Modelo geral de documento Document Intelligence
Importante
Começando com as versões do Document Intelligence 2024-02-29-preview, 2023-10-31-preview e no futuro, o modelo de documento geral (prebuilt-document) foi preterido. Para extrair pares chave-valor, marcas de seleção, texto, tabelas e estrutura de documentos, use os seguintes modelos:
| Caraterística | versão | Model ID |
|---|---|---|
Layout modelo com o parâmetro features=keyValuePairs opcional de cadeia de caracteres de consulta habilitado. |
• v4:2024-02-29-pré-visualização • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| Modelo de documento geral | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-document |
Este conteúdo aplica-se a:![]() v3.1 (GA) | Última versão:
v3.1 (GA) | Última versão:![]() v4.0 (visualização) | Versão anterior:
v4.0 (visualização) | Versão anterior:![]() v3.0
v3.0
Este conteúdo aplica-se a:![]() v3.0 (GA) | Últimas versões:
v3.0 (GA) | Últimas versões:![]() v4.0 (visualização)
v4.0 (visualização)![]() v3.1
v3.1
O modelo de documento Geral combina poderosas capacidades de Reconhecimento Ótico de Carateres (OCR) com modelos de aprendizagem profunda para extrair pares chave-valor, tabelas e marcas de seleção de documentos. O documento geral está disponível com as APIs v3.1 e v3.0. Para obter mais informações, consulte nosso guia de migração.
Características gerais do documento
O modelo de documento geral é um modelo pré-treinado; não requer rótulos ou treinamento.
Uma única API extrai pares chave-valor, marcas de seleção, texto, tabelas e estrutura de documentos.
O modelo de documento geral suporta documentos estruturados, semiestruturados e não estruturados.
As marcas de seleção são identificadas como campos com um valor de
:selected:ou:unselected:.
Exemplo de documento processado no Document Intelligence Studio
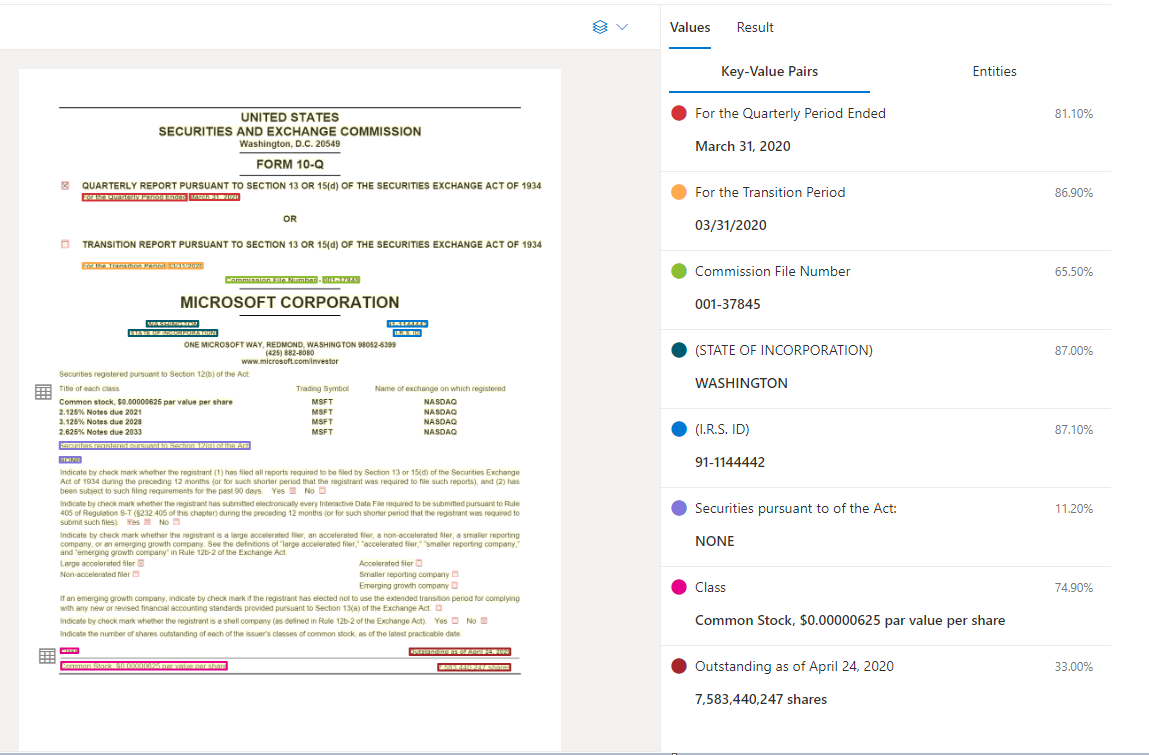
Extração do par chave-valor
A API de documento geral suporta a maioria dos tipos de formulário e analisa seus documentos e extrai chaves e valores associados. É ideal para extrair pares chave-valor comuns de documentos. Você pode usar o modelo de documento geral como uma alternativa para treinar um modelo personalizado sem rótulos.
Opções de desenvolvimento
O Document Intelligence v3.1 suporta as seguintes ferramentas, aplicativos e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de documento geral | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
documento pré-construído |
O Document Intelligence v3.0 suporta as seguintes ferramentas, aplicações e bibliotecas:
| Caraterística | Recursos | Model ID |
|---|---|---|
| Modelo de documento geral | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
documento pré-construído |
Requisitos de entrada
Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Formatos de ficheiro suportados:
Modelo PDF Imagem:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) e HTMLLida ✔ ✔ ✔ Esquema ✔ ✔ ✔ (2024-02-29-pré-visualização, 2023-10-31-pré-visualização) Documento Geral ✔ ✔ Pré-criado ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ (2024-02-29-pré-visualização) Para PDF e TIFF, até 2000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e 4 MB para a camada gratuita (F0).
As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 px x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a texto de cerca
8de -ponto a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para treinamento de modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e 1G-MB para o modelo neural.
Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GBde no máximo 10.000 páginas.
Extração de dados do modelo de documento geral
Tente extrair dados de formulários e documentos usando o Document Intelligence Studio.
Você precisa dos seguintes recursos:
Uma assinatura do Azure — você pode criar uma gratuitamente.
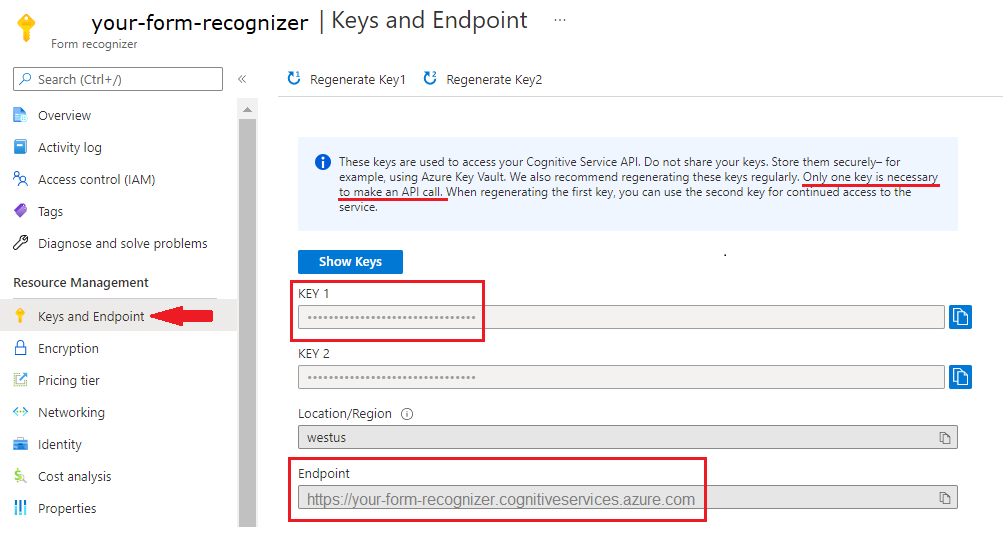
Uma instância de Document Intelligence no portal do Azure. Você pode usar o nível de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter sua chave e o ponto de extremidade.
Nota
O Document Intelligence Studio e o modelo de documento geral estão disponíveis com a API v3.0.
Na página inicial do Document Intelligence Studio, selecione Documentos gerais.
Pode analisar o documento de exemplo ou carregar os seus próprios ficheiros.
Selecione o botão Executar análise e, se necessário, configure as opções Analisar:

Pares chave-valor
Os pares chave-valor são extensões específicas dentro do documento que identificam um rótulo ou chave e sua resposta ou valor associado. Em um formulário estruturado, esses pares podem ser o rótulo e o valor que o usuário inseriu para esse campo. Em um documento não estruturado, eles podem ser a data em que um contrato foi executado com base no texto de um parágrafo. O modelo de IA é treinado para extrair chaves e valores identificáveis com base em uma ampla variedade de tipos de documentos, formatos e estruturas.
As chaves também podem existir isoladamente quando o modelo deteta a existência de uma chave, sem valor associado ou ao processar campos opcionais. Por exemplo, um campo de nome do meio pode ser deixado em branco em um formulário em alguns casos. Os pares chave-valor são extensões de texto contidas no documento. Para documentos em que o mesmo valor é descrito de maneiras diferentes, por exemplo, cliente/usuário, a chave associada é cliente ou usuário (com base no contexto).
Extração de dados
| Modelo | Extração de texto | Pares chave-valor | Marcas de seleção | Tabelas | Nomes comuns |
|---|---|---|---|---|---|
| Documento geral | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* - Disponível apenas nas 2023-07-31 versões API (v3.1 GA) e posteriores.
Idiomas e localidades suportados
Consulte a nossa página Suporte a idiomas — modelos de análise de documentos para obter uma lista completa dos idiomas suportados.
Considerações
Como as chaves são extensões de texto extraídas do documento, para documentos semiestruturados, as chaves precisam ser mapeadas para um dicionário de chaves existente.
Espere ver pares chave-valor com uma chave, mas nenhum valor. Por exemplo, se um usuário optar por não fornecer um endereço de e-mail no formulário.