Visão geral dos métodos de previsão no AutoML
Este artigo se concentra nos métodos que o AutoML usa para preparar dados de séries temporais e criar modelos de previsão. Instruções e exemplos para treinar modelos de previsão no AutoML podem ser encontrados em nosso artigo de configuração do AutoML para previsão de séries temporais .
O AutoML usa vários métodos para prever valores de séries temporais. Esses métodos podem ser atribuídos aproximadamente a duas categorias:
- Modelos de séries temporais que usam valores históricos da quantidade alvo para fazer previsões para o futuro.
- Modelos de regressão, ou explicativos, que usam variáveis preditoras para prever valores do alvo.
Como exemplo, considere o problema de prever a demanda diária por uma determinada marca de suco de laranja de uma mercearia. Deixe $y_t$ representar a demanda por esta marca no dia $t$. Um modelo de série temporal prevê a demanda em $t+1$ usando alguma função da demanda histórica,
$y_{t+1} = f(y_t, y_{t-1}, \ldots, y_{t-s})$.
A função $f$ muitas vezes tem parâmetros que ajustamos usando a demanda observada do passado. A quantidade de histórico que $f$ usa para fazer previsões, $s$, também pode ser considerada um parâmetro do modelo.
O modelo de série temporal no exemplo de demanda de suco de laranja pode não ser preciso o suficiente, pois usa apenas informações sobre a demanda passada. Existem muitos outros fatores que provavelmente influenciam a demanda futura, como preço, dia da semana e se é feriado ou não. Considere um modelo de regressão que use essas variáveis preditoras,
$y = g(\text{price}, \text{dia da semana}, \text{holiday})$.
Novamente, $g$ geralmente tem um conjunto de parâmetros, incluindo aqueles que regem a regularização, que o AutoML ajusta usando valores passados da demanda e os preditores. Omitimos $t$ da expressão para enfatizar que o modelo de regressão usa padrões correlacionais entre variáveis definidas contemporaneamente para fazer previsões. Ou seja, para prever $y_{t+1}$ a partir de $g$, devemos saber em que dia da semana $t+1$ cai, se é feriado, e o preço do suco de laranja no dia $t+1$. As duas primeiras informações são sempre facilmente encontradas consultando um calendário. Um preço de varejo geralmente é definido com antecedência, então o preço do suco de laranja provavelmente também é conhecido um dia à frente. No entanto, o preço pode não ser conhecido 10 dias no futuro! É importante entender que a utilidade dessa regressão é limitada por quão longe no futuro precisamos de previsões, também chamado de horizonte de previsão, e até que ponto conhecemos os valores futuros dos preditores.
Importante
Os modelos de regressão de previsão do AutoML assumem que todos os recursos fornecidos pelo usuário são conhecidos no futuro, pelo menos até o horizonte de previsão.
Os modelos de regressão de previsão do AutoML também podem ser aumentados para usar valores históricos do alvo e dos preditores. O resultado é um modelo híbrido com características de um modelo de série temporal e um modelo de regressão pura. As grandezas históricas são variáveis preditoras adicionais na regressão e referimo-nos a elas como grandezas defasadas. A ordem do atraso refere-se à distância em que o valor é conhecido. Por exemplo, o valor atual de um atraso de ordem dois do alvo para o nosso exemplo de demanda de suco de laranja é a demanda de suco observada de dois dias atrás.
Outra diferença notável entre os modelos de séries temporais e os modelos de regressão está na forma como geram previsões. Os modelos de séries temporais são geralmente definidos por relações de recursão e produzem previsões uma de cada vez. Para prever muitos períodos no futuro, eles iteram até o horizonte de previsão, alimentando previsões anteriores de volta ao modelo para gerar a próxima previsão de um período à frente, conforme necessário. Em contraste, os modelos de regressão são os chamados meteorologistas diretos que geram todas as previsões até o horizonte de uma só vez. Os meteorologistas diretos podem ser preferíveis aos recursivos porque os modelos recursivos compõem o erro de previsão quando alimentam previsões anteriores de volta ao modelo. Quando os recursos de atraso são incluídos, o AutoML faz algumas modificações importantes nos dados de treinamento para que os modelos de regressão possam funcionar como previsões diretas. Consulte o artigo de recursos de atraso para obter mais detalhes.
Modelos de previsão no AutoML
A tabela a seguir lista os modelos de previsão implementados no AutoML e a qual categoria eles pertencem:
| Modelos de Séries Temporais | Modelos de regressão |
|---|---|
| Ingênuo, Sazonal Ingênuo, Média, Média Sazonal, ARIMA(X), Alisamento Exponencial | SGD Linear, LARS LASSO, Rede Elástica, Profeta, K Vizinhos Mais Próximos, Árvore de Decisão, Floresta Aleatória, Árvores Extremamente Aleatórias, Árvores Impulsionadas por Gradiente, LightGBM, XGBoost, TCNForecaster |
Os modelos em cada categoria são listados aproximadamente em ordem da complexidade dos padrões que são capazes de incorporar, também conhecidos como capacidade do modelo. Um modelo ingênuo, que simplesmente prevê o último valor observado, tem baixa capacidade, enquanto a Rede Convolucional Temporal (TCNForecaster), uma rede neural profunda com potencialmente milhões de parâmetros ajustáveis, tem alta capacidade.
É importante ressaltar que o AutoML também inclui modelos de conjunto que criam combinações ponderadas dos modelos com melhor desempenho para melhorar ainda mais a precisão. Para a previsão, usamos um conjunto de votação suave onde a composição e os pesos são encontrados através do Caruana Ensemble Selection Algorithm.
Nota
Há duas ressalvas importantes para conjuntos de modelos de previsão:
- Atualmente, o TCN não pode ser incluído em conjuntos.
- Por padrão, o AutoML desabilita outro método de conjunto, o conjunto de pilha, que está incluído nas tarefas de regressão e classificação padrão no AutoML. O conjunto de pilha se encaixa em um metamodelo nas melhores previsões de modelo para encontrar pesos de conjunto. Descobrimos no benchmarking interno que essa estratégia tem uma tendência maior a se sobreajustar aos dados de séries temporais. Isso pode resultar em má generalização, de modo que o conjunto de pilha é desativado por padrão. No entanto, ele pode ser habilitado se desejado na configuração AutoML.
Como o AutoML usa seus dados
O AutoML aceita dados de séries cronológicas em formato tabular, "wide"; ou seja, cada variável deve ter sua própria coluna correspondente. O AutoML requer que uma das colunas seja o eixo de tempo para o problema de previsão. Esta coluna deve ser analisada em um tipo datetime. O conjunto de dados de série temporal mais simples consiste em uma coluna de tempo e uma coluna de destino numérica. O alvo é a variável que se pretende prever para o futuro. Segue-se um exemplo do formato neste caso simples:
| carimbo de data/hora | quantidade |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-02 | 97 |
| 2012-01-03 | 106 |
| ... | ... |
| 2013-12-31 | 347 |
Em casos mais complexos, os dados podem conter outras colunas alinhadas com o índice de tempo.
| carimbo de data/hora | SKU | preço | anunciados | quantidade |
|---|---|---|---|---|
| 2012-01-01 | SUCO1 | 3.5 | 0 | 100 |
| 2012-01-01 | PÃO3 | 5.76 | 0 | 47 |
| 2012-01-02 | SUCO1 | 3.5 | 0 | 97 |
| 2012-01-02 | PÃO3 | 5,5 | 1 | 68 |
| ... | ... | ... | ... | ... |
| 2013-12-31 | SUCO1 | 3.75 | 0 | 347 |
| 2013-12-31 | PÃO3 | 5.7 | 0 | 94 |
Neste exemplo, há uma SKU, um preço de varejo e um sinalizador indicando se um item foi anunciado, além do carimbo de data/hora e da quantidade de destino. Há evidentemente duas séries neste conjunto de dados - uma para o JUICE1 SKU e outra para o BREAD3 SKU; a SKU coluna é uma coluna ID de série temporal, uma vez que o agrupamento por ela dá dois grupos contendo uma única série cada. Antes de varrer os modelos, o AutoML faz a validação básica da configuração de entrada e dos dados e adiciona recursos de engenharia.
Requisitos em matéria de comprimento dos dados
Para treinar um modelo de previsão, você deve ter uma quantidade suficiente de dados históricos. Essa quantidade limite varia de acordo com a configuração do treinamento. Se você forneceu dados de validação, o número mínimo de observações de treinamento necessárias por série temporal é dado por,
$T_{\text{validação do usuário}} = H + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
onde $H$ é o horizonte de previsão, $l_{\text{max}}$ é a ordem de atraso máxima e $s_{\text{window}}$ é o tamanho da janela para recursos de agregação contínua. Se você estiver usando a validação cruzada, o número mínimo de observações é:
$T_{\text{CV}} = 2H + (n_{\text{CV}} - 1) n_{\text{step}} + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
onde $n_{\text{CV}}$ é o número de dobras de validação cruzada e $n_{\text{step}}$ é o tamanho da etapa CV, ou deslocamento entre dobras CV. A lógica básica por trás dessas fórmulas é que você sempre deve ter pelo menos um horizonte de observações de treinamento para cada série temporal, incluindo algum preenchimento para lags e divisões de validação cruzada. Consulte a seleção do modelo de previsão para obter mais detalhes sobre a validação cruzada para previsão.
Tratamento de dados em falta
Os modelos de séries temporais do AutoML requerem observações regularmente espaçadas no tempo. Regularmente espaçado, aqui, inclui casos como observações mensais ou anuais em que o número de dias entre observações pode variar. Antes da modelagem, o AutoML deve garantir que não há valores de série ausentes e que as observações são regulares. Por conseguinte, faltam dois casos de dados:
- Um valor está faltando para algumas células nos dados tabulares
- Falta uma linha que corresponde a uma observação esperada dada a frequência das séries cronológicas
No primeiro caso, o AutoML imputa valores ausentes usando técnicas comuns e configuráveis.
Um exemplo de uma linha esperada ausente é mostrado na tabela a seguir:
| carimbo de data/hora | quantidade |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-03 | 106 |
| 2012-01-04 | 103 |
| ... | ... |
| 2013-12-31 | 347 |
Esta série aparentemente tem uma frequência diária, mas não há observação para 2 de janeiro de 2012. Nesse caso, o AutoML tentará preencher os dados adicionando uma nova linha para 2 de janeiro de 2012. O novo valor para a quantity coluna e quaisquer outras colunas nos dados serão então imputados como outros valores ausentes. Claramente, o AutoML deve conhecer a frequência da série para preencher lacunas de observação como esta. O AutoML deteta automaticamente essa frequência ou, opcionalmente, o usuário pode fornecê-la na configuração.
O método de imputação para preencher os valores em falta pode ser configurado na entrada. Os métodos padrão estão listados na tabela a seguir:
| Tipo de coluna | Método de imputação por defeito |
|---|---|
| Destino | Forward fill (última observação realizada) |
| Característica numérica | Valor mediano |
Os valores em falta para características categóricas são tratados durante a codificação numérica incluindo uma categoria adicional correspondente a um valor em falta. A imputação está implícita no caso em apreço.
Engenharia automatizada de recursos
O AutoML geralmente adiciona novas colunas aos dados do usuário para aumentar a precisão da modelagem. O recurso de engenharia pode incluir o seguinte:
| Grupo de recursos | Padrão/Opcional |
|---|---|
| Recursos de calendário derivados do índice de tempo (por exemplo, dia da semana) | Predefinido |
| Características categóricas derivadas de IDs de séries cronológicas | Predefinido |
| Codificação de tipos categóricos para tipo numérico | Predefinido |
| Características do indicador para férias associadas a um determinado país ou região | Opcional |
| Desfasamentos em relação à quantidade-alvo | Opcional |
| Atrasos de colunas de feição | Opcional |
| Agregações de janela rolante (por exemplo, média móvel) da quantidade-alvo | Opcional |
| Decomposição sazonal (STL) | Opcional |
Você pode configurar a featurization a partir do SDK do AutoML por meio da classe ForecastingJob ou da interface da Web do estúdio do Azure Machine Learning.
Deteção e manuseamento de séries cronológicas não estacionárias
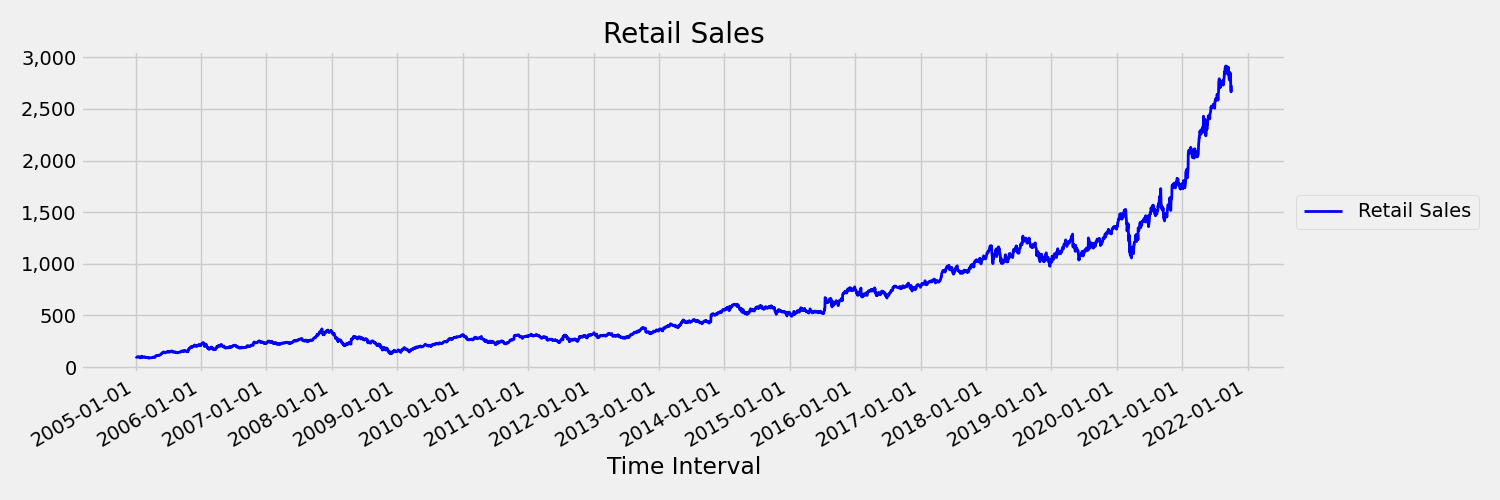
Uma série temporal em que a média e a variância mudam ao longo do tempo é chamada de não-estacionária. Por exemplo, séries temporais que exibem tendências estocásticas não são estacionárias por natureza. Para visualizar isso, a imagem a seguir traça uma série que geralmente está com tendência ascendente. Agora, calcule e compare os valores médios (médios) da primeira e da segunda metade da série. São os mesmos? Aqui, a média da série na primeira metade da trama é significativamente menor do que na segunda metade. O fato de que a média da série depende do intervalo de tempo que se está olhando, é um exemplo dos momentos que variam no tempo. Aqui, a média de uma série é o primeiro momento.
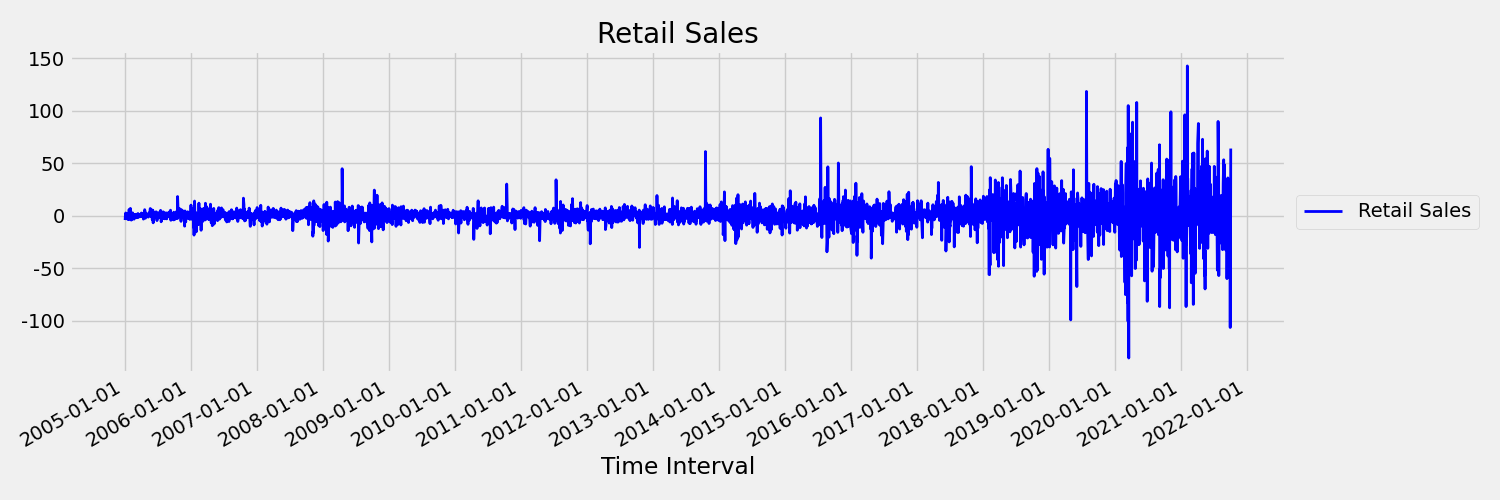
Em seguida, vamos examinar a imagem a seguir, que plota a série original em primeiras diferenças, $\Delta y_{t} = y_t - y_{t-1}$. A média da série é aproximadamente constante ao longo do intervalo de tempo, enquanto a variância parece variar. Assim, este é um exemplo de uma série temporal estacionária de primeira ordem.
Os modelos de regressão AutoML não podem lidar inerentemente com tendências estocásticas ou outros problemas bem conhecidos associados a séries temporais não estacionárias. Como resultado, a precisão da previsão fora da amostra pode ser fraca se tais tendências estiverem presentes.
O AutoML analisa automaticamente o conjunto de dados de séries temporais para determinar a estacionariedade. Quando séries temporais não estacionárias são detetadas, o AutoML aplica uma transformação diferencial automaticamente para mitigar o impacto do comportamento não estacionário.
Varredura de modelos
Depois que os dados são preparados com o tratamento de dados ausentes e a engenharia de recursos, o AutoML varre um conjunto de modelos e hiperparâmetros usando um serviço de recomendação de modelo. Os modelos são classificados com base em métricas de validação ou validação cruzada e, em seguida, opcionalmente, os modelos de topo podem ser usados em um modelo de conjunto. O melhor modelo, ou qualquer um dos modelos treinados, pode ser inspecionado, baixado ou implantado para produzir previsões, conforme necessário. Consulte o artigo Varredura e seleção de modelos para obter mais detalhes.
Agrupamento de modelos
Quando um conjunto de dados contém mais de uma série temporal, como no exemplo de dados fornecido, há várias maneiras de modelar esses dados. Por exemplo, podemos simplesmente agrupar a(s) coluna(s) de identificação da série temporal e treinar modelos independentes para cada série. Uma abordagem mais geral é particionar os dados em grupos que podem conter várias séries provavelmente relacionadas e treinar um modelo por grupo. Por padrão, a previsão de AutoML usa uma abordagem mista para o agrupamento de modelos. Os modelos de séries temporais, mais ARIMAX e Prophet, atribuem uma série a um grupo e outros modelos de regressão atribuem todas as séries a um único grupo. A tabela a seguir resume os agrupamentos de modelos em duas categorias, um-para-um e muitos-para-um:
| Cada série em grupo próprio (1:1) | Todas as séries em grupo único (N:1) |
|---|---|
| Ingênuo, Sazonal Ingênuo, Média, Média Sazonal, Alisamento Exponencial, ARIMA, ARIMAX, Profeta | Linear SGD, LARS LASSO, Elastic Net, K Vizinhos mais próximos, Árvore de decisão, Floresta aleatória, Árvores extremamente aleatórias, Árvores impulsionadas por gradiente, LightGBM, XGBoost, TCNForecaster |
Agrupamentos de modelos mais gerais são possíveis através da solução Many-Models do AutoML; veja o nosso notebook de ML automatizado Muitos Modelos.
Próximos passos
- Saiba mais sobre modelos de aprendizagem profunda para previsão no AutoML
- Saiba mais sobre varredura e seleção de modelos para previsão no AutoML.
- Saiba mais sobre como o AutoML cria recursos a partir do calendário.
- Saiba mais sobre como o AutoML cria recursos de atraso.
- Leia as respostas às perguntas frequentes sobre previsão no AutoML.