Aceder a dados a partir do armazenamento na cloud do Azure durante o desenvolvimento interativo
APLICA-SE A: Python SDK azure-ai-ml v2 (atual)
Python SDK azure-ai-ml v2 (atual)
Um projeto de aprendizado de máquina normalmente começa com análise exploratória de dados (EDA), pré-processamento de dados (limpeza, engenharia de recursos) e inclui a construção de protótipos de modelos de ML para validar hipóteses. Esta fase do projeto de prototipagem é altamente interativa por natureza, e presta-se ao desenvolvimento em um notebook Jupyter, ou um IDE com um console interativo Python. Neste artigo, você aprenderá a:
- Acesse dados de um URI de Armazenamentos de Dados do Azure Machine Learning como se fosse um sistema de arquivos.
- Materialize dados em Pandas usando
mltablea biblioteca Python. - Materialize ativos de dados do Azure Machine Learning em Pandas usando a
mltablebiblioteca Python. - Materializar dados através de um download explícito com o
azcopyutilitário.
Pré-requisitos
- Uma área de trabalho do Azure Machine Learning. Para obter mais informações, consulte Gerenciar espaços de trabalho do Azure Machine Learning no portal ou com o SDK do Python (v2).
- Um armazenamento de dados do Azure Machine Learning. Para obter mais informações, consulte Criar armazenamentos de dados.
Gorjeta
As orientações neste artigo descrevem o acesso a dados durante o desenvolvimento interativo. Ele se aplica a qualquer host que possa executar uma sessão Python. Isso pode incluir sua máquina local, uma VM na nuvem, um GitHub Codespace, etc. Recomendamos o uso de uma instância de computação do Azure Machine Learning - uma estação de trabalho em nuvem totalmente gerenciada e pré-configurada. Para obter mais informações, consulte Criar uma instância de computação do Azure Machine Learning.
Importante
Certifique-se de ter as bibliotecas mais recentes azure-fsspec e mltable python instaladas em seu ambiente python:
pip install -U azureml-fsspec mltable
Acessar dados de um URI de armazenamento de dados, como um sistema de arquivos
Um armazenamento de dados do Azure Machine Learning é uma referência a uma conta de armazenamento existente do Azure. Os benefícios da criação e uso de armazenamento de dados incluem:
- Uma API comum e fácil de usar para interagir com diferentes tipos de armazenamento (Blob/Files/ADLS).
- Fácil descoberta de armazenamentos de dados úteis em operações de equipe.
- Suporte de acesso baseado em credenciais (por exemplo, token SAS) e baseado em identidade (use ID do Microsoft Entra ou identidade gerenciada) para acessar dados.
- Para acesso baseado em credenciais, as informações de conexão são protegidas, para anular a exposição de chaves em scripts.
- Procure dados e copie e cole URIs de armazenamento de dados na interface do usuário do Studio.
Um URI de armazenamento de dados é um Identificador Uniforme de Recursos, que é uma referência a um local de armazenamento (caminho) em sua conta de armazenamento do Azure. Um URI de armazenamento de dados tem este formato:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Esses URIs de armazenamento de dados são uma implementação conhecida da especificação do sistema de arquivos (fsspec): uma interface pythonic unificada para sistemas de arquivos locais, remotos e incorporados e armazenamento de bytes.
Você pode pip instalar o azureml-fsspec pacote e seu pacote de azureml-dataprep dependência. Em seguida, você pode usar a implementação do Azure Machine Learning Datastore fsspec .
A implementação do Repositório fsspec de Dados do Azure Machine Learning lida automaticamente com a passagem de credencial/identidade que o armazenamento de dados do Azure Machine Learning usa. Você pode evitar a exposição da chave de conta em seus scripts e procedimentos de entrada adicionais em uma instância de computação.
Por exemplo, você pode usar diretamente URIs Datastore no Pandas. Este exemplo mostra como ler um arquivo CSV:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Gorjeta
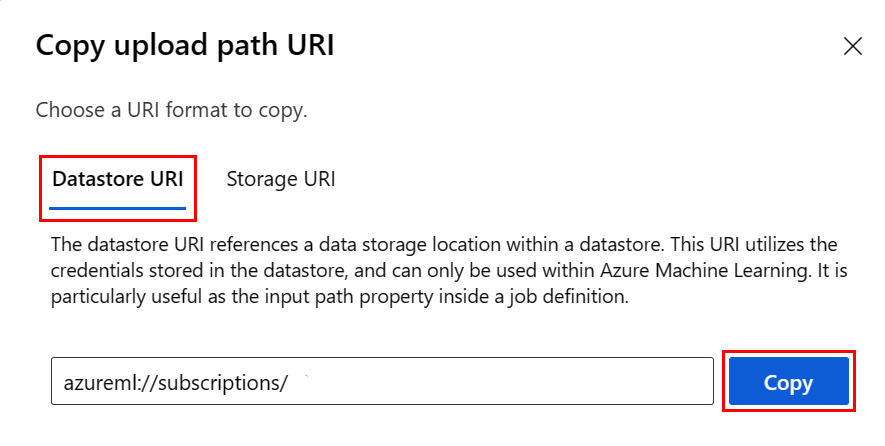
Em vez de lembrar o formato URI do armazenamento de dados, você pode copiar e colar o URI do armazenamento de dados da interface do usuário do Studio com estas etapas:
- Selecione Dados no menu à esquerda e, em seguida, selecione a guia Armazenamentos de dados.
- Selecione o nome do armazenamento de dados e, em seguida , Procurar.
- Encontre o arquivo/pasta que deseja ler no Pandas e selecione as reticências (...) ao lado dele. Selecione Copiar URI no menu. Você pode selecionar o URI do Datastore para copiar em seu bloco de anotações/script.
Você também pode instanciar um sistema de arquivos do Azure Machine Learning para manipular comandos semelhantes a sistemas de arquivos - por exemplols, , glob, , existsopen.
- O
ls()método lista arquivos em um diretório específico. Você pode usar ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) para listar arquivos. Apoiamos tanto '.' como '..', em caminhos relativos. - O
glob()método suporta '*' e '**' globbing. - O
exists()método retorna um valor Boolean que indica se um arquivo especificado existe no diretório raiz atual. - O
open()método retorna um objeto semelhante a um arquivo, que pode ser passado para qualquer outra biblioteca que espera trabalhar com arquivos python. Seu código também pode usar esse objeto, como se fosse um objeto de arquivo python normal. Esses objetos semelhantes a arquivos respeitam o uso dewithcontextos, conforme mostrado neste exemplo:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Carregar ficheiros através do AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath é o caminho local e rpath é o caminho remoto.
Se as pastas especificadas ainda rpath não existirem, criaremos as pastas para você.
Suportamos três modos de 'substituição':
- ACRESCENTAR: se existir um arquivo com o mesmo nome no caminho de destino, isso manterá o arquivo original
- FAIL_ON_FILE_CONFLICT: Se existir um arquivo com o mesmo nome no caminho de destino, isso gera um erro
- MERGE_WITH_OVERWRITE: Se existir um arquivo com o mesmo nome no caminho de destino, isso substituirá esse arquivo existente pelo novo arquivo
Baixar arquivos via AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Exemplos
Estes exemplos mostram o uso da especificação do sistema de arquivos em cenários comuns.
Leia um único arquivo CSV no Pandas
Você pode ler um único arquivo CSV no Pandas como mostrado:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Leia uma pasta de arquivos CSV no Pandas
O método Pandas read_csv() não suporta a leitura de uma pasta de arquivos CSV. Você deve glob caminhos csv e concatená-los em um quadro de dados com o método Pandas concat() . O próximo exemplo de código mostra como obter essa concatenação com o sistema de arquivos do Azure Machine Learning:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Lendo arquivos CSV no Dask
Este exemplo mostra como ler um arquivo CSV em um quadro de dados do Dask:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Leia uma pasta de arquivos de parquet no Pandas
Como parte de um processo ETL, os arquivos Parquet são normalmente gravados em uma pasta, que pode emitir arquivos relevantes para o ETL, como progresso, confirmações, etc. Este exemplo mostra arquivos criados a partir de um processo ETL (arquivos começando com _) que, em seguida, produzem um arquivo parquet de dados.
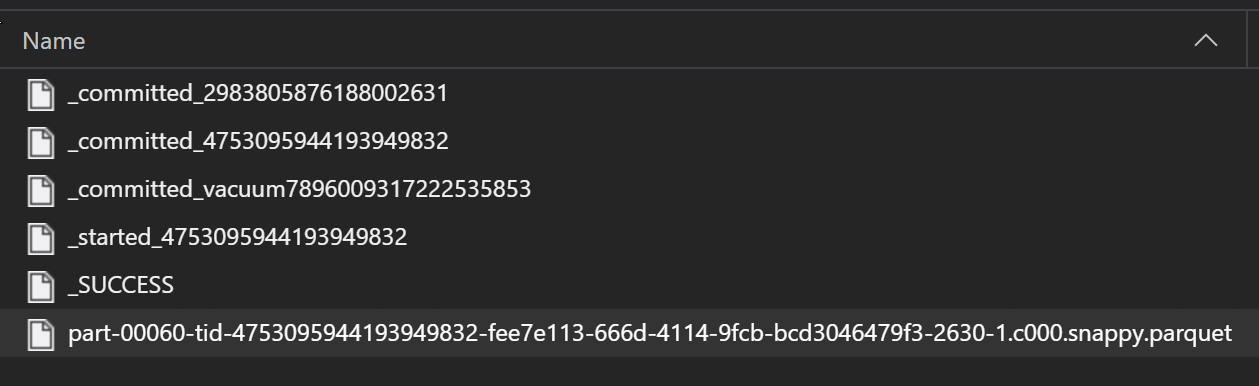
Nesses cenários, você só lerá os arquivos parquet na pasta e ignorará os arquivos de processo ETL. Este exemplo de código mostra como os padrões glob podem ler somente arquivos parquet em uma pasta:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Acessando dados do seu sistema de arquivos Azure Databricks (dbfs)
A especificação do sistema de arquivos () tem uma variedade de implementações conhecidas, incluindo o sistema de arquivos Databricks (fsspecdbfs).
Para aceder aos seus dados dbfs precisa:
- Nome da instância, na forma de
adb-<some-number>.<two digits>.azuredatabricks.net. Você pode encontrar esse valor na URL do seu espaço de trabalho do Azure Databricks. - Token de Acesso Pessoal (PAT); para obter mais informações sobre a criação de PAT, consulte Autenticação usando tokens de acesso pessoal do Azure Databricks
Com esses valores, você deve criar uma variável de ambiente em sua instância de computação para o token PAT:
export ADB_PAT=<pat_token>
Em seguida, você pode acessar dados no Pandas, conforme mostrado neste exemplo:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Leitura de imagens com pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Exemplo de conjunto de dados personalizado do PyTorch
Neste exemplo, você cria um conjunto de dados personalizado do PyTorch para processar imagens. Assumimos que existe um ficheiro de anotações (em formato CSV), com esta estrutura geral:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
As subpastas armazenam essas imagens, de acordo com seus rótulos:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Uma classe de conjunto de dados PyTorch personalizada deve implementar três funções: , e __getitem__, __len__conforme mostrado aqui: __init__
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Em seguida, você pode instanciar o conjunto de dados conforme mostrado aqui:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Materialize dados em Pandas usando mltable a biblioteca
A mltable biblioteca também pode ajudar a acessar dados no armazenamento em nuvem. A leitura de dados em Pandas com mltable tem este formato geral:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Caminhos suportados
A mltable biblioteca suporta a leitura de dados tabulares de diferentes tipos de caminho:
| Localização | Exemplos |
|---|---|
| Um caminho no computador local | ./home/username/data/my_data |
| Um caminho em um servidor http(s) público(s) | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Um caminho no Armazenamento do Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Um armazenamento de dados de longo prazo do Azure Machine Learning | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Nota
mltable faz a passagem de credenciais do usuário para caminhos no Armazenamento do Azure e nos armazenamentos de dados do Azure Machine Learning. Se você não tiver permissão para acessar os dados no armazenamento subjacente, não poderá acessar os dados.
Ficheiros, pastas e globs
mltable Suporta leitura de:
- ficheiro(s) - por exemplo:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - pasta(s) - por exemplo
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - Padrão(s) glob - por exemplo
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - uma combinação de arquivos, pastas e/ou padrões de globbing
mltable A flexibilidade permite a materialização de dados em um único dataframe, a partir de uma combinação de recursos de armazenamento local e em nuvem e combinações de arquivos/pastas/globs. Por exemplo:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Formatos de ficheiro suportados
mltable suporta os seguintes formatos de ficheiro:
- Texto delimitado (por exemplo: ficheiros CSV):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - Formato de linhas JSON:
mltable.from_json_lines_files(paths=[path])
Exemplos
Ler um ficheiro CSV
Atualize os espaços reservados (<>) neste trecho de código com seus detalhes específicos:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Ler arquivos parquet em uma pasta
Este exemplo mostra como pode usar padrões glob - como mltable curingas - para garantir que apenas os arquivos parquet sejam lidos.
Atualize os espaços reservados (<>) neste trecho de código com seus detalhes específicos:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Leitura de ativos de dados
Esta seção mostra como acessar seus ativos de dados do Azure Machine Learning no Pandas.
Ativo de tabela
Se você criou anteriormente um ativo de tabela no Azure Machine Learning (um , ou um mltableV1 TabularDataset), você pode carregar esse ativo de tabela no Pandas com este código:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Ativo de arquivo
Se você registrou um ativo de arquivo (um arquivo CSV, por exemplo), você pode ler esse ativo em um quadro de dados Pandas com este código:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Ativo de pasta
Se você registrou um ativo de pasta (uri_folder ou um V1 FileDataset) - por exemplo, uma pasta contendo um arquivo CSV - você pode ler esse ativo em um quadro de dados Pandas com este código:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Uma nota sobre a leitura e processamento de grandes volumes de dados com Pandas
Gorjeta
O Pandas não foi projetado para lidar com grandes conjuntos de dados - o Pandas só pode processar dados que cabem na memória da instância de computação.
Para grandes conjuntos de dados, recomendamos o uso do Azure Machine Learning gerenciado Spark. Isso fornece a API PySpark Pandas.
Talvez você queira iterar rapidamente em um subconjunto menor de um conjunto de dados grande antes de escalar para um trabalho assíncrono remoto. mltable fornece funcionalidade integrada para obter amostras de dados grandes usando o método take_random_sample :
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Você também pode usar subconjuntos de dados grandes com estas operações:
Download de dados usando o azcopy utilitário
Use o utilitário para baixar os dados para o azcopy SSD local do seu host (máquina local, VM na nuvem, Instância de Computação do Azure Machine Learning) no sistema de arquivos local. O azcopy utilitário, que é pré-instalado em uma instância de computação do Azure Machine Learning, lidará com isso. Se você não usar uma instância de computação do Azure Machine Learning ou uma DSVM (Máquina Virtual de Ciência de Dados), talvez seja necessário instalar azcopyo . Consulte azcopy para obter mais informações.
Atenção
Não recomendamos downloads de dados para o /home/azureuser/cloudfiles/code local em uma instância de computação. Esse local foi projetado para armazenar artefatos de bloco de anotações e códigos, não dados. A leitura de dados deste local incorrerá em uma sobrecarga de desempenho significativa durante o treinamento. Em vez disso, recomendamos o armazenamento de dados no , que é o home/azureuserSSD local do nó de computação.
Abra um terminal e crie um novo diretório, por exemplo:
mkdir /home/azureuser/data
Inicie sessão no azcopy usando:
azcopy login
Em seguida, você pode copiar dados usando um URI de armazenamento
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST