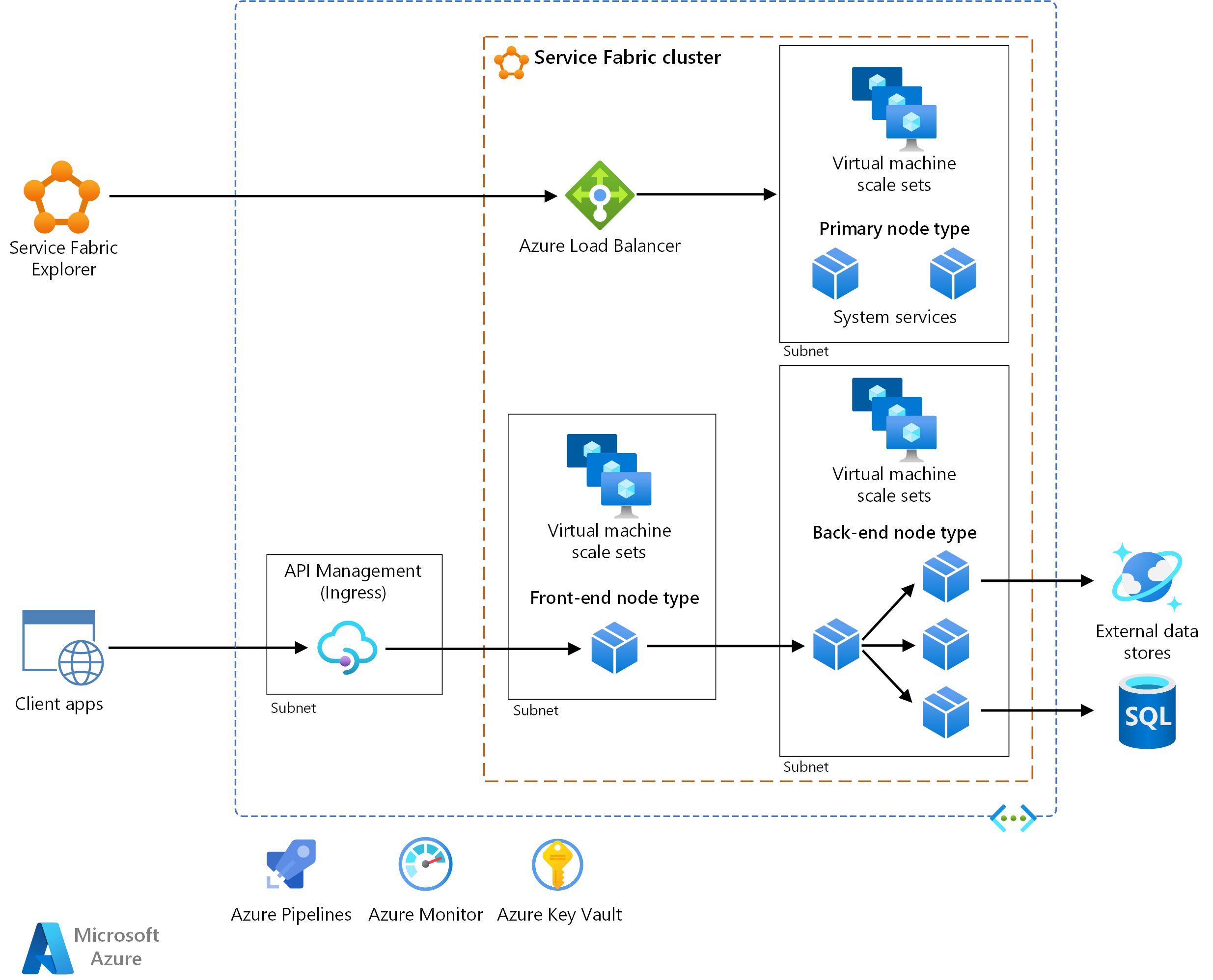
В этой эталонной архитектуре показана архитектура микрослужб, развернутая в Azure Service Fabric. В нем показана базовая конфигурация кластера, которая может быть отправной точкой для большинства развертываний.
 Эталонная реализация этой архитектуры доступна на сайте GitHub.
Эталонная реализация этой архитектуры доступна на сайте GitHub.
Архитектура
Скачайте файл Visio для этой архитектуры.
Примечание.
В этой статье рассматривается модель программирования Reliable Services для Service Fabric. Использование Service Fabric для развертывания контейнеров и управления ими выходит за рамки область этой статьи.
Рабочий процесс
Архитектура состоит из следующих компонентов: Другие термины см. в обзоре терминологии Service Fabric.
Кластер Service Fabric. Кластер — это подключенный к сети набор виртуальных машин( виртуальных машин), в котором развертываются микрослужбы и управляют ими.
Масштабируемые наборы виртуальных машин. Масштабируемые наборы виртуальных машин позволяют создавать и управлять группой идентичных, балансировки нагрузки и автомасштабирования виртуальных машин. Эти вычислительные ресурсы также предоставляют домены сбоя и обновления.
Узлы. Узлы — это виртуальные машины, принадлежащие кластеру Service Fabric.
Типы узлов. Тип узла представляет масштабируемый набор виртуальных машин, который развертывает коллекцию узлов. Кластер Service Fabric имеет по крайней мере один тип узла.
В кластере с несколькими типами узлов необходимо объявить тип первичного узла. Основной тип узла в кластере запускает системные службы Service Fabric. Эти службы предоставляют возможности платформы Service Fabric. Тип первичного узла также выступает в качестве начальных узлов, которые являются узлами, которые поддерживают доступность базового кластера.
Настройте дополнительные типы узлов для запуска служб.
Службы. Служба выполняет автономную функцию, которая может запускаться и запускаться независимо от других служб. Экземпляры служб развертываются на узлах в кластере. В Service Fabric есть два типа служб:
- Служба без отслеживания состояния. Служба без отслеживания состояния не поддерживает состояние в службе. Если требуется сохраняемость состояния, то состояние записывается в внешнее хранилище и извлекается из внешнего хранилища, например Azure Cosmos DB.
- Служба с отслеживанием состояния. Состояние службы хранится в самой службе. Большинство служб с отслеживанием состояния реализуют это с помощью надежных коллекций в Service Fabric.
Обозреватель Service Fabric. Service Fabric Обозреватель — это средство с открытым исходным кодом для проверки кластеров Service Fabric и управления ими.
Azure Pipelines. Azure Pipelines является частью Azure DevOps Services и выполняет автоматизированные сборки, тесты и развертывания. Вы также можете использовать сторонние решения непрерывной интеграции и непрерывной доставки (CI/CD), такие как Jenkins.
Azure Monitor. Azure Monitor собирает и хранит метрики и журналы, включая метрики платформы, для служб Azure в решении и телеметрии приложений. С помощью этих данных можно отслеживать приложения, настраивать оповещения и панели мониторинга, а также анализировать первопричины сбоев. Azure Monitor интегрируется с Service Fabric для сбора метрик из контроллеров, узлов и контейнеров, а также журналов контейнеров и контейнеров.
Azure Key Vault. Используйте Key Vault для хранения секретов приложений, используемых микрослужбами, например строка подключения.
Служба управления Azure API. В этой архитектуре Управление API выступает в качестве шлюза API, который принимает запросы от клиентов и направляет их в службы.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов для улучшения качества рабочей нагрузки.
Рекомендации по проектированию
Эта эталонная архитектура ориентирована на архитектуры микрослужб. Микрослужба — это небольшая, независимо версияная единица кода. Это можно обнаружить с помощью механизмов обнаружения служб и взаимодействовать с другими службами через API. Каждая служба является самодостаточной и должна реализовывать возможности одной компании. Дополнительные сведения о том, как разложить домен приложения на микрослужбы, см. в статье "Использование анализа домена для моделирования микрослужб".
Service Fabric обеспечивает инфраструктуру для эффективной сборки, развертывания и обновления микрослужб. Он также предоставляет возможности автомасштабирования, управления состоянием, мониторингом работоспособности и перезапуском служб в случае сбоя.
Service Fabric следует модели приложения, в которой приложение является коллекцией микрослужб. Приложение описано в файле манифеста приложения. Этот файл определяет типы служб, которые содержит приложение, а также указатели на независимые пакеты служб.
Пакет приложения также обычно содержит параметры, которые служат переопределениями для определенных параметров, используемых службами. Каждый пакет службы содержит файл манифеста, описывающий физические файлы и папки, необходимые для запуска этой службы, включая двоичные файлы, файлы конфигурации и данные только для чтения. Службы и приложения являются независимыми версиями и обновляемыми.
При необходимости манифест приложения может описать службы, которые автоматически подготавливаются при создании экземпляра приложения. Они называются службами по умолчанию. В этом случае манифест приложения также описывает создание этих служб. Эти сведения включают имя службы, количество экземпляров, политику безопасности или изоляции и ограничения размещения.
Примечание.
Избегайте использования служб по умолчанию, если вы хотите контролировать время существования служб. Службы по умолчанию создаются при создании приложения и выполняются до тех пор, пока приложение запущено.
Дополнительные сведения см. в статье "Чтобы узнать о Service Fabric?".
Модель упаковки "приложения — служба"
Принцип микрослужб заключается в том, что каждая служба может быть независимо развернута. Если в Service Fabric все службы группируются в один пакет приложения, а одна служба не будет обновлена, все обновление приложения откатится. Этот откат предотвращает обновление другой службы.
Поэтому в архитектуре микрослужб рекомендуется использовать несколько пакетов приложений. Поместите один или несколько связанных типов служб в один тип приложения. Например, поместите типы служб в один и тот же тип приложения, если ваша команда отвечает за набор служб, имеющих один из следующих атрибутов:
- Они выполняются в течение той же длительности и должны обновляться одновременно.
- Они имеют одинаковый жизненный цикл.
- Они совместно используют такие ресурсы, как зависимости или конфигурация.
Модели программирования Service Fabric
При добавлении микрослужбы в приложение Service Fabric определите, имеет ли оно состояние или данные, которые необходимо сделать высокодоступным и надежным. Если да, можно ли хранить данные вне службы или содержать данные в рамках службы? Выберите службу без отслеживания состояния, если вам не нужно хранить данные или хранить данные во внешнем хранилище. Рассмотрите возможность выбора службы с отслеживанием состояния, если применяется одна из этих инструкций:
- Вы хотите поддерживать состояние или данные в рамках службы. Например, необходимо, чтобы данные располагались в памяти рядом с кодом.
- Нельзя терпеть зависимость от внешнего хранилища.
Если у вас есть существующий код, который вы хотите запустить в Service Fabric, его можно запустить как гостевой исполняемый файл: произвольный исполняемый файл, который выполняется в качестве службы. Кроме того, можно упаковить исполняемый файл в контейнер, имеющий все зависимости, необходимые для развертывания.
Service Fabric моделирует контейнеры и гостевые исполняемые файлы как службы без отслеживания состояния. Рекомендации по выбору модели см. в обзоре модели программирования Service Fabric.
Вы несете ответственность за обслуживание среды, в которой выполняется гостевой исполняемый файл. Например, предположим, что гостевой исполняемый файл требует Python. Если исполняемый файл не является автономным, необходимо убедиться, что необходимая версия Python предварительно установлена в среде. Service Fabric не управляет средой. Azure предлагает несколько механизмов настройки среды, включая пользовательские образы и расширения виртуальных машин.
Чтобы получить доступ к гостевому исполняемому файлу через обратный прокси-сервер, убедитесь, что атрибут добавлен UriScheme в Endpoint элемент в манифесте службы гостевого исполняемого файла.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Если у службы есть дополнительные маршруты, укажите маршруты в значении PathSuffix . Значение не должно быть префиксировано или суффиксировано косой чертой (/). Другой способ — добавить маршрут в имя службы.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Дополнительные сведения см. в разделе:
Шлюз API
Шлюз API (входящий трафик ) находится между внешними клиентами и микрослужбами. Он выполняет роль обратного прокси-сервера, который перенаправляет запросы от клиентов к микрослужбам. Он также может выполнять перекрестные задачи, такие как проверка подлинности, завершение SSL и ограничение скорости.
Мы рекомендуем Azure Управление API для большинства сценариев, но Traefik является популярной альтернативой с открытым исходным кодом. Оба варианта технологии интегрированы с Service Fabric.
Управление API. Предоставляет общедоступный IP-адрес и направляет трафик к службам. Он выполняется в выделенной подсети в той же виртуальной сети, что и кластер Service Fabric.
Управление API может получить доступ к службам в типе узла, который предоставляется через подсистему балансировки нагрузки с частным IP-адресом. Этот параметр доступен только на уровнях "Премиум" и "Разработчик" Управление API. Для рабочих нагрузок используйте уровень "Премиум". Сведения о ценах описаны в Управление API ценах.
Дополнительные сведения см. в статье Service Fabric с помощью Azure Управление API обзор.
Траефик. Поддерживает такие функции, как маршрутизация, трассировка, журналы и метрики. Traefik выполняется как служба без отслеживания состояния в кластере Service Fabric. Управление версиями служб может поддерживаться с помощью маршрутизации.
Сведения о настройке Traefik для входящего трафика служб и обратном прокси-сервере в кластере см . на веб-сайте Traefik поставщика Azure Service Fabric. Дополнительные сведения об использовании Traefik с Service Fabric см. в записи блога интеллектуальной маршрутизации в Service Fabric с Traefik.
Traefik, в отличие от Azure Управление API, не имеет функциональных возможностей для разрешения секции службы с отслеживанием состояния (с несколькими секциями), в которую направляется запрос. Дополнительные сведения см. в разделе "Добавление сопоставления" для служб секционирования.
Другие варианты управления API включают Шлюз приложений Azure и Azure Front Door. Эти службы можно использовать вместе с Управление API для выполнения таких задач, как маршрутизация, завершение SSL и брандмауэр.
Обмен данными между службами
Чтобы упростить обмен данными между службами, рассмотрите следующие рекомендации:
Протокол связи. В архитектуре микрослужб службы должны взаимодействовать друг с другом с минимальным взаимодействием во время выполнения. Чтобы обеспечить взаимодействие между языками, http является отраслевым стандартом с широким спектром инструментов и HTTP-серверов, доступных на разных языках. Service Fabric поддерживает все эти средства и серверы.
Для большинства рабочих нагрузок рекомендуется использовать HTTP вместо удаленного взаимодействия службы, встроенного в Service Fabric.
Обнаружение служб. Чтобы взаимодействовать с другими службами в кластере, служба клиента должна разрешить текущее расположение целевой службы. В Service Fabric службы могут перемещаться между узлами и динамически изменять конечные точки службы.
Чтобы избежать подключений к устаревшим конечным точкам, можно использовать службу именования в Service Fabric для получения обновленных сведений о конечной точке. Однако Service Fabric также предоставляет встроенную службу обратного прокси-сервера , которая абстрагирует службу именования. Мы рекомендуем использовать этот параметр для обнаружения служб в качестве базового плана для большинства сценариев, так как проще использовать и получить более простой код.
Другие варианты взаимодействия между службами включают:
- Traefik для расширенной маршрутизации.
- DNS для сценариев совместимости, в которых служба ожидает использовать DNS.
- Класс ServicePartitionClient TCommunicationClient><, который кэширует конечные точки службы. Это может обеспечить лучшую производительность, так как вызовы проходят непосредственно между службами без посредников или пользовательских протоколов.
Масштабируемость
Service Fabric поддерживает масштабирование этих сущностей кластера:
- Масштабирование количества узлов для каждого типа узла
- Масштабирование служб
Этот раздел посвящен автомасштабированием. Вы можете вручную масштабировать в ситуациях, когда это уместно. Например, для задания количества экземпляров может потребоваться вмешательство вручную.
Начальная конфигурация кластера для масштабируемости
При создании кластера Service Fabric подготовьте типы узлов в зависимости от потребностей безопасности и масштабируемости. Каждый тип узла сопоставляется с масштабируемым набором виртуальных машин и может масштабироваться независимо.
- Создайте тип узла для каждой группы служб, имеющих разные требования к масштабируемости или ресурсам. Начните с подготовки типа узла (который становится основным типом узла) для системных служб Service Fabric. Создайте отдельные типы узлов для запуска общедоступных или интерфейсных служб. Создайте другие типы узлов при необходимости для внутренних и частных или изолированных служб. Укажите ограничения размещения, чтобы службы развертывались только в предполагаемых типах узлов.
- Укажите уровень устойчивости для каждого типа узла. Уровень устойчивости представляет способность Service Fabric влиять на обновления и операции обслуживания в масштабируемых наборах виртуальных машин. Для рабочих нагрузок выберите уровень устойчивости Silver или более высокого уровня устойчивости. Сведения о каждом уровне см. в разделе "Характеристики устойчивости" кластера.
- Если вы используете уровень устойчивости "Бронза", некоторые операции требуют выполнения вручную. Типы узлов с уровнем устойчивости "Бронза" требуют дополнительных шагов во время масштабирования. Дополнительные сведения об операциях масштабирования см . в этом руководстве.
Масштабирование узлов
Service Fabric поддерживает автомасштабирование для масштабирования и горизонтального масштабирования. Вы можете настроить каждый тип узла для автоматического масштабирования независимо.
Каждый тип узла может содержать не более 100 узлов. Начните с меньшего набора узлов и добавьте дополнительные узлы в зависимости от нагрузки. Если требуется более 100 узлов в типе узла, необходимо добавить дополнительные типы узлов. Дополнительные сведения см. в рекомендациях по планированию емкости кластера Service Fabric. Масштабируемый набор виртуальных машин не масштабируется мгновенно, поэтому учитывайте этот фактор при настройке правил автомасштабирования.
Чтобы поддерживать автоматическое масштабирование, настройте тип узла для уровня устойчивости Silver или Gold. Эта конфигурация гарантирует задержку масштабирования до тех пор, пока Service Fabric не завершит перемещение служб. Кроме того, он гарантирует, что масштабируемые наборы виртуальных машин сообщают Service Fabric о том, что виртуальные машины удаляются, а не только временно.
Дополнительные сведения о масштабировании на уровне узла или кластера см. в статье Масштабирование кластеров Azure Service Fabric.
Масштабирование служб
Службы без отслеживания состояния и отслеживания состояния применяют различные подходы к масштабированию.
Для службы без отслеживания состояния (автомасштабирование):
- Используйте триггер средней нагрузки секции. Этот триггер определяет, когда служба масштабируется или выходит на основе порогового значения нагрузки, указанного в политике масштабирования. Можно также задать частоту проверка триггера. См . раздел "Средняя загрузка секции" с масштабированием на основе экземпляров. Этот подход позволяет масштабировать до количества доступных узлов.
- Задайте
InstanceCountзначение -1 в манифесте службы, который сообщает Service Fabric запускать экземпляр службы на каждом узле. Этот подход позволяет службе динамически масштабироваться по мере масштабирования кластера. По мере изменения количества узлов в кластере Service Fabric автоматически создает и удаляет экземпляры служб для сопоставления.
Примечание.
В некоторых случаях может потребоваться вручную масштабировать службу. Например, если у вас есть служба, которая считывается из Центры событий Azure, может потребоваться, чтобы выделенный экземпляр считывал из каждой секции концентратора событий. Таким образом, можно избежать параллельного доступа к секции.
Для службы с отслеживанием состояния масштабируется по количеству секций, размеру каждой секции и количеству секций или реплика, выполняемых на компьютере:
Если вы создаете секционированные службы, убедитесь, что каждый узел получает достаточные реплика для даже распределения рабочей нагрузки без возникновения конфликтов ресурсов. При добавлении дополнительных узлов Service Fabric распределяет рабочие нагрузки на новые компьютеры по умолчанию. Например, если на каждом узле по умолчанию есть 5 узлов и 10 секций, Service Fabric будет размещать две основные реплика на каждом узле. При горизонтальном масштабировании узлов можно добиться большей производительности, так как работа равномерно распределяется по нескольким ресурсам.
Сведения о сценариях, которые используют эту стратегию, см. в разделе "Масштабирование" в Service Fabric.
Добавление или удаление секций не поддерживается. Другим вариантом, который обычно используется для масштабирования, является динамическое создание или удаление служб или целых экземпляров приложений. Пример этого шаблона описан в статье Масштабирование путем создания или удаления новых именованных служб.
Дополнительные сведения см. в разделе:
- Масштабирование кластера Service Fabric с помощью правил автомасштабирования или вручную
- Программное масштабирование кластера Service Fabric
- Масштабирование кластера Service Fabric путем добавления масштабируемого набора виртуальных машин
Использование метрик для балансировки нагрузки
В зависимости от того, как вы разрабатываете секцию, могут быть узлы с реплика, которые получают больше трафика, чем другие. Чтобы избежать этой ситуации, разделите состояние службы таким образом, чтобы оно распределялось по всем секциям. Используйте схему секционирования диапазона с хорошим хэш-алгоритмом. См. статью "Начало работы с секционированием".
Service Fabric использует метрики, чтобы узнать, как размещать и балансировать службы в кластере. Вы можете указать загрузку по умолчанию для каждой метрики, связанной со службой при создании этой службы. Затем Service Fabric учитывает ее при размещении службы или при каждом перемещении службы (например, во время обновления), чтобы сбалансировать узлы в кластере.
Начальная загрузка по умолчанию для службы не изменится в течение всего времени существования службы. Чтобы записать изменяющиеся метрики для службы, рекомендуется отслеживать службу, а затем динамически сообщать о загрузке. Такой подход позволяет Service Fabric настраивать выделение на основе указанной нагрузки в определенное время. Используйте метод IServicePartition.ReportLoad для создания отчетов о пользовательских метриках. Дополнительные сведения см. в разделе "Динамическая загрузка".
Доступность
Поместите службы в тип узла, отличный от типа первичного узла. Системные службы Service Fabric всегда развертываются в основном типе узла. Если службы развертываются в основном типе узла, они могут конкурировать с системными службами (и вмешиваться) в ресурсы. Если ожидается, что тип узла будет размещать службы с отслеживанием состояния, убедитесь, что имеется по крайней мере пять экземпляров узлов и выбран уровень устойчивости Silver или Gold.
Рассмотрите возможность ограничения ресурсов служб. См . механизм управления ресурсами.
Ниже приведены распространенные рекомендации.
- Не смешивайте службы, управляемые ресурсами, и службы, которые не управляются ресурсом одного типа узла. Неуправляемые службы могут потреблять слишком много ресурсов и влиять на управляемые службы. Укажите ограничения размещения, чтобы убедиться, что эти типы служб не выполняются в одном наборе узлов. (Это пример Шаблон переборки.)
- Укажите ядра ЦП и память для резервирования экземпляра службы. Сведения об использовании и ограничениях политик управления ресурсами см. в разделе "Управление ресурсами".
Чтобы избежать одной точки сбоя (SPOF), убедитесь, что целевой экземпляр каждой службы или число реплика больше одного. Наибольшее число, которое можно использовать в качестве экземпляра службы или реплика, равно количеству узлов, ограничивающих службу.
Убедитесь, что каждая служба с отслеживанием состояния имеет по крайней мере две активные вторичные реплика. Для рабочих нагрузок рекомендуется использовать пять реплика.
Дополнительные сведения см. в разделе "Доступность служб Service Fabric".
Безопасность
Безопасность обеспечивает гарантии от преднамеренного нападения и злоупотребления ценными данными и системами. Дополнительные сведения см. в разделе "Общие сведения о компоненте безопасности".
Ниже приведены некоторые ключевые моменты для защиты приложения в Service Fabric.
Виртуальная сеть
Рассмотрите возможность определения границ подсети для каждого масштабируемого набора виртуальных машин для управления потоком обмена данными. Каждый тип узла имеет собственный масштабируемый набор виртуальных машин в подсети в виртуальной сети кластера Service Fabric. Группы безопасности сети (NSG) можно добавить в подсети, чтобы разрешить или отклонить сетевой трафик. Например, с типами интерфейсных и внутренних узлов можно добавить группу безопасности сети в серверную подсеть, чтобы принимать входящий трафик только из интерфейсной подсети.
При вызове внешних служб Azure из кластера используйте конечные точки службы виртуальной сети, если служба Azure поддерживает ее. Использование конечной точки службы защищает службу только виртуальной сети кластера.
Например, если вы используете Azure Cosmos DB для хранения данных, настройте учетную запись Azure Cosmos DB с конечной точкой службы, чтобы разрешить доступ только из определенной подсети. Ознакомьтесь с ресурсами Azure Cosmos DB из виртуальных сетей.
Конечные точки и взаимодействие между службами
Не создавайте незащищенный кластер Service Fabric. Если кластер предоставляет конечные точки управления общедоступному Интернету, анонимные пользователи могут подключиться к нему. Незащищенные кластеры нельзя использовать для выполнения производственных задач. См . сценарии безопасности кластера Service Fabric.
Чтобы защитить обмен данными между службами, выполните приведенные действия.
- Рассмотрите возможность включения конечных точек HTTPS в веб-службах ASP.NET Core или Java.
- Установите безопасное подключение между обратным прокси-сервером и службами. Дополнительные сведения см. в Подключение безопасной службе.
Если вы используете шлюз API, вы можете отключить проверку подлинности на шлюз. Убедитесь, что отдельные службы не могут быть доступны напрямую (без шлюза API), если для проверки подлинности сообщений не применяется дополнительная безопасность.
Не предоставляйте обратный прокси-сервер Service Fabric публично. Это приводит к тому, что все службы, предоставляющие конечные точки HTTP, могут быть адресируемыми извне кластера. Это приведет к уязвимостям системы безопасности и потенциально предоставляет дополнительную информацию за пределами кластера без необходимости. Если вы хотите получить доступ к службе публично, используйте шлюз API. Раздел шлюза API далее в этой статье упоминание некоторые варианты.
Удаленный рабочий стол полезен для диагностики и устранения неполадок, но не забудьте закрыть его. Оставляя его открытым, вызывает отверстие безопасности.
Сертификаты и секреты
Храните секреты, такие как строка подключения в хранилищах данных, в хранилище ключей. Хранилище ключей должно находиться в том же регионе, что и масштабируемый набор виртуальных машин. Чтобы использовать хранилище ключей, выполните приведенные действия.
Проверка подлинности доступа службы к хранилищу ключей.
Включите управляемое удостоверение в масштабируемом наборе виртуальных машин, на котором размещена служба.
Храните секреты в хранилище ключей.
Добавьте секреты в формат, который можно преобразовать в пару "ключ-значение". Например, укажите
CosmosDB--AuthKey. При построении конфигурации двойный дефис (--) преобразуется в двоеточие (:).Доступ к этим секретам в службе.
Добавьте URI хранилища ключей в файл приложения Параметры.json. Добавьте в службу поставщик конфигурации, который считывает из хранилища ключей, создает конфигурацию и обращается к секрету из встроенной конфигурации.
Ниже приведен пример, в котором служба рабочего процесса хранит секрет в хранилище ключей в формате CosmosDB--Database.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Чтобы получить доступ к секрету, укажите имя секрета в встроенной конфигурации.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
Не используйте сертификаты клиента для доступа к Обозреватель Service Fabric. Вместо этого используйте идентификатор Microsoft Entra. Ознакомьтесь со службами Azure, поддерживающими проверку подлинности Microsoft Entra.
Не используйте самозаверяющий сертификаты для рабочей среды.
Защита неактивных данных
Если подключенные диски данных к масштабируемым наборам виртуальных машин кластера Service Fabric и службы сохраняют данные на этих дисках, необходимо зашифровать диски. Дополнительные сведения см. в статье "Шифрование ОС" и подключенных дисков данных в масштабируемом наборе виртуальных машин с помощью Azure PowerShell (предварительная версия).
Дополнительные сведения о защите Service Fabric см. в следующем разделе:
- Общие сведения о безопасности Azure Service Fabric
- Рекомендации по безопасности Azure Service Fabric
- Список проверка безопасности Azure Service Fabric
Устойчивость
Чтобы восстановиться после сбоев и обеспечить полное состояние, приложение должно реализовать определенные шаблоны устойчивости. Ниже приведены некоторые распространенные шаблоны:
- Повторите попытку. Для обработки ошибок, которые вы ожидаете, будут временными, например ресурсы, которые временно недоступны.
- Средство разбиения цепи: устранение ошибок, которые могут занять больше времени.
- Перебор: чтобы изолировать ресурсы для каждой службы.
Эта эталонная реализация использует Polly, параметр с открытым исходным кодом для реализации всех этих шаблонов.
Наблюдение
Перед изучением параметров мониторинга рекомендуется ознакомиться с этой статьей о диагностике распространенных сценариев с помощью Service Fabric. Вы можете подумать о мониторинге данных в следующих наборах:
- Метрики и журналы приложений
- Данные о работоспособности и событиях Service Fabric
- Метрики инфраструктуры и журналы
- Метрики и журналы для зависимых служб
Это два основных варианта анализа этих данных:
- Application Insights
- Служба Log Analytics
Azure Monitor можно использовать для настройки панелей мониторинга для мониторинга и отправки оповещений операторам. Некоторые сторонние средства мониторинга также интегрированы с Service Fabric, например Dynatrace. Дополнительные сведения см. в статье о партнерах по мониторингу Azure Service Fabric.
Метрики и журналы приложений
Данные телеметрии приложений позволяют отслеживать работоспособность службы и выявлять проблемы. Чтобы добавить трассировки и события в службу, выполните приведенные ниже действия.
- Используйте Microsoft.Extensions.Logging , если вы разрабатываете службу с помощью ASP.NET Core. Для других платформ используйте библиотеку ведения журналов, например Serilog.
- Добавьте собственное инструментирование с помощью класса TelemetryClient в пакете SDK и просмотрите данные в Application Аналитика. См. статью "Добавление пользовательского инструментирования в приложение".
- Трассировка событий журнала для событий Windows (ETW) с помощью EventSource. Этот параметр доступен по умолчанию в решении Visual Studio Service Fabric.
Приложение Аналитика предоставляет множество встроенных данных телеметрии: запросов, трассировок, событий, исключений, метрик, зависимостей. Если служба предоставляет конечные точки HTTP, включите приложение Аналитика путем вызова UseApplicationInsights метода расширения для Microsoft.AspNetCore.Hosting.IWebHostBuilder. Сведения о инструментировании службы для приложений Аналитика см. в следующих статьях:
- Руководство. Мониторинг и диагностика приложения ASP.NET Core в Service Fabric с помощью приложения Аналитика
- Application Insights для ASP.NET Core
- Пакет SDK Application Insights для .NET
- Пакет SDK Аналитика приложений для Service Fabric
Чтобы просмотреть трассировки и журналы событий, используйте приложение Аналитика в качестве одного из приемников для структурированного ведения журнала. Настройте приложение Аналитика с помощью ключа инструментирования путем вызова AddApplicationInsights метода расширения. В этом примере ключ инструментирования хранится в виде секрета в хранилище ключей.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Если служба не предоставляет конечные точки HTTP, необходимо написать пользовательское расширение, которое отправляет трассировки в приложение Аналитика. Пример см. в службе рабочего процесса в эталонной реализации.
ASP.NET основные службы используют интерфейс ILogger для ведения журнала приложений. Чтобы сделать эти журналы приложений доступными в Azure Monitor, отправьте ILogger события в приложение Аналитика. Приложение Аналитика может добавлять свойства корреляции в ILogger события, которые полезны для визуализации распределенной трассировки.
Дополнительные сведения см. в разделе:
Данные о работоспособности и событиях Service Fabric
Данные телеметрии Service Fabric включают метрики работоспособности и события о работе и производительности кластера Service Fabric и его сущностей: узлов, приложений, служб, секций и реплика. Данные о работоспособности и событиях могут поступать из:
EventStore. Эта служба системы с отслеживанием состояния собирает события, связанные с кластером и ее сущностями. Service Fabric использует EventStore для записи событий Service Fabric для предоставления сведений о кластере для обновлений состояния, устранения неполадок и мониторинга. EventStore также может сопоставлять события из разных сущностей в определенное время для выявления проблем в кластере. Служба предоставляет эти события через REST API.
Сведения о том, как запрашивать API EventStore, см. в разделе API Query EventStore для событий кластера. События из EventStore можно просмотреть в Log Analytics, настроив кластер с расширением Диагностика Azure для Windows (WAD).
HealthStore. Эта служба с отслеживанием состояния предоставляет моментальный снимок текущей работоспособности кластера. Он объединяет все данные о работоспособности, сообщаемые сущностями в иерархии. Данные визуализированы в service Fabric Обозреватель. HealthStore также отслеживает обновления приложений. Запросы работоспособности можно использовать в PowerShell, приложении .NET или REST API. Общие сведения о мониторинге работоспособности Service Fabric.
Пользовательские отчеты о работоспособности. Рассмотрите возможность реализации внутренних служб наблюдателя, которые могут периодически сообщать пользовательские данные о работоспособности, такие как неисправные состояния запущенных служб. Отчеты о работоспособности можно прочитать в Service Fabric Обозреватель.
Метрики и журналы инфраструктуры
Метрики инфраструктуры помогают понять выделение ресурсов в кластере. Ниже приведены основные варианты сбора этой информации:
- WAD. Сбор журналов и метрик на уровне узла в Windows. Вы можете использовать WAD, настроив расширение виртуальной машины IaaSDiagnostics в любом масштабируемом наборе виртуальных машин, сопоставленном с типом узла для сбора диагностических событий. Эти события могут включать журналы событий Windows, счетчики производительности, систему etw/манифестов и операционные события, а также пользовательские журналы.
- Агент Log Analytics. Настройте расширение виртуальной машины MicrosoftMonitoringAgent для отправки журналов событий Windows, счетчиков производительности и пользовательских журналов в Log Analytics.
Существует некоторое перекрытие типов метрик, собранных с помощью предыдущих механизмов, таких как счетчики производительности. Где есть перекрытие, рекомендуется использовать агент Log Analytics. Так как агент Log Analytics не использует службу хранилища Azure, задержка низка. Кроме того, счетчики производительности в IaaSDiagnostics нельзя легко загружать в Log Analytics.
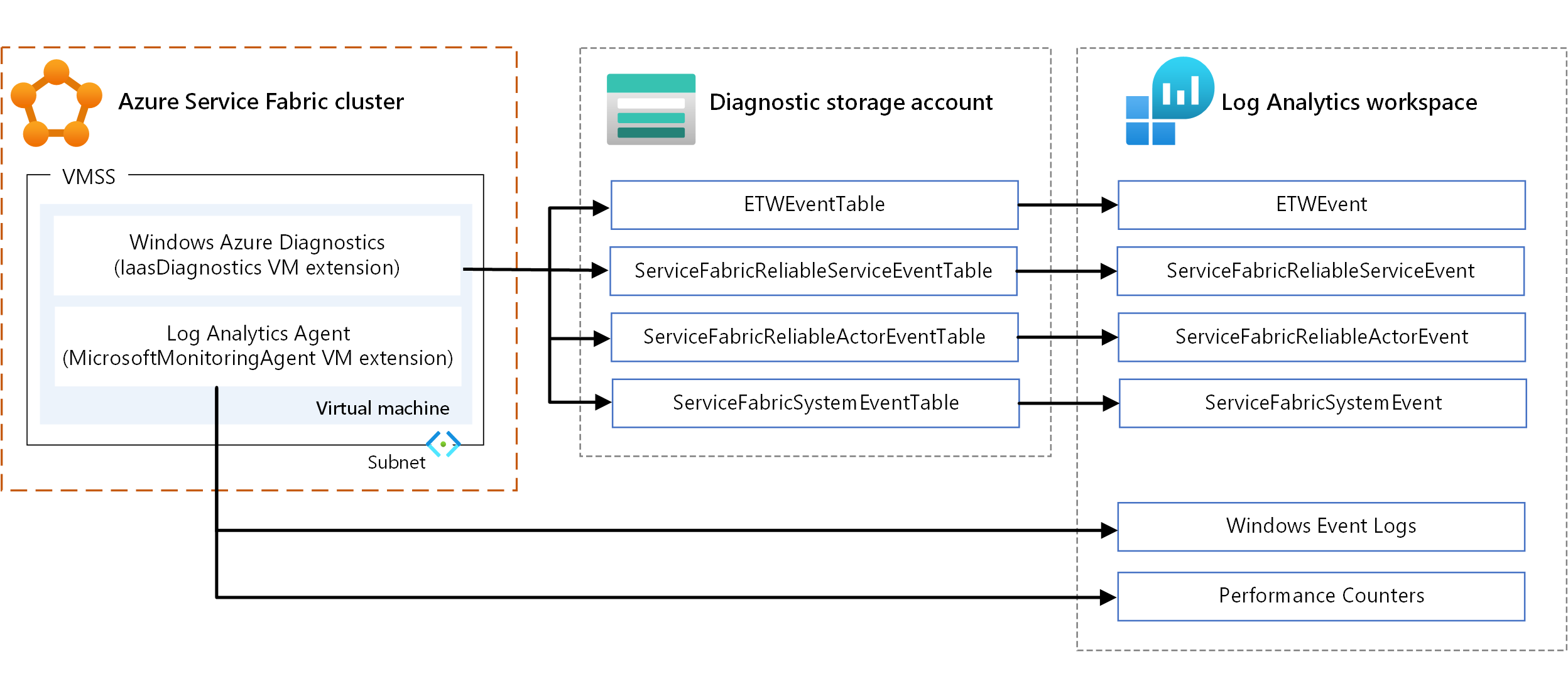
Сведения об использовании расширений виртуальных машин см. в статье о расширениях и функциях виртуальных машин Azure.
Чтобы просмотреть данные, настройте Log Analytics для отображения данных, собранных через WAD. Сведения о настройке Log Analytics для чтения событий из учетной записи хранения см. в статье "Настройка Log Analytics для кластера".
Кроме того, можно просматривать журналы производительности и данные телеметрии, связанные с кластером Service Fabric, рабочими нагрузками, сетевым трафиком, ожидающих обновлений и т. д. См . мониторинг производительности с помощью Log Analytics.
Решение "Карта служб" в Log Analytics содержит сведения о топологии кластера (т. е. процессах, выполняемых на каждом узле). Отправьте данные в учетную запись хранения в приложение Аналитика. Может возникнуть некоторая задержка при получении данных в приложение Аналитика. Если вы хотите просмотреть данные в режиме реального времени, попробуйте настроить центры событий с помощью приемников и каналов. Дополнительные сведения см. в разделе агрегирование событий и сбор с помощью WAD.
Зависимые метрики служб
- Карта приложений в приложении Аналитика предоставляет топологию приложения с помощью вызовов зависимостей HTTP, выполняемых между службами, с установленным пакетом SDK для приложений Аналитика.
- Карта служб в Log Analytics предоставляет сведения о входящего и исходящего трафика из и во внешние службы. Карта служб интегрируется с другими решениями, такими как обновления или безопасность.
- Пользовательские наблюдатели могут сообщать об ошибках во внешних службах. Например, служба может предоставить отчет о работоспособности ошибок, если он не может получить доступ к внешней службе или хранилищу данных (Azure Cosmos DB).
Распределенная трассировка
В архитектуре микрослужб несколько служб часто участвуют в выполнении задачи. Данные телеметрии из каждой из этих служб коррелируются с помощью полей контекста (например, идентификатора операции и идентификатора запроса) в распределенной трассировке.
С помощью карты приложений в приложении Аналитика можно создать представление распределенных логических операций и визуализировать весь граф службы приложения. Вы также можете использовать диагностика транзакций в приложении Аналитика для сопоставления данных телеметрии на стороне сервера. Дополнительные сведения см. в диагностика единой транзакции между компонентами.
Также важно сопоставить задачи, которые отправляются асинхронно с помощью очереди. Дополнительные сведения о отправке телеметрии корреляции в сообщении очереди см. в разделе инструментирование очередей.
Дополнительные сведения см. в разделе:
Оповещения и панели мониторинга
Приложение Аналитика и Log Analytics поддерживают обширный язык запросов (язык запросов Kusto), который позволяет извлекать и анализировать данные журнала. Используйте запросы для создания наборов данных и визуализации их в диагностика панелях мониторинга.
Используйте оповещения Azure Monitor для уведомления системных администраторов при возникновении определенных условий в определенных ресурсах. Например, уведомление может быть электронной почтой, функцией Azure или веб-перехватчиком. Дополнительные сведения см. в статье "Оповещения" в Azure Monitor.
Правила генерации оповещений поиска журналов позволяют определять и запускать запрос Kusto в рабочей области Log Analytics с регулярными интервалами. Если результат запроса соответствует определенному условию, создается оповещение.
Оптимизация затрат
Для оценки затрат используйте калькулятор цен Azure. Другие рекомендации описаны в разделе "Оптимизация затрат" в Microsoft Azure Well-Architected Framework.
Ниже приведены некоторые моменты, которые следует учитывать для некоторых служб, используемых в этой архитектуре.
Azure Service Fabric
Плата взимается за вычислительные экземпляры, хранилище, сетевые ресурсы и IP-адреса, которые вы выбираете при создании кластера Service Fabric. Для Service Fabric взимается плата за развертывание.
Масштабируемые наборы виртуальных машин
В этой архитектуре микрослужбы развертываются на узлах, которые являются масштабируемыми наборами виртуальных машин. Плата взимается за виртуальные машины Azure, развернутые в составе кластера и базовых ресурсов инфраструктуры, таких как хранилище и сеть. Для масштабируемых наборов виртуальных машин не взимается добавочная плата.
Управление API Azure
Azure Управление API — это шлюз для маршрутизации запросов от клиентов к службам в кластере.
Существуют различные варианты ценообразования. Параметр потребления взимается на основе оплаты за использование и включает компонент шлюза. На основе рабочей нагрузки выберите вариант, описанный в Управление API ценах.
Application Insights
С помощью приложения Аналитика можно собирать данные телеметрии для всех служб и просматривать трассировки и журналы событий структурированным образом. Цены на Приложение Аналитика — это модель с оплатой по мере использования, основанная на томе и вариантах хранения данных. Дополнительные сведения см. в разделе "Управление использованием и затратами для приложений Аналитика".
Azure Monitor
Для Azure Monitor Log Analytics взимается плата за прием и хранение данных. Дополнительные сведения см. на странице цен на Azure Monitor.
Azure Key Vault
Azure Key Vault используется для хранения ключа инструментирования для приложения Аналитика в качестве секрета. Azure предлагает Key Vault на двух уровнях служб. Если вам не нужны ключи, защищенные HSM, выберите уровень "Стандартный". Сведения о функциях на каждом уровне см. в разделе цен на Key Vault.
Azure DevOps Services
Эта эталонная архитектура использует Azure Pipelines для развертывания. Служба Azure Pipelines позволяет бесплатно размещать задание майкрософт с 1800 минут в месяц для CI/CD и одно локальное задание с неограниченными минутами в месяц. Дополнительные рабочие места имеют расходы. Дополнительные сведения см. в разделе о ценах на Azure DevOps Services.
Рекомендации по DevOps в архитектуре микрослужб см. в разделе CI/CD для микрослужб.
Сведения о развертывании приложения-контейнера с CI/CD в кластере Service Fabric см . в этом руководстве.
Развертывание этого сценария
Чтобы развернуть эталонную реализацию для этой архитектуры, выполните действия, описанные в репозитории GitHub.
Следующие шаги
- Учебный курс. Введение в Azure Service Fabric
- Общие сведения о Service Fabric
- Документация по службе "Управление API"
- Что такое Azure Pipelines?