Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Kusto Query Language (KQL) tem funções integradas de deteção e previsão de anomalias para verificar o comportamento anômalo. Uma vez que esse padrão é detetado, uma Análise de Causa Raiz (RCA) pode ser executada para mitigar ou resolver a anomalia.
O processo de diagnóstico é complexo e demorado, e feito por especialistas do domínio. O processo inclui:
- Buscar e juntar mais dados de diferentes fontes pelo mesmo período de tempo
- Procurando mudanças na distribuição de valores em múltiplas dimensões
- Traçando mais variáveis
- Outras técnicas baseadas no conhecimento e intuição do domínio
Como esses cenários de diagnóstico são comuns, plugins de aprendizado de máquina estão disponíveis para facilitar a fase de diagnóstico e encurtar a duração do RCA.
Todos os três plug-ins do Machine Learning a seguir implementam algoritmos de clustering: autocluster, baskete diffpatterns. O autocluster e basket plug-ins agrupam um único conjunto de registros, e o diffpatterns plug-in agrupa as diferenças entre dois conjuntos de registros.
Clusterizando um único conjunto de registros
Um cenário comum inclui um conjunto de dados selecionado por um critério específico, como:
- Janela de tempo que mostra comportamento anômalo
- Leituras de dispositivos de alta temperatura
- Comandos de longa duração
- Utilizadores com maiores gastos
Você quer uma maneira rápida e fácil de encontrar padrões comuns (segmentos) nos dados. Os padrões são um subconjunto do conjunto de dados cujos registros compartilham os mesmos valores em várias dimensões (colunas categóricas).
A consulta a seguir cria e mostra uma série temporal de exceções de serviço numa semana, em intervalos de dez minutos.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
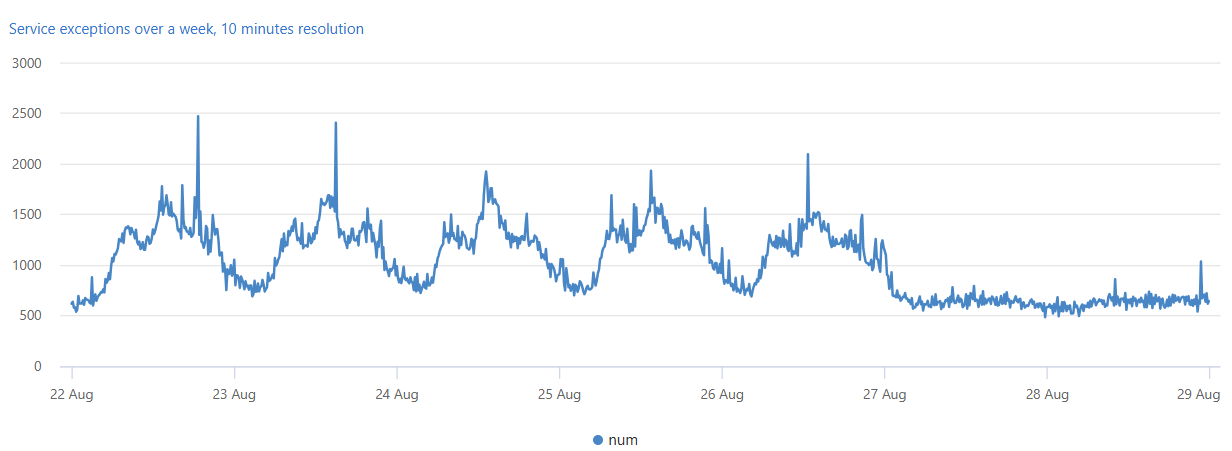
A contagem de exceções de serviço está correlacionada com o tráfego geral do serviço. Você pode ver claramente o padrão diário para dias úteis, de segunda a sexta-feira. Há um aumento nas contagens de exceções de serviço ao meio-dia e quedas nas contagens durante a noite. Contagens consistentemente baixas são visíveis no fim de semana. Os picos de exceção podem ser detetados usando a deteção de anomalias de séries temporais.
O segundo pico nos dados ocorre na tarde de terça-feira. A consulta a seguir é usada para diagnosticar e verificar se é um pico acentuado. A consulta redesenha o gráfico em torno do pico com uma resolução maior de oito horas dividida em intervalos de um minuto. Você pode então analisar os seus limites.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
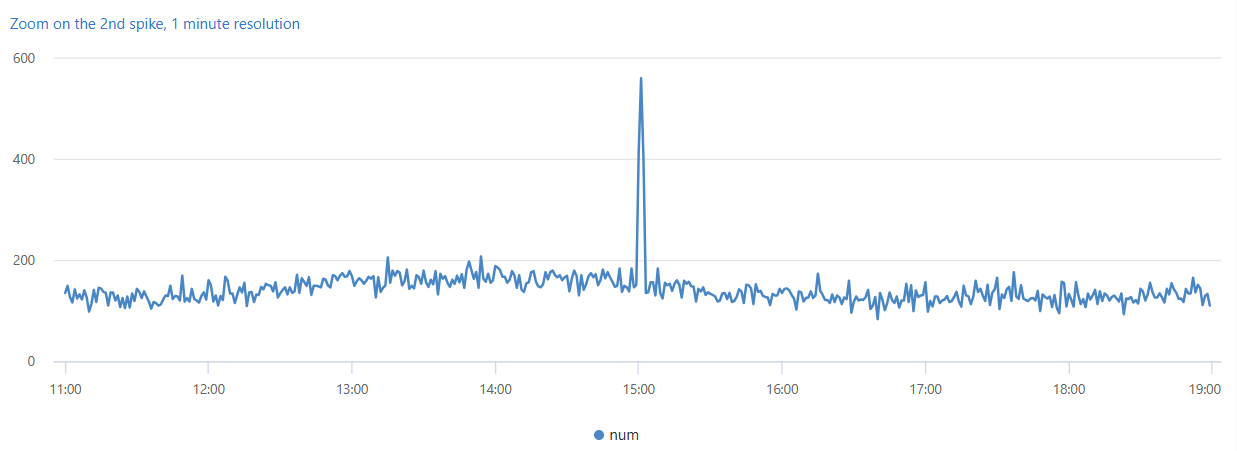
Você vê um estreito pico de dois minutos entre as 15:00 e as 15:02. Na consulta a seguir, conte as exceções nesta janela de dois minutos:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Contar |
|---|
| 972 |
Na consulta a seguir, amostra 20 exceções de um total de 972.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PrecisaTimeStamp | Região | ScaleUnit | DeploymentId | Ponto de rastreamento | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8D257DA1-7A1C-44F5-9ACD-F9E02FF507FD |
| 2016-08-23 15:00:10.5911748 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9D390E07-417D-42EB-BEBD-793965189A28 |
| 2016-08-23 15:00:20.7444854 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6E54C1C8-42D3-4E4E-8B79-9BB076CA71F1 |
| 2016-08-23 15:00:23.8694999 | EUS2 | SU2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19B9-4D85-9CA6-BC961861D287 |
| 2016-08-23 15:00:26.4271786 | NCUS | SU1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271BAE4-1C5B-4F73-98EF-CC117E9BE914 |
| 2016-08-23 15:00:27.8958124 | SCUS | SU3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8CF38575-FCA9-48CA-BD7C-21196F6D6765 |
| 2016-08-23 15:00:32.9884969 | SCUS | SU3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55A71811-5EC4-497A-A058-140FB0D611AD |
| 2016-08-23 15:00:37.4490273 | SCUS | SU3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | SCUS | SU3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8CF38575-FCA9-48CA-BD7C-21196F6D6765 |
| 2016-08-23 15:00:47.2983975 | NCUS | SU1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2A41B552-AA19-4987-8CDD-410A3AF016AC |
| 2016-08-23 15:00:50.8259021 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0D56B8E3-470D-4213-91DA-97405F8D005E |
| 2016-08-23 15:00:53.2490731 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55A71811-5EC4-497A-A058-140FB0D611AD |
| 2016-08-23 15:00:57.0000946 | EUS2 | SU2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | CB55739E-4AFE-46A3-970F-1B49D8EE7564 |
| 2016-08-23 15:00:58.2222707 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | SCUS | SU3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Mesmo que haja menos de mil exceções, ainda é difícil encontrar segmentos comuns, já que há vários valores em cada coluna. Você pode usar o autocluster() plugin para extrair instantaneamente uma pequena lista de segmentos comuns e encontrar os clusters interessantes dentro dos dois minutos do pico, como visto na seguinte consulta:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| Id de Segmento | Contar | Percentagem | Região | ScaleUnit | DeploymentId | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | EAU | SU7 | b5d1d4df547d4a04ac15885617edba57 | E7F60C5D-4944-42B3-922A-92E98A8E7DEC |
| 1 | 94 | 9.67078189300411 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | NCUS | SU1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | SCUS | SU3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5,65843621399177 | UEO | SU4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
Você pode ver pelos resultados acima que o segmento mais dominante contém 65,74% do total de registros de exceção e compartilha quatro dimensões. O próximo segmento é muito menos comum. Ele contém apenas 9,67% dos registros e compartilha três dimensões. Os outros segmentos são ainda menos comuns.
O Autocluster usa um algoritmo proprietário para minerar várias dimensões e extrair segmentos interessantes. "Interessante" significa que cada segmento tem uma cobertura significativa tanto do conjunto de recordes como dos recursos definidos. Os segmentos também são divergentes, o que significa que cada um é diferente dos outros. Um ou mais destes segmentos podem ser relevantes para o processo de RCA. Para minimizar a revisão e a avaliação de segmentos, o cluster automático extrai apenas uma pequena lista de segmentos.
Você também pode usar o basket() plugin como visto na seguinte consulta:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| Id de Segmento | Contar | Percentagem | Região | ScaleUnit | DeploymentId | Ponto de rastreamento | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | EAU | SU7 | b5d1d4df547d4a04ac15885617edba57 | E7F60C5D-4944-42B3-922A-92E98A8E7DEC | |
| 1 | 642 | 66.0493827160494 | EAU | SU7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | EAU | SU7 | b5d1d4df547d4a04ac15885617edba57 | 0 | E7F60C5D-4944-42B3-922A-92E98A8E7DEC |
| 3 | 315 | 32.4074074074074 | EAU | SU7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | E7F60C5D-4944-42B3-922A-92E98A8E7DEC |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | SCUS | SU5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | NCUS | SU1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | SCUS | SU3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | SCUS | ||||
| 9 | 55 | 5,65843621399177 | UEO | SU4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9,25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
O Basket implementa o algoritmo "Apriori" para mineração de conjuntos de itens. Ele extrai todos os segmentos cuja cobertura do conjunto de registros está acima de um limite (padrão 5%). Você pode ver que mais segmentos foram extraídos com outros semelhantes, como segmentos 0, 1 ou 2, 3.
Ambos os plugins são poderosos e fáceis de usar. Sua limitação é que eles agrupam um único conjunto de registros de forma não supervisionada, sem rótulos. Não está claro se os padrões extraídos caracterizam o conjunto de registros selecionado, os registros anômalos ou o conjunto de registros globais.
Agrupando a diferença entre dois conjuntos de registros
O diffpatterns() plugin supera a limitação de autocluster e basket.
Diffpatterns pega dois conjuntos de registros e extrai os principais segmentos que são diferentes. Um conjunto geralmente contém o conjunto de registros anômalos que está sendo investigado. Um é analisado por autocluster e basket. O outro conjunto contém o conjunto de registros de referência, a linha de base.
Na consulta a seguir, diffpatterns encontra clusters interessantes dentro dos dois minutos do pico, que são diferentes dos clusters dentro da linha de base. O intervalo de base é definido como os oito minutos antes das 15:00, quando começou o pico. Você estende por uma coluna binária (AB) e especifica se um registro específico pertence à linha de base ou ao conjunto anômalo.
Diffpatterns implementa um algoritmo de aprendizagem supervisionada, onde os dois rótulos de classe foram gerados pela bandeira anômala versus a linha de base (AB).
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| Id de Segmento | CondeA | Contagem B | PercentagemA | Percentagem B | DiferençaPercentualAB | Região | ScaleUnit | DeploymentId | Ponto de rastreamento |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | EAU | SU7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | SCUS | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25,81 | 17.38 | NCUS | SU1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | UEO | SU4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
O segmento mais dominante é o mesmo que foi extraído pela autocluster. Sua cobertura na janela anômala de dois minutos também é de 65,74%. No entanto, sua cobertura na janela de referência de oito minutos é de apenas 1,7%. A diferença é de 64,04%. Esta diferença parece estar relacionada com o pico anómalo. Para verificar essa suposição, a consulta a seguir divide o gráfico original nos registros que pertencem a esse segmento problemático e nos registros dos outros segmentos.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
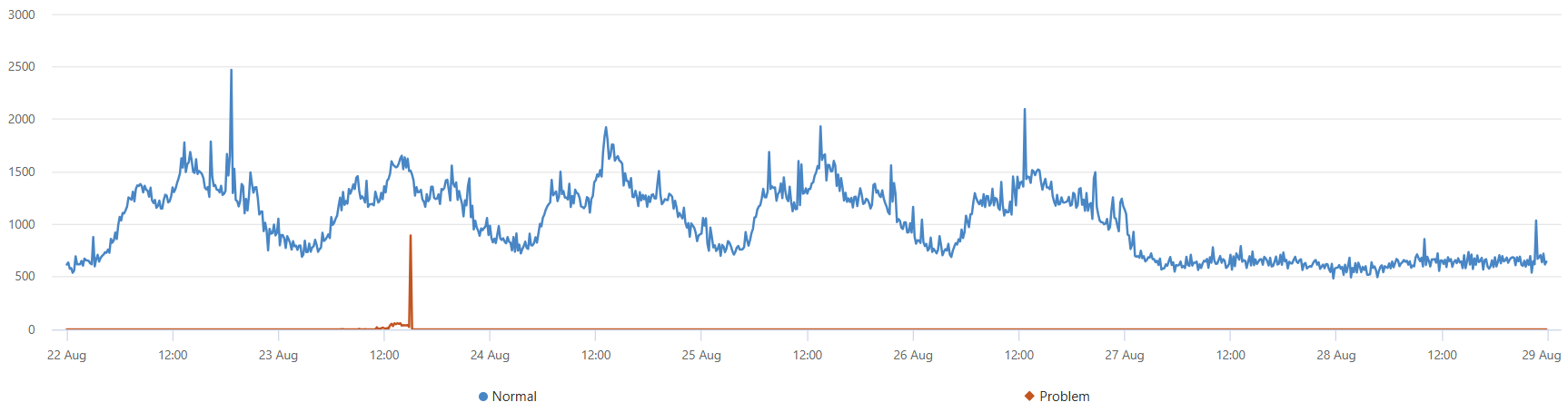
Este gráfico permite-nos ver que o pico na tarde de terça-feira foi devido a exceções deste segmento específico, descoberto usando o diffpatterns plugin.
Resumo
Os plug-ins do Machine Learning são úteis para muitos cenários. O autocluster e o basket implementam um algoritmo de aprendizagem não supervisionada e são fáceis de usar.
Diffpatterns implementa um algoritmo de aprendizagem supervisionada e, embora mais complexo, é mais poderoso para extrair segmentos de diferenciação para RCA.
Esses plugins são usados interativamente em cenários ad-hoc e em serviços de monitoramento automático quase em tempo real. A deteção de anomalias de séries temporais é seguida por um processo de diagnóstico. O processo é altamente otimizado para atender aos padrões de desempenho necessários.