DevOps para um pipeline de ingestão de dados
Na maioria dos cenários, uma solução de ingestão de dados é uma composição de scripts, invocações de serviço e um pipeline orquestrando todas as atividades. Neste artigo, você aprenderá a aplicar práticas de DevOps ao ciclo de vida de desenvolvimento de um pipeline comum de ingestão de dados que prepara dados para treinamento de modelo de aprendizado de máquina. O pipeline é criado usando os seguintes serviços do Azure:
- Azure Data Factory: lê os dados brutos e orquestra a preparação de dados.
- Azure Databricks: executa um bloco de anotações Python que transforma os dados.
- Azure Pipelines: automatiza um processo contínuo de integração e desenvolvimento.
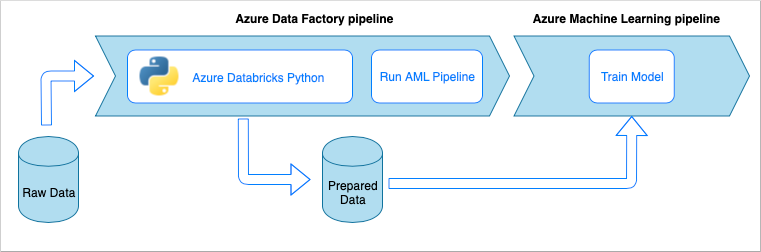
Fluxo de trabalho do pipeline de ingestão de dados
O pipeline de ingestão de dados implementa o seguinte fluxo de trabalho:
- Os dados brutos são lidos em um pipeline do Azure Data Factory (ADF).
- O pipeline do ADF envia os dados para um cluster do Azure Databricks, que executa um bloco de anotações Python para transformar os dados.
- Os dados são armazenados em um contêiner de blob, onde podem ser usados pelo Aprendizado de Máquina do Azure para treinar um modelo.
Visão geral da integração contínua e da entrega
Tal como acontece com muitas soluções de software, há uma equipa (por exemplo, Engenheiros de Dados) a trabalhar nela. Eles colaboram e compartilham os mesmos recursos do Azure, como Azure Data Factory, Azure Databricks e contas de Armazenamento do Azure. A recolha destes recursos é um ambiente de desenvolvimento. Os engenheiros de dados contribuem para a mesma base de código-fonte.
Um sistema de integração e entrega contínua automatiza o processo de criação, teste e entrega (implantação) da solução. O processo de Integração Contínua (IC) executa as seguintes tarefas:
- Monta o código
- Verifica isso com os testes de qualidade do código
- Executa testes de unidade
- Produz artefatos como código testado e modelos do Azure Resource Manager
O processo de Entrega Contínua (CD) implanta os artefatos nos ambientes downstream.
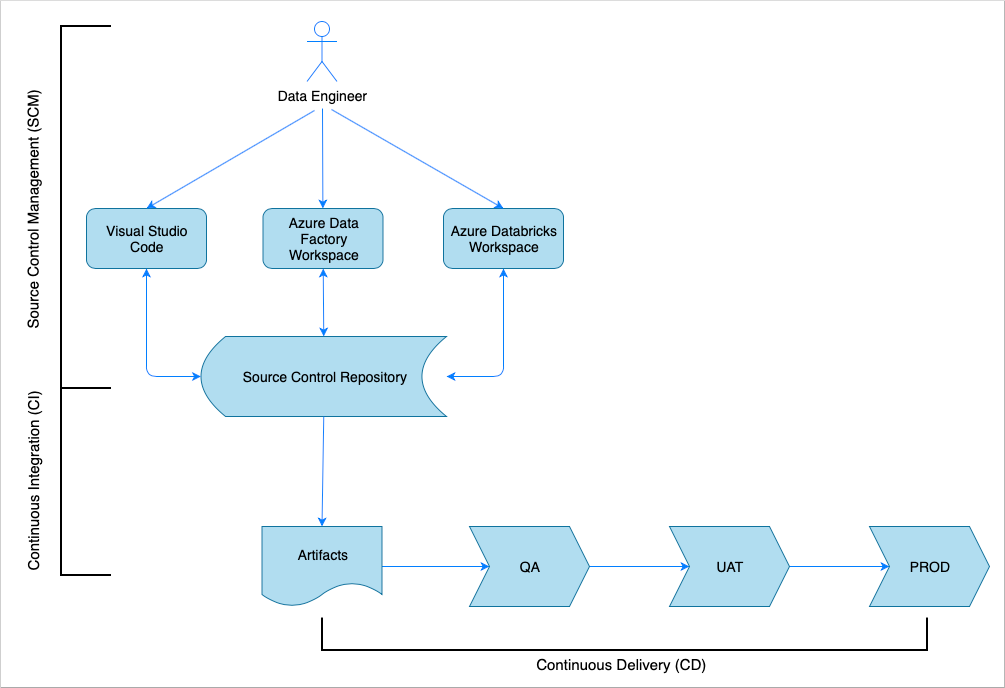
Este artigo demonstra como automatizar os processos de CI e CD com o Azure Pipelines.
Gerenciamento de controle de origem
O gerenciamento de controle do código-fonte é necessário para controlar as alterações e permitir a colaboração entre os membros da equipe. Por exemplo, o código seria armazenado em um repositório do Azure DevOps, GitHub ou GitLab. O fluxo de trabalho de colaboração é baseado em um modelo de ramificação.
Código-fonte Python Notebook
Os engenheiros de dados trabalham com o código-fonte do bloco de anotações Python localmente em um IDE (por exemplo, Visual Studio Code) ou diretamente no espaço de trabalho Databricks. Quando as alterações de código são concluídas, elas são mescladas ao repositório seguindo uma política de ramificação.
Gorjeta
Recomendamos armazenar o código em arquivos em .py vez de no .ipynb formato Jupyter Notebook. Ele melhora a legibilidade do código e permite verificações automáticas da qualidade do código no processo de CI.
Código-fonte do Azure Data Factory
O código-fonte dos pipelines do Azure Data Factory é uma coleção de arquivos JSON gerados por um espaço de trabalho do Azure Data Factory. Normalmente, os engenheiros de dados trabalham com um designer visual no espaço de trabalho do Azure Data Factory em vez de diretamente com os arquivos de código-fonte.
Para configurar o espaço de trabalho para usar um repositório de controle de origem, consulte Criar com a integração do Azure Repos Git.
Integração contínua (CI)
O objetivo final do processo de Integração Contínua é reunir o trabalho conjunto da equipe a partir do código-fonte e prepará-lo para a implantação nos ambientes downstream. Assim como no gerenciamento do código-fonte, esse processo é diferente para os blocos de anotações Python e pipelines do Azure Data Factory.
Python Notebook CI
O processo de CI para os Blocos de Anotações Python obtém o código da ramificação de colaboração (por exemplo, mestre ou desenvolvimento) e executa as seguintes atividades:
- Linting de código
- Teste de unidades
- Salvando o código como um artefato
O trecho de código a seguir demonstra a implementação dessas etapas em um pipeline yaml do Azure DevOps:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
O pipeline usa flake8 para fazer o alinhamento de código Python. Ele executa os testes de unidade definidos no código-fonte e publica o forro e os resultados do teste para que estejam disponíveis na tela de execução do Azure Pipelines.
Se o linting e o teste de unidade forem bem-sucedidos, o pipeline copiará o código-fonte para o repositório de artefatos a ser usado pelas etapas de implantação subsequentes.
Azure Data Factory CI
O processo de CI para um pipeline do Azure Data Factory é um gargalo para um pipeline de ingestão de dados. Não há integração contínua. Um artefato implantável para o Azure Data Factory é uma coleção de modelos do Azure Resource Manager. A única maneira de produzir esses modelos é clicar no botão publicar no espaço de trabalho do Azure Data Factory.
- Os engenheiros de dados mesclam o código-fonte de suas ramificações de recursos na ramificação de colaboração, por exemplo, mestre ou desenvolvimento.
- Alguém com as permissões concedidas clica no botão de publicação para gerar modelos do Azure Resource Manager a partir do código-fonte na ramificação de colaboração.
- O espaço de trabalho valida os pipelines (pense nisso como linting e teste de unidade), gera modelos do Azure Resource Manager (pense nisso como de criação) e salva os modelos gerados em uma ramificação técnica adf_publish no mesmo repositório de código (pense nisso como publicar artefatos). Essa ramificação é criada automaticamente pelo espaço de trabalho do Azure Data Factory.
Para obter mais informações sobre esse processo, consulte Integração e entrega contínuas no Azure Data Factory.
É importante certificar-se de que os modelos gerados do Azure Resource Manager são agnósticos em relação ao ambiente. Isso significa que todos os valores que podem diferir entre ambientes são parametrizados. O Azure Data Factory é inteligente o suficiente para expor a maioria desses valores como parâmetros. Por exemplo, no modelo a seguir, as propriedades de conexão com um espaço de trabalho do Azure Machine Learning são expostas como parâmetros:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
No entanto, convém expor suas propriedades personalizadas que não são manipuladas pelo espaço de trabalho do Azure Data Factory por padrão. No cenário deste artigo, um pipeline do Azure Data Factory invoca um bloco de anotações Python que processa os dados. O bloco de notas aceita um parâmetro com o nome de um ficheiro de dados de entrada.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
Esse nome é diferente para ambientes Dev, QA, UAT e PROD. Em um pipeline complexo com várias atividades, pode haver várias propriedades personalizadas. É uma boa prática coletar todos esses valores em um só lugar e defini-los como variáveis de pipeline:

As atividades de pipeline podem se referir às variáveis de pipeline enquanto realmente as usam:
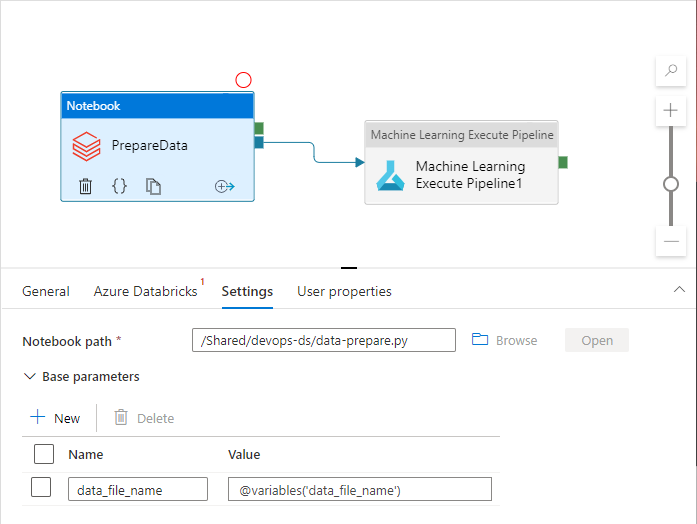
O espaço de trabalho do Azure Data Factory não expõe variáveis de pipeline como parâmetros de modelos do Azure Resource Manager por padrão. O espaço de trabalho usa o Modelo de Parametrização Padrão que dita quais propriedades de pipeline devem ser expostas como parâmetros de modelo do Azure Resource Manager. Para adicionar variáveis de pipeline à lista, atualize a "Microsoft.DataFactory/factories/pipelines"seção do Modelo de Parametrização Padrão com o seguinte trecho e coloque o arquivo json de resultado na raiz da pasta de origem:
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
Isso forçará o espaço de trabalho do Azure Data Factory a adicionar as variáveis à lista de parâmetros quando o botão de publicação for clicado:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
Os valores no arquivo JSON são valores padrão configurados na definição de pipeline. Espera-se que eles sejam substituídos pelos valores do ambiente de destino quando o modelo do Azure Resource Manager for implantado.
Entrega contínua (CD)
O processo de Entrega Contínua pega os artefatos e os implanta no primeiro ambiente de destino. Ele garante que a solução funcione executando testes. Se for bem-sucedido, ele continua para o próximo ambiente.
O CD Azure Pipelines consiste em vários estágios que representam os ambientes. Cada estágio contém implantações e trabalhos que executam as seguintes etapas:
- Implantar um Python Notebook no espaço de trabalho do Azure Databricks
- Implantar um pipeline do Azure Data Factory
- Executar o pipeline
- Verifique o resultado da ingestão de dados
Os estágios de pipeline podem ser configurados com aprovações e portas que fornecem controle adicional sobre como o processo de implantação evolui através da cadeia de ambientes.
Implantar um bloco de anotações Python
O trecho de código a seguir define uma implantação do Azure Pipeline que copia um bloco de anotações Python para um cluster Databricks:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
Os artefatos produzidos pelo CI são copiados automaticamente para o agente de implantação e estão disponíveis na $(Pipeline.Workspace) pasta. Nesse caso, a tarefa de implementação refere-se ao di-notebooks artefato que contém o bloco de anotações Python. Essa implantação usa a extensão Databricks Azure DevOps para copiar os arquivos do bloco de anotações para o espaço de trabalho Databricks.
O Deploy_to_QA estágio contém uma referência ao devops-ds-qa-vg grupo de variáveis definido no projeto Azure DevOps. As etapas nesta etapa referem-se às variáveis desse grupo de variáveis (por exemplo, $(DATABRICKS_URL) e $(DATABRICKS_TOKEN)). A ideia é que o próximo estágio (por exemplo, Deploy_to_UAT) opere com os mesmos nomes de variáveis definidos em seu próprio grupo de variáveis com escopo UAT.
Implantar um pipeline do Azure Data Factory
Um artefato implantável para o Azure Data Factory é um modelo do Azure Resource Manager. Ele será implantado com a tarefa de Implantação do Grupo de Recursos do Azure, conforme demonstrado no seguinte trecho:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
O valor do parâmetro data filename vem da variável definida em um grupo de variáveis de estágio de QA $(DATA_FILE_NAME) . Da mesma forma, todos os parâmetros definidos em ARMTemplateForFactory.json podem ser substituídos. Se não estiverem, os valores padrão serão usados.
Execute o pipeline e verifique o resultado da ingestão de dados
A próxima etapa é certificar-se de que a solução implantada está funcionando. A definição de trabalho a seguir executa um pipeline do Azure Data Factory com um script do PowerShell e executa um bloco de anotações Python em um cluster do Azure Databricks. O bloco de notas verifica se os dados foram ingeridos corretamente e valida o ficheiro de dados do resultado com $(bin_FILE_NAME) o nome.
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
A tarefa final no trabalho verifica o resultado da execução do bloco de anotações. Se retornar um erro, ele definirá o status da execução do pipeline como falha.
Juntando peças
O Pipeline do Azure CI/CD completo consiste nos seguintes estágios:
- IC
- Implantar no QA
- Implantar no Databricks + Implantar no ADF
- Teste de integração
Ele contém um número de estágios de implantação igual ao número de ambientes de destino que você tem. Cada estágio de implantação contém duas implantações que são executadas em paralelo e um trabalho que é executado após as implantações para testar a solução no ambiente.
Uma implementação de exemplo do pipeline é montada no seguinte trecho de yaml:
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'