Configurar um grupo de failover para o Banco de Dados SQL do Azure
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo ensina como configurar um grupo de failover para bancos de dados únicos e em pool no Banco de Dados SQL do Azure usando o portal do Azure, o Azure PowerShell e a CLI do Azure.
Para scripts de ponta a ponta, revise como adicionar um único banco de dados a um grupo de failover com o Azure PowerShell ou a CLI do Azure.
Pré-requisitos
Considere os seguintes pré-requisitos para criar seu grupo de failover para um único banco de dados:
- As configurações de login e firewall do servidor secundário devem corresponder às do servidor primário.
Criar o grupo de ativação pós-falha
Crie seu grupo de failover e adicione seu único banco de dados a ele usando o portal do Azure.
Selecione Azure SQL no menu esquerdo do portal do Azure. Se o Azure SQL não estiver na lista, selecione Todos os serviços e digite Azure SQL na caixa de pesquisa. (Opcional) Selecione a estrela ao lado do Azure SQL para favoritá-la e adicione-a como um item na navegação à esquerda.
Selecione o banco de dados que você deseja adicionar ao grupo de failover.
Selecione o nome do servidor em Nome do servidor para abrir as configurações do servidor.

Selecione Grupos de failover no painel Configurações e, em seguida, selecione Adicionar grupo para criar um novo grupo de failover.
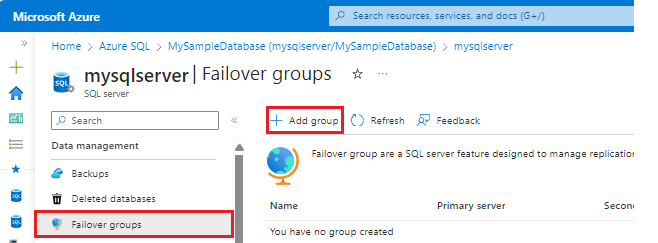
Na página Grupo de Failover, insira ou selecione os valores necessários e selecione Criar. Crie um novo servidor secundário ou selecione um servidor secundário existente. O servidor secundário no grupo de failover deve estar em uma região diferente do servidor primário.
- Bancos de dados dentro do grupo: escolha o banco de dados que você deseja adicionar ao seu grupo de failover. Adicionar o banco de dados ao grupo de failover iniciará automaticamente o processo de replicação geográfica.
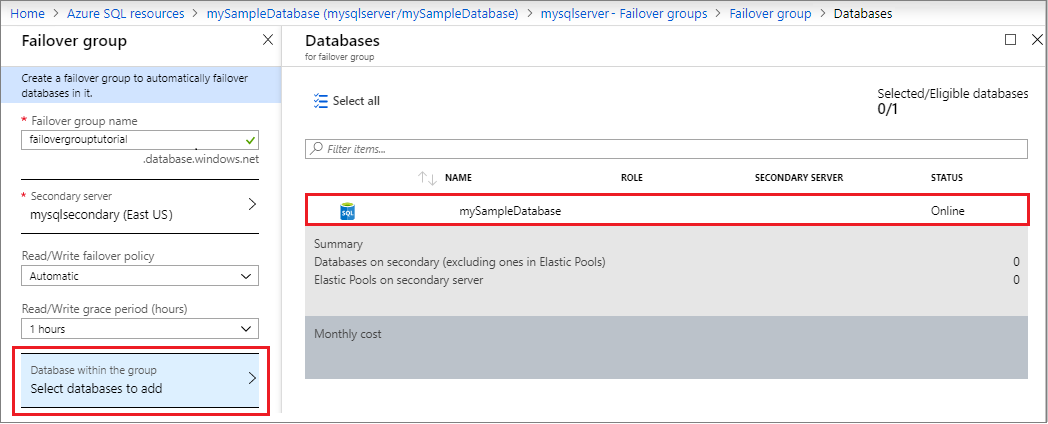
Testar failover planejado
Teste o failover do seu grupo de failover sem perda de dados usando o portal do Azure ou o PowerShell.
Teste o failover do seu grupo de failover usando o portal do Azure.
Selecione Azure SQL no menu esquerdo do portal do Azure. Se o Azure SQL não estiver na lista, selecione Todos os serviços e digite "Azure SQL" na caixa de pesquisa. (Opcional) Selecione a estrela ao lado do Azure SQL para favoritá-la e adicione-a como um item na navegação à esquerda.
Selecione o banco de dados que você deseja adicionar ao grupo de failover.
Selecione Grupos de failover no painel Configurações e escolha o grupo de failover que você acabou de criar.
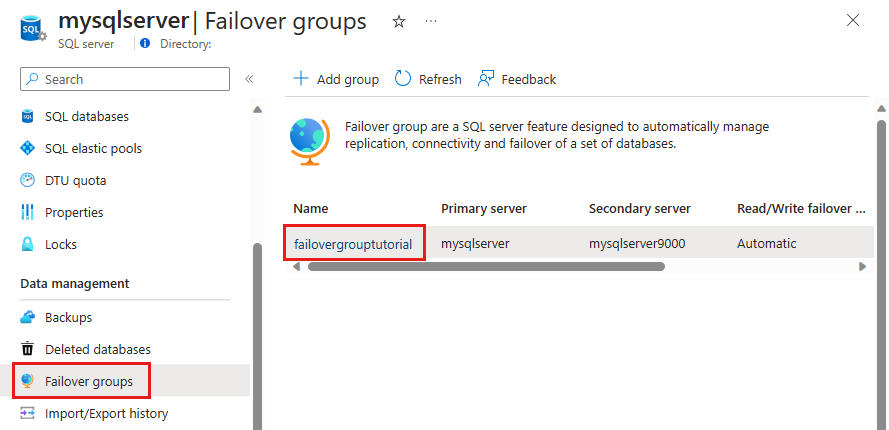
Analise qual servidor é primário e qual servidor é secundário.
Selecione Failover no painel de tarefas para fazer failover do grupo de failover que contém seu banco de dados.
Selecione Sim no aviso que o notifica de que as sessões TDS serão desconectadas.
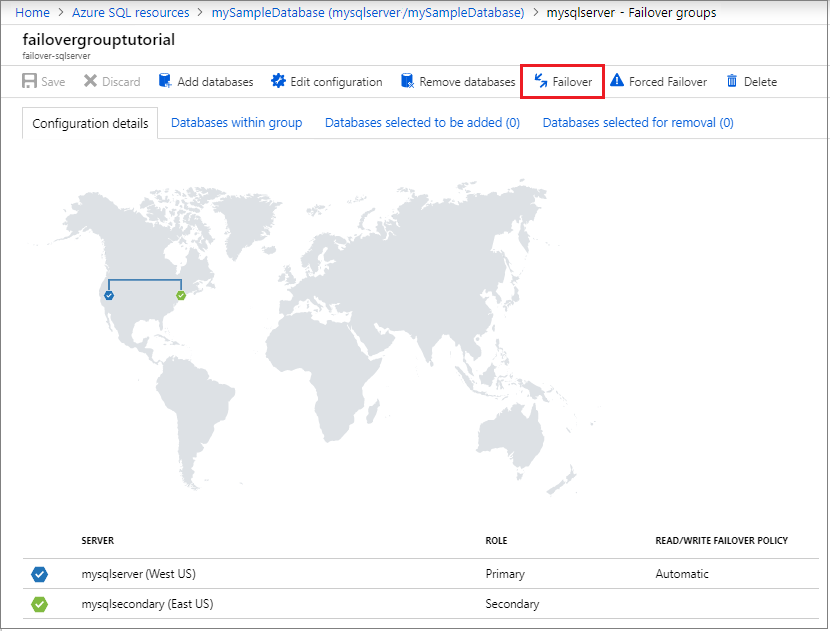
Analise qual servidor agora é primário e qual servidor é secundário. Se o failover for bem-sucedido, os dois servidores deverão ter trocado de funções.
Selecione Failover novamente para fazer com que os servidores voltem às suas funções originais.
Importante
Se você precisar excluir o banco de dados secundário, remova-o do grupo de failover antes de excluí-lo. A exclusão de um banco de dados secundário antes que ele seja removido do grupo de failover pode causar um comportamento imprevisível.
Para scripts de ponta a ponta, revise como adicionar um pool elástico a um grupo de failover com o Azure PowerShell ou a CLI do Azure.
Pré-requisitos
Considere os seguintes pré-requisitos para criar seu grupo de failover para um banco de dados em pool:
- As configurações de login e firewall do servidor secundário devem corresponder às do servidor primário.
Criar o grupo de ativação pós-falha
Crie o grupo de failover para seu pool elástico usando o portal do Azure ou o PowerShell.
Crie seu grupo de failover e adicione seu pool elástico a ele usando o portal do Azure.
Selecione Azure SQL no menu esquerdo do portal do Azure. Se o Azure SQL não estiver na lista, selecione Todos os serviços e digite "Azure SQL" na caixa de pesquisa. (Opcional) Selecione a estrela ao lado do Azure SQL para favoritá-la e adicione-a como um item na navegação à esquerda.
Selecione o pool elástico que você deseja adicionar ao grupo de failover.
No painel Visão geral, selecione o nome do servidor em Nome do servidor para abrir as configurações do servidor.
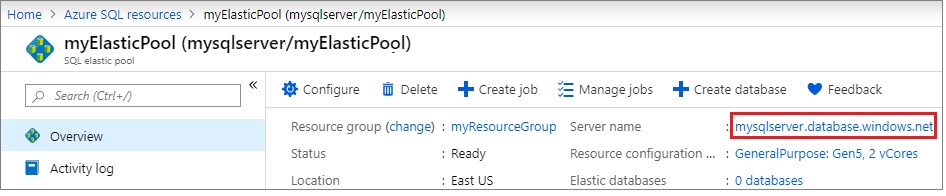
Selecione Grupos de failover no painel Configurações e, em seguida, selecione Adicionar grupo para criar um novo grupo de failover.
Na página Grupo de Failover, insira ou selecione os valores necessários e selecione Criar. Crie um novo servidor secundário ou selecione um servidor secundário existente.
Selecione Bancos de dados dentro do grupo e escolha o pool elástico que deseja adicionar ao grupo de failover. Se ainda não existir um pool elástico no servidor secundário, será exibido um aviso solicitando que você crie um pool elástico no servidor secundário. Selecione o aviso e, em seguida, selecione OK para criar o pool elástico no servidor secundário.
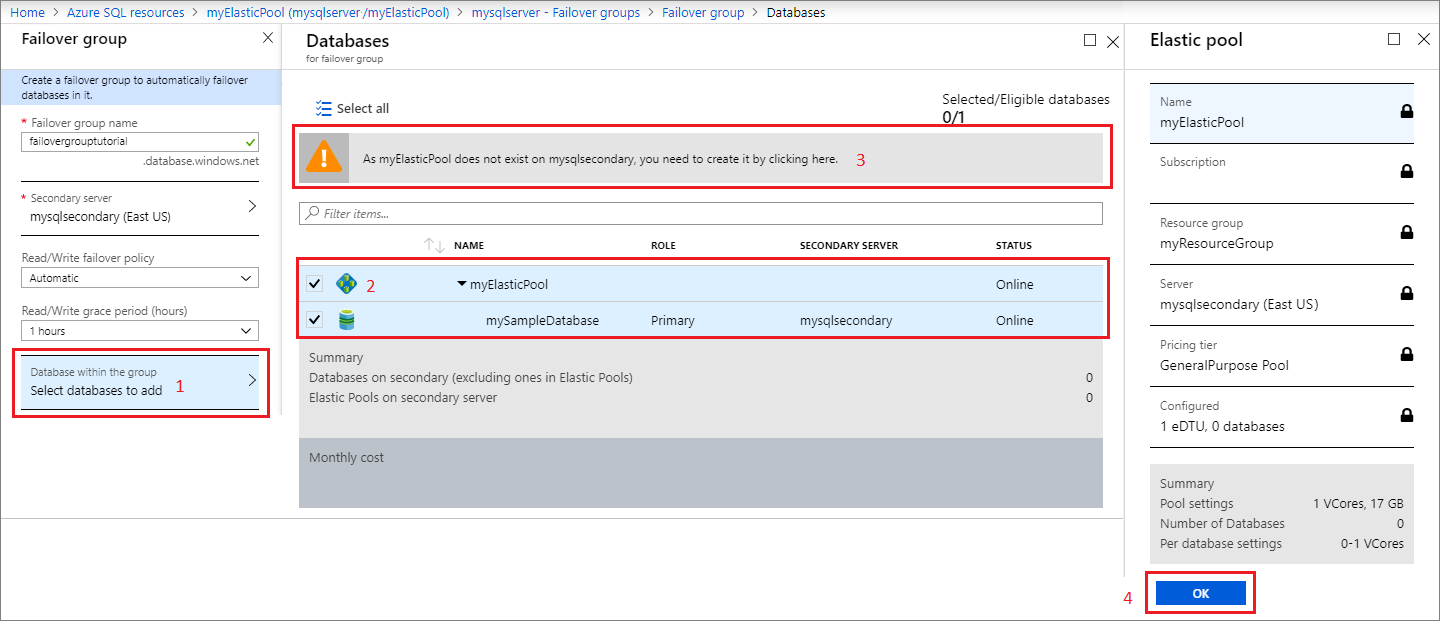
Use Selecionar para aplicar as configurações do pool elástico ao grupo de failover e, em seguida, selecione Criar para criar seu grupo de failover. Adicionar o pool elástico ao grupo de failover iniciará automaticamente o processo de replicação geográfica.
Testar failover planejado
Teste o failover sem perda de dados do seu pool elástico usando o portal do Azure ou o PowerShell.
Faça failover do grupo de failover para o servidor secundário e, em seguida, faça failover usando o portal do Azure.
Selecione Azure SQL no menu esquerdo do portal do Azure. Se o Azure SQL não estiver na lista, selecione Todos os serviços e digite "Azure SQL" na caixa de pesquisa. (Opcional) Selecione a estrela ao lado do Azure SQL para favoritá-la e adicione-a como um item na navegação à esquerda.
Selecione o pool elástico do qual deseja fazer failover.
No painel Visão geral, selecione o nome do servidor em Nome do servidor para abrir as configurações do servidor.
Selecione Grupos de failover em Configurações e escolha o grupo de failover criado anteriormente.
Analise qual servidor é primário e qual servidor é secundário.
Selecione Failover no painel de tarefas para fazer failover do grupo de failover que contém o pool elástico.
Selecione Sim no aviso que o notifica de que as sessões TDS serão desconectadas.
Analise qual servidor é primário, qual servidor é secundário. Se o failover for bem-sucedido, os dois servidores deverão ter trocado de funções.
Selecione Failover novamente para que o grupo de failover volte às configurações originais.
Importante
Se você precisar excluir o banco de dados secundário, remova-o do grupo de failover antes de excluí-lo. A exclusão de um banco de dados secundário antes que ele seja removido do grupo de failover pode causar um comportamento imprevisível.
Utilizar o Private Link
A utilização de uma ligação privada permite-lhe associar um servidor lógico a um endereço IP privado específico na rede virtual e na sub-rede.
Para usar um link privado com seu grupo de failover, faça o seguinte:
- Verifique se os servidores primário e secundário estão em uma região emparelhada.
- Crie a rede virtual e a sub-rede em cada região para hospedar pontos de extremidade privados para servidores primários e secundários, de modo que eles tenham espaços de endereço IP não sobrepostos. Por exemplo, o intervalo de endereços da rede virtual principal de 10.0.0.0/16 e o intervalo de endereços da rede virtual secundária de 10.0.0.1/16 sobrepõem-se. Para obter mais informações sobre os intervalos de endereços de rede virtual, veja o blogue Estruturar redes virtuais do Azure.
- Crie um ponto final privado e uma zona DNS Privado do Azure para o servidor principal.
- Crie um ponto final privado para o servidor secundário também, mas, desta vez, escolha reutilizar a mesma zona DNS Privado que foi criada para o servidor principal.
- Depois que o link privado for estabelecido, você poderá criar o grupo de failover seguindo as etapas descritas anteriormente neste artigo.
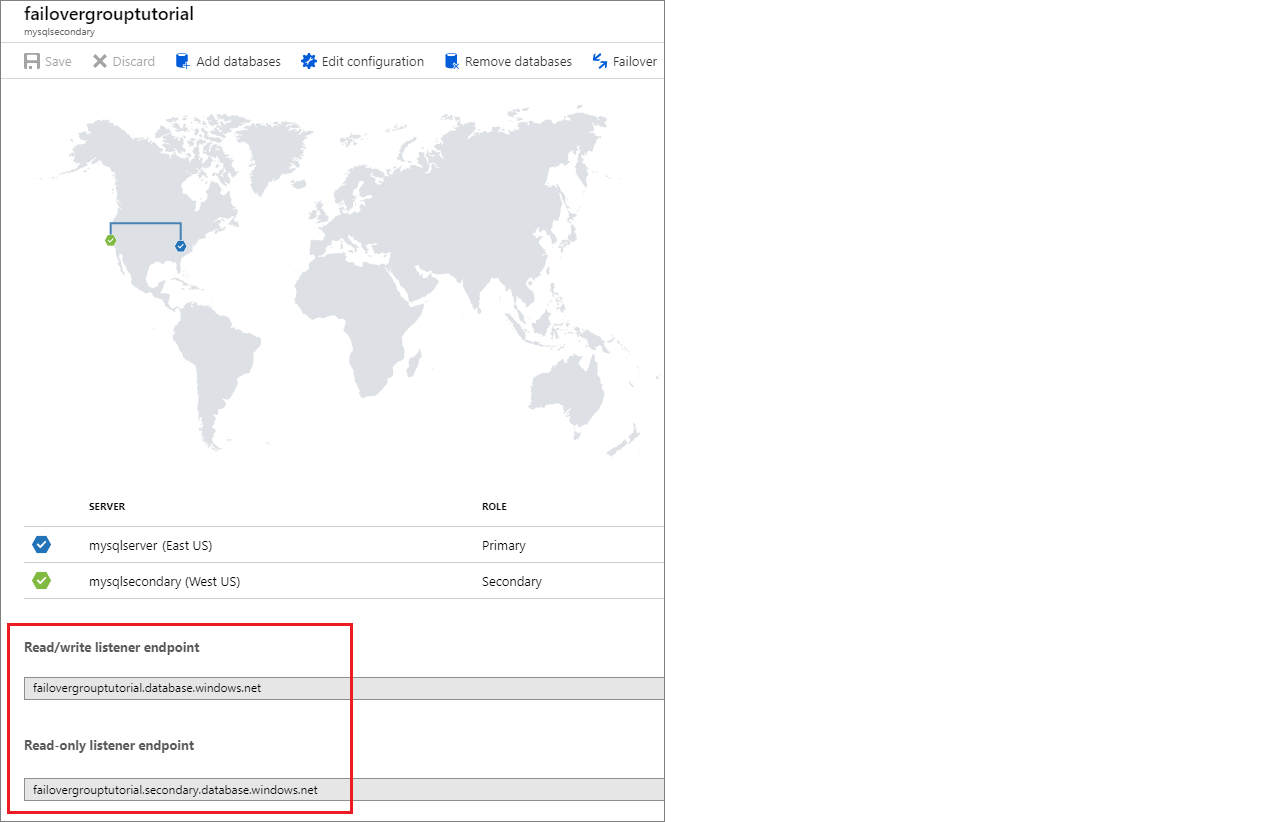
Localizar o ponto final do serviço de escuta
Depois que o grupo de failover estiver configurado, atualize a cadeia de conexão do seu aplicativo para o ponto de extremidade do ouvinte. Isso mantém seu aplicativo conectado ao ouvinte do grupo de failover, em vez do banco de dados primário ou do pool elástico. Dessa forma, você não precisa atualizar manualmente a cadeia de conexão sempre que a entidade do banco de dados fizer failover e o tráfego será roteado para qualquer entidade que seja principal no momento.
O ponto de extremidade do ouvinte está na forma de , e é visível no portal do Azure ao exibir o grupo de fog-name.database.windows.netfailover:
Dimensionamento de bancos de dados em um grupo de failover
Você pode dimensionar o banco de dados primário para cima ou para baixo para um tamanho de computação diferente (dentro da mesma camada de serviço) sem desconectar nenhum geosecundário. Ao aumentar verticalmente, recomendamos que comece por aumentar verticalmente a instância de georreplicação secundária e, em seguida, a principal. Ao reduzir verticalmente, inverta a ordem: comece por reduzir verticalmente a principal e, em seguida, a secundária. Quando você dimensiona um banco de dados para uma camada de serviço diferente, essa recomendação é imposta.
Esta sequência é recomendada especificamente para evitar o problema em que o geo-secundário em um SKU mais baixo fica sobrecarregado e deve ser repropagado durante um processo de upgrade ou downgrade. Também pode evitar o problema ao tornar a instância primária só de leitura, em detrimento de afetar todas as cargas de trabalho de leitura/gravação na instância primária.
Nota
Se tiver criado uma georreplicação secundária como parte da configuração do grupo de ativação pós-falha, não é recomendado reduzi-la verticalmente. Trata-se de garantir que a camada de dados tem capacidade suficiente para processar a carga de trabalho habitual após uma ativação pós-falha geográfica. Talvez não seja possível dimensionar um geo-secundário após um failover não planejado quando o geo-primário anterior não estiver disponível devido a uma interrupção. Esta é uma limitação conhecida.
Evitar a perda de dados críticos
Devido à alta latência das redes de longa distância, a replicação geográfica usa um mecanismo de replicação assíncrona. A replicação assíncrona torna inevitável a possibilidade de perda de dados se o primário falhar. Para proteger transações críticas contra perda de dados, um desenvolvedor de aplicativos pode chamar o procedimento armazenado sp_wait_for_database_copy_sync imediatamente após confirmar a transação. A chamada bloqueia o thread de chamada sp_wait_for_database_copy_sync até que a última transação confirmada tenha sido transmitida e reforçada no log de transações do banco de dados secundário. No entanto, não espera que as transações transmitidas sejam repetidas (refeitas) no secundário. sp_wait_for_database_copy_sync tem como escopo um link de replicação geográfica específico. Qualquer usuário com direitos de conexão com o banco de dados primário pode chamar este procedimento.
Nota
sp_wait_for_database_copy_sync Impede a perda de dados após failover geográfico para transações específicas, mas não garante a sincronização completa para acesso de leitura. O atraso causado por uma sp_wait_for_database_copy_sync chamada de procedimento pode ser significativo e depende do tamanho do log de transações ainda não transmitido no primário no momento da chamada.
Alterar a região secundária
Para ilustrar a sequência de alterações, assumiremos que o servidor A é o servidor primário, o servidor B é o servidor secundário existente e o servidor C é o novo secundário na terceira região. Para fazer a transição, siga estas etapas:
- Crie secundários adicionais de cada banco de dados no servidor A para o servidor C usando a replicação geográfica ativa. Cada banco de dados no servidor A terá dois secundários, um no servidor B e outro no servidor C. Isso garante que os bancos de dados primários permaneçam protegidos durante a transição.
- Elimine o grupo de ativação pós-falha. Neste ponto, as tentativas de entrada usando pontos de extremidade de grupo de failover começam a falhar.
- Recrie o grupo de failover com o mesmo nome entre os servidores A e C.
- Adicione todos os bancos de dados primários no servidor A ao novo grupo de failover. Neste ponto, as tentativas de login param de falhar.
- Exclua o servidor B. Todas as bases de dados em B serão eliminadas automaticamente.
Alterar a região primária
Para ilustrar a sequência de alterações, assumiremos que o servidor A é o servidor primário, o servidor B é o servidor secundário existente e o servidor C é o novo primário na terceira região. Para fazer a transição, siga estas etapas:
- Execute um failover geográfico planejado para alternar o servidor primário para B. O servidor A se torna o novo servidor secundário. O failover pode resultar em vários minutos de tempo de inatividade. O tempo real depende do tamanho do grupo de failover.
- Crie secundários adicionais de cada banco de dados no servidor B para o servidor C usando a replicação geográfica ativa. Cada banco de dados no servidor B terá dois secundários, um no servidor A e outro no servidor C. Isso garante que os bancos de dados primários permaneçam protegidos durante a transição.
- Elimine o grupo de ativação pós-falha. Neste ponto, as tentativas de entrada usando pontos de extremidade de grupo de failover começam a falhar.
- Recrie o grupo de failover com o mesmo nome entre os servidores B e C.
- Adicione todos os bancos de dados primários em B ao novo grupo de failover. Neste ponto, as tentativas de login param de falhar.
- Execute um failover geográfico planejado do grupo de failover para alternar B e C. Agora o servidor C torna-se o primário e B o secundário. Todos os bancos de dados secundários no servidor A serão automaticamente vinculados aos primários em C. Como na etapa 1, o failover pode resultar em vários minutos de tempo de inatividade.
- Exclua o servidor A. Todas as bases de dados em A serão eliminadas automaticamente.
Importante
Quando o grupo de failover é excluído, os registros DNS dos pontos de extremidade do ouvinte também são excluídos. Nesse ponto, há uma probabilidade diferente de zero de outra pessoa criar um grupo de failover ou um alias DNS do servidor com o mesmo nome. Como os nomes de grupo de failover e aliases DNS devem ser globalmente exclusivos, isso impedirá que você use o mesmo nome novamente. Para minimizar esse risco, não use nomes genéricos de grupo de failover.
Grupos de failover e segurança de rede
Para alguns aplicativos, as regras de segurança exigem que o acesso à rede para a camada de dados seja restrito a um componente ou componentes específicos, como uma VM, serviço Web, etc. Esse requisito apresenta alguns desafios para o design de continuidade de negócios e o uso de grupos de failover. Considere as seguintes opções ao implementar esse acesso restrito.
Usar grupos de failover e pontos de extremidade de serviço de rede virtual
Se você estiver usando pontos de extremidade e regras de serviço de Rede Virtual para restringir o acesso ao seu banco de dados, lembre-se de que cada ponto de extremidade do serviço de rede virtual se aplica a apenas uma região do Azure. O ponto de extremidade não permite que outras regiões aceitem comunicações da sub-rede. Portanto, somente os aplicativos cliente implantados na mesma região podem se conectar ao banco de dados primário. Como um failover geográfico resulta no redirecionamento das sessões de cliente do Banco de dados SQL para um servidor em uma região diferente (secundária), essas sessões podem falhar se forem originadas de um cliente fora dessa região. Por esse motivo, a política de failover gerenciada pela Microsoft não poderá ser habilitada se os servidores participantes estiverem incluídos nas regras da Rede Virtual. Para suportar a política de failover manual, siga estas etapas:
- Provisione cópias redundantes dos componentes frontend do seu aplicativo (serviço Web, máquinas virtuais, etc.) na região secundária.
- Configure regras de rede virtual individualmente para o servidor primário e secundário.
- Habilite o failover de frontend usando uma configuração do Gerenciador de tráfego.
- Inicie um failover geográfico manual quando a interrupção for detetada. Essa opção é otimizada para aplicativos que exigem latência consistente entre o frontend e a camada de dados e oferece suporte à recuperação quando o frontend, a camada de dados ou ambos são afetados pela interrupção.
Nota
Se você estiver usando o ouvinte somente leitura para balancear a carga de uma carga de trabalho somente leitura, verifique se essa carga de trabalho é executada em uma VM ou outro recurso na região secundária para que possa se conectar ao banco de dados secundário.
Usar grupos de failover e regras de firewall
Se seu plano de continuidade de negócios exigir failover usando grupos de failover, você poderá restringir o acesso ao Banco de dados SQL usando regras de firewall IP públicas. Essa configuração garante que um failover geográfico não bloqueie conexões de componentes front-end e pressupõe que o aplicativo possa tolerar a latência mais longa entre o frontend e a camada de dados.
Para dar suporte ao failover de grupo de failover, siga estas etapas:
- Crie um IP público.
- Crie um balanceador de carga público e atribua o IP público a ele.
- Crie uma rede virtual e as máquinas virtuais para seus componentes front-end.
- Crie um grupo de segurança de rede e configure conexões de entrada.
- Verifique se as conexões de saída estão abertas para o Banco de Dados SQL do Azure em uma região usando uma
Sql.<Region>marca de serviço. - Crie uma regra de firewall do Banco de dados SQL para permitir o tráfego de entrada do endereço IP público criado na etapa 1.
Para obter mais informações sobre como configurar o acesso de saída e qual IP usar nas regras de firewall, consulte Conexões de saída do balanceador de carga.
Importante
Para garantir a continuidade dos negócios durante interrupções regionais, você deve garantir redundância geográfica para componentes frontend e bancos de dados.
Permissões
As permissões para um grupo de failover são gerenciadas por meio do controle de acesso baseado em função do Azure (Azure RBAC).
O acesso de gravação do RBAC do Azure é necessário para criar e gerenciar grupos de failover. A função de Colaborador do SQL Server tem todas as permissões necessárias para gerenciar grupos de failover.
A tabela a seguir lista escopos de permissão específicos para o Banco de Dados SQL do Azure:
| Ação | Permissão | Scope |
|---|---|---|
| Criar o grupo de ativação pós-falha | Acesso de gravação do RBAC do Azure | Servidor primário Servidor secundário Todos os bancos de dados no grupo de failover |
| Atualizar grupo de failover | Acesso de gravação do RBAC do Azure | Grupo de failover Todos os bancos de dados no servidor primário atual |
| Grupo de failover de failover | Acesso de gravação do RBAC do Azure | Grupo de failover no novo servidor |
Limitações
Esteja ciente das seguintes limitações:
- Não é possível criar grupos de failover entre dois servidores na mesma região do Azure.
- Os grupos de failover oferecem suporte à replicação geográfica de todos os bancos de dados do grupo para apenas um servidor lógico secundário em uma região diferente.
- Não é possível mudar o nome dos grupos de ativação pós-falha. Terá de eliminar os grupos e voltar a criá-los com outro nome.
- Não há suporte para a renomeação de banco de dados em um grupo de failover. Você precisará excluir temporariamente o grupo de failover para poder renomear um banco de dados ou remover o banco de dados do grupo de failover.
- A remoção de um grupo de ativação pós-falha para uma base de dados de conjunto ou única não para a replicação e não elimina a base de dados replicada. Você precisará interromper manualmente a replicação geográfica e excluir o banco de dados do servidor secundário se quiser adicionar um banco de dados único ou em pool de volta a um grupo de failover depois que ele for removido. Não fazer qualquer um deles pode resultar em um erro semelhante ao ao tentar adicionar o banco de dados ao
The operation cannot be performed due to multiple errorsgrupo de failover. - O nome do grupo de failover está sujeito a restrições de nomenclatura.
Gerencie grupos de failover programaticamente
Os grupos de failover também podem ser gerenciados programaticamente usando o Azure PowerShell, a CLI do Azure e a API REST. As tabelas a seguir descrevem o conjunto de comandos disponíveis. Os grupos de failover incluem um conjunto de APIs do Azure Resource Manager para gerenciamento, incluindo a API REST do Banco de Dados SQL do Azure e cmdlets do Azure PowerShell. Essas APIs exigem o uso de grupos de recursos e dão suporte ao controle de acesso baseado em função do Azure (Azure RBAC). Para obter mais informações sobre como implementar funções de acesso, consulte Controle de acesso baseado em função do Azure (Azure RBAC).
| Cmdlet | Description |
|---|---|
| New-AzSqlDatabaseFailoverGroup | Este comando cria um grupo de failover e o registra em servidores primários e secundários |
| Remove-AzSqlDatabaseFailoverGroup | Remove um grupo de failover do servidor |
| Get-AzSqlDatabaseFailoverGroup | Recupera a configuração de um grupo de failover |
| Set-AzSqlDatabaseFailoverGroup | Modifica a configuração de um grupo de failover |
| Switch-AzSqlDatabaseFailoverGroup | Aciona o failover de um grupo de failover para o servidor secundário |
| Add-AzSqlDatabaseToFailoverGroup | Adiciona um ou mais bancos de dados a um grupo de failover |
Nota
É possível implantar seu grupo de failover em assinaturas usando o -PartnerSubscriptionId parâmetro no Azure Powershell começando com Az.SQL 3.11.0. Para saber mais, leia o exemplo a seguir.
Próximos passos
Para obter uma visão geral das opções de alta disponibilidade do Banco de Dados SQL do Azure, consulte replicação geográfica e grupos de failover.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários