Réplicas e instâncias
Este artigo fornece uma descrição geral do ciclo de vida das réplicas de serviços com monitorização de estado e instâncias de serviços sem estado.
Instâncias de serviços sem estado
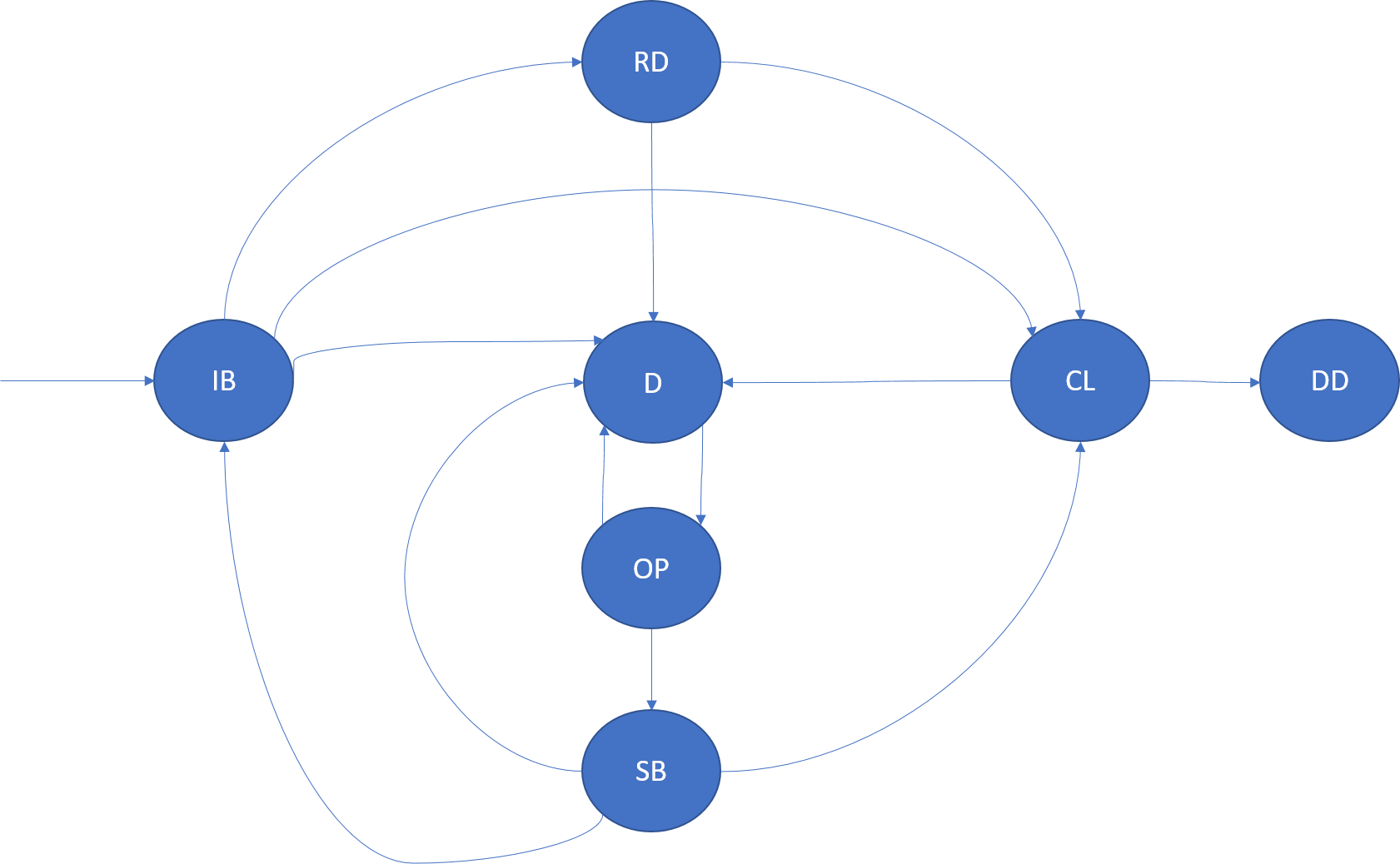
Uma instância de um serviço sem estado é uma cópia da lógica de serviço que é executada num dos nós do cluster. Uma instância numa partição é identificada exclusivamente pelo respetivo InstanceId. O ciclo de vida de uma instância é modelado no seguinte diagrama:
InBuild (IB)
Depois de o cluster Resource Manager determinar uma colocação para a instância, entra neste estado de ciclo de vida. A instância é iniciada no nó. O anfitrião da aplicação é iniciado, a instância é criada e, em seguida, aberta. Após a conclusão do arranque, a instância transita para o estado pronto.
Se o anfitrião da aplicação ou o nó desta instância falhar, transitará para o estado removido.
Pronto (RD)
No estado pronto, a instância está em execução no nó. Se esta instância for um serviço fiável, o RunAsync foi invocado.
Se o anfitrião da aplicação ou o nó desta instância falhar, transitará para o estado removido.
Fechar (CL)
No estado de fecho, o Azure Service Fabric está em processo de encerrar a instância neste nó. Este encerramento pode dever-se a vários motivos, por exemplo, uma atualização da aplicação, um balanceamento de carga ou o serviço a ser eliminado. Após a conclusão do encerramento, passa para o estado removido.
Removido (DD)
No estado removido, a instância já não está em execução no nó. Neste momento, o Service Fabric mantém os metadados sobre esta instância, que é eventualmente também eliminada.
Nota
É possível efetuar a transição de qualquer estado para o estado removido com a opção ForceRemove em Remove-ServiceFabricReplica.
Réplicas de serviços com estado
Uma réplica de um serviço com monitorização de estado é uma cópia da lógica de serviço em execução num dos nós do cluster. Além disso, a réplica mantém uma cópia do estado desse serviço. Dois conceitos relacionados descrevem o ciclo de vida e o comportamento das réplicas com estado:
- Ciclo de vida da réplica
- Função de réplica
O debate seguinte descreve os serviços com monitorização de estado persistentes. Para serviços com estado voláteis (ou dentro da memória), os estados inativos e removidos são equivalentes.
InBuild (IB)
Uma réplica inBuild é uma réplica criada ou preparada para associar o conjunto de réplicas. Dependendo da função de réplica, o IB tem semântica diferente.
Se o anfitrião da aplicação ou o nó de uma réplica InBuild falhar, transitará para o estado inativo.
Réplicas inBuild primárias: InBuild Primário são as primeiras réplicas de uma partição. Normalmente, esta réplica ocorre quando a partição está a ser criada. As réplicas inBuild primárias também surgem quando todas as réplicas de uma partição são reiniciadas ou removidas.
Réplicas InBuild idleSecondary: estas são novas réplicas criadas pelo cluster Resource Manager ou réplicas existentes que ficaram inativas e precisam de ser adicionadas novamente ao conjunto. Estas réplicas são propagadas ou criadas pela primária antes de poderem associar o conjunto de réplicas como ActiveSecondary e participar no reconhecimento de quórum das operações.
Réplicas do ActiveSecondary InBuild: este estado é observado em algumas consultas. É uma otimização em que o conjunto de réplicas não está a ser alterado, mas tem de ser criada uma réplica. A réplica em si segue as transições normais da máquina de estado (conforme descrito na secção sobre funções de réplica).
Pronto (RD)
Uma réplica Pronta é uma réplica que está a participar na replicação e na confirmação de quórum das operações. O estado pronto é aplicável às réplicas secundárias primárias e ativas.
Se o anfitrião da aplicação ou o nó de uma réplica pronta falhar, transitará para o estado de inatividade.
Fechar (CL)
Uma réplica entra no estado de fecho nos seguintes cenários:
Encerrar o código da réplica: o Service Fabric poderá ter de encerrar o código em execução de uma réplica. Este encerramento pode ser por vários motivos. Por exemplo, pode ocorrer devido a uma atualização da aplicação, dos recursos de infraestrutura ou da infraestrutura ou devido a uma falha reportada pela réplica. Quando a réplica fechar, a réplica transita para o estado de inatividade. O estado persistente associado a esta réplica armazenada no disco não é limpo.
Remover a réplica do cluster: o Service Fabric poderá ter de remover o estado persistente e encerrar o código em execução de uma réplica. Este encerramento pode ser por vários motivos, por exemplo, balanceamento de carga.
Removido (DD)
No estado removido, a instância já não está em execução no nó. Também não existe nenhum estado no nó. Neste momento, o Service Fabric mantém os metadados sobre esta instância, que é eventualmente também eliminada.
Baixo (D)
No estado inativo, o código de réplica não está em execução, mas o estado persistente dessa réplica existe nesse nó. Uma réplica pode estar inativa por vários motivos, por exemplo, o nó estar inativo, uma falha no código de réplica, uma atualização da aplicação ou falhas de réplica.
Uma réplica inativa é aberta pelo Service Fabric conforme necessário, por exemplo, quando a atualização for concluída no nó.
A função de réplica não é relevante no estado inativo.
Abrir (OP)
Uma réplica inativa entra no estado de abertura quando o Service Fabric precisa de voltar a fazer a cópia de segurança da réplica. Por exemplo, este estado pode ocorrer após a conclusão de uma atualização de código para a aplicação num nó.
Se o anfitrião da aplicação ou o nó de uma réplica de abertura falhar, transitará para o estado de inatividade.
A função de réplica não é relevante no estado de abertura.
StandBy (SB)
Uma réplica standby é uma réplica de um serviço persistente que ficou inativo e foi então aberto. Esta réplica poderá ser utilizada pelo Service Fabric se precisar de adicionar outra réplica ao conjunto de réplicas (porque a réplica já tem alguma parte do estado e o processo de compilação é mais rápido). Após a expiração de StandByReplicaKeepDuration, a réplica de reserva é eliminada.
Se o anfitrião da aplicação ou o nó de uma réplica de reserva falhar, transita para o estado de inatividade.
A função de réplica não é relevante no estado de reserva.
Nota
Qualquer réplica que não esteja inativa ou removida é considerada como estando em cima.
Nota
É possível efetuar a transição de qualquer estado para o estado removido com a opção ForceRemove em Remove-ServiceFabricReplica.
Função de réplica
A função da réplica determina a função no conjunto de réplicas:
- Primário (P): existe um principal no conjunto de réplicas que é responsável por realizar operações de leitura e escrita.
- ActiveSecondary (S): são réplicas que recebem atualizações de estado da primária, aplicam-nas e, em seguida, devolvem confirmações. Existem várias secundárias ativas no conjunto de réplicas. O número destas secundárias ativas determina o número de falhas que o serviço pode processar.
- IdleSecondary (I): estas réplicas estão a ser criadas pela primária. Estão a receber o estado da primária antes de poderem ser promovidos para a secundária ativa.
- Nenhuma (N): estas réplicas não têm uma responsabilidade no conjunto de réplicas.
- Desconhecido (U): esta é a função inicial de uma réplica antes de receber qualquer chamada à API ChangeRole do Service Fabric.
O diagrama seguinte ilustra as transições de função de réplica e alguns cenários de exemplo em que podem ocorrer:
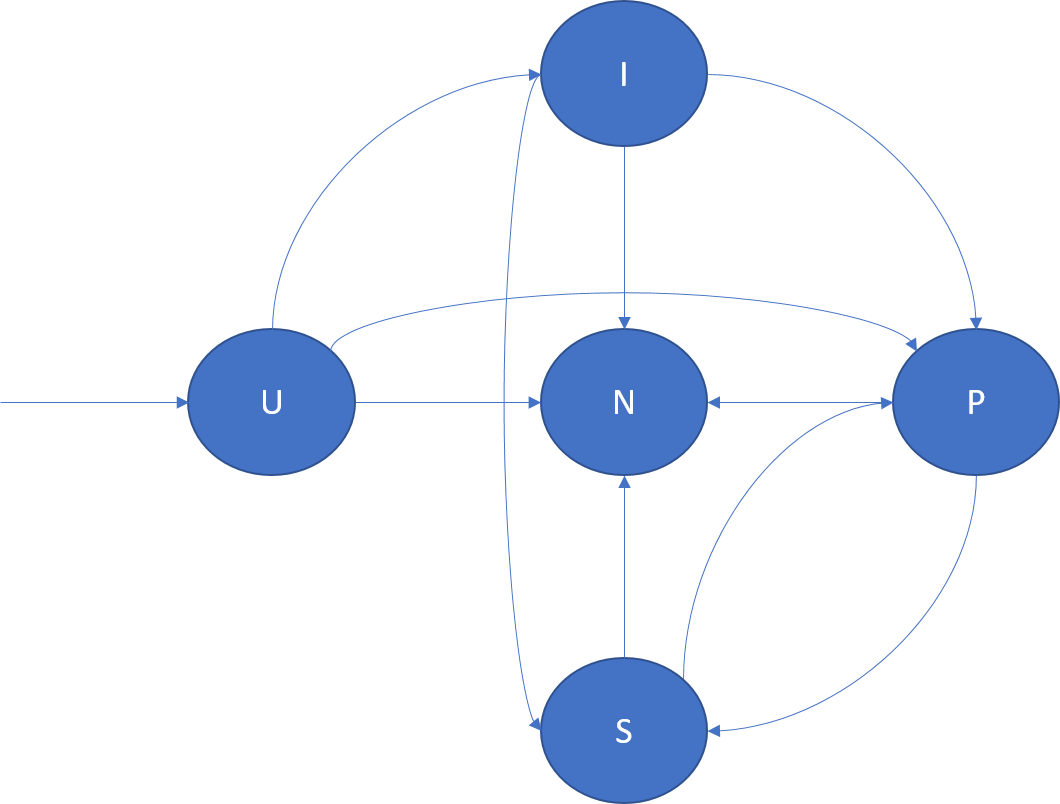
- U -> P: Criação de uma nova réplica primária.
- U –> I: Criação de uma nova réplica inativa.
- U -> N: Eliminação de uma réplica de reserva.
- I -> S: Promoção da secundária inativa para a secundária ativa para que os seus reconhecimentos contribuam para o quórum.
- I -> P: Promoção da secundária inativa para a primária. Isto pode ocorrer em reconfigurações especiais quando o secundário inativo é o candidato correto para ser primário.
- I -> N: Eliminação da réplica secundária inativa.
- S -> P: Promoção da secundária ativa para a primária. Tal pode dever-se à ativação pós-falha do movimento primário ou primário iniciado pelo cluster Resource Manager. Por exemplo, pode ser uma resposta a uma atualização da aplicação ou balanceamento de carga.
- S -> N: Eliminação da réplica secundária ativa.
- P -> S: Despromoção da réplica primária. Tal pode dever-se a um movimento primário iniciado pelo cluster Resource Manager. Por exemplo, pode ser uma resposta a uma atualização da aplicação ou balanceamento de carga.
- P -> N: Eliminação da réplica primária.
Nota
Os modelos de programação de nível superior, como o Reliable Actors e o Reliable Services, ocultam o conceito de funções de réplica do programador. Em Atores, a noção de um papel é desnecessária. Em Serviços, é amplamente simplificado para a maioria dos cenários.
Passos seguintes
Para obter mais informações sobre os conceitos do Service Fabric, veja o seguinte artigo: