Usar o Apache Spark Structured Streaming com o Apache Kafka e o Azure Cosmos DB
Saiba como usar o Apache SparkStructured Streaming para ler dados do Apache Kafka no Azure HDInsight e, em seguida, armazenar os dados no Azure Cosmos DB.
O Azure Cosmos DB é um banco de dados multimodelo distribuído globalmente. Este exemplo usa um modelo de banco de dados do Azure Cosmos DB para NoSQL. Para obter mais informações, consulte o documento Bem-vindo ao Azure Cosmos DB .
A transmissão em fluxo estruturada do Spark é um motor de processamento de fluxos incorporado no SQL do Spark. Permite-lhe expressar computações de transmissão em fluxo, tal como a computação em lotes o faz em dados estáticos. Para obter mais informações sobre Streaming Estruturado, consulte o Guia de Programação de Streaming Estruturado em Apache.org.
Importante
Este exemplo usa o Spark 2.4 no HDInsight 4.0.
Os passos neste documento criam um grupo de recursos do Azure que contém um cluster do Spark no HDInsight e um cluster do Kafka no HDInsight. Estes dois clusters estão localizados numa Rede Virtual do Azure, o que permite que o cluster do Spark comunique diretamente com o cluster do Kafka.
Quando tiver concluído os passos neste documento, elimine os clusters para evitar encargos em excesso.
Criar os clusters
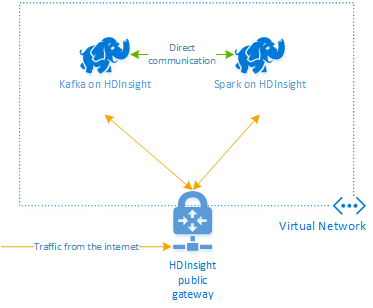
O Apache Kafka no HDInsight não fornece acesso aos corretores Kafka pela internet pública. Qualquer coisa que fale com Kafka deve estar na mesma rede virtual do Azure que os nós no cluster Kafka. Neste exemplo, os clusters Kafka e Spark estão localizados em uma rede virtual do Azure. O diagrama a seguir mostra como a comunicação flui entre os clusters:
Nota
O serviço Kafka está limitado à comunicação na rede virtual. Outros serviços em cluster, como SSH e Ambari, podem ser acedidos através da Internet. Para obter mais informações sobre as portas públicas disponíveis com o HDInsight, veja Portas e URIs utilizados pelo HDInsight.
Embora você possa criar uma rede virtual do Azure, Kafka e clusters Spark manualmente, é mais fácil usar um modelo do Azure Resource Manager. Use as etapas a seguir para implantar uma rede virtual do Azure, Kafka e clusters do Spark em sua assinatura do Azure.
Utilize o botão seguinte para iniciar sessão no Azure e abrir o modelo no Portal do Azure.

O modelo do Azure Resource Manager está localizado no repositório GitHub para este projeto (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb).
Este modelo cria os seguintes recursos:
Um Kafka no cluster HDInsight 4.0.
Um cluster Spark no HDInsight 4.0.
Uma Rede Virtual do Azure, que contém os clusters do HDInsight. A rede virtual criada pelo modelo usa o espaço de endereço 10.0.0.0/16.
Um banco de dados do Azure Cosmos DB para NoSQL.
Importante
O bloco de anotações de streaming estruturado usado neste exemplo requer o Spark no HDInsight 4.0. Se utilizar uma versão anterior do Spark no HDInsight, irá receber mensagens de erro ao utilizar o bloco de notas.
Use as seguintes informações para preencher as entradas na seção Implantação personalizada:
Property valor Subscrição Selecione a subscrição do Azure. Grupo de recursos Crie um grupo ou selecione um existente. Este grupo contém o cluster HDInsight. Nome da conta do Azure Cosmos DB Esse valor é usado como o nome para a conta do Azure Cosmos DB. O nome só pode conter letras minúsculas, números e o caráter de hífen (-). Tem de ter entre 3 e 31 carateres. Nome do cluster de base Esse valor é usado como o nome base para os clusters Spark e Kafka. Por exemplo, inserir myhdi cria um cluster Spark chamado spark-myhdi e um cluster Kafka chamado kafka-myhdi. Versão do cluster A versão do cluster HDInsight. Este exemplo é testado com o HDInsight 4.0 e pode não funcionar com outros tipos de cluster. Nome de Utilizador de Início de Sessão do Cluster O nome de usuário admin para os clusters Spark e Kafka. Palavra-passe de Início de Sessão do Cluster A senha de usuário administrador para os clusters Spark e Kafka. Nome de utilizador SSH O usuário SSH para criar para os clusters Spark e Kafka. Palavra-passe SSH A senha para o usuário SSH para os clusters Spark e Kafka. 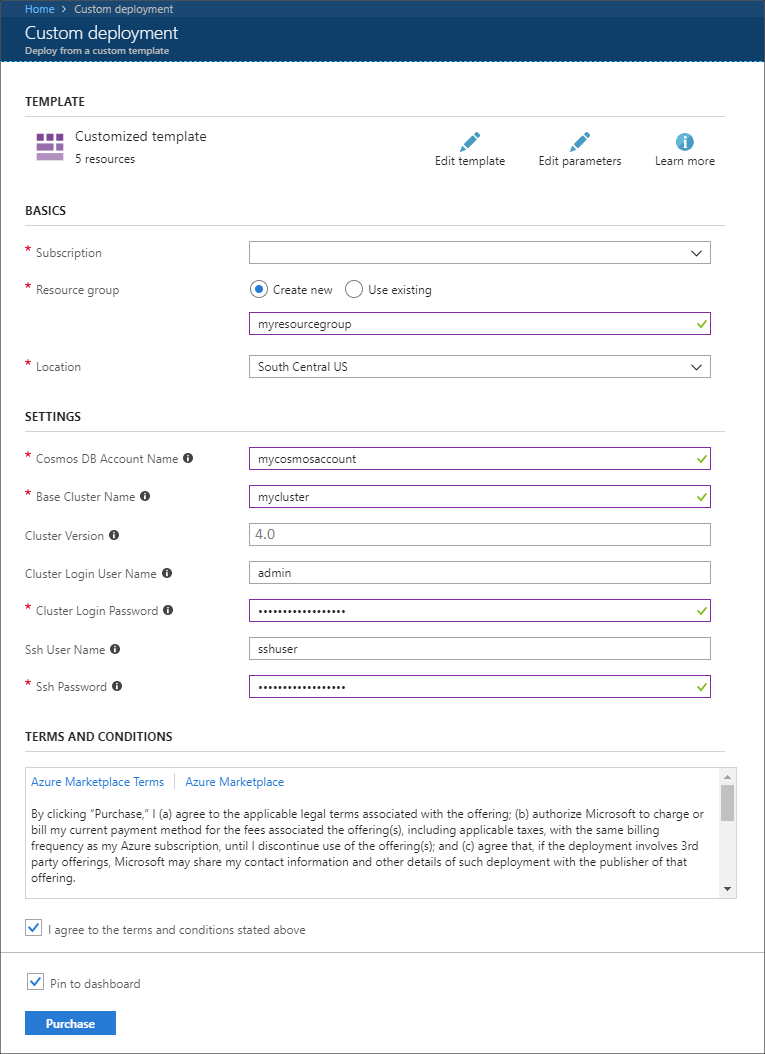
Leia os Termos e Condições e selecione Aceito os temos e as condições apresentados acima.
Por fim, selecione Comprar. Pode levar até 45 minutos para criar os clusters, a rede virtual e a conta do Azure Cosmos DB.
Criar o banco de dados e a coleção do Azure Cosmos DB
O projeto usado neste documento armazena dados no Azure Cosmos DB. Antes de executar o código, você deve primeiro criar um banco de dados e uma coleção em sua instância do Azure Cosmos DB. Você também deve recuperar o ponto de extremidade do documento e a chave usada para autenticar solicitações no Azure Cosmos DB.
Uma maneira de fazer isso é usar a CLI do Azure. O script a seguir criará um banco de dados chamado kafkadata e uma coleção chamada kafkacollection. Em seguida, ele retorna a chave primária.
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
As informações do ponto final do documento e da chave primária são semelhantes ao seguinte texto:
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
Importante
Salve o ponto de extremidade e os valores de chave, conforme eles são necessários nos Blocos de Anotações Jupyter.
Obter os blocos de notas
O código de exemplo descrito neste documento está disponível em https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb.
Carregar os blocos de notas
Use as seguintes etapas para carregar os blocos de anotações do projeto para o cluster do Spark no HDInsight:
No navegador da Web, conecte-se ao Jupyter Notebook no cluster do Spark. No seguinte URL, substitua
CLUSTERNAMEpelo nome do seu cluster do Spark:https://CLUSTERNAME.azurehdinsight.net/jupyterQuando lhe for pedido, introduza o início de sessão do cluster (admin) e a palavra-passe utilizada quando criou o cluster.
No canto superior direito da página, use o botão Carregar para carregar o arquivo Stream-taxi-data-to-kafka.ipynb no cluster. Selecione Abrir para iniciar o carregamento.
Encontre a entrada Stream-taxi-data-to-kafka.ipynb na lista de blocos de anotações e selecione o botão Carregar ao lado dela.
Repita as etapas 1 a 3 para carregar o notebook Stream-data-from-Kafka-to-Cosmos-DB.ipynb .
Carregue dados de táxi em Kafka
Depois que os arquivos forem carregados, selecione a entrada Stream-taxi-data-to-kafka.ipynb para abrir o bloco de anotações. Siga os passos no bloco de notas para carregar dados no Kafka.
Processar dados de táxi usando o Spark Structured Streaming
Na página inicial do Jupyter Notebook , selecione a entrada Stream-data-from-Kafka-to-Cosmos-DB.ipynb . Siga as etapas no bloco de anotações para transmitir dados do Kafka para o Azure Cosmos DB usando o Spark Structured Streaming.
Próximos passos
Agora que você aprendeu a usar o Apache Spark Structured Streaming, consulte os seguintes documentos para saber mais sobre como trabalhar com o Apache Spark, Apache Kafka e Azure Cosmos DB: