Rastreie experimentos e modelos de ML com MLflow
Neste artigo, você aprenderá a usar o MLflow para controlar seus experimentos e execuções em espaços de trabalho do Azure Machine Learning.
O rastreamento é o processo de salvar informações relevantes sobre os experimentos que você executa. As informações salvas (metadados) variam de acordo com o seu projeto e podem incluir:
- Código
- Detalhes do ambiente (como versão do sistema operacional, pacotes Python)
- Dados de entrada
- Configurações de parâmetros
- Modelos
- Métricas de avaliação
- Visualizações de avaliação (tais como matrizes de confusão, gráficos de importância)
- Resultados da avaliação (incluindo algumas previsões de avaliação)
Quando você está trabalhando com trabalhos no Azure Machine Learning, o Azure Machine Learning rastreia automaticamente algumas informações sobre seus experimentos, como código, ambiente e dados de entrada e saída. No entanto, para outros, como modelos, parâmetros e métricas, o construtor de modelos precisa configurar seu rastreamento, pois eles são específicos para o cenário específico.
Nota
Se você quiser acompanhar experimentos que estão sendo executados no Azure Databricks, consulte Rastrear experimentos de ML do Azure Databricks com MLflow e Azure Machine Learning. Para saber mais sobre o acompanhamento de experiências em execução no Azure Synapse Analytics, consulte Acompanhar experiências de ML do Azure Synapse Analytics com MLflow e Azure Machine Learning.
Benefícios do rastreamento de experimentos
Recomendamos vivamente que os profissionais de aprendizagem automática acompanhem as experiências, quer esteja a treinar com trabalhos no Azure Machine Learning ou a treinar interativamente em blocos de notas. O acompanhamento de experiências permite-lhe:
- Organize todos os seus experimentos de aprendizado de máquina em um único lugar. Em seguida, você pode pesquisar e filtrar experimentos e detalhar para ver detalhes sobre os experimentos executados antes.
- Compare experimentos, analise resultados e depure o treinamento do modelo com pouco trabalho extra.
- Reproduza ou execute novamente experimentos para validar os resultados.
- Melhore a colaboração, pois você pode ver o que outros colegas de equipe estão fazendo, compartilhar resultados de experimentos e acessar dados de experimentos programaticamente.
Por que usar o MLflow para rastrear experimentos?
Os espaços de trabalho do Azure Machine Learning são compatíveis com MLflow, o que significa que você pode usar o MLflow para controlar execuções, métricas, parâmetros e artefatos em seus espaços de trabalho do Azure Machine Learning. Uma grande vantagem de usar o MLflow para rastreamento é que você não precisa alterar suas rotinas de treinamento para trabalhar com o Aprendizado de Máquina do Azure ou injetar qualquer sintaxe específica da nuvem.
Para obter mais informações sobre todas as funcionalidades de MLflow e Azure Machine Learning suportadas, consulte MLflow e Azure Machine Learning.
Limitações
Alguns métodos disponíveis na API MLflow podem não estar disponíveis quando conectados ao Azure Machine Learning. Para obter detalhes sobre operações com e sem suporte, consulte Matriz de suporte para consultar execuções e experimentos.
Pré-requisitos
- Uma subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
Instale o pacote
mlflowMLflow SDK e o plug-in do Azure Machine Learning para MLflowazureml-mlflow.pip install mlflow azureml-mlflowGorjeta
Você pode usar o
mlflow-skinnypacote, que é um pacote MLflow leve sem dependências de armazenamento SQL, servidor, interface do usuário ou ciência de dados.mlflow-skinnyé recomendado para usuários que precisam principalmente dos recursos de rastreamento e registro em log do MLflow sem importar o conjunto completo de recursos, incluindo implantações.Uma área de trabalho do Azure Machine Learning. Você pode criar um seguindo o tutorial Criar recursos de aprendizado de máquina.
Se você estiver executando o rastreamento remoto (ou seja, rastreando experimentos que estão sendo executados fora do Aprendizado de Máquina do Azure), configure o MLflow para apontar para o URI de rastreamento do seu espaço de trabalho do Azure Machine Learning. Para obter mais informações sobre como conectar o MLflow ao seu espaço de trabalho, consulte Configurar o MLflow para o Azure Machine Learning.
Configurar a experiência
O MLflow organiza informações em experimentos e execuções (as execuções são chamadas de trabalhos no Azure Machine Learning). Por padrão, as execuções são registradas em um experimento chamado Padrão que é criado automaticamente para você. Você pode configurar o experimento onde o rastreamento está acontecendo.
Para treinamento interativo, como em um bloco de anotações Jupyter, use o comando mlflow.set_experiment()MLflow . Por exemplo, o trecho de código a seguir configura um experimento:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Configurar a execução
O Azure Machine Learning rastreia qualquer trabalho de treinamento no que o MLflow chama de execução. Use execuções para capturar todo o processamento que seu trabalho executa.
Quando você está trabalhando interativamente, o MLflow começa a acompanhar sua rotina de treinamento assim que você tenta registrar informações que exigem uma execução ativa. Por exemplo, o rastreamento MLflow começa quando você registra uma métrica, um parâmetro ou inicia um ciclo de treinamento, e a funcionalidade de registro automático do Mlflow está habilitada. No entanto, geralmente é útil iniciar a execução explicitamente, especialmente se você quiser capturar o tempo total para seu experimento no campo Duração . Para iniciar a execução explicitamente, use mlflow.start_run().
Independentemente de você iniciar a execução manualmente ou não, você eventualmente precisará interromper a execução, para que o MLflow saiba que sua execução de experimento está concluída e possa marcar o status da execução como Concluído. Para parar uma corrida, use mlflow.end_run().
Recomendamos vivamente que inicie as execuções manualmente, para que não se esqueça de as terminar quando estiver a trabalhar em blocos de notas.
Para iniciar uma execução manualmente e terminá-la quando terminar de trabalhar no bloco de notas:
mlflow.start_run() # Your code mlflow.end_run()Geralmente é útil usar o paradigma do gerenciador de contexto para ajudá-lo a se lembrar de terminar a corrida:
with mlflow.start_run() as run: # Your codeQuando você inicia uma nova execução com
mlflow.start_run()o , pode ser útil especificar orun_nameparâmetro, que posteriormente se traduz no nome da execução na interface do usuário do Aprendizado de Máquina do Azure e ajudá-lo a identificar a execução mais rapidamente:with mlflow.start_run(run_name="hello-world-example") as run: # Your code
Habilitar o registro automático do MLflow
Você pode registrar métricas, parâmetros e arquivos com MLflow manualmente. No entanto, você também pode confiar no recurso de registro automático do MLflow. Cada estrutura de aprendizado de máquina suportada pelo MLflow decide o que rastrear automaticamente para você.
Para habilitar o registro automático, insira o seguinte código antes do código de treinamento:
mlflow.autolog()
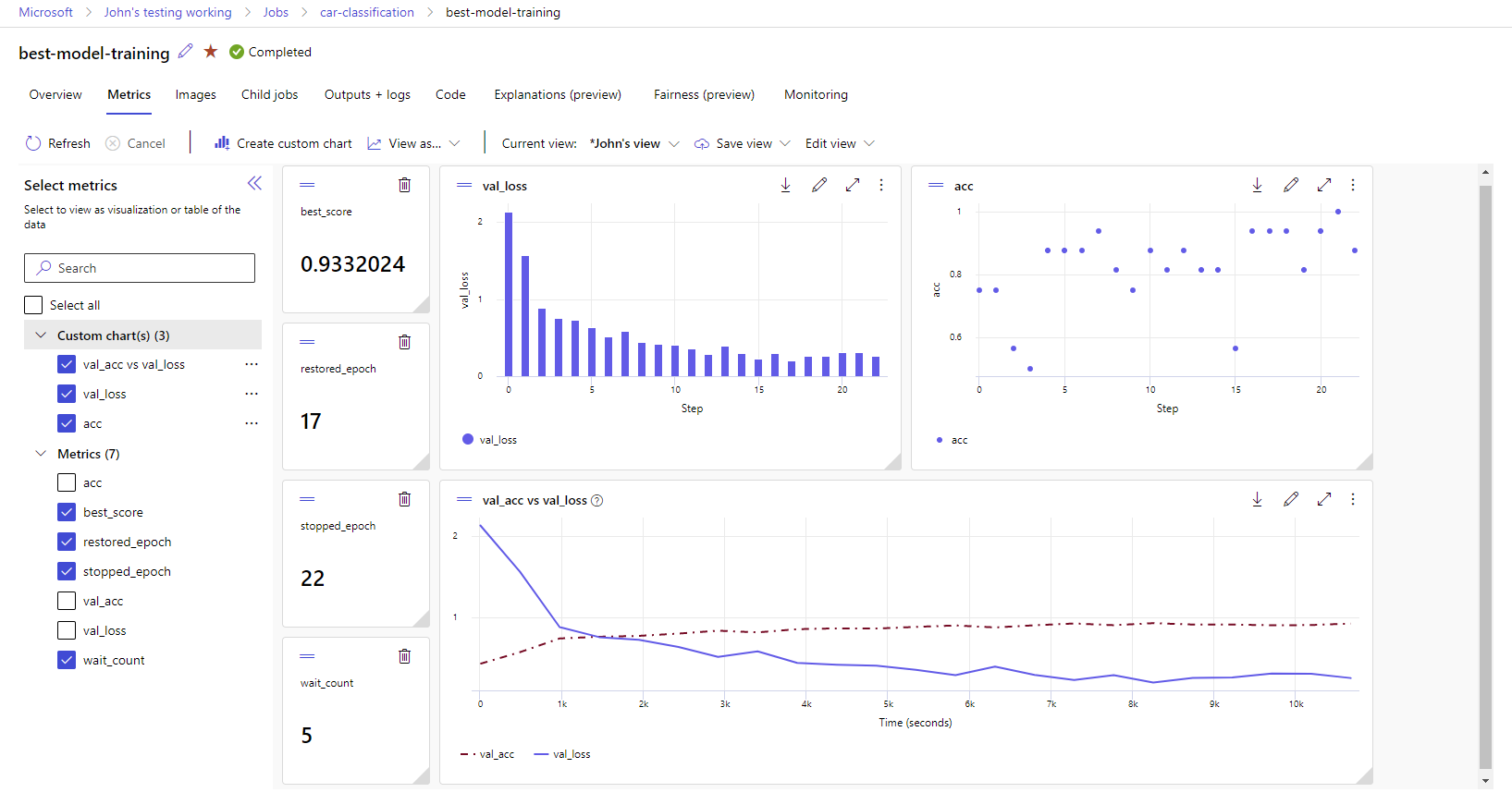
Visualize métricas e artefatos em seu espaço de trabalho
As métricas e artefatos do log MLflow são rastreados em seu espaço de trabalho. Você pode visualizá-los e acessá-los no estúdio a qualquer momento ou acessá-los programaticamente através do SDK MLflow.
Para visualizar métricas e artefatos no estúdio:
Vá para o estúdio do Azure Machine Learning.
Navegue até o seu espaço de trabalho.
Encontre a experiência pelo nome na sua área de trabalho.
Selecione as métricas registradas para renderizar gráficos no lado direito. Você pode personalizar os gráficos aplicando suavização, alterando a cor ou plotando várias métricas em um único gráfico. Você também pode redimensionar e reorganizar o layout como desejar.
Depois de criar a visualização desejada, salve-a para uso futuro e compartilhe-a com seus colegas de equipe, usando um link direto.

Para acessar ou consultar métricas, parâmetros e artefatos programaticamente por meio do SDK MLflow, use mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Gorjeta
Para métricas, o código de exemplo anterior retornará apenas o último valor de uma determinada métrica. Se você quiser recuperar todos os valores de uma determinada métrica, use o mlflow.get_metric_history método. Para obter mais informações sobre como recuperar valores de uma métrica, consulte Obtendo parâmetros e métricas de uma execução.
Para baixar artefatos registrados, como arquivos e modelos, use mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Para obter mais informações sobre como recuperar ou comparar informações de experimentos e execuções no Aprendizado de Máquina do Azure, usando MLflow, consulte Consultar & comparar experimentos e execuções com MLflow.