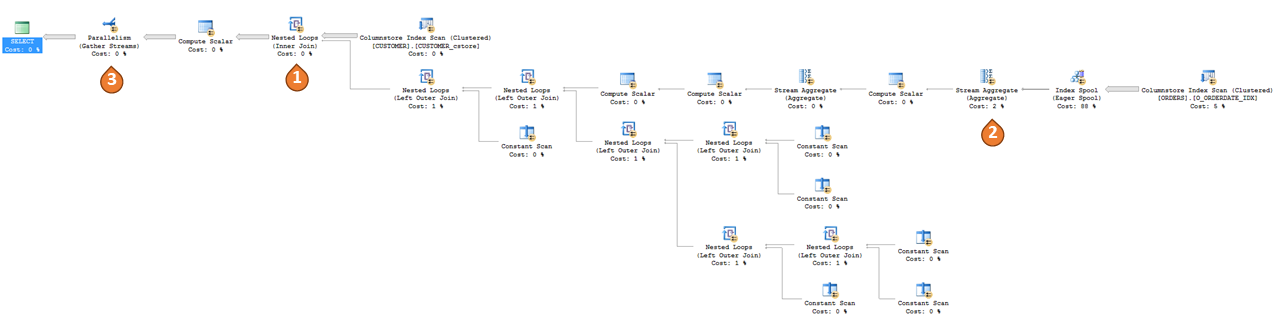
Como mencionado anteriormente, o plano de consulta não tem mais um operador de função definida pelo usuário, mas seus efeitos agora são observáveis no plano, como modos de exibição ou TVFs embutidos. Aqui estão algumas observações importantes do plano de acima:
- O SQL Server inferiu a junção implícita entre
CUSTOMEReORDERSe tornou isso explícito por meio de um operador de junção. - O SQL Server também inferiu o
GROUP BY O_CUSTKEY on ORDERSimplícito e usou IndexSpool + StreamAggregate implementá-lo. - O SQL Server agora está usando o paralelismo em todos os operadores.
Dependendo da complexidade da lógica na UDF, o plano de consulta resultante também poderá ficar maior e mais complexo. Como podemos ver, as operações dentro da UDF agora não são mais uma caixa opaca e, portanto, o otimizador de consulta é capaz de calcular o custo e otimizar essas operações. Além disso, uma vez que a UDF não está mais no plano, invocação da UDF iterativa é substituída por um plano que evita completamente a sobrecarga de chamada de função.
Requisitos de UDFs escalares que podem ser embutidas
Uma UDF T-SQL escalar poderá ser embutida se todas as seguintes condições forem verdadeiras:
- A UDF é escrita usando as seguintes construções:
DECLARE,SET: declaração de variável e atribuições.SELECT: consulta SQL com atribuições de variáveis simples/múltiplas 1.IF/ELSE: ramificação com níveis arbitrários de aninhamento.RETURN: instruções de retorno únicas ou múltiplas. A partir do SQL Server 2019 (15.x) CU5, a UDF só pode conter uma instrução RETURN para ser considerada para embutimento 6.UDF: Chamadas de funções aninhadas/recursivas 2.- Outros: operações relacionais, como
EXISTS,IS NULL.
- A UDF não invoca uma função intrínseca que seja dependente do tempo (como
GETDATE()) ou que tenha efeitos colaterais 3 (comoNEWSEQUENTIALID()). - A UDF usa a cláusula
EXECUTE AS CALLER(comportamento padrão se a cláusulaEXECUTE ASnão for especificada). - A UDF não faz referência a variáveis de tabela ou a parâmetros com valores de tabelas.
- A consulta que invoca um UDF escalar não faz referência a uma chamada de UDF escalar em sua cláusula
GROUP BY. - A consulta que invoca um UDF escalar em sua lista de seleção com a cláusula
DISTINCTnão tem a cláusulaORDER BY. - A UDF não é usada na cláusula
ORDER BY. - A UDF não é compilado nativamente (há suporte para interoperabilidade).
- A UDF não é usado em uma coluna computada ou em uma definição de restrição de verificação.
- A UDF não faz referência a tipos definidos pelo usuário.
- Não há assinaturas adicionadas à UDF.
- A UDF não é uma função de partição.
- A UDF não contém referências a CTEs (Expressões de Tabelas Comuns).
- A UDF não contém referências a funções intrínsecas que possam alterar os resultados quando incorporadas (como
@@ROWCOUNT) . 4. - A UDF não contém funções agregadas que estão sendo passadas como parâmetros para uma UDF escalar 4.
- A UDF não faz referência a exibições internas (como
OBJECT_ID) 4. - A UDF não faz referência a métodos XML 5.
- A UDF não contém SELECT com
ORDER BYsem uma cláusulaTOP 15. - A UDF não contém uma consulta SELECT que execute uma atribuição com a cláusula
ORDER BY(comoSELECT @x = @x + 1 FROM table1 ORDER BY col1) 5. - A UDF não contém várias instruções RETURN 6.
- A UDF não é chamada a partir de uma instrução RETURN 6.
- A UDF não faz referência à função
STRING_AGG6. - A UDF não faz referência a tabelas remotas 7.
- A consulta que chama a UDF não usa
GROUPING SETS,CUBEouROLLUP7. - A consulta de chamada de UDF não contém uma variável que seja usada como parâmetro de UDF para atribuição (por exemplo,
SELECT @y = 2,@x = UDF(@y)) 7. - A UDF não faz referência a colunas criptografadas 8.
- A UDF não contém referências a
WITH XMLNAMESPACES8. - A consulta que invoca a UDF não tem Expressões de Tabelas Comuns (CTEs) 8.
1SELECT com acumulação/agregação de variáveis não é compatível para embutimento (como SELECT @val += col1 FROM table1).
2 UDFs recursivos serão embutidos em uma profundidade determinada apenas.
3 Funções intrínsecas cujos resultados dependem da hora do sistema atual são dependente de hora. Uma função intrínseca que pode atualizar algum estado global interno é um exemplo de uma função com efeitos colaterais. Essas funções retornam resultados diferentes todas as vezes que são chamadas com base no estado interno.
4 Restrição adicionada no SQL Server 2019 (15.x) CU2
5 Restrição adicionada no SQL Server 2019 (15.x) CU4
6 Restrição adicionada no SQL Server 2019 (15.x) CU5
7 Restrição adicionada no SQL Server 2019 (15.x) CU6
8 Restrição adicionada no SQL Server 2019 (15.x) CU11
Para obter informações sobre as correções mais recentes no Embutimento de UDF escalar T-SQL e alterações nos cenários de elegibilidade para embutimento, consulte o artigo da Base de Dados de Conhecimento: CORREÇÃO: problemas com Embutimento de UDF escalar no SQL Server 2019.
Verificar se uma UDF pode ou não ser embutida
Para cada UDF escalar do T-SQL, a exibição de catálogo sys.sql_modules inclui uma propriedade chamada is_inlineable, que indica se uma UDF pode ser embutida ou não.
A propriedade is_inlineable é derivada dos constructos encontrados na definição da UDF. Ela não verifica se a UDF é de fato embutível em tempo de compilação. Para obter mais informações, confira as condições de inlining.
Um valor de 1 indica que ele é pode ser embutido e 0 indica o contrário. Essa propriedade terá um valor de 1 para todos as TVFs embutidos também. Para todos os outros módulos, o valor será 0.
Se uma UDF escalar for embutível, isso não significa que ele sempre será embutida. O SQL Server decidirá qual (por consulta, por UDF) se embutirá uma UDF ou não. Alguns exemplos de quando um UDF não pode ser embutido incluem:
Se a definição da UDF for executada em milhares de linhas de código, o SQL Server poderá optar por não a embutir.
Uma invocação de UDF em uma cláusula
GROUP BYnão será embutida. Essa decisão é tomada quando a consulta que referencia uma UDF escalar é compilada.Se a UDF for assinada com um certificado. Como assinaturas podem ser adicionadas e removidas após a criação de uma UDF, a decisão de embutir ou não é tomada quando a consulta que faz referência a uma UDF escalar é compilada. Por exemplo, as funções do sistema normalmente são assinadas com um certificado. Você pode usar sys. crypt_properties para localizar quais objetos são assinados.
SELECT * FROM sys.crypt_properties AS cp INNER JOIN sys.objects AS o ON cp.major_id = o.object_id;
Verificar se o embutimento ocorreu ou não
Se todas as pré-condições forem atendidas e o SQL Server decidir executar embutimento, ele transformará a UDF em uma expressão relacional. A partir do plano de consulta, é fácil descobrir se o embutimento ocorreu ou não:
- O xml do plano não terá um nó xml
<UserDefinedFunction>para uma UDF que tenha sido embutida com sucesso. - Determinados XEvents são emitidos.
Habilitar o embutimento de UDF escalar
Você pode qualificar automaticamente as cargas de trabalho para embutimento de UDF escalar habilitando o nível de compatibilidade 150 para o banco de dados. Você pode definir isso usando o Transact-SQL. Por exemplo:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Além disso, não há nenhuma outra alteração que precise ser feita para consultas ou UDFs para aproveitar esse recurso.
Desabilitar o Embutimento de UDF escalar sem alterar o nível de compatibilidade
O embutimento de UDF escalar pode ser desabilitado no escopo da UDF, da instrução ou do banco de dados enquanto ainda mantém o nível de compatibilidade do banco de dados 150 e superior. Para desabilitar o embutimento de UDF escalar no escopo do banco de dados, execute a seguinte instrução dentro do contexto do banco de dados aplicável:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Para habilitar novamente o embutimento de UDF escalar para o banco de dados, execute a seguinte instrução dentro do contexto do banco de dados aplicável:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON;
Quando LIGADA, essa configuração aparecerá como habilitada em sys.database_scoped_configurations.
Você também pode desabilitar o embutimento de UDF escalar de uma consulta específica designando DISABLE_TSQL_SCALAR_UDF_INLINING como uma dica de consulta USE HINT.
Uma dica de consulta USE HINT tem precedência sobre a configuração no escopo do banco de dados ou a configuração de nível de compatibilidade.
Por exemplo:
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (dbo.discount_price(L_EXTENDEDPRICE, L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
O embutimento de UDF escalar também pode ser desabilitado para uma UDF específica usando a cláusula INLINE na instrução CREATE FUNCTION ou ALTER FUNCTION.
Por exemplo:
CREATE OR ALTER FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2)
WITH INLINE = OFF
AS
BEGIN
RETURN @price * (1 - @discount);
END;
Depois que a declaração acima é executada, essa UDF nunca será embutida em nenhuma consulta que a invoque. Para habilitar novamente o embutimento para essa UDF, execute a seguinte instrução:
CREATE OR ALTER FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2)
WITH INLINE = ON
AS
BEGIN
RETURN @price * (1 - @discount);
END
A cláusula INLINE não é obrigatória. Se a cláusula INLINE não for especificada, ela será automaticamente definida como ON/OFF, com base no fato de a UDF poder ou não ser embutida. Se INLINE = ON for especificado, mas a UDF for considerada não qualificada para embutimento, um erro será gerado.
Observações importantes
Conforme descrito neste artigo, o embutimento de UDF escalar transforma uma consulta com UDFs escalares em uma consulta com uma subconsulta escalar equivalente. Devido a essa transformação, os usuários podem observar algumas diferenças no comportamento nos seguintes cenários:
O embutimento resultará em um hash de consulta diferente para o mesmo texto da consulta.
Determinados avisos em instruções dentro da UDF (como divisão por zero etc.) que podem ter sido ocultados anteriormente, pode aparecer devido ao embutimento.
Dicas de junção no nível da consulta talvez não sejam válidas, pois o embutimento pode introduzir novas junções. Dicas de junção local precisarão ser usadas em vez disso.
Exibições que fazem referência a UDFs escalares embutidas não podem ser indexadas. Se você precisar criar um índice nessas exibições, desabilite embutimento para UDFs referenciadas.
Pode haver algumas diferenças no comportamento de Máscara de Dados Dinâmicos com embutimento de UDF.
Em determinadas situações (dependendo da lógica da UDF), o embutimento pode ser mais conservador com relação ao mascaramento de colunas de saída. Nos cenários em que as colunas referenciadas em uma UDF não são colunas de saída, elas não serão mascaradas.
Se uma UDF referenciar funções internas, como
SCOPE_IDENTITY(),@@ROWCOUNTou@@ERROR, o valor retornado pela função interna será alterado com o inlining. Essa alteração no comportamento ocorre porque o embutimento altera o escopo das instruções dentro da UDF. A partir do SQL Server 2019 (15.x) CU2, o embutimento é bloqueado quando a UDF faz referência a determinadas funções intrínsecas (por exemplo,@@ROWCOUNT).Se uma variável for atribuída com o resultado de um UDF embutido e também usado como index_column_name na Dica de consulta FORCESEEK, resultará em uma Mensagem de erro 8622, indicando que o processador de consultas não pôde produzir um plano de consulta devido às dicas definidas na consulta.
Confira também
- Criar funções definidas pelo usuário (Mecanismo de Banco de Dados)
- Central de desempenho do Mecanismo de Banco de Dados do SQL Server e do Banco de Dados SQL do Azure
- Guia de arquitetura de processamento de consultas
- Referência de operadores físicos e lógicos de plano de execução
- Junções
- Demonstrar o processamento de consulta inteligente
- CORREÇÃO: problemas com Embutimento de UDF escalar no SQL Server 2019
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de