Применение DataOps к Фабрика данных Azure
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Фабрика данных Azure — это служба microsoft Интеграция данных и ETL в облаке. В этом документе приводятся рекомендации по DataOps в фабрике данных. Это не предназначено для полного руководства по CI/CD, Git или DevOps. Скорее, вы найдете руководство команды фабрики данных по достижению DataOps в службе со ссылками на подробные ссылки на реализацию рекомендаций по развертыванию фабрики данных, управления фабрикой и управления. В конце этого документа содержится раздел ресурсов со ссылками на руководства.
Что такое DataOps?
DataOps — это процесс, который организации данных практикуют для совместного управления данными, предназначенные для повышения ценности для лиц, принимающих решения.
Gartner предоставляет это четкое определение DataOps:
DataOps — это совместная практика управления данными, ориентированная на улучшение взаимодействия, интеграции и автоматизации потоков данных между диспетчерами данных и потребителями данных в организации. Цель DataOps — ускорить доставку, создавая прогнозируемую доставку и управление изменениями данных, моделей данных и связанных артефактов. DataOps использует технологию для автоматизации проектирования, развертывания и управления доставкой данных с соответствующим уровнем управления и использования метаданных для повышения удобства использования и ценности данных в динамической среде.
Как достичь DataOps в Фабрика данных Azure?
Фабрика данных Azure предоставляет инженерам данных визуальную парадигму конвейера данных для легкого создания проектов интеграции данных в масштабе облака и ETL. Фабрика данных использует собственные интеграции со зрелыми средствами управления версиями, такими как GitHub и Azure DevOps, а также более широкая экосистема Azure, чтобы обеспечить множество встроенных функций для упрощения работы DataOps, которые включают широкие связи совместной работы, управления и артефактов.
В частности, после переноса собственного репозитория GitHub или Azure DevOps в фабрику данных служба предоставляет интуитивно понятные встроенные параметры пользовательского интерфейса для распространенных команд, таких как фиксации, сохранение артефактов и управление версиями. Служба также предоставляет возможность предоставлять рекомендации по ci/CD и коду проверка, чтобы защитить работоспособность и работоспособность рабочей среды.
"Код" в Фабрика данных Azure
Все артефакты в Фабрика данных Azure, имеют ли они конвейеры, связанные службы, триггеры и т. д. имеют соответствующие представления "кода" в JSON за интеграцией визуального пользовательского интерфейса. Эти артефакты действуют в соответствии со стандартами шаблонов Azure Resource Manager. Код можно найти, щелкнув значок скобки в правом верхнем углу холста. Пример json "code" будет выглядеть следующим образом:
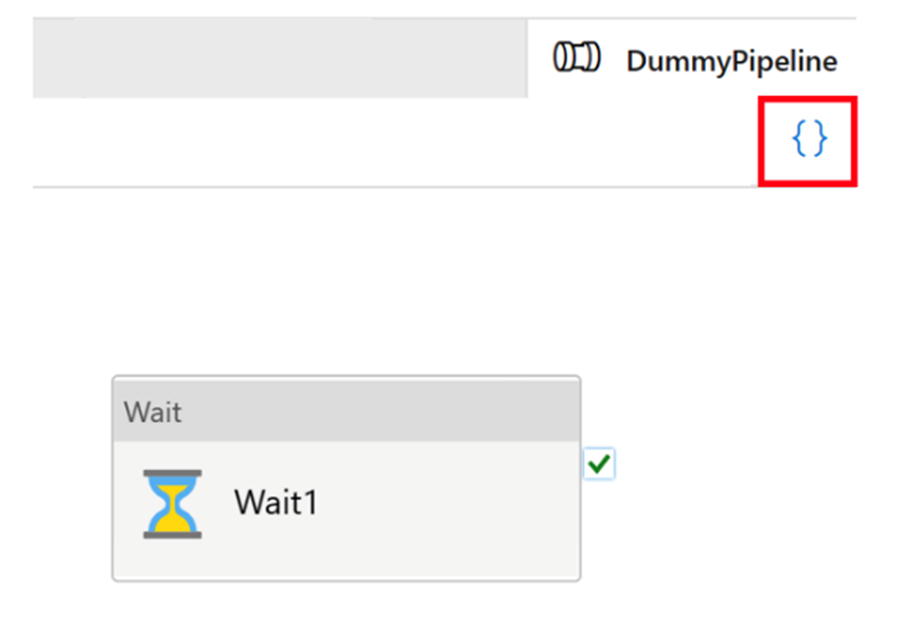
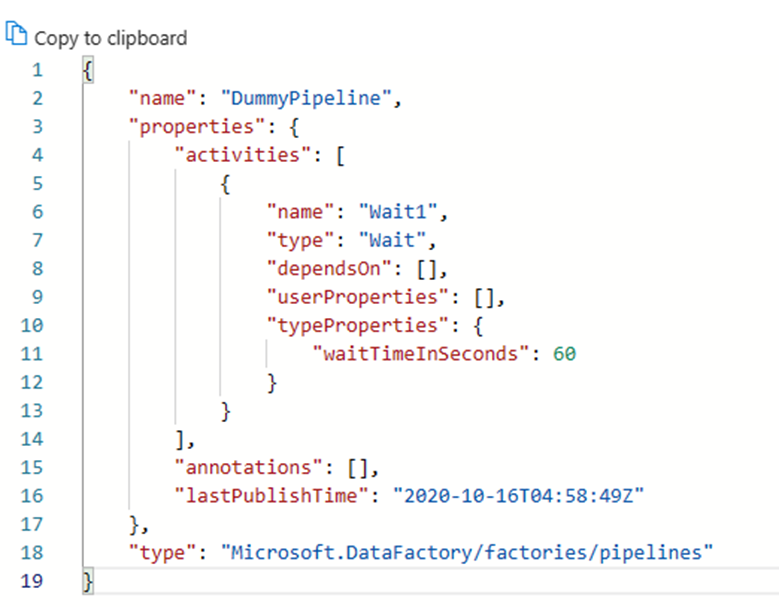
Режим реального времени и управление версиями Git
Каждая фабрика имеет один источник истины: конвейеры, связанные службы и определения триггеров, хранящиеся в службе. Этот источник истины заключается в том, что выполняется конвейер и что определяет поведение триггеров. Если вы находитесь в режиме реального времени, каждый раз, когда вы публикуете, вы непосредственно изменяете один источник истины. На следующем рисунке показано, как выглядит кнопка "Опубликовать все " в режиме реального времени.

Динамический режим может быть удобным для отдельных пользователей, работающих над побочными проектами, так как он позволяет разработчикам видеть немедленные последствия изменения кода. Однако это не рекомендуется для команды разработчиков, работающих над рабочими проектами на уровне рабочей среды. Опасности включают в себя толстые пальцы, случайное удаление критически важных ресурсов, публикацию непроверенных кодов и т. д., просто назовите несколько. При работе с критически важными проектами и платформами рекомендуется включить репозиторий Git и использовать режим Git в фабрике данных для упрощения процесса разработки. Управление версиями и встроенные возможности проверка режима Git помогают предотвратить большинство аварий, связанных с сенсорным режимом прямо.
Примечание.
В режиме Git кнопка "Опубликовать" или "Опубликовать все" будет заменена сохранением или сохранением всех, и изменения фиксируются в собственных ветвях (не напрямую изменяя базы динамического кода).
Настройка интеграции GitHub и Azure DevOps
В Фабрика данных Azure настоятельно рекомендуется хранить репозиторий в GitHub или Azure DevOps. Служба полностью поддерживает как методы, так и выбор используемого репозитория зависит от ваших отдельных организационных стандартов. Существует два метода настройки нового репозитория или подключения к существующему репозиторию: использование портал Azure или создание из пользовательского интерфейса Фабрика данных Azure Studio
создание фабрики портал Azure
При создании фабрики данных из портал Azure репозиторий Git по умолчанию — Azure DevOps. Вы также можете выбрать GitHub в качестве репозитория и настроить параметры репозитория.
В портал Azure выберите тип репозитория и введите имена репозитория и ветви, чтобы создать новую фабрику, интегрированную с Git.
Принудительное использование Git с Политика Azure в организации
Использование Git в проектах Фабрика данных Azure является настоятельно рекомендуемой практикой. Даже если вы не реализуете полный процесс CI/CD, интеграция Git с ADF позволяет сохранять артефакты ресурсов в собственной песочнице (ветвь Git), где можно протестировать изменения независимо от остальных ветвей фабрики. Вы можете использовать Политика Azure для принудительного использования Git в фабрике вашей организации.
Azure Data Factory Studio
После создания фабрики данных вы также можете подключиться к репозиторию через Фабрика данных Azure Studio. На вкладке "Управление " вы увидите параметр настройки параметров репозитория и репозитория.

С помощью интерактивного процесса вы будете направляться с помощью ряда шагов, которые помогут вам легко настроить и подключиться к вашему репозиторию. После полной настройки вы можете начать совместную работу и сохранить ресурсы в репозитории.
Непрерывная интеграция и непрерывная поставка (CI/CD)
CI/CD — это парадигма разработки кода, в которой изменения проверяются и тестируются при переходе на различные этапы разработки, тестирования, промежуточного хранения и т. д. После проверки и тестирования на каждом этапе они, наконец, публикуются в живых базах кода в рабочей среде.
Непрерывная интеграция (CI) — это практика автоматического тестирования и проверки при каждом изменении базы кода разработчиком. Непрерывная доставка (CD) означает, что после успешного выполнения тестов непрерывной интеграции изменения будут перенесены на следующий этап непрерывно.
Как упоминалось кратко ранее, код в Фабрика данных Azure принимает форму JSON шаблона Azure Resource Manager. Таким образом, изменения, которые проходят через процесс непрерывной интеграции и доставки (CI/CD), включают в себя дополнения, удаления и изменения в большие двоичные объекты JSON.
Конвейер выполняется в Фабрика данных Azure
Прежде чем говорить о CI/CD в Фабрика данных Azure, сначала необходимо поговорить о том, как служба выполняет конвейер. Перед запуском конвейера фабрика данных выполняет следующие действия:
- Извлекает последнее опубликованное определение конвейера и связанные с ним ресурсы, такие как наборы данных, связанные службы и т. д.
- Компилирует его до действий; Если фабрика данных недавно выполнила ее, она извлекает действия из кэшированных компиляций.
- Запускает конвейер.
Выполнение конвейера приводит к следующим шагам:
- Служба принимает моментальный снимок определения конвейера.
- В течение длительности конвейера определения не изменяются.
- Даже если конвейеры выполняются в течение длительного времени, они не влияют на последующие изменения, внесенные после их запуска. При публикации изменений в связанной службе, конвейерах и т. д. во время выполнения они не влияют на выполняемые запуски.
- При публикации изменений последующие запуски запускались после публикации используйте обновленные определения.
Публикация в Фабрика данных Azure
Независимо от того, развертываете ли конвейеры с помощью Azure Release Pipeline для автоматизации публикации или вручную развертываете шаблоны Resource Manager в серверной части, публикация представляет собой ряд операций создания и обновления наборов данных, связанных служб, конвейеров и триггеров для каждого артефакта. Эффект совпадает с тем, что базовые вызовы REST API вызываются напрямую.
Ниже приведены некоторые действия:
- Все эти вызовы API синхронны, то есть вызов возвращается только при успешной публикации или сбое. Для артефакта не будет состояния частичного развертывания.
- Вызовы API имеют большую степень последовательности. Мы пытаемся параллелизировать вызовы, сохраняя референциальные зависимости артефактов. Порядок развертываний — связанная служба —> среда выполнения набора данных и интеграции — конвейер —>> триггер. Этот порядок гарантирует, что зависимые артефакты могут правильно ссылаться на ее зависимости. Например, конвейеры зависят от наборов данных и поэтому фабрика данных развертывает их после наборов данных.
- Развертывание связанных служб, наборов данных и т. д. не зависит от конвейеров. Существуют ситуации, когда фабрика данных обновляет связанные службы до обновления конвейера. Мы поговорим об этой ситуации в разделе "Когда остановить триггер".
- Развертывание не удаляет артефакты из фабрик. Для очистки фабрики необходимо явно вызывать API-интерфейсы для каждого типа артефакта (конвейер, набор данных, связанная служба и т. д.). Пример скрипта после развертывания см. в Фабрика данных Azure.
- Даже если вы не коснулись конвейера, набора данных или связанной службы, он по-прежнему вызывает вызов API быстрого обновления к фабрике.
Триггеры публикации
- Триггеры имеют состояния: запущены или остановлены.
- Вы не можете вносить изменения в триггер в режиме запуска . Перед публикацией изменений необходимо остановить триггер.
- Вы можете вызвать API создания или обновления триггера в триггере в режиме запуска .
- Если полезные данные изменяются, API завершается сбоем.
- Если полезные данные остаются неизменными, API завершается успешно.
- Это поведение оказывает глубокое влияние на то, когда остановить триггер.
Когда остановить триггер
Когда речь идет о развертывании в рабочей фабрике данных, при этом динамические триггеры запускают конвейер все время, вопрос становится вопросом "Следует ли остановить их?".
Короткий ответ заключается в том, что только в следующих нескольких сценариях следует рассмотреть возможность остановки триггера:
- При обновлении определений триггера необходимо остановить, включая поля, такие как дата окончания, частота и связь конвейера.
- Рекомендуется остановить триггер, если вы обновляете наборы данных или связанные службы, на которые ссылается динамический конвейер. Например, если вы поворачиваете учетные данные для SQL Server.
- Вы можете остановить триггер, если связанный конвейер вызывает ошибки и завершается сбоем и бременем серверов.
Ниже приведены некоторые моменты, которые следует учитывать при остановке триггеров:
- Как описано в разделе "Запуск конвейера" в Фабрика данных Azure, когда триггер запускает запуск конвейера, он принимает моментальный снимок конвейера, набора данных, среды выполнения интеграции и связанных определений служб. Если конвейер выполняется до заполнения изменений серверной частью, триггер запускает запуск со старой версией. В большинстве случаев это должно быть хорошо.
- Как описано в разделе "Триггеры публикации". Если триггер находится в состоянии запуска , его невозможно обновить. Таким образом, если необходимо изменить сведения об определении триггера, остановите триггер перед публикацией изменений.
- Как описано в разделе "Публикация" в Фабрика данных Azure, изменения наборов данных или связанных служб перед изменением конвейера. Чтобы убедиться, что конвейер использует правильные учетные данные и взаимодействует с правильными серверами, рекомендуется остановить связанный триггер.
Подготовка изменений "code"
Рекомендуется следовать этим рекомендациям для запросов на вытягивание.
- Каждый разработчик должен работать над собственными отдельными ветвями и в конце дня создавать запросы на вытягивание в основную ветвь репозитория. Ознакомьтесь с руководствами по запросам на вытягивание в GitHub и DevOps.
- Когда хранители шлюзов утверждают запросы на вытягивание и объединяют изменения в основную ветвь, процесс CI/CD может начаться. Существует два предлагаемых метода для повышения изменений в средах: автоматизированных и ручных.
- Когда вы будете готовы к запуску конвейеров CI/CD, вы можете сделать это обычно с помощью Выпуска Azure Pipeline или сделать развертывание конкретных отдельных конвейеров с помощью этой программы открытый код из проигрывателя Azure.
Автоматическое развертывание изменений
Чтобы помочь в автоматизированных развертываниях, рекомендуется использовать пакет npm Фабрика данных Azure служебных программ. Использование пакета npm помогает проверить все ресурсы в конвейере и создать шаблоны ARM для пользователя.
Чтобы приступить к работе с пакетом npm служебных программ Фабрика данных Azure, обратитесь к автоматической публикации для непрерывной интеграции и доставки.
Развертывание изменений вручную
После объединения ветви обратно в основную ветвь совместной работы в репозитории Git можно вручную опубликовать изменения в динамической службе Фабрика данных Azure. Служба предоставляет пользовательский интерфейс для публикации из фабрик, отличных от разработки, с параметром "Отключить публикацию" (из ADF Studio).
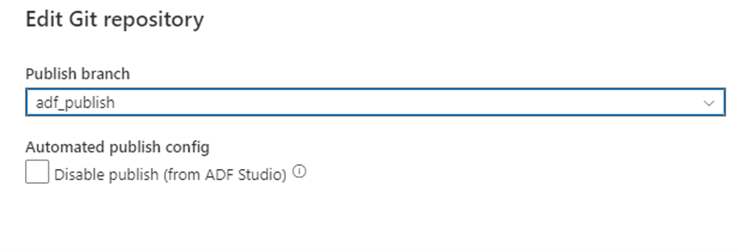
Выборочное развертывание
Выборочное развертывание зависит от функции GitHub и Azure DevOps, известной как выбор вишни. Эта функция позволяет развертывать только определенные изменения, но не другие. Например, один разработчик внес изменения в несколько конвейеров, но для сегодняшнего развертывания может потребоваться только развернуть изменения в одном.
Следуйте инструкциям из Azure DevOps и GitHub, чтобы выбрать фиксации, соответствующие нужному конвейеру. Убедитесь, что все изменения, включая соответствующие изменения, внесенные в триггеры, связанные службы и зависимости, связанные с конвейером, были выбраны.
После выбора изменений и объединения с основным конвейером совместной работы можно запустить процесс CI/CD для предлагаемых изменений. Дополнительные сведения о том, как исправить, выбрать вишню или использовать внешние платформы для выборочного развертывания, как описано в разделе автоматического тестирования этой статьи.
Модульное тестирование
Модульное тестирование является важной частью процесса разработки новых конвейеров или редактирования существующих артефактов фабрики данных, которая фокусируется на тестировании компонентов кода. Фабрика данных позволяет выполнять индивидуальное модульное тестирование на уровне артефакта конвейера и потока данных с помощью функции отладки конвейера.

При разработке потоков данных вы сможете получить аналитические сведения о каждом отдельном преобразовании и изменении кода с помощью функции предварительного просмотра данных для выполнения модульного тестирования перед развертыванием изменений в рабочей среде.

Служба предоставляет динамические и интерактивные отзывы о действиях конвейера в пользовательском интерфейсе при отладке и модульном тестировании в Фабрика данных Azure.
Автоматическое тестирование
Существует несколько средств для автоматического тестирования, которые можно использовать с Фабрика данных Azure. Так как служба хранит объекты в службе как сущности JSON, можно использовать платформу модульного тестирования .NET с открытым исходным кодом NUnit с Visual Studio. Дополнительные сведения о настройке автоматического тестирования для Фабрика данных Azure см. в этой записи, которая содержит подробное описание настройки среды автоматического модульного тестирования для фабрики. (Особое спасибо Ричарду Свинбанку за разрешение на использование этого блога.)
Клиенты также могут запускать конвейеры TEST с помощью PowerShell или AZ CLI в рамках процесса CI/CD для предварительного и последующего развертывания.
Ключевым преимуществом фабрики данных является параметризация наборов данных. Эта функция позволяет клиентам запускать одни и те же конвейеры с различными наборами данных, чтобы убедиться, что их новая разработка соответствует всем требованиям к источнику и назначению.
Другие платформы CI/CD для Фабрика данных Azure
Как описано ранее, встроенная интеграция Git доступна в собственном коде с помощью пользовательского интерфейса Фабрика данных Azure, включая объединение, ветвление, сравнение и публикацию. Однако существуют и другие полезные платформы CI/CD, популярные в сообществе Azure, которые предоставляют альтернативные механизмы для предоставления аналогичных возможностей. Методология Фабрика данных Azure Git основана на шаблонах ARM, в то время как платформы, такие как ADFTools от Камил Nowinski, принимают другой подход, опираясь на отдельные артефакты JSON из фабрики. Инженеры данных, которые смеют в Azure DevOps и предпочитают работать в этой среде (в отличие от подхода пользовательского интерфейса на основе ARM, который служба предлагает вне поля) может найти, что эта платформа работает хорошо для них и для распространенных сценариев, таких как частичные развертывания. Эта платформа также может упростить обработку триггеров при развертывании в средах с состояниями триггеров.
Управление данными в Фабрика данных Azure
Важным аспектом эффективного управления данными является управление данными. Для средств ETL интеграции с данными, предоставляя связи происхождения данных и артефактов, можно предоставить важную информацию для инженера данных, чтобы понять влияние подчиненных изменений. Фабрика данных предоставляет встроенные представления артефактов, составляющие реализацию фабрики.
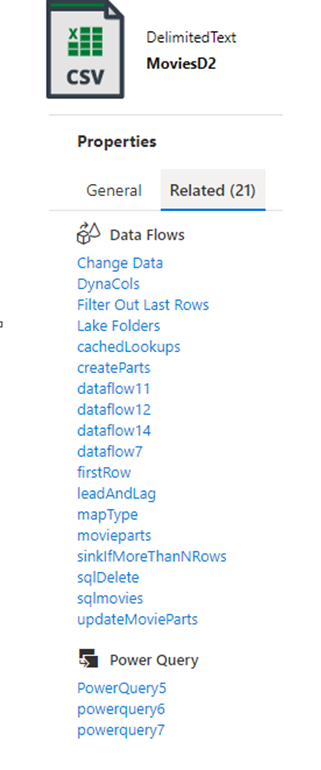
Встроенная интеграция с Microsoft Purview также обеспечивает происхождение, анализ влияния и каталогизацию данных.
Microsoft Purview предоставляет унифицированное решение по управлению данными для управления локальными, многооблачными и программными средствами как услугами (SaaS). Это позволяет легко создавать целостную, актуальную карту ландшафта данных с автоматизированным обнаружением данных, классификацией конфиденциальных данных и сквозной линией данных. Эти функции позволяют потребителям данных получать доступ к ценным, надежным управления данными.
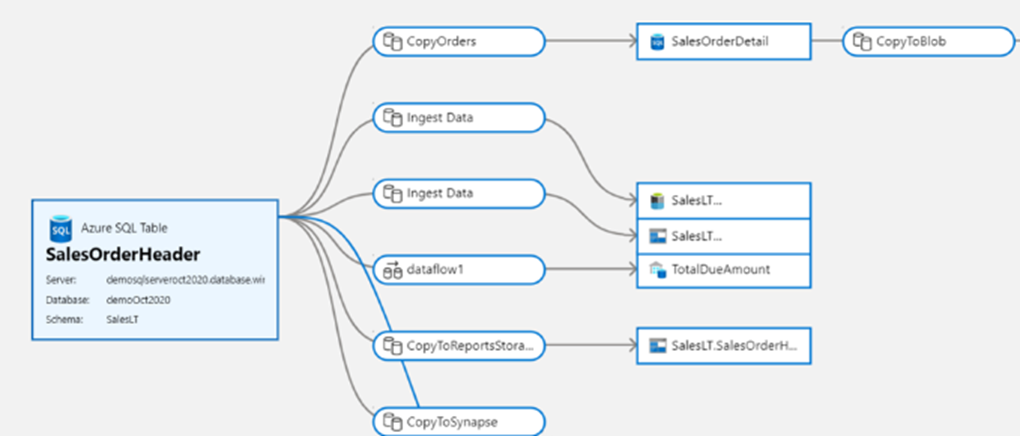
Благодаря встроенной интеграции с Каталог данных Purview фабрика данных позволяет легко искать и обнаруживать ресурсы данных для использования в конвейерах интеграции данных в пределах всего пространства данных вашей организации.

Вы можете использовать основную панель поиска из Фабрика данных Azure Studio для поиска ресурсов данных в каталоге Purview.
