Introdução ao Microsoft Spark Utilities
Microsoft Spark Utilities (MSSparkUtils) é um pacote interno para ajudá-lo a executar facilmente tarefas comuns. Você pode usar o MSSparkUtils para trabalhar com sistemas de arquivos, obter variáveis de ambiente, encadear blocos de anotações e trabalhar com segredos. MSSparkUtils estão disponíveis em PySpark (Python), Scala, .NET Spark (C#)e R (Preview) notebooks e pipelines Synapse.
Pré-requisitos
Configurar o acesso ao Azure Data Lake Storage Gen2
Os notebooks Synapse usam o Microsoft Entra pass-through para acessar as contas ADLS Gen2. Você precisa ser um Contribuidor de Dados de Blob de Armazenamento para acessar a conta (ou pasta) do ADLS Gen2.
Os pipelines Synapse usam a Identidade de Serviço Gerenciado (MSI) do espaço de trabalho para acessar as contas de armazenamento. Para usar o MSSparkUtils em suas atividades de pipeline, sua identidade de espaço de trabalho precisa ser o Contribuidor de Dados de Blob de Armazenamento para acessar a conta (ou pasta) do ADLS Gen2.
Siga estas etapas para garantir que sua ID do Microsoft Entra e o MSI do espaço de trabalho tenham acesso à conta ADLS Gen2:
Abra o portal do Azure e a conta de armazenamento que você deseja acessar. Você pode navegar até o contêiner específico que deseja acessar.
Selecione o Controle de acesso (IAM) no painel esquerdo.
Selecione Adicionar>Adicionar atribuição de funções para abrir o painel Adicionar atribuição de funções.
Atribua a seguinte função. Para obter os passos detalhados, veja o artigo Atribuir funções do Azure com o portal do Azure.
Definição Value Função Contribuidor de Dados de Blobs de Armazenamento Atribuir acesso a USER e MANAGEDIDENTITY Membros sua conta Microsoft Entra e sua identidade de espaço de trabalho Nota
O nome da identidade gerenciada também é o nome do espaço de trabalho.
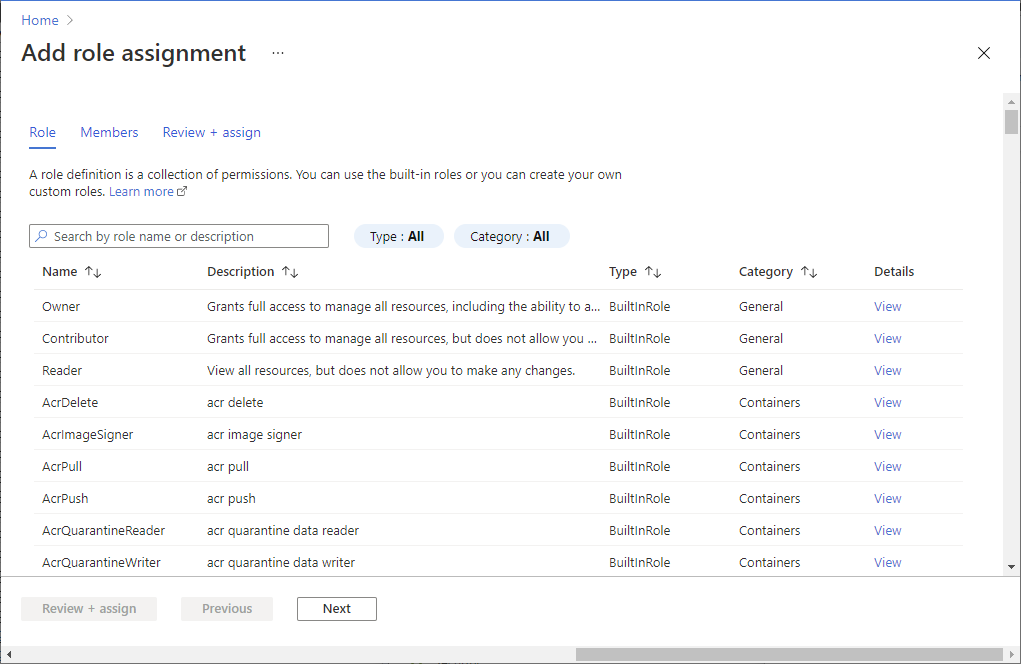
Selecione Guardar.
Você pode acessar dados no ADLS Gen2 com Synapse Spark através do seguinte URL:
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Configurar o acesso ao Armazenamento de Blobs do Azure
O Synapse usa a assinatura de acesso compartilhado (SAS) para acessar o Armazenamento de Blob do Azure. Para evitar a exposição de chaves SAS no código, recomendamos a criação de um novo serviço vinculado no espaço de trabalho Synapse para a conta de Armazenamento de Blob do Azure que você deseja acessar.
Siga estas etapas para adicionar um novo serviço vinculado para uma conta de Armazenamento de Blob do Azure:
- Abra o Azure Synapse Studio.
- Selecione Gerenciar no painel esquerdo e selecione Serviços vinculados em Conexõesexternas.
- Pesquisar Armazenamento de Blob do Azure no painel Novo Serviço vinculado à direita.
- Selecione Continuar.
- Selecione a Conta de Armazenamento de Blob do Azure para acessar e configurar o nome do serviço vinculado. Sugira o uso da chave Account para o método Authentication.
- Selecione Testar conexão para validar se as configurações estão corretas.
- Selecione Criar primeiro e clique em Publicar tudo para salvar as alterações.
Você pode acessar dados no Armazenamento de Blobs do Azure com o Synapse Spark por meio da seguinte URL:
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Aqui está um exemplo de código:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Configurar o acesso ao Cofre da Chave do Azure
Você pode adicionar um Cofre da Chave do Azure como um serviço vinculado para gerenciar suas credenciais no Synapse. Siga estas etapas para adicionar um Cofre de Chaves do Azure como um serviço vinculado Synapse:
Abra o Azure Synapse Studio.
Selecione Gerenciar no painel esquerdo e selecione Serviços vinculados em Conexõesexternas.
Pesquisar Azure Key Vault no painel Novo serviço vinculado à direita.
Selecione a Conta do Cofre da Chave do Azure para acessar e configurar o nome do serviço vinculado.
Selecione Testar conexão para validar se as configurações estão corretas.
Selecione Criar primeiro e clique em Publicar tudo para salvar a alteração.
Os blocos de anotações Synapse usam a passagem do Microsoft Entra para acessar o Azure Key Vault. Os pipelines Synapse usam a identidade do espaço de trabalho (MSI) para acessar o Cofre da Chave do Azure. Para garantir que seu código funcione tanto no bloco de anotações quanto no pipeline do Sinapse, recomendamos conceder permissão de acesso secreto para sua conta do Microsoft Entra e identidade do espaço de trabalho.
Siga estas etapas para conceder acesso secreto à identidade do seu espaço de trabalho:
- Abra o portal do Azure e o Cofre da Chave do Azure que você deseja acessar.
- Selecione as políticas de acesso no painel esquerdo.
- Selecione Adicionar política de acesso:
- Escolha Key, Secret, & Certificate Management como modelo de configuração.
- Selecione sua conta do Microsoft Entra e sua identidade de espaço de trabalho (igual ao nome do espaço de trabalho) na entidade de seleção ou verifique se ela já está atribuída.
- Selecione Selecionar e Adicionar.
- Selecione o botão Salvar para confirmar alterações.
Utilitários do sistema de arquivos
mssparkutils.fs fornece utilitários para trabalhar com vários sistemas de arquivos, incluindo o Azure Data Lake Storage Gen2 (ADLS Gen2) e o Azure Blob Storage. Certifique-se de configurar o acesso ao Azure Data Lake Storage Gen2 e ao Armazenamento de Blobs do Azure adequadamente.
Execute os seguintes comandos para obter uma visão geral dos métodos disponíveis:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
Resultados em:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Listar ficheiros
Listar o conteúdo de um diretório.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Ver propriedades do ficheiro
Retorna as propriedades do arquivo, incluindo nome do arquivo, caminho do arquivo, tamanho do arquivo, tempo de modificação do arquivo e se é um diretório e um arquivo.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Criar novo diretório
Cria o diretório fornecido se ele não existir e quaisquer diretórios pai necessários.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Copiar ficheiro
Copia um arquivo ou diretório. Suporta cópia entre sistemas de arquivos.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
Arquivo de cópia de desempenho
Esse método fornece uma maneira mais rápida de copiar ou mover arquivos, especialmente grandes volumes de dados.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Nota
O método só suporta no Azure Synapse Runtime para Apache Spark 3.3 e Azure Synapse Runtime para Apache Spark 3.4.
Visualizar conteúdo do arquivo
Retorna até os primeiros bytes 'maxBytes' do arquivo fornecido como uma String codificada em UTF-8.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Mover ficheiro
Move um arquivo ou diretório. Suporta movimentação entre sistemas de arquivos.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Gravar arquivo
Grava a cadeia de caracteres fornecida em um arquivo, codificado em UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Acrescentar conteúdo a um ficheiro
Acrescenta a cadeia de caracteres fornecida a um arquivo, codificado em UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Excluir arquivo ou diretório
Remove um arquivo ou um diretório.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Utilitários para notebook
Não suportado.
Você pode usar os Utilitários de Notebook MSSparkUtils para executar um bloco de anotações ou sair de um bloco de anotações com um valor. Execute o seguinte comando para obter uma visão geral dos métodos disponíveis:
mssparkutils.notebook.help()
Obtenha resultados:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Nota
Os utilitários de notebook não são aplicáveis para definições de trabalho do Apache Spark (SJD).
Referenciar um bloco de notas
Faça referência a um bloco de notas e devolve o respetivo valor de saída. Você pode executar chamadas de função de aninhamento em um bloco de anotações interativamente ou em um pipeline. O notebook que está sendo referenciado será executado no pool Spark do qual o notebook chama essa função.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Por exemplo:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
Depois que a execução terminar, você verá um link de instantâneo chamado 'Exibir execução do bloco de anotações: Nome do bloco de anotações' mostrado na saída da célula, você pode clicar no link para ver o instantâneo para essa execução específica.

Referência: executar vários blocos de anotações em paralelo
O método mssparkutils.notebook.runMultiple() permite executar vários blocos de anotações em paralelo ou com uma estrutura topológica predefinida. A API está usando um mecanismo de implementação multithread dentro de uma sessão de faísca, o que significa que os recursos de computação são compartilhados pelas execuções do bloco de anotações de referência.
Com mssparkutils.notebook.runMultiple()o , você pode:
Execute vários notebooks simultaneamente, sem esperar que cada um termine.
Especifique as dependências e a ordem de execução de seus blocos de anotações, usando um formato JSON simples.
Otimize o uso dos recursos de computação do Spark e reduza o custo de seus projetos Synapse.
Visualize os instantâneos de cada registro de execução do bloco de anotações na saída e depure/monitore as tarefas do bloco de anotações convenientemente.
Obtenha o valor de saída de cada atividade executiva e use-o em tarefas a jusante.
Você também pode tentar executar o mssparkutils.notebook.help("runMultiple") para encontrar o exemplo e o uso detalhado.
Aqui está um exemplo simples de execução de uma lista de blocos de anotações em paralelo usando esse método:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
O resultado da execução do bloco de anotações raiz é o seguinte:

Segue-se um exemplo de execução de blocos de notas com estrutura topológica utilizando mssparkutils.notebook.runMultiple(). Use esse método para orquestrar facilmente blocos de anotações por meio de uma experiência de código.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Nota
- O método só suporta no Azure Synapse Runtime para Apache Spark 3.3 e Azure Synapse Runtime para Apache Spark 3.4.
- O grau de paralelismo da execução de vários blocos de anotações é restrito ao recurso de computação total disponível de uma sessão do Spark.
Sair de um bloco de notas
Sai de um bloco de notas com um valor. Você pode executar chamadas de função de aninhamento em um bloco de anotações interativamente ou em um pipeline.
Quando você chama uma função exit() de um bloco de anotações interativamente, o Azure Synapse lança uma exceção, ignora a execução de células de subsequência e mantém a sessão do Spark ativa.
Quando você orquestra um bloco de anotações que chama uma
exit()função em um pipeline Synapse, o Azure Synapse retornará um valor de saída, concluirá a execução do pipeline e interromperá a sessão do Spark.Quando você chama uma
exit()função em um bloco de anotações que está sendo referenciado, o Azure Synapse interrompe a execução adicional no bloco de anotações que está sendo referenciado e continua a executar as próximas células no bloco de anotações que chamam arun()função. Por exemplo: o Bloco de Anotações1 tem três células e chama umaexit()função na segunda célula. O Notebook2 tem cinco células e chamarun(notebook1)na terceira célula. Quando você executa o Notebook2, o Notebook1 será parado na segunda célula ao pressionar aexit()função. O Notebook2 continuará a executar sua quarta célula e quinta célula.
mssparkutils.notebook.exit("value string")
Por exemplo:
O bloco de notas Sample1 localiza-se em pasta/ com as seguintes duas células:
- A célula 1 define um parâmetro de entrada com o valor padrão definido como 10.
- A célula 2 sai do bloco de notas com a entrada como valor de saída.
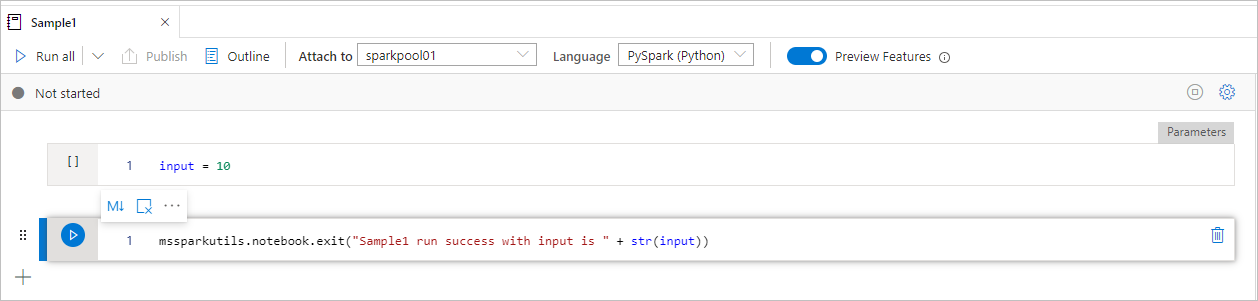
Você pode executar o Sample1 em outro bloco de anotações com valores padrão:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Resultados em:
Sample1 run success with input is 10
Você pode executar o Sample1 em outro bloco de anotações e definir o valor de entrada como 20:
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
Resultados em:
Sample1 run success with input is 20
Você pode usar os Utilitários de Notebook MSSparkUtils para executar um bloco de anotações ou sair de um bloco de anotações com um valor. Execute o seguinte comando para obter uma visão geral dos métodos disponíveis:
mssparkutils.notebook.help()
Obtenha resultados:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Referenciar um bloco de notas
Faça referência a um bloco de notas e devolve o respetivo valor de saída. Você pode executar chamadas de função de aninhamento em um bloco de anotações interativamente ou em um pipeline. O notebook que está sendo referenciado será executado no pool Spark do qual o notebook chama essa função.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Por exemplo:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
Depois que a execução terminar, você verá um link de instantâneo chamado 'Exibir execução do bloco de anotações: Nome do bloco de anotações' mostrado na saída da célula, você pode clicar no link para ver o instantâneo para essa execução específica.
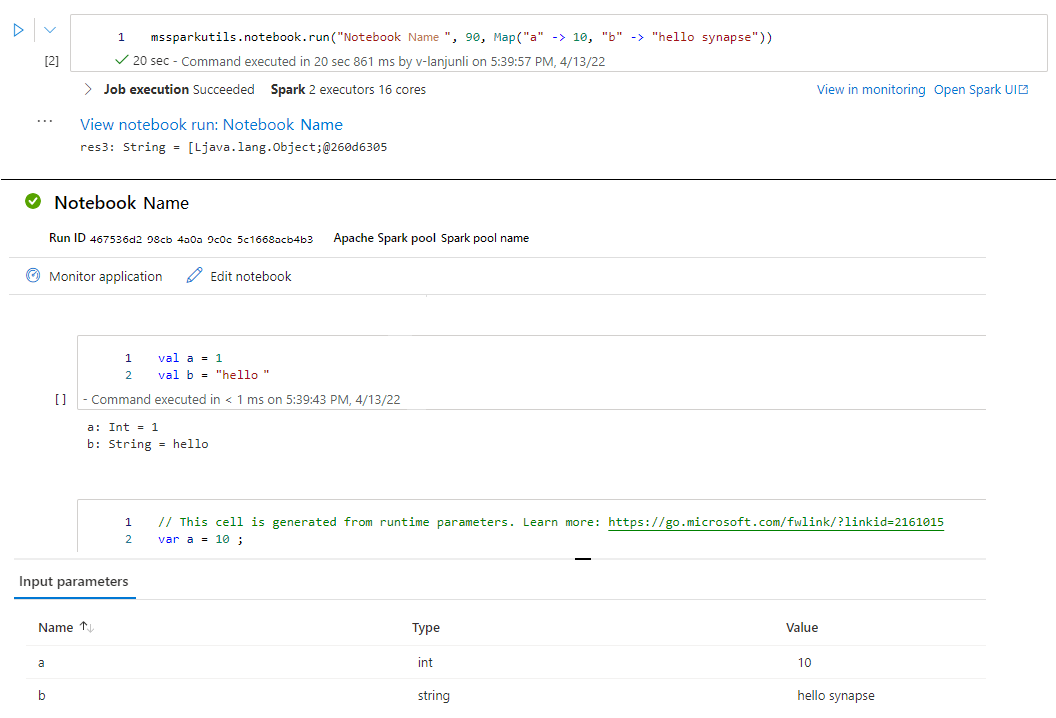
Sair de um bloco de notas
Sai de um bloco de notas com um valor. Você pode executar chamadas de função de aninhamento em um bloco de anotações interativamente ou em um pipeline.
Quando você chama uma
exit()função de bloco de anotações interativamente, o Azure Synapse lança uma exceção, ignora a execução de células de subsequência e mantém a sessão do Spark ativa.Quando você orquestra um bloco de anotações que chama uma
exit()função em um pipeline Synapse, o Azure Synapse retornará um valor de saída, concluirá a execução do pipeline e interromperá a sessão do Spark.Quando você chama uma
exit()função em um bloco de anotações que está sendo referenciado, o Azure Synapse interrompe a execução adicional no bloco de anotações que está sendo referenciado e continua a executar as próximas células no bloco de anotações que chamam arun()função. Por exemplo: o Bloco de Anotações1 tem três células e chama umaexit()função na segunda célula. O Notebook2 tem cinco células e chamarun(notebook1)na terceira célula. Quando você executa o Notebook2, o Notebook1 será parado na segunda célula ao pressionar aexit()função. O Notebook2 continuará a executar sua quarta célula e quinta célula.
mssparkutils.notebook.exit("value string")
Por exemplo:
O bloco de anotações Sample1 localiza-se em mssparkutils/folder/ com as duas células a seguir:
- A célula 1 define um parâmetro de entrada com o valor padrão definido como 10.
- A célula 2 sai do bloco de notas com a entrada como valor de saída.
Você pode executar o Sample1 em outro bloco de anotações com valores padrão:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
Resultados em:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
Você pode executar o Sample1 em outro bloco de anotações e definir o valor de entrada como 20:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
Resultados em:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
Você pode usar os Utilitários de Notebook MSSparkUtils para executar um bloco de anotações ou sair de um bloco de anotações com um valor. Execute o seguinte comando para obter uma visão geral dos métodos disponíveis:
mssparkutils.notebook.help()
Obtenha resultados:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Referenciar um bloco de notas
Faça referência a um bloco de notas e devolve o respetivo valor de saída. Você pode executar chamadas de função de aninhamento em um bloco de anotações interativamente ou em um pipeline. O notebook que está sendo referenciado será executado no pool Spark do qual o notebook chama essa função.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Por exemplo:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
Depois que a execução terminar, você verá um link de instantâneo chamado 'Exibir execução do bloco de anotações: Nome do bloco de anotações' mostrado na saída da célula, você pode clicar no link para ver o instantâneo para essa execução específica.
Sair de um bloco de notas
Sai de um bloco de notas com um valor. Você pode executar chamadas de função de aninhamento em um bloco de anotações interativamente ou em um pipeline.
Quando você chama uma
exit()função de bloco de anotações interativamente, o Azure Synapse lança uma exceção, ignora a execução de células de subsequência e mantém a sessão do Spark ativa.Quando você orquestra um bloco de anotações que chama uma
exit()função em um pipeline Synapse, o Azure Synapse retornará um valor de saída, concluirá a execução do pipeline e interromperá a sessão do Spark.Quando você chama uma
exit()função em um bloco de anotações que está sendo referenciado, o Azure Synapse interrompe a execução adicional no bloco de anotações que está sendo referenciado e continua a executar as próximas células no bloco de anotações que chamam arun()função. Por exemplo: o Bloco de Anotações1 tem três células e chama umaexit()função na segunda célula. O Notebook2 tem cinco células e chamarun(notebook1)na terceira célula. Quando você executa o Notebook2, o Notebook1 será parado na segunda célula ao pressionar aexit()função. O Notebook2 continuará a executar sua quarta célula e quinta célula.
mssparkutils.notebook.exit("value string")
Por exemplo:
O bloco de notas Sample1 localiza-se em pasta/ com as seguintes duas células:
- A célula 1 define um parâmetro de entrada com o valor padrão definido como 10.
- A célula 2 sai do bloco de notas com a entrada como valor de saída.
Você pode executar o Sample1 em outro bloco de anotações com valores padrão:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Resultados em:
Sample1 run success with input is 10
Você pode executar o Sample1 em outro bloco de anotações e definir o valor de entrada como 20:
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
Resultados em:
Sample1 run success with input is 20
Utilitários de credenciais
Você pode usar os Utilitários de Credenciais MSSparkUtils para obter os tokens de acesso de serviços vinculados e gerenciar segredos no Cofre de Chaves do Azure.
Execute o seguinte comando para obter uma visão geral dos métodos disponíveis:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Obter resultado:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Nota
Atualmente, getSecretWithLS(linkedService, secret) não é suportado em C#.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Obter token
Retorna o token do Microsoft Entra para um determinado público, nome (opcional). A tabela abaixo lista todos os tipos de público disponíveis:
| Tipo de público | Literal de cadeia de caracteres a ser usado na chamada de API |
|---|---|
| Armazenamento do Azure | Storage |
| Azure Key Vault | Vault |
| Gestão do Azure | AzureManagement |
| Azure SQL Data Warehouse (dedicado e sem servidor) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Azure Data Explorer | AzureDataExplorer |
| Base de Dados do Azure para MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Base de Dados do Azure para PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Validar token
Retorna true se o token não tiver expirado.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Obter cadeia de conexão ou credenciais para o serviço vinculado
Retorna cadeia de conexão ou credenciais para serviço vinculado.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Obtenha segredo usando a identidade do espaço de trabalho
Retorna o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome do serviço vinculado usando a identidade do espaço de trabalho. Certifique-se de configurar o acesso ao Cofre da Chave do Azure adequadamente.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Obter segredo usando credenciais de usuário
Retorna o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome de serviço vinculado usando credenciais de usuário.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Colocar segredo usando a identidade do espaço de trabalho
Coloca o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome do serviço vinculado usando a identidade do espaço de trabalho. Certifique-se de configurar o acesso ao Cofre da Chave do Azure adequadamente.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Colocar segredo usando a identidade do espaço de trabalho
Coloca o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome do serviço vinculado usando a identidade do espaço de trabalho. Certifique-se de configurar o acesso ao Cofre da Chave do Azure adequadamente.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Colocar segredo usando a identidade do espaço de trabalho
Coloca o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome do serviço vinculado usando a identidade do espaço de trabalho. Certifique-se de configurar o acesso ao Cofre da Chave do Azure adequadamente.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Coloque segredo usando credenciais de usuário
Coloca o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome do serviço vinculado usando credenciais de usuário.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Coloque segredo usando credenciais de usuário
Coloca o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome do serviço vinculado usando credenciais de usuário.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Coloque segredo usando credenciais de usuário
Coloca o segredo do Cofre da Chave do Azure para um determinado nome do Cofre da Chave do Azure, nome secreto e nome do serviço vinculado usando credenciais de usuário.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Utilitários ambientais
Execute os seguintes comandos para obter uma visão geral dos métodos disponíveis:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Obter resultado:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Obter nome de utilizador
Retorna o nome de usuário atual.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Obter ID de utilizador
Retorna o ID de usuário atual.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Obter ID de trabalho
Retorna a ID do trabalho.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Obter nome do espaço de trabalho
Retorna o nome do espaço de trabalho.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Obter nome da piscina
Retorna o nome do pool de faíscas.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Obter ID de cluster
Retorna a ID do cluster atual.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Contexto de tempo de execução
Mssparkutils runtime utils exposed 3 propriedades de tempo de execução, você pode usar o contexto de tempo de execução mssparkutils para obter as propriedades listadas abaixo:
- Notebookname - O nome do bloco de anotações atual sempre retornará valor para o modo interativo e o modo pipeline.
- Pipelinejobid - O ID de execução do pipeline retornará o valor no modo de pipeline e retornará a cadeia de caracteres vazia no modo interativo.
- Activityrunid - O ID de execução da atividade do bloco de anotações retornará o valor no modo pipeline e retornará a cadeia de caracteres vazia no modo interativo.
Atualmente, o contexto de tempo de execução suporta Python e Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Gestão de sessões
Parar uma sessão interativa
Em vez de clicar manualmente no botão parar, às vezes é mais conveniente parar uma sessão interativa chamando uma API no código. Para esses casos, fornecemos uma API mssparkutils.session.stop() para suportar a interrupção da sessão interativa via código, está disponível para Scala e Python.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() A API interromperá a sessão interativa atual de forma assíncrona em segundo plano, interromperá a sessão do Spark e liberará recursos ocupados pela sessão para que fiquem disponíveis para outras sessões no mesmo pool.
Nota
Não recomendamos APIs internas de linguagem de chamada, como sys.exit no Scala ou sys.exit() em Python em seu código, porque essas APIs simplesmente matam o processo do interpretador, deixando a sessão do Spark ativa e os recursos não liberados.
Dependências do pacote
Se você quiser desenvolver blocos de anotações ou trabalhos localmente e precisar fazer referência aos pacotes relevantes para dicas de compilação/IDE, você pode usar os pacotes a seguir.