Cópia em massa de ficheiros para base de dados
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve um modelo de solução que você pode usar para copiar dados em massa do Azure Data Lake Storage Gen2 para o Azure Synapse Analytics / Banco de Dados SQL do Azure.
Sobre este modelo de solução
Este modelo recupera arquivos da fonte do Azure Data Lake Storage Gen2. Em seguida, ele itera sobre cada arquivo na origem e copia o arquivo para o armazenamento de dados de destino.
Atualmente, este modelo suporta apenas a cópia de dados no formato DelimitedText . Os arquivos em outros formatos de dados também podem ser recuperados do armazenamento de dados de origem, mas não podem ser copiados para o armazenamento de dados de destino.
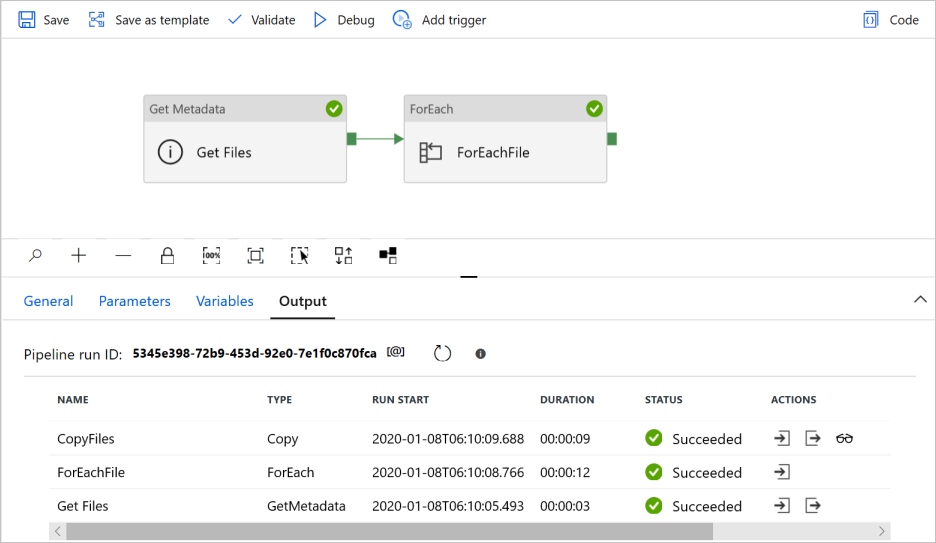
O modelo contém três atividades:
- A atividade Get Metadata recupera arquivos do Azure Data Lake Storage Gen2 e os passa para a atividade ForEach subsequente.
- A atividade ForEach obtém arquivos da atividade Obter metadados e itera cada arquivo para a atividade Copiar .
- A atividade de cópia reside na atividade ForEach para copiar cada arquivo do armazenamento de dados de origem para o armazenamento de dados de destino.
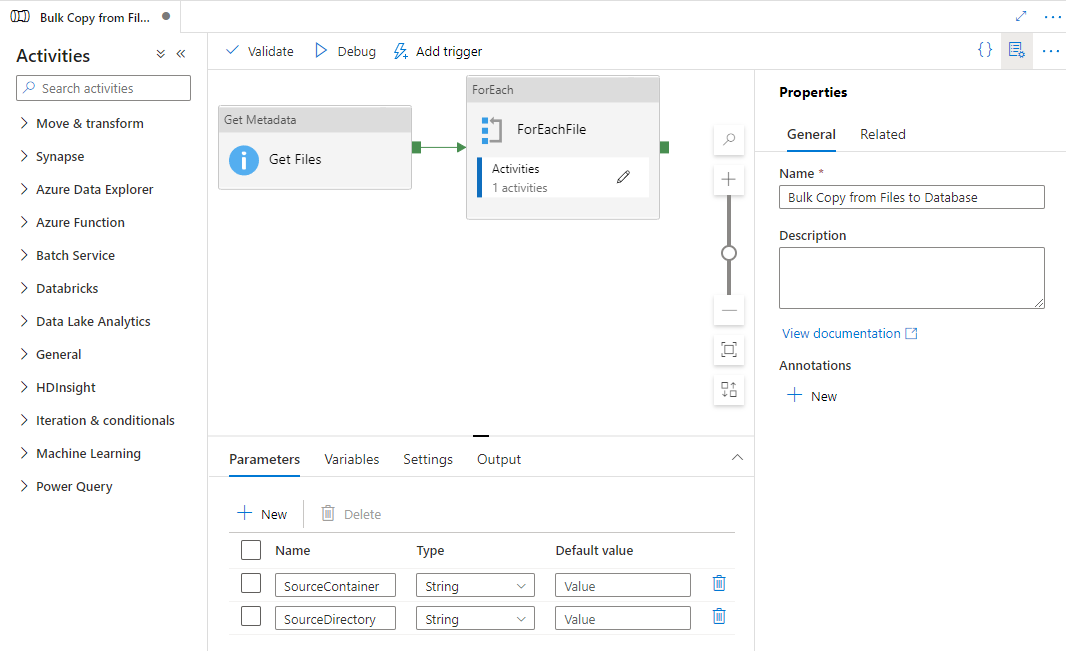
O modelo define os dois parâmetros a seguir:
- SourceContainer é o caminho do contêiner raiz do qual os dados são copiados no Azure Data Lake Storage Gen2.
- SourceDirectory é o caminho de diretório sob o contêiner raiz de onde os dados são copiados em seu Azure Data Lake Storage Gen2.
Como usar este modelo de solução
Abra o Azure Data Factory Studio e selecione a guia Autor com o ícone de lápis.
Passe o cursor sobre a seção Pipelines e selecione as reticências que aparecem no lado direito. Selecione Pipeline no modelo em seguida.
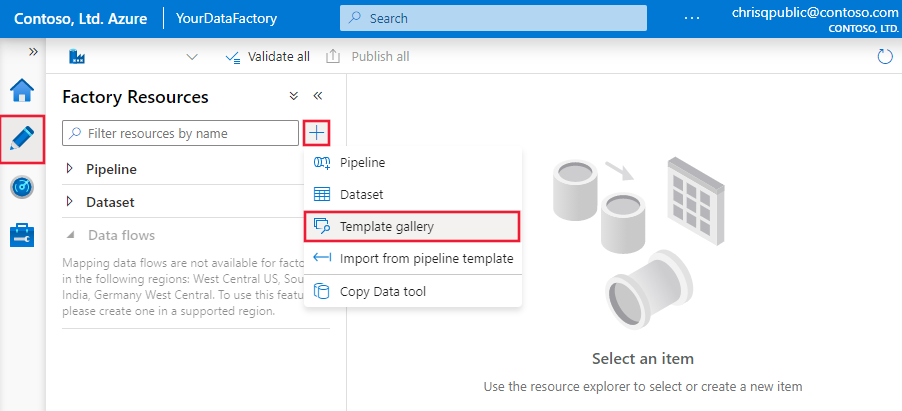
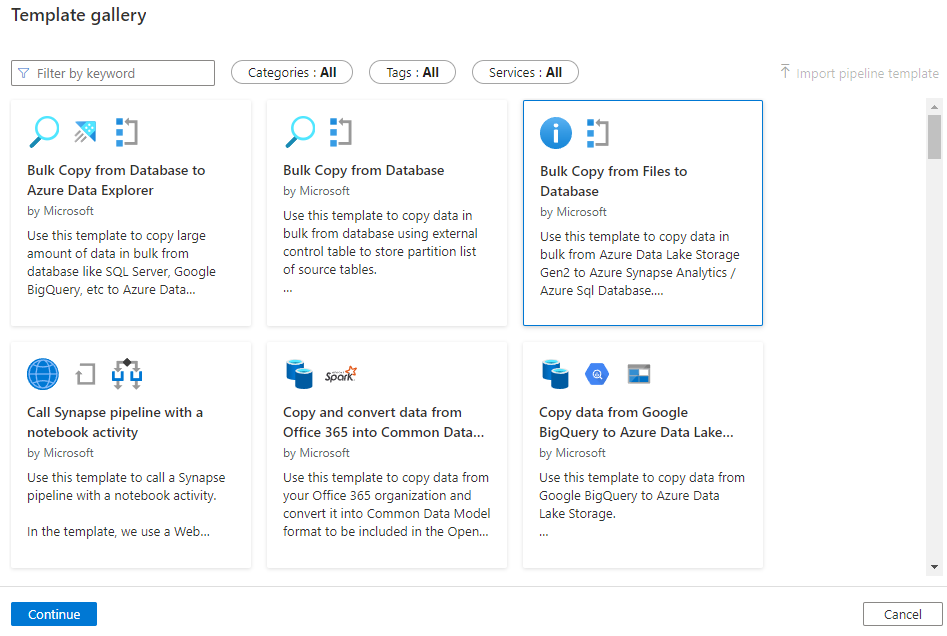
Selecione o modelo Cópia em massa de arquivos para banco de dados e, em seguida, selecione Continuar.
Crie uma nova conexão com o armazenamento Gen2 de origem como sua origem e uma com o banco de dados para seu coletor. Em seguida, selecione Usar este modelo.

Um novo pipeline é criado conforme mostrado no exemplo a seguir:
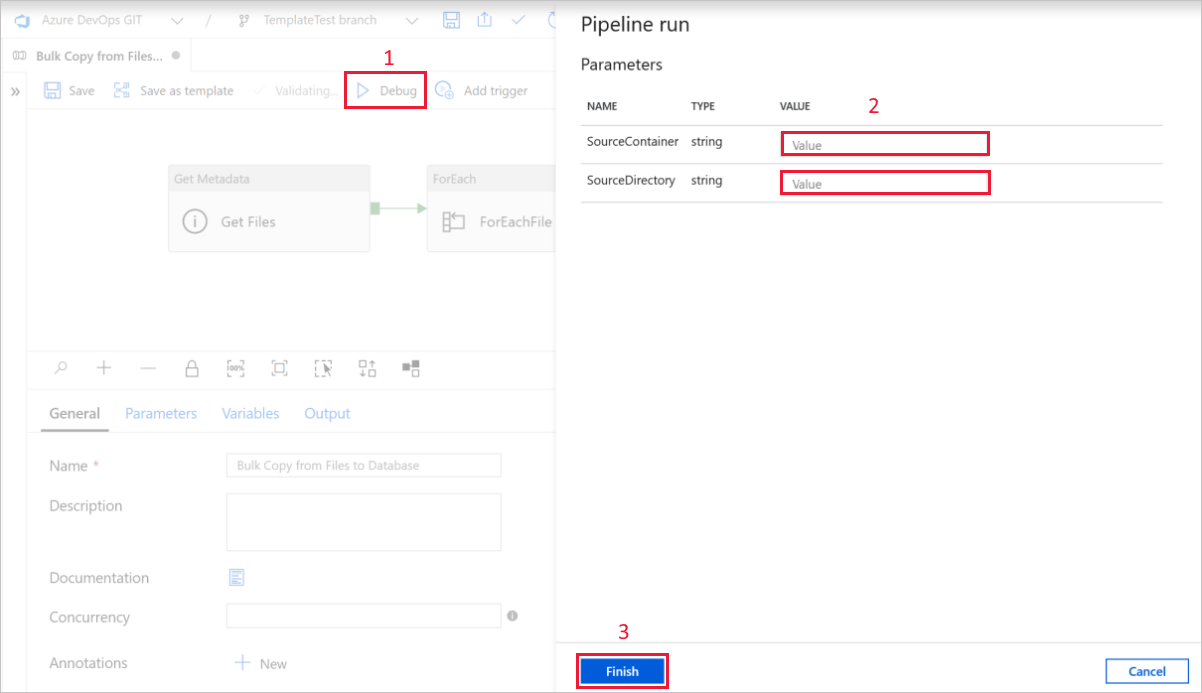
Selecione Depurar, insira os Parâmetros e selecione Concluir.
Quando a execução do pipeline for concluída com êxito, você verá resultados semelhantes ao exemplo a seguir: