Exemplo de pipelines e conjuntos de dados para o estruturador do Azure Machine Learning
Use os exemplos internos no designer do Azure Machine Learning para começar rapidamente a criar seus próprios pipelines de aprendizado de máquina. O repositório GitHub do designer do Azure Machine Learning contém documentação detalhada para ajudá-lo a entender alguns cenários comuns de aprendizado de máquina.
Pré-requisitos
- Uma subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta gratuita
- Uma área de trabalho do Azure Machine Learning
Importante
Se você não vir elementos gráficos mencionados neste documento, como botões no estúdio ou designer, talvez não tenha o nível correto de permissões para o espaço de trabalho. Entre em contato com o administrador da assinatura do Azure para verificar se você recebeu o nível correto de acesso. Para obter mais informações, veja Gerir utilizadores e funções.
Usar pipelines de amostra
O designer salva uma cópia dos pipelines de exemplo no espaço de trabalho do estúdio. Você pode editar o pipeline para adaptá-lo às suas necessidades e salvá-lo como seu. Use-os como ponto de partida para iniciar seus projetos.
Veja como usar um exemplo de designer:
Entre no ml.azure.com e selecione o espaço de trabalho com o qual deseja trabalhar.
Selecione Designer.
Selecione um pipeline de exemplo na seção Novo pipeline .
Selecione Mostrar mais amostras para obter uma lista completa de amostras.
Para executar um pipeline, primeiro você precisa definir o destino de computação padrão para executar o pipeline.
No painel Configurações à direita da tela, selecione Selecionar destino de computação.
Na caixa de diálogo exibida, selecione um destino de computação existente ou crie um novo. Selecione Guardar.
Selecione Enviar na parte superior da tela para enviar um trabalho de pipeline.
Dependendo do pipeline de amostra e das configurações de computação, os trabalhos podem levar algum tempo para serem concluídos. As configurações de computação padrão têm um tamanho mínimo de nó de 0, o que significa que o designer deve alocar recursos depois de ficar ocioso. Trabalhos de pipeline repetidos levarão menos tempo, uma vez que os recursos de computação já estão alocados. Além disso, o designer usa resultados armazenados em cache para cada componente para melhorar ainda mais a eficiência.
Depois que o pipeline terminar de ser executado, você poderá revisá-lo e visualizar a saída de cada componente para saber mais. Use as seguintes etapas para exibir as saídas dos componentes:
- Clique com o botão direito do mouse no componente na tela cuja saída você gostaria de ver.
- Selecione Visualizar.
Use os exemplos como pontos de partida para alguns dos cenários de aprendizado de máquina mais comuns.
Regressão
Explore esses exemplos de regressão internos.
| Título de exemplo | Description |
|---|---|
| Regressão - Previsão de preços do automóvel (básico) | Preveja os preços dos carros usando regressão linear. |
| Regressão - Previsão do preço do automóvel (avançado) | Preveja os preços dos carros usando a floresta de decisão e impulsione os regressores da árvore de decisão. Compare modelos para encontrar o melhor algoritmo. |
Classificação
Explore estes exemplos de classificação incorporados. Você pode saber mais sobre os exemplos abrindo os exemplos e exibindo os comentários do componente no designer.
| Título de exemplo | Description |
|---|---|
| Classificação binária com seleção de recursos - Previsão de renda | Preveja a renda como alta ou baixa, usando uma árvore de decisão impulsionada por duas classes. Use a correlação de Pearson para selecionar recursos. |
| Classificação binária com script Python personalizado - Previsão de Risco de Crédito | Classifique os pedidos de crédito como de alto ou baixo risco. Use o componente Execute Python Script para ponderar seus dados. |
| Classificação Binária - Previsão de Relacionamento com o Cliente | Preveja a rotatividade de clientes usando árvores de decisão impulsionadas por duas classes. Use o SMOTE para obter amostras de dados tendenciosos. |
| Classificação de Texto – Wikipédia SP 500 Dataset | Classifique tipos de empresas a partir de artigos da Wikipédia com regressão logística multiclasse. |
| Classificação Multiclasse - Reconhecimento de Cartas | Crie um conjunto de classificadores binários para classificar letras escritas. |
Imagem digitalizada
Explore estas amostras de visão computacional integradas. Você pode saber mais sobre os exemplos abrindo os exemplos e exibindo os comentários do componente no designer.
| Título de exemplo | Description |
|---|---|
| Classificação de imagem usando DenseNet | Use componentes de visão computacional para construir um modelo de classificação de imagem baseado no PyTorch DenseNet. |
Recomendador
Explore estes exemplos de recomendações incorporadas. Você pode saber mais sobre os exemplos abrindo os exemplos e exibindo os comentários do componente no designer.
| Título de exemplo | Description |
|---|---|
| Recomendação ampla e profunda - Previsão de classificação de restaurantes | Crie um mecanismo de recomendação de restaurantes a partir de recursos e classificações de restaurantes/usuários. |
| Recomendação - Tweets de classificação de filmes | Crie um mecanismo de recomendação de filmes a partir de recursos e classificações de filmes/usuários. |
Utilitário
Saiba mais sobre os exemplos que demonstram utilitários e recursos de aprendizado de máquina. Você pode saber mais sobre os exemplos abrindo os exemplos e exibindo os comentários do componente no designer.
| Título de exemplo | Description |
|---|---|
| Classificação binária usando Vowpal Wabbit Model - Adult Income Prediction | Vowpal Wabbit é um sistema de aprendizado de máquina que empurra a fronteira do aprendizado de máquina com técnicas como online, hashing, allreduce, reductions, learning2search, ative e interactive learning. Este exemplo mostra como usar o modelo Vowpal Wabbit para criar um modelo de classificação binária. |
| Usar script R personalizado - Previsão de atraso de voo | Use o script R personalizado para prever se um voo programado de passageiros sofrerá um atraso superior a 15 minutos. |
| Validação cruzada para classificação binária - Previsão de renda de adulto | Use a validação cruzada para construir um classificador binário para a renda de adultos. |
| Importância da funcionalidade de permutação | Use a importância do recurso de permutação para calcular as pontuações de importância para o conjunto de dados de teste. |
| Ajustar parâmetros para classificação binária - Previsão de renda adulta | Use Tune Model Hyperparameters para encontrar hiperparâmetros ideais para criar um classificador binário. |
Conjuntos de Dados
Quando você cria um novo pipeline no designer do Azure Machine Learning, vários conjuntos de dados de exemplo são incluídos por padrão. Esses conjuntos de dados de exemplo são usados pelos pipelines de exemplo na página inicial do designer.
Os conjuntos de dados de exemplo estão disponíveis na categoria Amostras de conjuntos-de dados. Você pode encontrar isso na paleta de componentes à esquerda da tela no designer. Você pode usar qualquer um desses conjuntos de dados em seu próprio pipeline arrastando-o para a tela.
| Nome do conjunto de dados | Descrição do conjunto de dados |
|---|---|
| Conjunto de dados da Classificação Binária de Renda do Censo Adulto | Um subconjunto da base de dados do Censo de 1994, utilizando adultos trabalhadores com mais de 16 anos com um índice de rendimento ajustado de > 100. Uso: classifique as pessoas usando dados demográficos para prever se uma pessoa ganha mais de 50 mil por ano. Investigação relacionada: Kohavi, R., Becker, B., (1996). Repositório UCI Machine Learning. Irvine, CA: Universidade da Califórnia, Escola de Informação e Ciência da Computação |
| Dados sobre os preços dos automóveis (Raw) | Informações sobre automóveis por marca e modelo, incluindo o preço, características como o número de cilindros e MPG, bem como uma pontuação de risco de seguro. A pontuação de risco está inicialmente associada ao preço do automóvel. Em seguida, é ajustado para ter em conta o risco real num processo conhecido pelos atuários como símbolo. Um valor de +3 indica que o automóvel é arriscado e um valor de -3 que é provavelmente seguro. Uso: Prever a pontuação de risco por características, usando regressão ou classificação multivariada. Investigação relacionada: Schlimmer, J.C. (1987). Repositório UCI Machine Learning. Irvine, CA: Universidade da Califórnia, Escola de Informação e Ciência da Computação. |
| Rótulos de apetência do CRM compartilhados | Rótulos do desafio de previsão de relacionamento com o cliente da Copa KDD 2009 (orange_small_train_appetency.labels). |
| Etiquetas de Churn do CRM compartilhadas | Rótulos do desafio de previsão de relacionamento com o cliente da KDD Cup 2009 (orange_small_train_churn.labels). |
| Conjunto de dados do CRM compartilhado | Estes dados são provenientes do desafio de previsão de relacionamento com o cliente KDD Cup 2009 (orange_small_train.data.zip). O conjunto de dados contém 50 mil clientes da empresa francesa de telecomunicações Orange. Cada cliente tem 230 recursos anonimizados, sendo 190 numéricos e 40 categóricos. As características são muito escassas. |
| CRM Upselling Rótulos Compartilhados | Rótulos do desafio de previsão de relacionamento com o cliente KDD Cup 2009 (orange_large_train_upselling.labels |
| Dados de atrasos de voos | Dados de desempenho pontual de voos de passageiros retirados da recolha de dados TranStats do Departamento de Transportes dos EUA (On-Time). O conjunto de dados abrange o período de abril a outubro de 2013. Antes de ser carregado para o designer, o conjunto de dados foi processado da seguinte forma: - O conjunto de dados foi filtrado para cobrir apenas os 70 aeroportos mais movimentados do continente dos EUA - Voos cancelados foram rotulados como atrasados por mais de 15 minutos - Voos desviados foram filtrados - Foram selecionadas as seguintes colunas: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Conjunto de dados UCI de cartão de crédito alemão | O conjunto de dados UCI Statlog (German Credit Card) (Statlog+German+Credit+Data), usando o arquivo german.data. O conjunto de dados classifica as pessoas, descritas por um conjunto de atributos, como de baixo ou alto risco de crédito. Cada exemplo representa uma pessoa. Existem 20 características, numéricas e categóricas, e um rótulo binário (o valor do risco de crédito). As entradas de alto risco de crédito têm rótulo = 2, as entradas de baixo risco de crédito têm rótulo = 1. O custo de classificar incorretamente um exemplo de baixo risco como alto é 1, enquanto o custo de classificar incorretamente um exemplo de alto risco como baixo é 5. |
| Títulos de filmes IMDB | O conjunto de dados contém informações sobre filmes que foram classificados em tweets do Twitter: ID do filme IMDB, nome do filme, gênero e ano de produção. Há 17 mil filmes no conjunto de dados. O conjunto de dados foi introduzido no artigo "S. Dooms, T. De Pessemier e L. Martens. MovieTweetings: um conjunto de dados de classificação de filmes coletados do Twitter. Workshop sobre Crowdsourcing e Computação Humana para Sistemas de Recomendação, CrowdRec na RecSys 2013." |
| Classificações de filmes | O conjunto de dados é uma versão estendida do conjunto de dados Movie Tweetings. O conjunto de dados tem 170 mil classificações para filmes, extraídas de tweets bem estruturados no Twitter. Cada instância representa um tweet e é uma tupla: ID de usuário, ID de filme IMDB, classificação, carimbo de data/hora, número de favoritos para este tweet e número de retweets deste tweet. O conjunto de dados foi disponibilizado por A. Said, S. Dooms, B. Loni e D. Tikk para o Recommender Systems Challenge 2014. |
| Conjunto de dados meteorológicos | Observações meteorológicas terrestres horárias da NOAA (dados mesclados de 201304 a 201310). Os dados meteorológicos abrangem observações feitas a partir de estações meteorológicas de aeroportos, cobrindo o período de abril a outubro de 2013. Antes de ser carregado para o designer, o conjunto de dados foi processado da seguinte forma: - Os IDs das estações meteorológicas foram mapeados para os IDs dos aeroportos correspondentes - As estações meteorológicas não associadas aos 70 aeroportos mais movimentados foram filtradas - A coluna Data foi dividida em colunas separadas Ano, Mês e Dia - Foram selecionadas as seguintes colunas: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Conjunto de dados Wikipedia SP 500 | Os dados são derivados da Wikipédia (https://www.wikipedia.org/) com base em artigos de cada empresa S&P 500, armazenados como dados XML. Antes de ser carregado para o designer, o conjunto de dados foi processado da seguinte forma: - Extrair conteúdo de texto para cada empresa específica - Remover formatação wiki - Remover caracteres não alfanuméricos - Converter todo o texto em minúsculas - Foram adicionadas categorias de empresas conhecidas Note-se que para algumas empresas não foi possível encontrar um artigo, pelo que o número de registos é inferior a 500. |
| Dados de recursos do restaurante | Um conjunto de metadados sobre restaurantes e suas características, como tipo de comida, estilo de jantar e localização. Uso: use este conjunto de dados, em combinação com os outros dois conjuntos de dados de restaurantes, para treinar e testar um sistema de recomendação. Investigação relacionada: Bache, K. e Lichman, M. (2013). Repositório UCI Machine Learning. Irvine, CA: Universidade da Califórnia, Escola de Informação e Ciência da Computação. |
| Classificações de restaurantes | Contém classificações dadas pelos utilizadores aos restaurantes numa escala de 0 a 2. Uso: use este conjunto de dados, em combinação com os outros dois conjuntos de dados de restaurantes, para treinar e testar um sistema de recomendação. Investigação relacionada: Bache, K. e Lichman, M. (2013). Repositório UCI Machine Learning. Irvine, CA: Universidade da Califórnia, Escola de Informação e Ciência da Computação. |
| Dados do cliente do restaurante | Um conjunto de metadados sobre clientes, incluindo dados demográficos e preferências. Uso: use este conjunto de dados, em combinação com os outros dois conjuntos de dados de restaurantes, para treinar e testar um sistema de recomendação. Investigação relacionada: Bache, K. e Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: Universidade da Califórnia, Escola de Informação e Ciência da Computação. |
Clean up resources (Limpar recursos)
Importante
Você pode usar os recursos criados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Excluir tudo
Se você não planeja usar nada do que criou, exclua todo o grupo de recursos para não incorrer em cobranças.
No portal do Azure, selecione Grupos de recursos no lado esquerdo da janela.
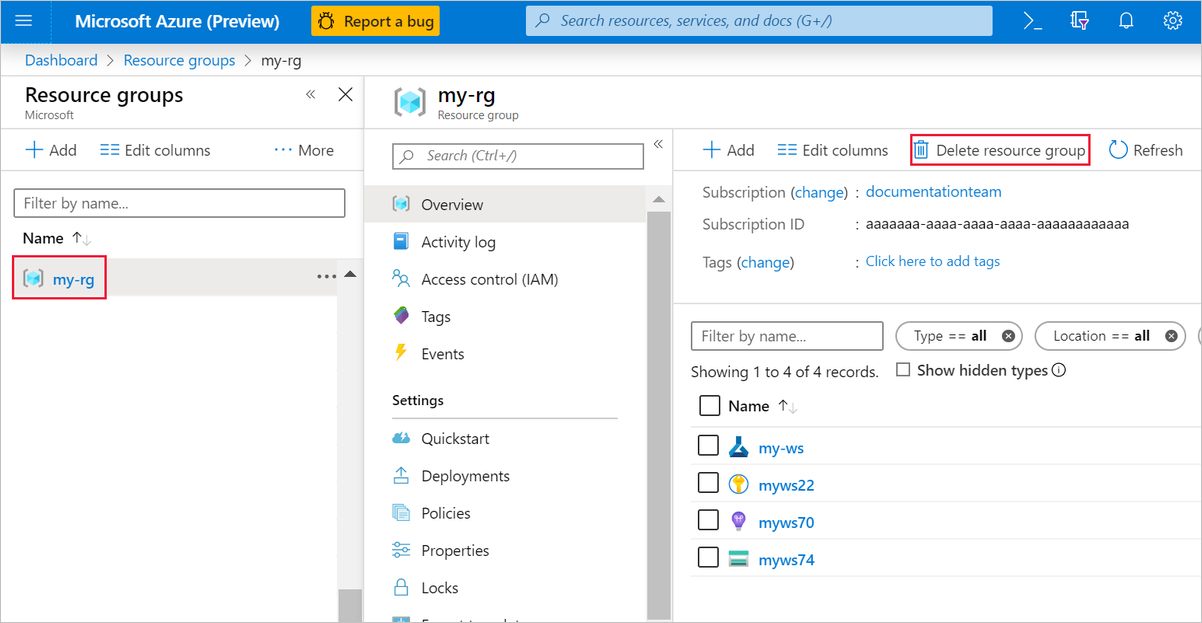
Na lista, selecione o grupo de recursos que você criou.
Selecione Eliminar grupo de recursos.
A exclusão do grupo de recursos também exclui todos os recursos criados no designer.
Excluir ativos individuais
No designer onde você criou seu experimento, exclua ativos individuais selecionando-os e, em seguida, selecionando o botão Excluir .
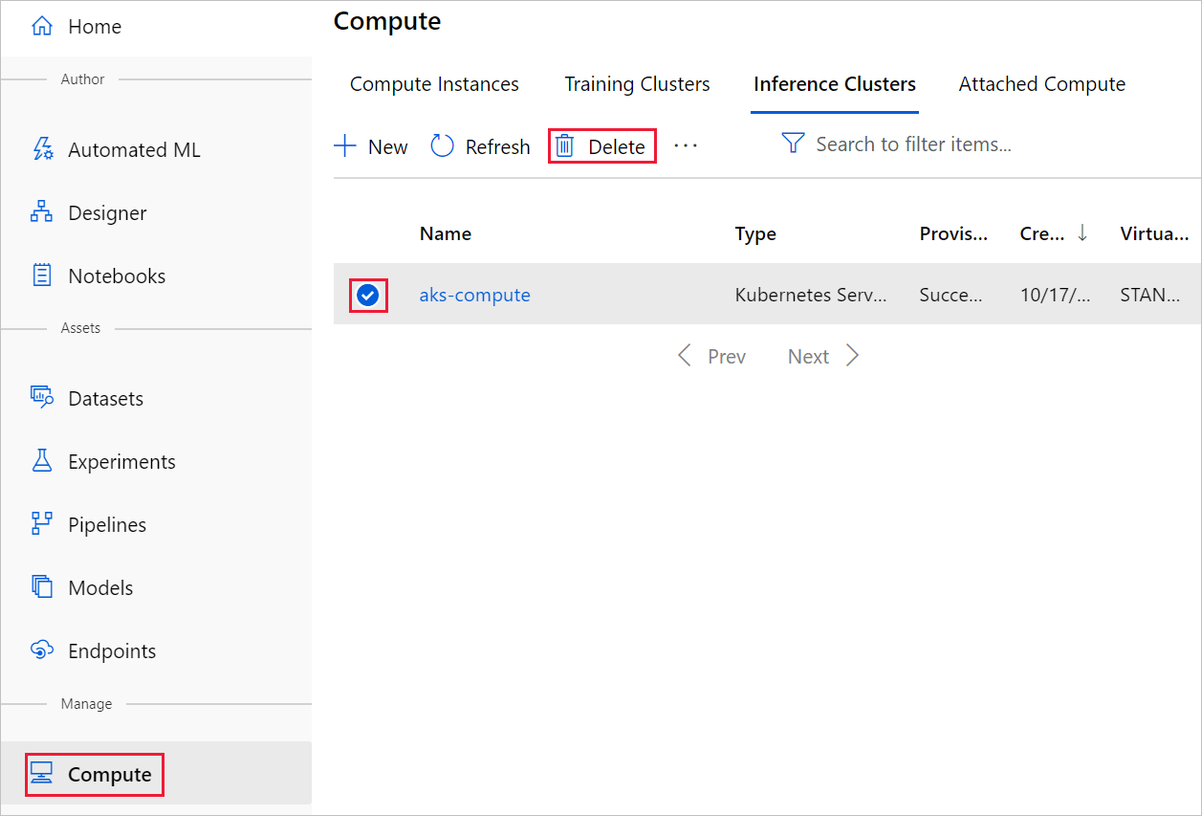
O destino de computação que você criou aqui é automaticamente dimensionado para zero nós quando não está sendo usado. Esta ação é tomada para minimizar as cobranças. Se você quiser excluir o destino de computação, execute estas etapas:
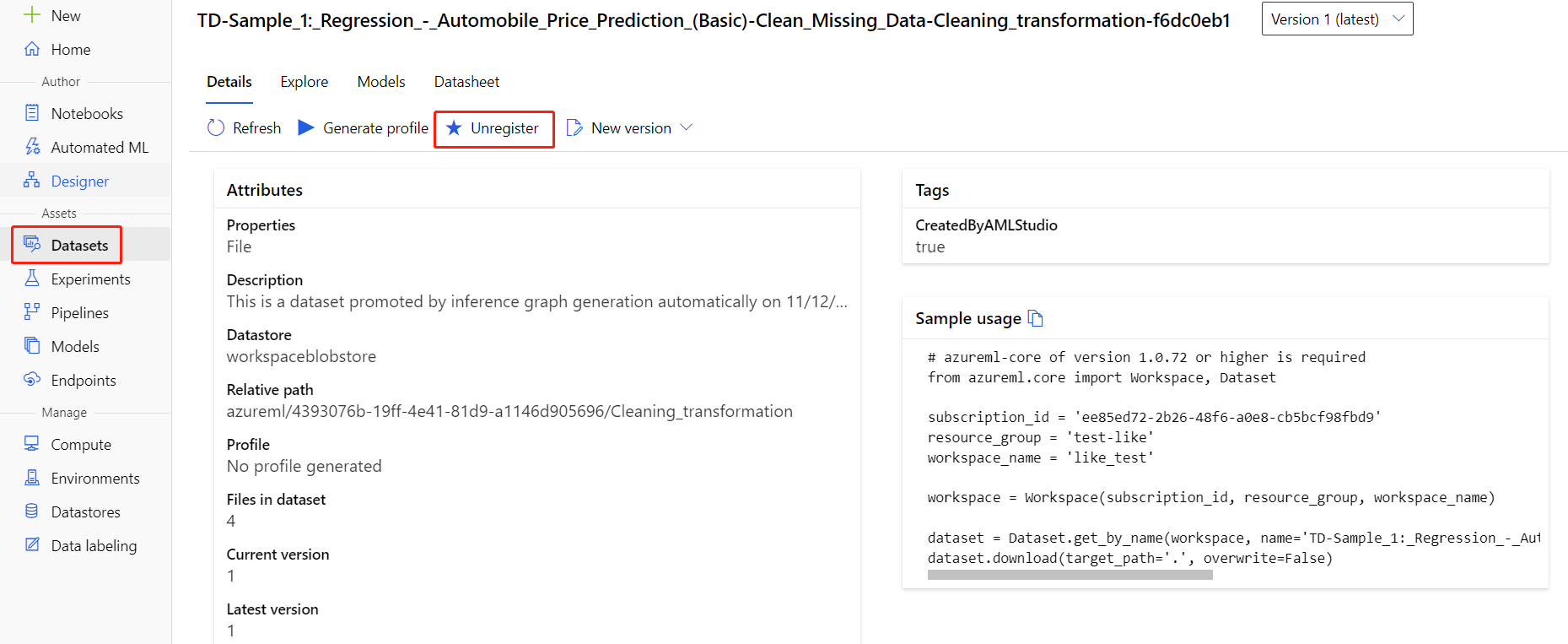
Você pode cancelar o registro de conjuntos de dados do seu espaço de trabalho selecionando cada conjunto de dados e selecionando Cancelar registro.
Para excluir um conjunto de dados, vá para a conta de armazenamento usando o portal do Azure ou o Gerenciador de Armazenamento do Azure e exclua manualmente esses ativos.
Próximos passos
Aprenda os fundamentos da análise preditiva e do aprendizado de máquina com o Tutorial: Preveja o preço do automóvel com o designer