Resiliência no design e na política
A frase que provavelmente se ouvirá com mais frequência em conjunto com "recuperação de desastres" é "continuidade de negócios". A continuidade tem uma conotação positiva. Faz referência ao ideal de limitar o âmbito de um evento de desastre ou mesmo algo menor em termos de âmbito aos limites do datacenter.
No entanto, "continuidade" não é um termo de engenharia, apesar dos esforços nesse sentido. Não existe uma fórmula, metodologia ou receita únicas para a continuidade do negócio. Para qualquer organização, pode haver um conjunto único de melhores práticas que dizem respeito ao tipo e à forma de negócio que realiza. A continuidade é a aplicação bem-sucedida destas práticas para obter um resultado positivo.
O significado da resiliência
Os engenheiros compreendem o conceito de resiliência. Quando um sistema tem bom desempenho em variadas circunstâncias, é considerado resiliente. Um gestor de risco considera um negócio bem preparado quando o mesmo implementa isenções de falhas, medidas de segurança e procedimentos após desastre prontos para responder a qualquer impacto adverso que possa enfrentar. Um engenheiro pode não perceber o ambiente em que um sistema opera em termos tão preto e branco, "normal" e "ameaçado", "segurança" e "desastre". Essa pessoa percebe que o sistema que suporta uma empresa está em ordem de funcionamento adequada quando fornece níveis de serviço contínuos e previsíveis em face de circunstâncias adversas.
Em 2011, assim como a computação em nuvem se tornou uma tendência crescente no data center, a Agência Europeia de Segurança das Redes e da Informação (ENISA, uma unidade da União Europeia) emitiu um relatório em resposta a um pedido do governo da UE para obter informações sobre a resiliência dos sistemas que eles usaram para coletar e coletar informações. O relatório afirmava claramente que ainda não havia consenso entre os seus funcionários de TCI (na Europa, "TCI" é um termo para "TI", que inclui comunicações) relativo ao significado real de "resiliência" ou à respetiva medição.
Isto levou a ENISA a descobrir um projeto lançado por uma equipa de investigadores da Universidade do Kansas (KU), liderada pelo Prof. James P. G. Sterbenz, com a intenção de ser implantado no Departamento de Defesa dos EUA. Chama-se Iniciativa de Redes Resilientes e Persistentes (ResiliNets)1 e é um método para visualizar o estado flutuante da resiliência nos sistemas de informações em várias circunstâncias. A ResiliNets é o protótipo de um modelo de consenso para a política de resiliência nas organizações.
O modelo da KU utiliza várias métricas familiares e fáceis de explicar, sendo que algumas dessas já foram introduzidas neste capítulo. Estas incluem:
Tolerância a falhas: conforme explicado anteriormente, trata-se da capacidade de um sistema de manter os níveis de serviço esperados quando as falhas estão presentes
Tolerância à interrupção: trata-se da capacidade desse mesmo sistema de manter os níveis de serviço esperados face a circunstâncias operacionais imprevisíveis e, muitas vezes, extremas que não são causadas pelo próprio sistema. Por exemplo: cortes elétricos, falha de largura de banda na Internet e picos de tráfego
Capacidade de sobrevivência: trata-se de uma estimativa da capacidade de um sistema de fornecer níveis de desempenho do serviço razoáveis, se não sempre nominais, em todas as circunstâncias possíveis, incluindo desastres naturais
A teoria chave avançada pela ResiliNets é que os sistemas de informações se tornam mais resistentes, de forma quantificável, através de uma combinação de engenharia de sistemas e esforço humano. O que as pessoas fazem (e mais do que isso, o que continuam a fazer em matéria de prática quotidiana) torna os sistemas mais fortes.
Tomando uma pista de como soldados, marinheiros e fuzileiros navais em um teatro de operações ativo aprendem e lembram os princípios de implantação tática, a equipe KU propôs um mnemônico de volta do guardanapo para lembrar o ciclo de vida da prática ResiliNets: D2 R2 + DR. Conforme retratado na Imagem 9, as variáveis aqui representam o seguinte, nesta ordem:**
Defender o sistema contra ameaças à sua operação normal
Detetar a ocorrência de efeitos adversos, devido a possíveis falhas, bem como circunstâncias externas
Remediar o impacto subsequente que esses efeitos podem ter no sistema, mesmo que esse impacto ainda não tenha sido sustentado
Recuperar os níveis normais de serviço
Diagnosticar as principais causas dos acontecimentos
Refinar futuros comportamentos, se necessário, para estarem mais bem preparados para a sua reincidência
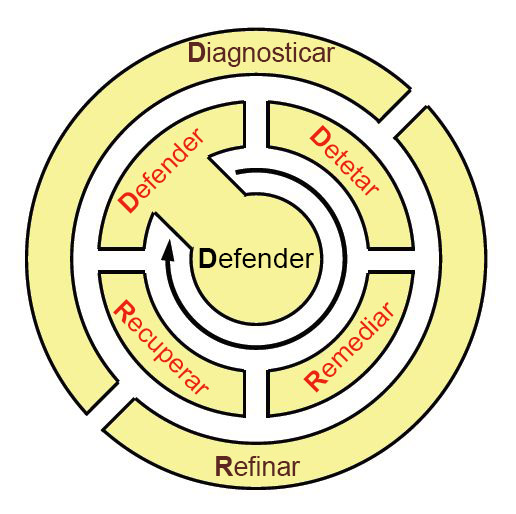
Figura 9: O ciclo de vida das atividades de práticas recomendadas em um ambiente que utiliza ResiliNets.
Durante cada uma destas fases, são obtidas determinadas métricas de desempenho e operacionais, tanto de pessoas como para sistemas. A combinação destas métricas resulta em pontos que podem ser representados num gráfico como o da Imagem 9.10 com um plano geométrico euclidiano. Cada métrica pode ser reduzida a dois valores unidimensionais: um que reflete os parâmetros de nível de serviço P e outro que representa o estado operacional N. Como todos os seis estágios do ciclo ResiliNets são implementados e repetidos, o estado de serviço S é plotado no gráfico em coordenadas (N, P).
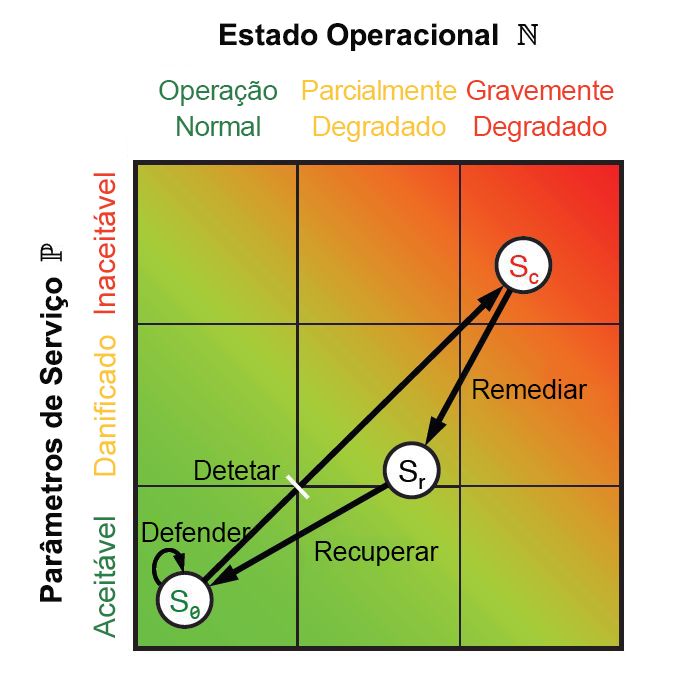
Figura 10: O espaço de estado ResiliNets e o loop interno da estratégia.
Uma organização que cumpre os seus objetivos de serviço terá o seu estado S a pairar firmemente no canto inferior esquerdo do gráfico, esperando-se que permaneça lá ou perto durante o que é denominado ciclo interno. Quando os objetivos de serviço estão a ser degradados, o estado será deslocado num vetor indesejado em direção ao canto superior direito.
Embora o modelo ResiliNets não se tenha tornado uma representação ubíqua da resiliência das TI nas grandes empresas, a sua adoção por algumas organizações proeminentes, particularmente no setor público, desencadeou algumas das mudanças que catalisaram a revolução da cloud:
Visualização do desempenho. A resiliência não tem de ser uma filosofia para que o seu estado atual seja comunicado aos intervenientes relevantes. Na verdade, pode ser demonstrado com menos de uma palavra. As plataformas de gestão de desempenho modernas que incorporam métricas da cloud incorporaram dashboards e ferramentas semelhantes que desempenham as suas funções de forma eficaz.
As medidas e procedimentos de recuperação não têm de esperar por um desastre. Um sistema de informações minucioso e bem concebido, continuamente dotado de engenheiros e operadores vigilantes, implementará diariamente procedimentos de manutenção que apresentem pouca, se alguma, diferença em relação aos procedimentos de remediação durante uma crise. Num ambiente de recuperação após desastres de reserva ativa, por exemplo, a remediação do problema do nível de serviço pode efetivamente tornar-se automática, sendo que o router principal simplesmente afasta o tráfego dos componentes afetados. Por outras palavras, a preparação para as falhas não tem de ser o mesmo que esperar por elas.
Os sistemas de informações são compostos por pessoas. A automatização pode tornar o trabalho das pessoas mais eficaz e fazer com que os seus produtos sejam produzidos de forma mais eficiente. No entanto, não substitui as pessoas num sistema concebido para responder a alterações circunstanciais e ambientais que não podem ser antecipadas.
Computação orientada para a recuperação
A ResiliNets é uma implementação de um conceito que a Microsoft ajudou a financiar após a mudança do século, chamado Computação orientada para a recuperação (ROC).2 O seu princípio fundamental era que as falhas e os erros eram verdades perenes do ambiente informático. Em vez de passar excessivos períodos de tempo a desinfetar este ambiente, por assim dizer, pode ser mais benéfico para as organizações aplicar medidas de senso comum que contribuam para a inoculação do ambiente. Trata-se do equivalente de computação do conceito radical, introduzido pouco antes da mudança do século XX, de que as pessoas devem lavar as mãos várias vezes por dia.
Resiliência na cloud pública
Todos os fornecedores de serviços cloud públicos cumprem princípios e quadros de resiliência, mesmo quando optam por não lhe atribuir esse nome. No entanto, uma plataforma cloud não adiciona resiliência ao datacenter de uma organização, a menos que absorva na íntegra os recursos de informação dessa organização na cloud. Uma implementação híbrida em cloud é tão resistente como os seus administradores menos diligentes. Se pudermos supor que os administradores de um CSP serão diligentes no cumprimento da resiliência (ou então violar os termos do seu SLA), tem de ser sempre tarefa do cliente manter a resiliência de todo o sistema.
Azure Resiliency Framework
A orientação da norma internacional da estratégia de continuidade de negócio é a ISO 22301. Tal como acontece com outros quadros da International Standards Organization (ISO), especifica orientações para as melhores práticas e operações, cuja conformidade permite a certificação profissional de uma organização.
Este quadro ISO não define a continuidade do negócio, nem, aliás, a sua resiliência. Em vez disso, define o significado de continuidade no contexto da própria organização. "A organização deve identificar e selecionar estratégias de continuidade do negócio", consta no documento de orientação, "com base nos resultados da análise de impacto empresarial e na avaliação dos riscos. As estratégias de continuidade das atividades devem ser compostas por uma ou mais soluções.» Não enumera quais podem ou devem ser essas soluções.3
A Imagem 11 é a representação da Microsoft da implementação em várias fases da conformidade com a norma ISO 22301 do Azure. Tenha em atenção a inclusão de objetivos relativos a tempos de atividade do contrato de nível de serviço (SLA). Para os clientes que escolhem este nível de resiliência, o Azure replica datacenters virtuais nas suas zonas de disponibilidade locais, mas depois aprovisiona réplicas separadas cuja geolocalização é separada por centenas de quilómetros. No entanto, por questões legais, (especialmente para manter a conformidade com as leis de privacidade da União Europeia), esta redundância separada pela geolocalização está normalmente limitada a "limites de residência dos dados" como a América do Norte ou a Europa.
![Figure 11: Azure Resiliency Framework, which protects active components on multiple levels, in accordance with ISO 22301. [Courtesy Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
Figura 11: Azure Resiliency Framework, que protege componentes ativos em vários níveis, de acordo com a ISO 22301. [Cortesia Microsoft]
Embora a norma ISO 22301 esteja associada à resiliência e seja, muitas vezes, descrita como um conjunto de diretrizes de resiliência, os níveis de resiliência para os quais o Azure foi testado apenas se aplicam à plataforma Azure e não aos recursos dos clientes alojados naquela plataforma. Continua a ser da responsabilidade do cliente gerir, manter e melhorar frequentemente os seus processos, incluindo a forma como os seus recursos são replicados na cloud do Azure e noutros locais.
Google Container Engine
Até recentemente, o software era visto como o estado de uma máquina que era funcionalmente idêntica ao hardware, mas num formato digital. Nessa perspetiva, o software tem sido visto como um componente relativamente estático num sistema de informações. Os protocolos de segurança exigiam que o software fosse atualizado regularmente e que "regularmente" normalmente significasse algumas vezes por ano, à medida que as atualizações e correções de erros ficassem disponíveis.
O que a dinâmica da cloud viabilizou, embora muitos engenheiros de TI não tivessem antecipado, foi a capacidade de o software evoluir de forma gradual, porém frequente. Integração Contínua e Entrega Contínua: a (CI/CD) é um conjunto emergente de princípios no qual a automatização permite a transição frequente, muitas vezes diária, de alterações incrementais no software, tanto no lado do servidor como do cliente. Os utilizadores de smartphones experimentam a CI/CD regularmente, em virtude de aplicações que são atualizadas algumas vezes por semana nas lojas de aplicações. Cada alteração provocada pela CI/CD pode ser menor. No entanto, o facto de pequenas alterações poderem ser rapidamente implementadas sem qualquer dificuldade causou um efeito secundário imprevisível, porém bem-vindo: sistemas de informações muito mais resistentes.
Com os modelos de implementação da CI/CD, os clusters de servidores totalmente redundantes são aprovisionados e mantidos, muitas vezes em infraestrutura de cloud pública, exclusivamente como meios de testar componentes de software recém-produzidos para erros, e, em seguida, realizar a transição desses componentes num ambiente de trabalho simulado para descobrir potenciais falhas. Desta forma, os processos de reparação podem ocorrer num ambiente seguro que não tenha qualquer efeito direto nos níveis de serviço orientado para o cliente ou para o utilizador, até a aplicação, o teste e a aprovação das soluções para implementação.
O Google Container Engine (GKE, no qual o "K" significa "Kubernetes") é o ambiente da Google Cloud Platform para os clientes que implementam aplicações e serviços baseados em contentores, em vez de aplicações baseadas na VM. Uma implementação completa alojada em contentores pode incluir microsserviços ("serviços µ"), bases de dados separadas das cargas de trabalho e concebidas para operar independentemente ("conjuntos de dados com estado"), bibliotecas de códigos dependentes e pequenos sistemas operativos utilizados caso o código de aplicação precise de utilizar o próprio sistema de ficheiros do contentor. A Imagem 9.12 retrata uma dessas implementações no estilo sugerido pela Google para os clientes do GKE.
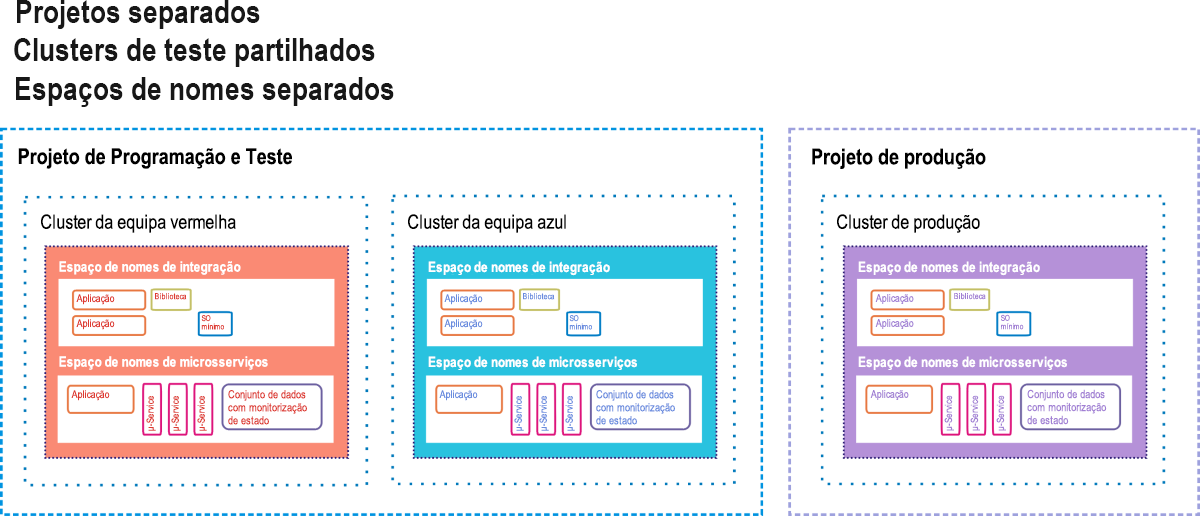
Figura 12: Uma opção de espera ativa como um ambiente de preparação de CI/CD para o Google Container Engine.
No GKE, um projeto é semelhante a um datacenter, no sentido de se considerar que tem todos os recursos que um datacenter normalmente teria, mas em formato virtual. Pode haver um ou mais clusters de servidores atribuídos a um projeto. Os componentes alojados em contentores existem nos seus próprios espaços de nomes, que são como os seus universos domésticos. Cada um é composto por todos os componentes endereçados cujo acesso é permitido aos respetivos contentores de membros. Tudo o que estiver fora do espaço de nomes tem de ser endereçado com endereços IP remotos. Os engenheiros da Google sugerem que aplicações de cliente/servidor de estilo antigo (chamadas "monólitos" por programadores de contentores) podem coexistir com aplicações alojadas em contentores, desde que cada classe utilize o seu próprio espaço de nome por questões de segurança, enquanto partilha o mesmo projeto.
Neste diagrama de implementação sugerido, existem três clusters ativos, cada um com dois espaços de nome: um para software antigo, um para software novo. Dois destes clusters são delegados para testes: um para testes iniciais de desenvolvimento e outro para a transição final. Num pipeline da CI/CD, são injetados novos contentores de código num dos clusters de testes. Ali, tem de passar por uma bateria de testes automatizados, que comprovem que não têm erros, antes de serem transferidos para a transição. Uma segunda bateria aguarda os novos contentores de software lá. Apenas o código que passou nos testes de transição do segundo escalão pode ser injetado no cluster de produção ativo que os clientes finais estão a utilizar.
No entanto, mesmo aí, há isenções de falhas. Num cenário de implementação A/B, o novo código coexiste com o código antigo durante um determinado período de tempo. Se o novo código não cumprir as especificações ou introduzir falhas no sistema, pode ser removido, deixando para trás o antigo código. Se o intervalo de palavras expirar e o novo código tiver um bom desempenho, o código antigo é removido.
Este processo é uma forma sistemática e semi-automatizada de os sistemas de informações evitarem a introdução de erros que originam falhas. No entanto, não é uma configuração à prova de desastres, a menos que o cluster de produção seja replicado em modo de reserva ativa. Certamente, este esquema de replicação consome muitos recursos com base na cloud. No entanto, os custos envolvidos podem ainda ser muito inferiores aos suportados por uma organização devido a uma falha no sistema.
Referências
Sterbenz, James P.G., et al. "ResiliNets: Iniciativa de Rede Multinível Resiliente e Sobrevivente." https://resilinets.org/main_page.html.
Patterson, David, et al. "Computação Orientada para a Recuperação: Motivação, Definição, Princípios e Exemplos." Microsoft Research, março de 2002. https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/.
ISO. "Segurança e resiliência - Sistemas de gestão da continuidade de negócios - Requisitos." https://dri.ca/docs/ISO_DIS_22301_(E).pdf.