Configurar um ambiente de desenvolvimento com o Azure Databricks e o AutoML no Azure Machine Learning
Saiba como configurar um ambiente de desenvolvimento no Azure Machine Learning que utiliza o Azure Databricks e o ML automatizado.
O Azure Databricks é ideal para executar fluxos de trabalho de machine learning intensivos em larga escala na plataforma do Apache Spark dimensionável na cloud do Azure. Fornece um ambiente colaborativo baseado em Blocos de Notas com um cluster de computação baseado em CPU ou GPU.
Para obter informações sobre outros ambientes de desenvolvimento de machine learning, veja Configurar o ambiente de desenvolvimento do Python.
Pré-requisito
Área de trabalho do Azure Machine Learning. Para criar um, utilize os passos no artigo Criar recursos da área de trabalho .
Azure Databricks com o Azure Machine Learning e AutoML
O Azure Databricks integra-se com o Azure Machine Learning e as respetivas capacidades de AutoML.
Pode utilizar o Azure Databricks:
- Para preparar um modelo com o Spark MLlib e implementar o modelo no ACI/AKS.
- Com capacidades automatizadas de machine learning com um SDK do Azure Machine Learning.
- Como destino de computação de um pipeline do Azure Machine Learning.
Configurar um cluster do Databricks
Criar um cluster do Databricks. Algumas definições aplicam-se apenas se instalar o SDK para machine learning automatizado no Databricks.
Demora alguns minutos a criar o cluster.
Utilize estas definições:
| Definições | Aplica-se a | Valor |
|---|---|---|
| Nome do Cluster | sempre | yourclustername |
| Versão do Databricks Runtime | sempre | 9.1 LTS |
| Versão de Python | sempre | 3 |
| Tipo de Trabalho (determina o n.º máximo de iterações simultâneas) |
ML Automatizado apenas |
Preferida da VM otimizada para memória |
| Trabalhadores | sempre | 2 ou superior |
| Ativar o Dimensionamento Automático | ML Automatizado apenas |
Desselecionar |
Aguarde até que o cluster esteja em execução antes de continuar.
Adicionar o SDK do Azure Machine Learning ao Databricks
Assim que o cluster estiver em execução, crie uma biblioteca para anexar o pacote do SDK do Azure Machine Learning adequado ao cluster.
Para utilizar o ML automatizado, avance para Adicionar o SDK do Azure Machine Learning com AutoML.
Clique com o botão direito do rato na pasta área de trabalho atual onde pretende armazenar a biblioteca. Selecione Criar>Biblioteca.
Dica
Se tiver uma versão antiga do SDK, desmarque-a das bibliotecas instaladas do cluster e mude para o lixo. Instale a nova versão do SDK e reinicie o cluster. Se existir um problema após o reinício, desencaixe e volte a ligar o cluster.
Escolha a seguinte opção (não são suportadas outras instalações do SDK)
Extras do pacote SDK Origem Nome do PyPi Para o Databricks Carregar Ovo python ou PyPI azureml-sdk[databricks] Aviso
Não é possível instalar outros extras do SDK. Selecione apenas a opção [
databricks] .- Não selecione Anexar automaticamente a todos os clusters.
- Selecione Anexar junto ao nome do cluster.
Monitorize os erros até que o estado mude para Anexado, o que pode demorar vários minutos. Se este passo falhar:
Experimente reiniciar o cluster ao:
- No painel esquerdo, selecione Clusters.
- Na tabela, selecione o nome do cluster.
- No separador Bibliotecas , selecione Reiniciar.
Uma instalação com êxito tem o seguinte aspeto:
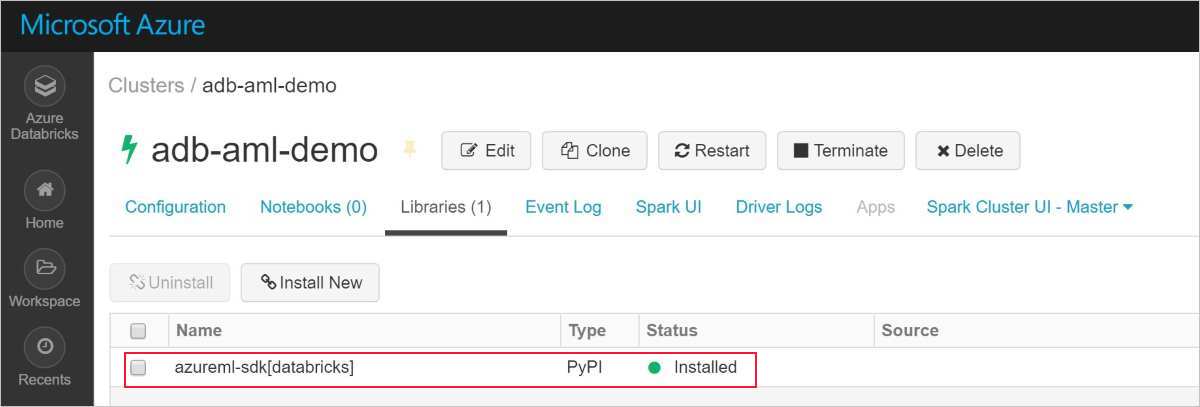
Adicionar o SDK do Azure Machine Learning com AutoML ao Databricks
Se o cluster tiver sido criado com o Databricks Runtime 7.3 LTS (não ML), execute o seguinte comando na primeira célula do seu bloco de notas para instalar o SDK do Azure Machine Learning.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
Definições de configuração do AutoML
Na configuração autoML, ao utilizar o Azure Databricks, adicione os seguintes parâmetros:
max_concurrent_iterationsbaseia-se no número de nós de trabalho no cluster.spark_context=scbaseia-se no contexto do Spark predefinido.
Blocos de notas ML que funcionam com o Azure Databricks
Experimente:
Embora muitos blocos de notas de exemplo estejam disponíveis, apenas estes blocos de notas de exemplo funcionam com o Azure Databricks.
Importe estes exemplos diretamente a partir da área de trabalho. Veja abaixo:
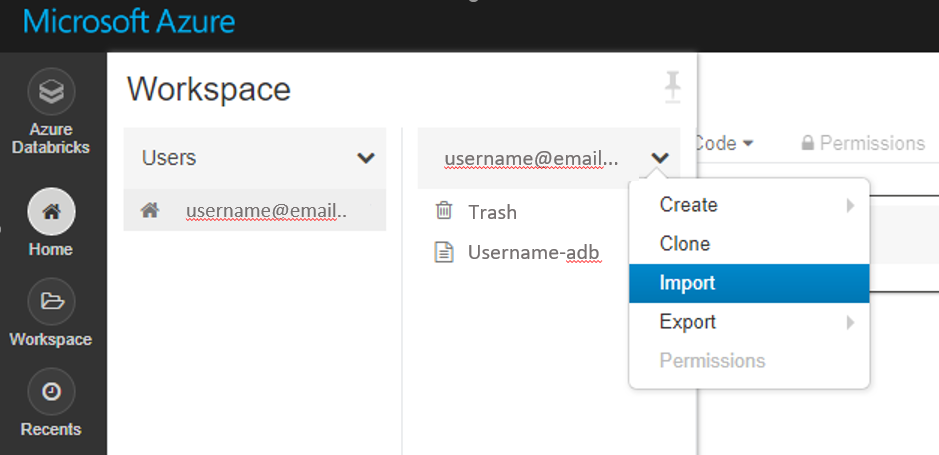
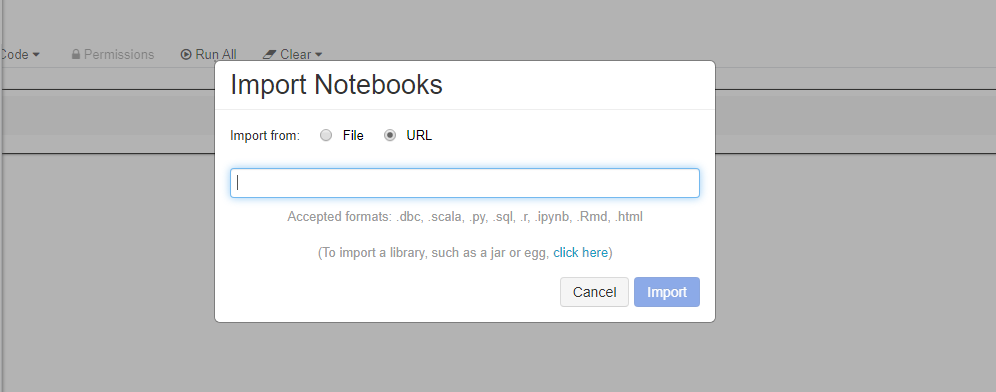
Saiba como criar um pipeline com o Databricks como computação de preparação.
Resolução de problemas
O Databricks cancela uma execução de machine learning automatizada: quando utiliza capacidades automatizadas de machine learning no Azure Databricks, para cancelar uma execução e iniciar uma nova execução de experimentação, reinicie o cluster do Azure Databricks.
Iterações do Databricks >10 para machine learning automatizado: nas definições automatizadas de machine learning, se tiver mais de 10 iterações, defina
show_outputcomoFalsequando submeter a execução.Widget do Databricks para o SDK do Azure Machine Learning e machine learning automatizado: o widget SDK do Azure Machine Learning não é suportado num bloco de notas do Databricks porque os blocos de notas não conseguem analisar widgets HTML. Pode ver o widget no portal com este código Python na célula do bloco de notas do Azure Databricks:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Falha ao instalar pacotes
A instalação do SDK do Azure Machine Learning falha no Azure Databricks quando são instalados mais pacotes. Alguns pacotes, como
psutil, podem causar conflitos. Para evitar erros de instalação, instale pacotes ao congelar a versão da biblioteca. Este problema está relacionado com o Databricks e não com o SDK do Azure Machine Learning. Também poderá ter este problema com outras bibliotecas. Exemplo:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0Em alternativa, pode utilizar scripts init se continuar a ter problemas de instalação com bibliotecas python. Esta abordagem não é oficialmente suportada. Para obter mais informações, veja Scripts init com âmbito de cluster.
Erro de importação: não é possível importar o nome
Timedeltade : Se vir este erro quando utiliza machine learning automatizado, execute as duas linhas seguintes no seu bloco depandas._libs.tslibsnotas:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Erro de importação: nenhum módulo com o nome "pandas.core.indexes": se vir este erro quando utiliza machine learning automatizado:
Execute este comando para instalar dois pacotes no cluster do Azure Databricks:
scikit-learn==0.19.1 pandas==0.22.0Desencaixe e, em seguida, volte a ligar o cluster ao seu bloco de notas.
Se estes passos não resolverem o problema, tente reiniciar o cluster.
FailToSendFeather: se vir um
FailToSendFeathererro ao ler dados no cluster do Azure Databricks, veja as seguintes soluções:- Atualize
azureml-sdk[automl]o pacote para a versão mais recente. - Adicione
azureml-dataprepa versão 1.1.8 ou superior. - Adicione
pyarrowa versão 0.11 ou superior.
- Atualize
Passos seguintes
- Preparar e implementar um modelo no Azure Machine Learning com o conjunto de dados MNIST.
- Veja a referência do SDK do Azure Machine Learning para Python.