Ajuste o desempenho e mantenha bancos de dados no Banco de Dados do Azure para MySQL - Servidor Flexível usando o sys_schema
APLICA-SE A: Banco de Dados do Azure para MySQL - Servidor Único Banco de Dados do Azure para MySQL - Servidor Flexível
Banco de Dados do Azure para MySQL - Servidor Único Banco de Dados do Azure para MySQL - Servidor Flexível
Importante
O servidor único do Banco de Dados do Azure para MySQL está no caminho de desativação. É altamente recomendável que você atualize para o Banco de Dados do Azure para o servidor flexível MySQL. Para obter mais informações sobre como migrar para o Banco de Dados do Azure para servidor flexível MySQL, consulte O que está acontecendo com o Banco de Dados do Azure para Servidor Único MySQL?
O performance_schema MySQL, disponível pela primeira vez no MySQL 5.5, fornece instrumentação para muitos recursos vitais do servidor, como alocação de memória, programas armazenados, bloqueio de metadados, etc. No entanto, o performance_schema contém mais de 80 tabelas, e obter as informações necessárias muitas vezes requer a junção de tabelas dentro do performance_schema e tabelas do information_schema. Com base em performance_schema e information_schema, o sys_schema fornece uma poderosa coleção de exibições amigáveis em um banco de dados somente leitura e está totalmente habilitado no Banco de Dados do Azure para servidor flexível MySQL versão 5.7.
Há 52 modos de exibição no sys_schema e cada modo de exibição tem um dos seguintes prefixos:
- Host_summary ou E/S: latências relacionadas a E/S.
- InnoDB: Status e bloqueios do buffer InnoDB.
- Memória: Uso de memória pelo host e usuários.
- Esquema: Informações relacionadas ao esquema, como incremento automático, índices, etc.
- Instrução: Informações sobre instruções SQL; Pode ser uma instrução que resultou em uma verificação completa da tabela ou um longo tempo de consulta.
- Usuário: Recursos consumidos e agrupados pelos usuários. Exemplos são E/S de arquivos, conexões e memória.
- Esperar: Aguarde eventos agrupados por host ou usuário.
Agora vamos ver alguns padrões de uso comuns do sys_schema. Para começar, agruparemos os padrões de uso em duas categorias: Ajuste de desempenho e Manutenção de banco de dados.
Afinação de Desempenho
sys.user_summary_by_file_io
IO é a operação mais cara no banco de dados. Podemos descobrir a latência média de E/S consultando a visualização sys.user_summary_by_file_io . Com os 125 GB de armazenamento provisionado padrão, minha latência de E/S é de cerca de 15 segundos.
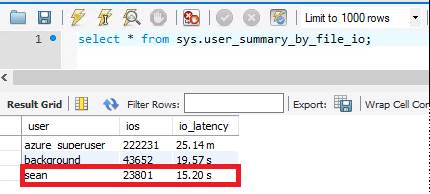
Como o servidor flexível do Banco de Dados do Azure para MySQL dimensiona a E/S em relação ao armazenamento, depois de aumentar meu armazenamento provisionado para 1 TB, minha latência de E/S reduz para 571 ms.

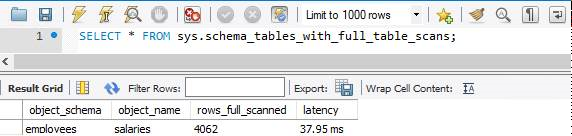
sys.schema_tables_with_full_table_scans
Apesar do planejamento cuidadoso, muitas consultas ainda podem resultar em verificações completas da tabela. Para obter mais informações sobre os tipos de índices e como otimizá-los, consulte este artigo: Como solucionar problemas de desempenho de consulta. As verificações completas de tabelas consomem muitos recursos e degradam o desempenho do banco de dados. A maneira mais rápida de encontrar tabelas com verificação de tabela completa é consultar a visualização sys.schema_tables_with_full_table_scans .
sys.user_summary_by_statement_type
Para solucionar problemas de desempenho do banco de dados, pode ser benéfico identificar os eventos que acontecem dentro do seu banco de dados, e usar a visualização sys.user_summary_by_statement_type pode fazer o truque.
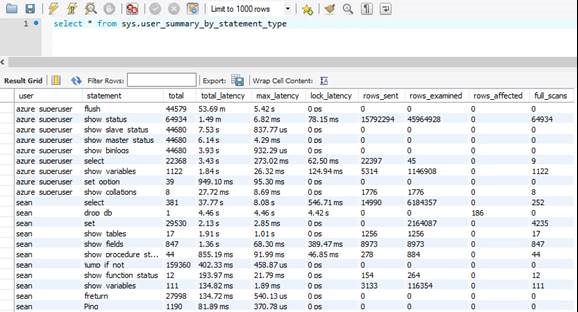
Neste exemplo, o Banco de Dados do Azure para servidor flexível MySQL gastou 53 minutos liberando o log de consulta lenta 44579 vezes. Isso é muito tempo e muitos IOs. Você pode reduzir essa atividade desativando seu log de consulta lenta ou diminuindo a frequência de logon de consulta lenta no portal do Azure.
Manutenção da base de dados
sys.innodb_buffer_stats_by_table
[! IMPORTANTE]
Consultar essa exibição pode afetar o desempenho. Recomenda-se executar essa solução de problemas fora do horário comercial de pico.
O pool de buffers InnoDB reside na memória e é o principal mecanismo de cache entre o DBMS e o armazenamento. O tamanho do buffer pool InnoDB está vinculado à camada de desempenho e não pode ser alterado, a menos que uma SKU de produto diferente seja escolhida. Tal como acontece com a memória no seu sistema operativo, as páginas antigas são trocadas para criar espaço para dados mais recentes. Para descobrir quais tabelas consomem a maior parte da memória do pool de buffers InnoDB, você pode consultar a visualização sys.innodb_buffer_stats_by_table .
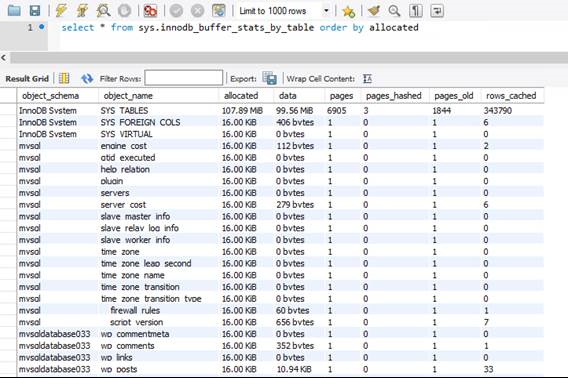
No gráfico acima, é evidente que, além das tabelas e visualizações do sistema, cada tabela no banco de dados mysqldatabase033, que hospeda um dos meus sites WordPress, ocupa 16 KB, ou 1 página, de dados na memória.
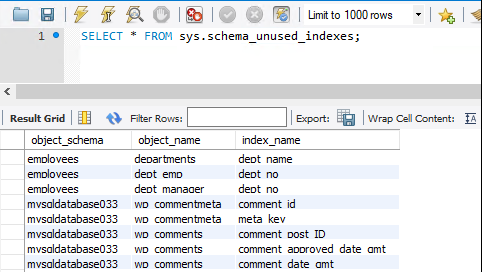
Sys.schema_unused_indexes & sys.schema_redundant_indexes
Os índices são ótimas ferramentas para melhorar o desempenho de leitura, mas incorrem em custos adicionais para inserções e armazenamento. Sys.schema_unused_indexes e sys.schema_redundant_indexes fornecem informações sobre índices não utilizados ou duplicados.

Conclusão
Em resumo, o sys_schema é uma ótima ferramenta para ajuste de desempenho e manutenção do banco de dados. Certifique-se de aproveitar esse recurso em sua instância de servidor flexível do Banco de Dados do Azure para MySQL.
Próximos passos
- Para encontrar respostas de colegas para suas perguntas mais preocupadas ou postar uma nova pergunta/resposta, visite Stack Overflow.